







Redis 3.2.3 crashed by signal: 11 服务宕机问题排查
现象
Redis执行bgsave 、bgrewriteaof、全量scan等操作都会出现崩溃
=== REDIS BUG REPORT START: Cut & paste starting from here ===
4664:C 13 Jul 13:44:19.092 # Redis 3.2.3 crashed by signal: 11
4664:C 13 Jul 13:44:19.092 # Crashed running the instuction at: 0x4234c0
4664:C 13 Jul 13:44:19.092 # Accessing address: (nil)
4664:C 13 Jul 13:44:19.092 # Failed assertion: <no assertion failed> (<no file>:0)
------ STACK TRACE ------
EIP:
redis-rdb-bgsave 0.0.0.0:7000 [cluster](dictNext+0x70)[0x4234c0]
Backtrace:
redis-rdb-bgsave 0.0.0.0:7000 [cluster](logStackTrace+0x29)[0x45d3d9]
redis-rdb-bgsave 0.0.0.0:7000 [cluster](sigsegvHandler+0xaa)[0x45d8ca]
/lib64/libpthread.so.0(+0xf630)[0x7f82f8e7d630]
------ CURRENT CLIENT INFO ------
id=89347820 addr=127.0.0.1:63314 fd=104 name= age=35 idle=0 flags=N db=0 sub=0 psub=0 multi=-1 qbuf=0 qbuf-free=32768 obl=0 oll=0 omem=0 events=r cmd=bgsave
argv[0]: 'BGSAVE'
32912:C 13 Jul 14:28:16.596 # ------------------------------------------------
32912:C 13 Jul 14:28:16.596 # !!! Software Failure. Press left mouse button to continue
32912:C 13 Jul 14:28:16.596 # Guru Meditation: "Unknown encoding type" #object.c:456
32912:C 13 Jul 14:28:16.596 # (forcing SIGSEGV in order to print the stack trace)
32912:C 13 Jul 14:28:16.596 # ------------------------------------------------
10430:M 13 Jul 14:28:16.672 # Background saving terminated by signal 11
=== REDIS BUG REPORT START: Cut & paste starting from here ===
10430:M 13 Jul 15:01:55.933 # Redis 3.2.3 crashed by signal: 11
10430:M 13 Jul 15:01:55.933 # Crashed running the instuction at: 0x438ea0
10430:M 13 Jul 15:01:55.933 # Accessing address: (nil)
10430:M 13 Jul 15:01:55.933 # Failed assertion: <no assertion failed> (<no file>:0)
------ STACK TRACE ------
EIP:
/opt/cachecloud/redis/src/redis-server 0.0.0.0:7000 [cluster](scanCallback+0xb0)[0x438ea0]
Backtrace:
/opt/cachecloud/redis/src/redis-server 0.0.0.0:7000 [cluster](logStackTrace+0x29)[0x45d3d9]
/opt/cachecloud/redis/src/redis-server 0.0.0.0:7000 [cluster](sigsegvHandler+0xaa)[0x45d8ca]
/lib64/libpthread.so.0(+0xf630)[0x7f82f8e7d630]
/opt/cachecloud/redis/src/redis-server 0.0.0.0:7000 [cluster](scanCallback+0xb0)[0x438ea0]
/opt/cachecloud/redis/src/redis-server 0.0.0.0:7000 [cluster](dictScan+0x198)[0x423a28]
=== REDIS BUG REPORT START: Cut & paste starting from here ===
24773:S 15 Jul 17:29:29.787 # Redis 3.2.3 crashed by signal: 11
24773:S 15 Jul 17:29:29.787 # Crashed running the instuction at: 0x4231ea
24773:S 15 Jul 17:29:29.787 # Accessing address: (nil)
24773:S 15 Jul 17:29:29.787 # Failed assertion: <no assertion failed> (<no file>:0)
------ STACK TRACE ------
EIP:
/opt/cachecloud/redis/src/redis-server 0.0.0.0:7000 [cluster](dictFind+0x8a)[0x4231ea]
排查
最开始生产的该实例已经是单点了,从节点虽然启动了,但是主节点无法生成dump文件进行主从同步,无法bgsave的操作,也无法进行数据传输的操作。正当我和同事讨论要不要开启aof备份时,这个主节点挂了,只能立即启动,但是数据丢了一半。这里有个教训,这种情况应该首先在实例开启AOF,这样在崩溃时才有还原的数据以及排查的数据。
重新启动以后,我们立刻开启了aof备份,可以正常备份数据。当时如果开启了aof备份就好了,起码数据不会丢很多,开启aof备份以后,会立即进行全量的备份,将内存中的已有数据都写入aof备份文件。但是此时,造成崩溃的数据已经丢了,现在进行bgsave等操作等正常了。这时领导说要不升级下版本试试(这点要考),我们目前不能复现所以无法确定问题所在,所以没有同意进行升级。使用这个集群的项目组最近新上了功能,使用了bitmap的bitfield命令,但是没法定位问题,所以不能确定是否是这个原因(这点要考)。
因为想起mysql也有因为编码问题无法存储表情包只能使用utf8_mb4的情况,所以第二天特意找到很多表情码中文码进行读写测试,都没有出现崩溃的情况。可以正常进行数据读写。
第二天无事发生,到了第三天,又出现了类似的情况。首先是一个从节点挂掉,然后一个主节点成了单点,从节点重新启动不停向主节点请求数据同步,但主节点生成rdb始终是失败的。没过一会,主节点也失败了,这次有了aof的备份数据,直接启动节点就可以了,而且有了aof的节点数据。但是问题并没有解决。领导说要不升级到高版本试试,因为目前使用的版本是3.2.3,所以现在反正也无法定位到问题,不如死马当活马医,升级下版本试试。那就试试,于是在本地的虚拟机中搭建了3.2.12版本的实例,然后拿生产的aof备份文件进行导入启动,然后进行 scan 、bgsave等测试,确定是能够正常进行没有崩溃以后,便和业务约好一定时间进行维护,将该应用使用的集群的所有实例全部升级到了3.2.13版本。
生产稳定以后,就开始想办法复现问题定位原因了。改问题可以通过几种方式进行复现:
- 使用该数据文件进行启动,然后执行
save、bgsave、bgrewriteaof - 使用改数据文件进行启动,然后进行
save,使用less命令查看崩溃后生成的临时rdb文件temp-xxx.xxx.rdb的最后一个key,使用这个key在全局使用一个非常大的count进行scan,可以偶现崩溃情况。 - 使用该数据文件进行启动,然后执行全量scan可以偶现。
为了找到问题的key,我尝试使用几种排查的方法,
- 二分法:将aof备份文件给切分成等大小的10份、5份、2份,将每份数据的截断的命令进行删除后,非别启动实例导入每份数据,然后分别在每个实例上面执行bgsave命令,都能够正常的执行。没有出现崩溃的情况,因为对同一个key的操作是可能会分布到多个文件中,所以这个方法没法复现。
- 全局scan方式:启动实例并引入aof备份文件以后,使用java程序执行全局scan命令,
scan 0 match * count 600直到全部数据执行完毕。看是否触发崩溃。经过多次试验,并不是每次都能够复现崩溃情况(有可能存在数据超时的情况),崩溃时记录下崩溃的时候执行的key,然后拿到这个key,将其所有的操作从aof文件中导出,在一个空实例中执行,再执行bgsave命令,没有复现崩溃的情况。每次崩溃时的key也不一样。 - 修改源码,在执行bgsave中崩溃的代码以及scanCallback崩溃时的代码中对key进行输出。但这种方式只能定位到出现崩溃时的前一个key,每次的也不一样。
从以上的几次测试,可以看出,并不是特定的key数据导致的崩溃。
- 使用gdb打断点的方式,进行按步调试,但是崩溃发生的地方是循环中,因为key太多,也无法正常调试。
使用个各种方式都没法定位到问题,后来想到,既然升级了版本以后,没有再出现崩溃的问题,那么应该是某个版本对bug进行了修复,然后就从3.2.3以后的版本往后逐个创建新虚拟机进行编译->启动->导入数据->bgsave,到3.2.6版本就没有出现这个问题了。然后就查看3.2.6这个版本的修改记录,https://github.com/redis/redis/blob/3.2.6/00-RELEASENOTES
Upgrade urgency MODERATE: GEORADIUS, BITFIELD and Redis Cluster minor fixes.
This release mainly fixes three bugs:
1. A bug with BITFIELD that may cause the bitmap corruption when setting offsets
larger than the current string size.
2. A GEORADIUS bug that may happen when using very large radius lengths, in
the range of 10000km or alike, due to wrong bounding box calculation.
3. A bug with Redis Cluster which crashes when reading a nodes configuration
file with zero bytes at the end, which sometimes happens with certain ext4
configurations after a system crash.
前面不是提到了吗,使用这个集群的应用最近上了个新功能,使用了bitmap,3.2.6这个版本正好修复了bitfield命令的一个bug,使用aof文件解析工具waoffle,将aof文件解析为redis命令后,将所有的bitfield命令导出。最开始没有对bug修复描述的A bug with BITFIELD that may cause the bitmap corruption when setting offsets larger than the current string size正确理解,只能通过根据bug修复的代码进行反推。
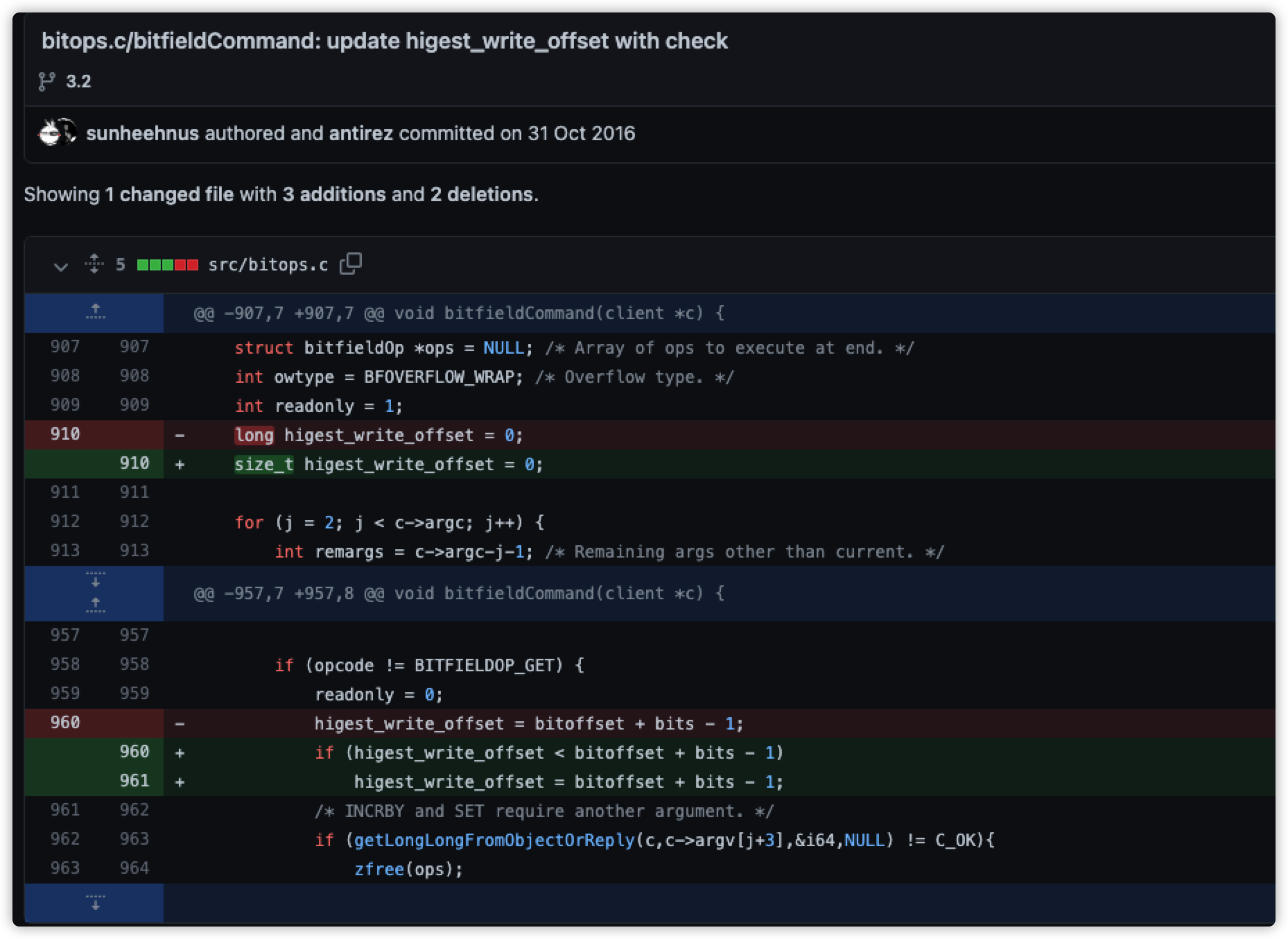
在源码处增加对执行命令、key及参数进行输出,将符合修复代码部分的命令进行输出,源码修改如下:
bitops.c
958 if (opcode != BITFIELDOP_GET) {
959 readonly = 0;
960 if(higest_write_offset!=0 && higest_write_offset < (bitoffset + bits - 1)){
961 serverLog(LL_WARNING,"key=>%s,higest:%d,sum:%d,bitoffset:%d,bits:%d",c->argv[1]->ptr,higest_write_offset,( bitoffset + bits - 1),bitoffset,bits);
962 }
963 higest_write_offset = bitoffset + bits - 1;
964 //if (higest_write_offset < bitoffset + bits - 1)
965 // higest_write_offset = bitoffset + bits - 1;
966 /* INCRBY and SET require another argument. */
967 if (getLongLongFromObjectOrReply(c,c->argv[j+3],&i64,NULL) != C_OK){
968 zfree(ops);
969 return;
970 }
971 }
符合修复部分的命令都是那种在一次bitfield命令中执行多次set命令的情况,而且只有后面命令的offset的值小于前面命令的offset值的命令才符合修复代码中的判断。
BITFIELD r_s_b-f416-45dd-9016-3c19c7e934f5 set u1 12 1 set u1 3 1
BITFIELD r_s_5-62DE-40C4-8FAE-602146E6A224 set u1 129 1 set u1 13 1
中间还做过一些通过分批执行aof备份提取的bitfield命令的定位key的测试,但是这个不是特定的key导致的,所以其实是无用排查。
最后开始分析源码,来进行故障原因分析,具体的涉及的代码可以看中文注释的所在位置:
//bitops.c
void bitfieldCommand(client *c) {
robj *o;
size_t bitoffset;
int j, numops = 0, changes = 0;
struct bitfieldOp *ops = NULL; /* Array of ops to execute at end. */
int owtype = BFOVERFLOW_WRAP; /* Overflow type. */
int readonly = 1;
//最大写入偏移量
long higest_write_offset = 0;
……省略部分代码……
if (opcode != BITFIELDOP_GET) {
readonly = 0;
//这里可以看到,这个higest_write_offset是每个循环都设置的
//一般情况下没问题,但是如果一次bitfield命令执行多次的话
//如 `BITFIELD read_status_d74cb723-1db5-489e-9adb-80d53e305d17 set u1 364 1 set u1 124 1`
//如果是这个命令执行的话,higest_write_offset会被设置为一个较小的值,如上面的命令会设为124
//再看3.2.6对bitfield bug修复所改的代码,就是增加了一个判断,是higest_write_offset的值会是命令中的最大的值
//if (higest_write_offset < bitoffset + bits - 1)
// higest_write_offset = bitoffset + bits - 1;
//
higest_write_offset = bitoffset + bits - 1;
/* INCRBY and SET require another argument. */
if (getLongLongFromObjectOrReply(c,c->argv[j+3],&i64,NULL) != C_OK){
zfree(ops);
return;
}
}
……省略部分代码……
if (readonly) {
/* Lookup for read is ok if key doesn't exit, but errors
* if it's not a string. */
o = lookupKeyRead(c->db,c->argv[1]);
if (o != NULL && checkType(c,o,OBJ_STRING)) return;
} else {
/* Lookup by making room up to the farest bit reached by
* this operation. */
//非只读操作
if ((o = lookupStringForBitCommand(c, higest_write_offset)) == NULL) return;
}
……省略部分代码……
}
/* This is an helper function for commands implementations that need to write
* bits to a string object. The command creates or pad with zeroes the string
* so that the 'maxbit' bit can be addressed. The object is finally
* returned. Otherwise if the key holds a wrong type NULL is returned and
* an error is sent to the client. */
// The command creates or pad with zeroes the string so that the 'maxbit' bit can be addressed.
// 这个命令创建string或将string填充0,这样 maxbit 的位才能被定位
// 这个maxbit的值就是higest_write_offset
robj *lookupStringForBitCommand(client *c, size_t maxbit) {
//将位数转为字节数
size_t byte = maxbit >> 3;
robj *o = lookupKeyWrite(c->db,c->argv[1]);
if (o == NULL) {
o = createObject(OBJ_STRING,sdsnewlen(NULL, byte+1));
dbAdd(c->db,c->argv[1],o);
} else {
if (checkType(c,o,OBJ_STRING)) return NULL;
o = dbUnshareStringValue(c->db,c->argv[1],o);
o->ptr = sdsgrowzero(o->ptr,byte+1);
}
return o;
}
/* Grow the sds to have the specified length. Bytes that were not part of
* the original length of the sds will be set to zero.
*
* if the specified length is smaller than the current length, no operation
* is performed. */
sds sdsgrowzero(sds s, size_t len) {
//获取当前字符串的长度
size_t curlen = sdslen(s);
//如果最大长度小于当前长度则不做任何操作
if (len <= curlen) return s;
//否则
s = sdsMakeRoomFor(s,len-curlen);
if (s == NULL) return NULL;
/* Make sure added region doesn't contain garbage */
memset(s+curlen,0,(len-curlen+1)); /* also set trailing \0 byte */
//这里会将 sds的长度设置为给定的长度,这个len是上面的(higest_write_offset >> 3) +1的长度
sdssetlen(s, len);
return s;
}
/* Enlarge the free space at the end of the sds string so that the caller
* is sure that after calling this function can overwrite up to addlen
* bytes after the end of the string, plus one more byte for nul term.
*
* Note: this does not change the *length* of the sds string as returned
* by sdslen(), but only the free buffer space we have. */
//在sds字符串后扩大空闲空间以便调用这个方法后可以在字符串后覆写新增的长度的字节,额外增加一个字节标识空位
//这个操作不会修改sds字符串的长度,只会改变空闲缓冲空间
sds sdsMakeRoomFor(sds s, size_t addlen) {
void *sh, *newsh;
size_t avail = sdsavail(s);
size_t len, newlen;
char type, oldtype = s[-1] & SDS_TYPE_MASK;
int hdrlen;
/* Return ASAP if there is enough space left. */
if (avail >= addlen) return s;
len = sdslen(s);
sh = (char*)s-sdsHdrSize(oldtype);
newlen = (len+addlen);
if (newlen < SDS_MAX_PREALLOC)
newlen *= 2;
else
newlen += SDS_MAX_PREALLOC;
type = sdsReqType(newlen);
/* Don't use type 5: the user is appending to the string and type 5 is
* not able to remember empty space, so sdsMakeRoomFor() must be called
* at every appending operation. */
if (type == SDS_TYPE_5) type = SDS_TYPE_8;
hdrlen = sdsHdrSize(type);
if (oldtype==type) {
newsh = s_realloc(sh, hdrlen+newlen+1);
if (newsh == NULL) return NULL;
s = (char*)newsh+hdrlen;
} else {
/* Since the header size changes, need to move the string forward,
* and can't use realloc */
newsh = s_malloc(hdrlen+newlen+1);
if (newsh == NULL) return NULL;
memcpy((char*)newsh+hdrlen, s, len+1);
s_free(sh);
s = (char*)newsh+hdrlen;
s[-1] = type;
//这里的sdssetlen实际上是设置了sds的长度 ,及strlen返回的结果
sdssetlen(s, len);
}
sdssetalloc(s, newlen);
return s;
}
static inline void sdssetlen(sds s, size_t newlen) {
unsigned char flags = s[-1];
switch(flags&SDS_TYPE_MASK) {
case SDS_TYPE_5:
{
unsigned char *fp = ((unsigned char*)s)-1;
*fp = SDS_TYPE_5 | (newlen << SDS_TYPE_BITS);
}
break;
case SDS_TYPE_8:
SDS_HDR(8,s)->len = newlen;
break;
case SDS_TYPE_16:
SDS_HDR(16,s)->len = newlen;
break;
case SDS_TYPE_32:
SDS_HDR(32,s)->len = newlen;
break;
case SDS_TYPE_64:
SDS_HDR(64,s)->len = newlen;
break;
}
}
BITFIELD r_s_8888_8888_8888_8888 set u1 202 1 set u1 19 1
从以上代码可以,如果在一次bitfield命令中执行多次set命令,并且后面命令的offset的值比前面的值小的话,会影响到sds字符传的长度的值。
-----------------------------
| | | | | | | | | | | | | | |
-----------------------------
第一次执行设置大offset命令
-----------------------------
|0|0|0|0|0|0|0|0|0|0|0|0|0|1|
-----------------------------
^ higest_write_offset
第二次执行设置大offset命令
-----------------------------
|0|0|0|0|0|1|0|0|0|0|0|0|0|1|
-----------------------------
^ higest_write_offset
|---sds----|
最终的sds的长度被设置为后面的短的位置,字符串的长度被截断了,这时就算执行bitfield命令获取高位的位值获取到的也只是0。
sds的组成部分为,len、 alloc、 flags 、buf[]
//以 sdshdr64举例
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
这个buf[]为一个柔性数组,即未给定长度可以动态调整长度的数组。sds的扩容策略是若sds中剩余空闲长度大于新增内容的长度,则直接在柔性数组的buf末尾追加,无需扩容。若sds中剩余空闲长度小于或等于新增内容的长度,则分两种情况:(当前长度+新增长度)<1MB,按(当前长度+新增长度)的2被扩容;若(当前长度+新增长度)>1MB,则按(当前长度+新增长度)+1MB进行扩容。然后根据新长度重新选取存储类型,并分配空间。若无需更改类型,则通过realloc扩大柔性数据即可,否则则需要重新开辟内存,将原字符串的buf内容移动到新位置。
根据故障的数据,最大的为900多,所以应该有会触发柔性数组由sdshdr8(256以内)向sdshdr16(65536)的扩容。并且前面的higest_write_offset的循环设置,会导致sds截断,如下面的命令测试。sds strlen r_s_8888_8888_8888_8888 的长度的值为 19>>3 +1 == 19/8 + 1 = 3
127.0.0.1:8888> BITFIELD r_s_8888_8888_8888_8888 set u1 202 1 set u1 19 1
1) (integer) 1
2) (integer) 0
127.0.0.1:8888> bitfield r_s_8888_8888_8888_8888 get u1 202
1) (integer) 0
127.0.0.1:8888> bitfield r_s_8888_8888_8888_8888 get u1 19
1) (integer) 1
127.0.0.1:8888> strlen r_s_8888_8888_8888_8888
(integer) 3
由此我推测,被截断的剩下的那部分内存是导致redis崩溃的原因,比如说这块内存被回收或间接的使用影响到了其他的dictEntry内存的key的部分,或者影响到了其他的redisobject的encoding部分,导致数据不完整,以至于扫描到对应的key,或者获取对应的dictEntry的key或者encoding等等,就会因为数据的错乱而导致崩溃。这个情况必须是bug代码配合大量数据执行才能出现的情况。以目前的能力只能推测到这里,没法进行再深入的验证了。
另外当时有一个排查方向是怀疑在执行bug代码时正好进行频繁rehash导致有问题,但是看了rehash的代码,rehash的过程只是hashtable[0] 和 hashtable[1]的交替扩容及key的hash值的重新计算和dictEntry与hashtable的bucket索引的重新绑定,并没有涉及到dictEntry以及redisObject的内存变动,所以排除rehash造成的该崩溃。
这个问题排查的难点是虽然可以稳定的复现,但是复现时的数据不是固定的数据,复现方式多样(save ,bgsave, bgrewriteaof, scan 等等),第一次故障出现时,因为没有数据所以没法复现,而且bgsave都是失败的,主从也无法进行同步,数据迁移等等,所以排查起来非常麻烦。最后还是通过版本比对进行反推问题产生原因。C语言太妙了。
















 378
378











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









