






conda install nltk
import nltk
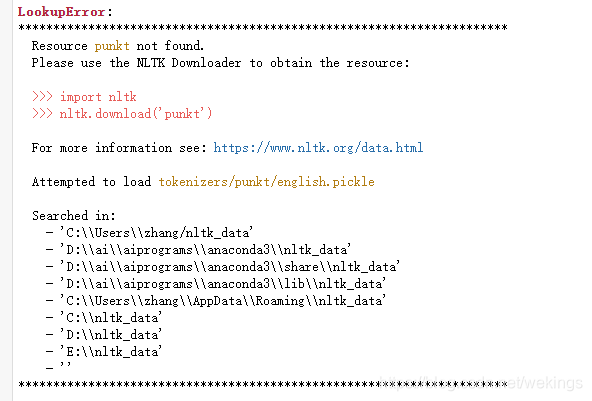
调用英文分词nltk.word_tokenize()时报错,原因是没有下载nltk的数据包,通过nltk.download()下载
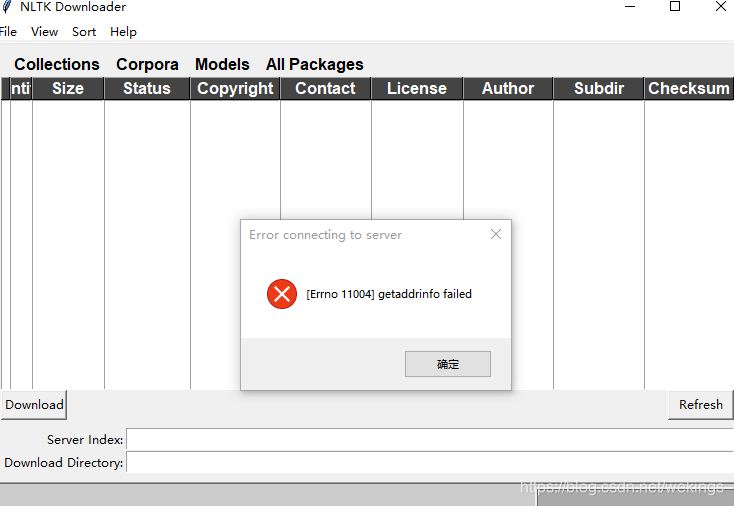
数据包下载失败,可以使用离线下载的方式解决:
https://github.com/nltk/nltk_data/tree/gh-pages
下载成功后得到nltk_data-gh-pages.zip,解压,并且将解压后的文件夹packages重命名为nltk_data,将此文件夹拷贝到nltk的搜索路径。
搜索路径是图一报错下显示的路径,也可通过以下方式查看搜索路径:
nltk.data.path

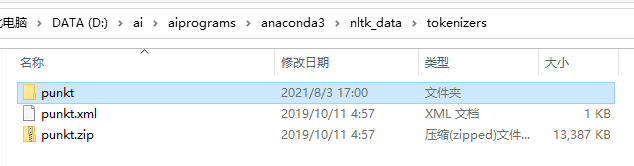
拷贝完成后,还要找到你需要的包的路径再进行解压,例如,我需要tokenizers下punkt的数据,将其解压,记得解压完成后将嵌套的那一层目录去掉呀,解压完成后就可以正常使用啦!

















 1858
1858

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









