







Hadoop介绍
引用:Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。Hadoop实现了一个分布式文件系统( Distributed File System),其中一个组件是HDFS(Hadoop Distributed File System)。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算 。
测试环境预览
节点浏览
hdfs界面:note1:9870
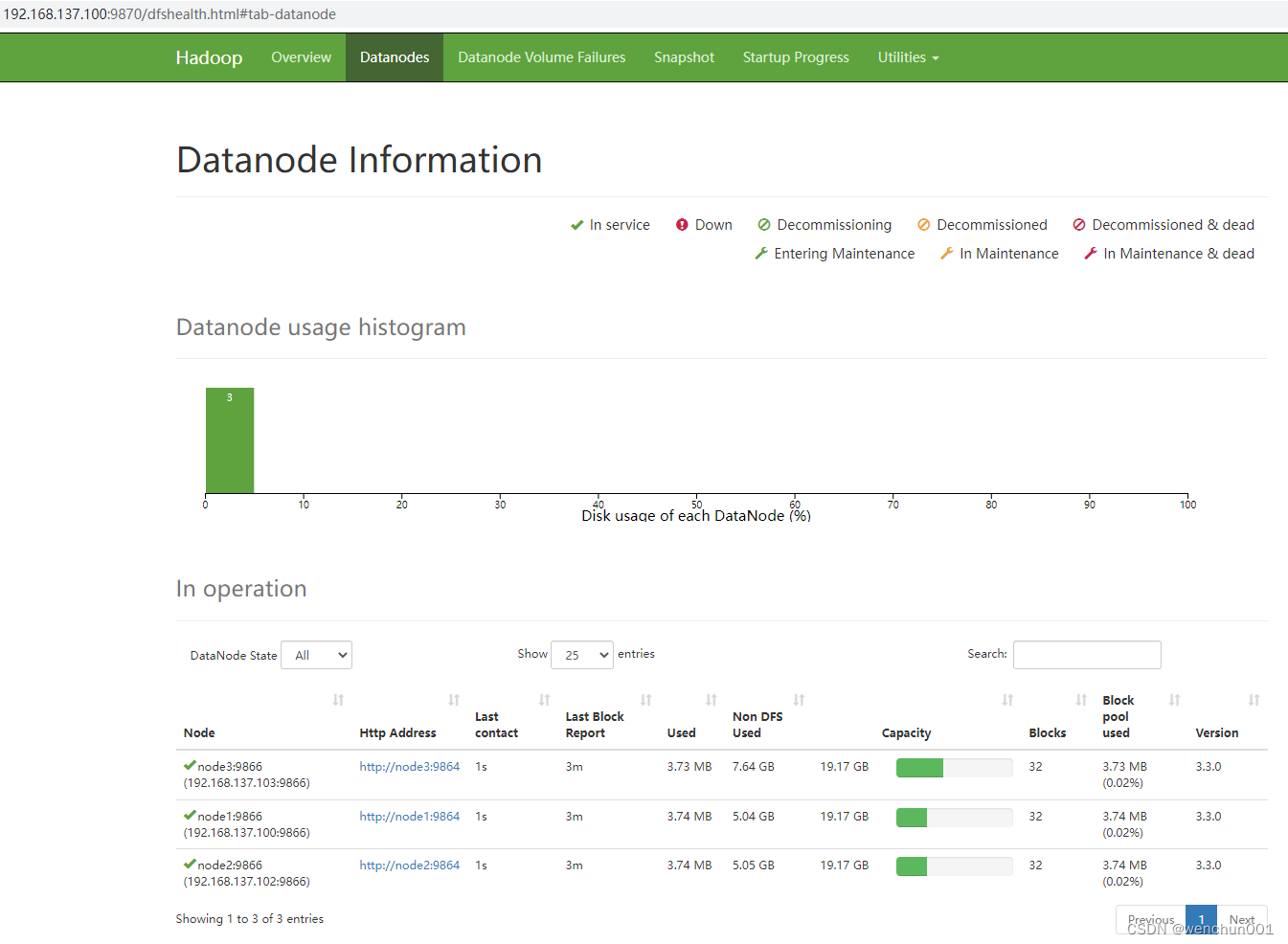
HDFS界面
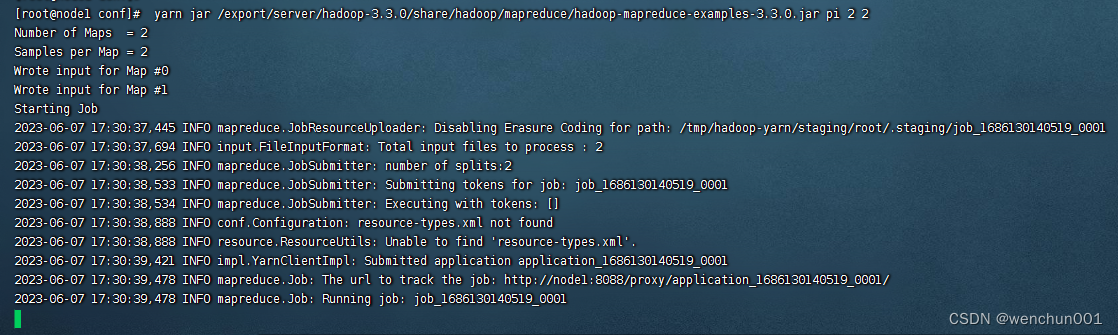
执行MR示例
yarn jar /export/server/hadoop-3.3.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar pi 2 2
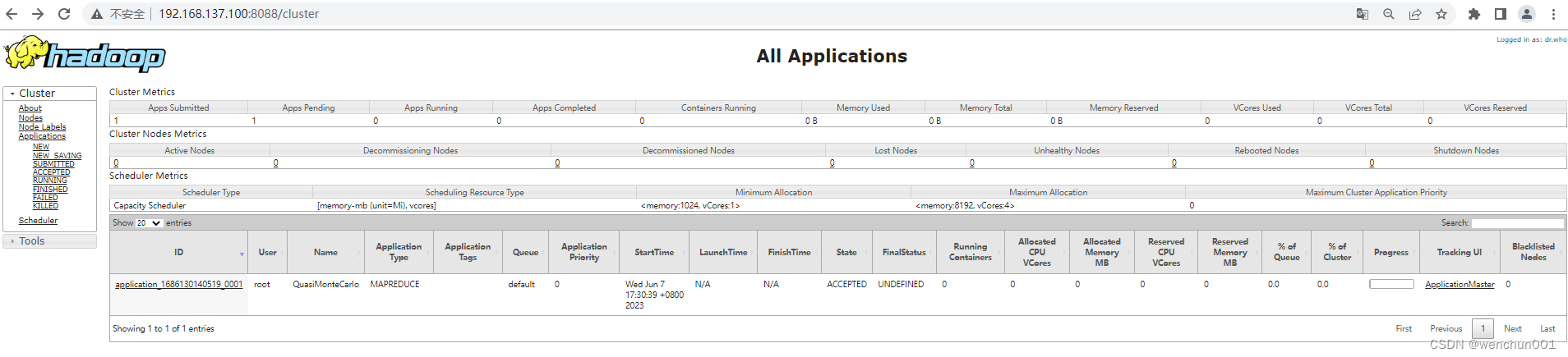
Hadoop界面
软件包
jdk_1.8
hadoop-3.3.0
zk(yarn集群高可用必备)
配置好的集群文件hadoop文件夹:https://download.csdn.net/download/wenchun001/87878810
服务器资源
3台虚拟机
vm,vbox都行,每台都改一下/etc/hosts
#vi /etc/hosts
192.168.137.100 node1
192.168.137.102 node2
192.168.137.103 node3
192.168.137.100 node1
192.168.137.102 node2
192.168.137.103 node3
配置信息
yarn-site.xml
[root@node2 src]# find / -name yarn-site.xml
/export/server/hadoop-3.3.0/share/hadoop/tools/sls/sample-conf/yarn-site.xml
/export/server/hadoop-3.3.0/etc/hadoop/yarn-site.xml
<?xml version="1.0"?>
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 配置内存,可能有问题 -->
<property><name>yarn.scheduler.maximum-allocation-mb</name><value>2048</value><discription>每个节点可用内存,单位MB,默认8182MB</discription></property><property><name>yarn.nodemanager.vmem-pmem-ratio</name><value>2.1</value></property><property><name>yarn.nodemanager.resource.memory-mb</name><value>2048</value></property>
<!-- -->
<!-- RM启用ha -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- yarnCluster 标识 -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yarnCluster</value>
</property>
<property>
<name>yarn.resourcemanager.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.ha.automatic-failover.embedded</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.connect.retry-interval.ms</name>
<value>2000</value>
</property>
<!-- 集器中rm的标识 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- rm1主机地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>node1</value>
</property>
<!-- rm2主机地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>node2</value>
</property>
<!-- rm1 WebUI地址 -->
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>node1:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>node2:8088</value>
</property>
<property>
<name>yarn.resourcemanager.address.rm1</name>
<value>node1:8032</value>
</property>
<property>
<name>yarn.resourcemanager.address.rm2</name>
<value>node2:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm1</name>
<value>node1:8030</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm2</name>
<value>node2:8030</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>node1:2189,node1:2182,node1:2183</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://node2:19888/jobhistory/logs</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
</property>
<!-- RM恢复重启机制 -->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<property>
<name>yarn.resourcemanager.zk.state-store.address</name>
<value>node1:2189,node1:2182,node1:2183</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!-- 选择调度器,默认容量 -->
<property>
<description>The class to use as the resource scheduler.</description>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value>
</property>
<!-- ResourceManager处理调度器请求的线程数量,默认50;如果提交的任务数大于50,可以增加该值,但是不能超过3台 * 4线程 = 12线程(去除其他应用程序实际不能超过8) -->
<property>
<description>Number of threads to handle scheduler interface.</description>
<name>yarn.resourcemanager.scheduler.client.thread-count</name>
<value>8</value>
</property>
<property>
<name>yarn.application.classpath</name>
<value>/export/server/hadoop-3.3.0/etc/hadoop:/export/server/hadoop-3.3.0/share/hadoop/common/lib/*:/export/server/hadoop-3.3.0/share/hadoop/common/*:/export/server/hadoop-3.3.0/share/hadoop/hdfs:/export/server/hadoop-3.3.0/share/hadoop/hdfs/lib/*:/export/server/hadoop-3.3.0/share/hadoop/hdfs/*:/export/server/hadoop-3.3.0/share/hadoop/mapreduce/*:/export/server/hadoop-3.3.0/share/hadoop/yarn:/export/server/hadoop-3.3.0/share/hadoop/yarn/lib/*:/export/server/hadoop-3.3.0/share/hadoop/yarn/*</value>
</property>
</configuration>
相关命令
关闭命令
# /export/server/hadoop-3.3.0/sbin/stop-all.sh
启动命令
# /export/server/hadoop-3.3.0/sbin/start-all.sh
启动RM
#yarn --daemon start resourcemanager
获取YARN集群状态
#yarn rmadmin -getAllServiceState

手动设置rm1不可用
#yarn rmadmin -transitionToStandby rm1 --forcemanual
手动设置rm2可用
#yarn rmadmin -transitionToActive rm2 --forcemanual
测试示例
计算圆周率
# yarn jar /export/server/hadoop-3.3.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar pi 2 2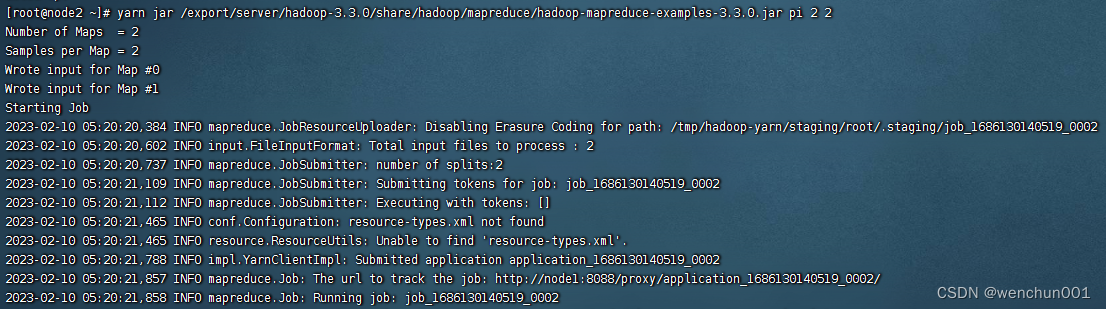
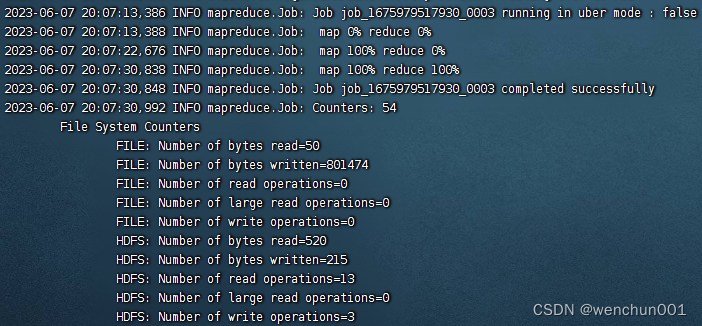
763 yarn jar /export/server/hadoop-3.3.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar wordcount input output
764 hadoop fs -rm -r output
765 yarn jar /export/server/hadoop-3.3.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar wordcount input output
766 hadoop fs -rm -r output
767 yarn jar /export/server/hadoop-3.3.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar wordcount input output
768 yarn jar /export/server/hadoop-3.3.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar pi 2 2
769 yarn jar /export/server/hadoop-3.3.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar pi 20 20
770 history
771 hadoop fs -ls
772 hadoop fs -cat output
773 hadoop fs -ls output
774 hadoop fs -cat output/part-r-0000
775 hadoop fs -cat output/_SUCCESS
776 hadoop fs -cat /user/root/output/_SUCCESS
777 hadoop fs -cat /user/root/output/*
778 hadoop fs -ls output
779 hadoop fs -cat /user/root/output/*
任务面板

















 413
413











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









