







Linux
常用
# scp -r ./software/* root@Master:/software/
远程传送到另一台机器,-r 是可以把文件夹也复制
$ stat file
可以查看access/modify/change
当执行了此文件后,access会更新时间。
modify文件时,会影响到这三个。
vi
:set nu
mongo 查看
pgrep mongo -l
netstat -lanp | grep “27017”
service mongod stop
service mongod start
运行jar
nohup java -jar xxx.jar &
查看防火墙状态:
systemctl status firewalld
查看某个端口是否被释放
firewall-cmd --query-port=xxxx/tcp
释放某个端口
firewall-cmd --add-port=xxxx/tcp --permanent
要重启:
service firewalld restart
disk use
du -sh : 查看当前目录总共占的容量。而不单独列出各子项占用的容量;
du -lh --max-depth=1 : 查看当前目录下一级子文件和子目录占用的磁盘容量;
vi
有时候需要查看一些日志文件,然后要从底部开始查看的话
可以按 shift+g 即可跳到文件底部
要返回文件顶部的时候 按 gg即可
port
查看端口使用,监听状态和相关pid
ss -lntpd | grep :22
pid
查看pid相关情况
ps -ef|grep pid
nohup

$ nohup ./xxx.sh &
learning
# type ifconfig 查看类型,会出现存储位置
# file /xxx/ifconfig 对文件的属性描述。 会看到 ELF 这是二进制的一种,可执行文件
# yum install man man-pages 安装manual帮助手册
linux只有能力启动二进制文件,但是
当shell中有#! /usr/bin/python 时,linux会先启动 /usr/bin/python 然后去读取shell脚本内容执行。
# echo $$ 查看当前pid
# ps -fe 查看所有进程信息, every formatted
# type echo 输出 echo is a shell builtin
# help echo 对于builtin的命令可以用help查看,
# help 会看到所有的builtin命令。查看内部命令。
# man:外部命令文档,用man
# echo $PATH 查看环境变量的配置。有了这个配置,type xxx 时才知道在哪里。
当在cli里任意输入字符后,内部命令之外的会看看Path中是否配置了外部。如果内外都没,则 command not found
# whereis 定位命令位置
# echo $LANG 查看编码格式
man:
1. 用户命令(/bin, /usr/bin, /usr/local/bin)
2. 系统调用
3. 库用户
4. 特殊文件(设备文件)
5. 文件格式(配置文件的语法)
6. 游戏
7. 杂项(mischellaneous)
8. 管理命令(/sbin, /usr/sbin, /usr/local/sbin)
# du -sh ./* 磁盘使用汇总
# umount /dev
# mount /dev/sda1 /boot 把/dev/sda1 挂载到 /boot ,会覆盖
Linux中一切皆文件,因此有IO流。
冯诺依曼体系中计算机5大组成:
计算器,控制器,存储器(内存),I,O。
IO包括:硬盘,网卡,U盘,鼠标。。。
Linux中一切皆文件,指的是:比如打印机,那么output就是指打印。
如果键盘是文件,那么linux从键盘拿到的应该是字符流,比如是utf8,因为拆开一个个字节没有意义了。这种不能拆分截取的是c。
而b 是block,硬盘属于b,可以用字节流读取,随便截取。
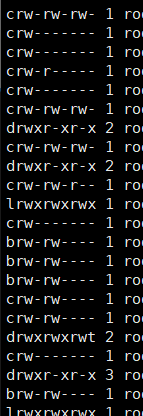 除了b,c 还有socket (s),pipe §
除了b,c 还有socket (s),pipe §
link (l)
# cd /proc 可以看到很多数字,每个进程也是一个目录,这个就是pid号
 fd 是 file descriptor
fd 是 file descriptor
蓝色的0: 标准输入
1:标准输出
2:报错误输出
通过一切皆文件的IO,可以O到其他文件里,“链接”的感觉。

蓝色框是:硬链接数量
红色root:此文件是谁的
黄色root:属于哪个group的
linux目录系统
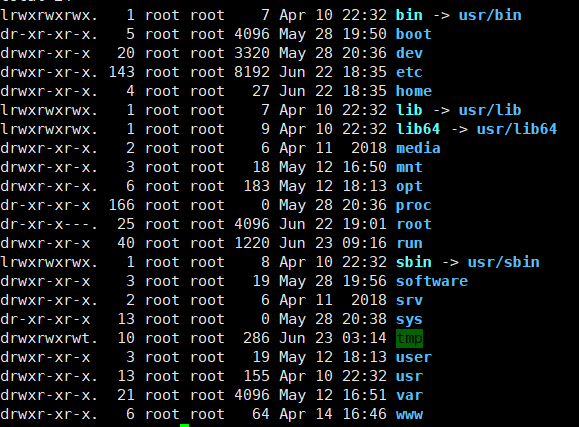
boot:引导程序的目录
dev:设备
bin, sbin: 放可执行程序
etc:配置文件放置
home:user的家目录
lib, lib64:放置扩展库。不能关门造车,使用三方库。
media, mnt: 挂载用的
usr:等价于windows 的 programm files
opt: 对比与usr,有些绿色三方,解压使用的。放置三方程序,比如oracle,
var: 放置程序产生的数据文件。当var目录很大时,比如日志很多时,可以把var单挂到其他硬盘上
proc:进程相关
# mount /dev/cdrom /mnt
# df -h 查看时,会看到多了个挂载条目
linux 文件系统操作命令
# cd 等价于 cd ~ 回家了
# cd - 可以回到上次cd的目录
# cd ~god 去/home/god 串门
# mkdir abc
# mkdir ./abc/a/b/c/ -p 每个子目录会递归创建,纵向的
# mkdir ./abc/a ./abc/a2 横向的多个目录
# mkdir ./abc/{x,y,z}dir 会创建 xdir, ydir, zdir
# rm -f file 强制删除,不会询问是否删除了
# rm -rf dir 递归删除目录里所有
# ln src aln 给src创建链接,这是硬链接。删除src后,硬链接依然可以使用。
# ln -s src aln 创建软链接。如同windows中的快捷方式
# ln -sfn src aln
-b 删除,覆盖以前建立的链接
-d 允许超级用户制作目录的硬链接
-f 强制执行
-i 交互模式,文件存在则提示用户是否覆盖
-n 把符号链接视为一般目录
-s 软链接(符号链接)
-v 显示详细的处理过程
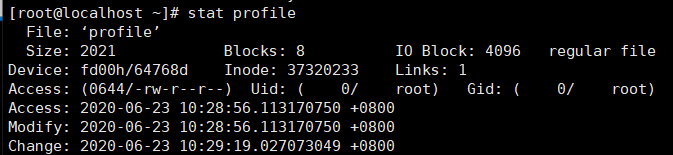
# stat file 可以查看file的元数据,即他的属性,是描述数据的数据。
# touch file, 当file存在时,会把 Access, Modify, Change 修改为一致的。用处:安全检查,防止被黑。
linux-文件预览命令-管道基本使用
# cat file 全量显示。查看文件内容,已经涉及到输入输出流了。
# more file 可以用sparse/b 控制上下翻页。但是当浏览到end时,会退出。优点:比less消耗资源少。
# less file 和more不同的是:到End时不会退出
# head -n file 查看输入流的前n行。当不写 -n 时,默认是前10行。
# tail -n file 查看后n行
问题:如何查看文件的中间几行呢?
答案:使用管道。
# head -10 file | tail -3 ,就可以查看file的 7-10行了。具体意思:把head显示的前10行,放到管道,然后tail拿管道里的流 再进行显示后3行。
有了管道,实现基于文本流的加工方式。
# ls -l /etc | more 使用管道可以对ls内容进行分屏。
管道本质:输出流 |输入流。即:前面的输出流,传给后面的。
# echo "/" | ls -l 是错的。ls没有IO功能
# echo "/" | xargs ls -l 这个可以。
# tail -f file 会阻塞查看file,即不会退出。有种实时查看的感觉。
# echo "content" 1>> file 当file有了新内容后,上面的tail 会实时查看到。其中写的1是output. 0/1/2 对应于 input/output/error
VI 编辑器使用
打开文件:
# vi file
# vi +n file 打开文件,并定位到第n行。
# vi + file 打开文件,并定位到最后一行。等价于打开文件后,shift g
# vi +/PATTERN 可以直接定位到匹配到Pattern的那行
关闭文件:
:q quit
:wq write and quit
:x 等价与 :wq
:q! quit force
:w write
:w! write force
ZZ 大写的ZZ,编辑模式下。:wq
全屏编辑器
模式:
- 编辑模式: 默认是编辑模式
- 输入模式(从编辑模式 到 输入模式):
- 当按了 i 后,进入 insert,是在光标前面输入,
- I,大写i, 在光标所在行头输入
- 按 a 后,是在光标后面输入。
- 按A后,在光标所在行尾输入。
- o: 小写的o,是在光标下面一行输入
- O:大小O,是在光标上面一行输入
- ESC:从输入模式或末行模式 到 编辑模式
- 末行模式(从编辑模式到末行模式):冒号 接受用户命令输入,有些高级功能
- :set nu 设置行号
- : set nonu 取消行号
编辑模式
移动光标:
- 字符:h/j/k/l : 左下上右
- 单词为单位,
- w 移动到下个单词首
- e:跳到当前或下一个单词的词尾
- b: begin of word
- 行内
- 0:绝对行首
- ^: 行首的第一个非空白字符
- $:绝对行尾
- 行间
- G:文章末尾
- gg:文章开头
- 3G: 其他行。
- 翻屏
- ctrl f 往下翻
- ctrl b 往上翻
- 删除&替换单个字符
- x: 删除光标位置字符
- 3x:删除光标开始的3个字符。
- 注意:命令都可以和数字组合。 - r:替换光标位置字符
- 删除命令:d
- dw 删除一个word
- dd 删除一行
- 4dd 删除光标开始的4行
- dG:从光标删除到末尾
- dgg: 从光标删除到头
- 复制粘贴,剪切
- yw
- yy:复制一行。和dd用法一样
- p,可以dd之后,再小p 粘贴。在所在光标的下面粘贴。
- P:在所在光标的上面粘贴。
- 撤销,重做
- u 撤销
- ctrl r 重做撤销的操作
- . 重复上一步的操作
末行模式
ESC之后,:
:set nu
:set nonu
:set readonly
/abc 可以查找abc,使用 n往下, N往上 找
:! ls -l /usr/local/bin 在末行模式下可以通过cli命令查看。就不用先退出VI 再操作cli命令了。
s查找并替换:
:1,$s/src/desc/
/ 临近s命令的第一个字符为边界字符: / @ #
需要指定范围从第1行到末尾$
:1,$s/src/desc/gi
g是一行内全部替换。当一行内有多个src时,每个src都会替代为dest。如果不加g,每行只对第一个src进行替代。
i是忽略大小写
范围:
- n 行号
- . 当前光标行
- +n 偏移n行
- $ 末尾行
- % 全文,相当于1,$
:.,+2d 一共删除3行,当前光标行以及往下2行。
:1,$-1d 删除第一行到倒数第2行。
linux grep和正则表达式
grep:查找
# grep "ex" profile 只显示文件中 含有ex的行
# grep -v "ex" file 反显,即把ex之外的行显示
为了实现更加精确的查找,使用正则。
注意区分:正则 和 模式匹配。
模式匹配如下:
ls -l a* 那么诸如 a,ab, abc都会匹配
ls -l a?, 问号是占位,只有诸如 ab, ac 才匹配
正则
分为 匹配操作符,重复操作符。
匹配操作符:
\ 转义字符
. 匹配任意单个字符
[1249a], [a-k], 字符序列单字符占位
[^12] 取反
^ 行首
$ 行尾
\<, \>: \<abc 单词首尾边界
| 连接操作符
(,) 选择操作符
\n 反向引用
重复操作符:
? 匹配0到1次
* 匹配0到多次
+ 匹配1到多次
{n} 匹配n次
{n,} 匹配n到多次
{n,m} 匹配n到m次
上面的黑色加粗的是 grep 认为的 正则,是可以被grep默认识别的。
其他的是扩展正则表达式,需要加\ 才能被grep识别,比如 \?, \+, \{, \}, \|, \(, \)
# grep "\<ooxx\>" file 找到单词ooxx
# grep "oo[0-9]\{4\}xx" a.txt 可以匹配到诸如 oo1234xx。
# grep "\(oo\)\(xx\).*\1\2" a.txt 此处通过小括号分组,再用\1 \2取
linux 文本数据操作 cut, sort, wc, sed, awk
cut 显示切割的行数据
-f 选择显示的列
-s 不显示没有分隔符的行
-d 自定义分隔符
cut -d ' ' -f1,2 file 没被切分的也会显示
cut -d ' ' -f1-3 file 显示第1到3列
cut -d ' ' -s -f1 file 只显示 被切分的
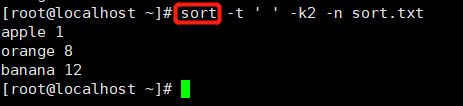
sort 排序文件的行
默认按照ascii排序,即11比8小。
-n 按数值排序
-r 倒序
-t 自定义分隔符
-k 选择排序列
-u 合并相同行
-f 忽略大小写
wc
wordcount
# cat file | wc -l
linux 文本数据操作 sed。行编辑器。
sed是行编辑器。很像宏。
类比于VI里的末行模式。
sed
-n 静默模式,不再默认显示模式空间中的内容
-i 直接修改原文件
-e SCRIPT 可以同时执行多个脚本
-f /PATH/TO/SED_SCRIPT
-r 表示使用扩展正则表达式
行编辑器 Command:
d 删除符合条件的行
p 显示符合条件的行
a 在指定的行后面追加新行,内容为string
\n 可以用于换行
i 在指定的行前面添加新行,内容为string
r FILE 将指定的行前面添加新行,内容为string
w FILE 将地址指定的范围内的行另存至指定的文件中
s/pattern/pattern/gi 查找并替换。s///, s###, s@@@
\(\),\1,\2
# sed "/apple/d" file 会把有apple的那行删除
awk 强大的文本分析工具
在之前的大数据工程师,awk是必须的。
当拿到很大大数据时,先采样做demo,对数据有初步了解。
- 相对于grep的查找,sed的编辑,awk在对数据分析并生成报告时,很强大。
- awk是把文件逐行的读入(很像spark的对record的处理),(空格,制表符)为默认分隔符,将每行切片,切开的部分再进行各种分析处理。
awk -F ‘{pattern + action}’ {filename}
- 支持自定义分隔符
- 支持正则表达式匹配
- 支持自定义变量、数组 a[1], a[tome], map(key) ,虽然是数组 但是有map的感觉
- 支持内置变量
- ARGC 命令行参数个数
- ARGV 命令行参数排列
- ENVIRON 支持队列中系统环境变量的使用
- FILENAME awk浏览的文件名
- FNR 浏览文件的记录数
- FS 设置输入域分隔符,等价于命令行 -F选项
- NF 浏览记录的域的个数
- NR 已读的记录数. number of row
- OFS 输出域分隔符
- ORS 输出记录分隔符
- RS 控制记录分隔符
- 支持函数
- print, split, substr, sub, gsub
- 支持流程控制语句,类C语言
- if, while, do/while, for, break, continue
# awk -F ':' '{ print $1 }' passwd 用冒号split,然后打印第一个。
# awk -F ':' 'BEGIN{print "name\tshell"} { print $1 "\t" $7 } END{print "end"}' passwd
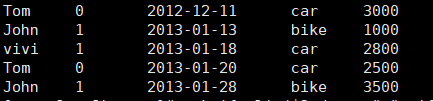
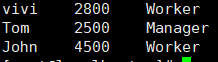
awk '{split($3,date, "-");
if(date[2]==01){name[$1]+= $5; if($2=="0"){role[$1]="Manager"}else{role[$1]="Worker"}}}
END{for(i in name){print i "\t" name[i] "\t" role[i] }}' awk.txt
注意:awk中 1-based index
拿到一月份的工资。数据如下:
 结果:
结果:
用户管理、权限管理
即使只有3个人的团队,也有等级。
不应直接用root操作。
平时都是用以普通用户身份操作,到需要时才su root.
只有用户是没有意义的,需要和权限绑定才行。
以下在 root 下操作,
# useradd lq01 新增用户
# passwd lq01 有反应后,再设置密码
# userdel -r user 删除用户,可以使用-r选项删除用户以及用户家目录和用户邮件
# userdel -f user 删除用户,如果user当前是登录状态,可以使用-f选项强制删除用户
需求:
当两个用户lq01,lq02之间有共享资源时,但对于第三人并不共享时,如何办?
解决:
# cd /
# mkdir lqshare
把lq01, lq02 放到一个group里,然后设置lqshare的 group权限。
# groupadd sharelqgroup 新建一个组
# id lq01 可以查看lq01相关的信息。uid / gid / groups
# usermod -a -G sharelqgroup lq01 把用户lq01 追加(-a)到 Group sharelqgroup里。
把创建的文件夹 lqshare,修改chown
# chown root:sharelqgroup lqshare
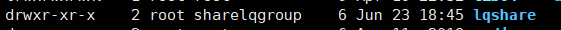 上图中可看到:组已经改变了。但是 group 的权限还没有改。
上图中可看到:组已经改变了。但是 group 的权限还没有改。
# chmod g+w lqshare/
# chmod o-rx lqshare/
# chmod 777 file
755 对于dir的默认
644 对于file的默认
奇数肯定有x权限。
查看有哪些group:
# cat /etc/group
权限管理本质:对文件、文件夹的管理
chown, chmod
Linux对包的管理
- 编译安装
- rpm
- yum
三者共存。
虽然编译安装麻烦,但是使用场景比如 对某个包进行手动精简,然后编译,在server上运行。
RPM安装
是已经编译完的了。
比如安装rpm包
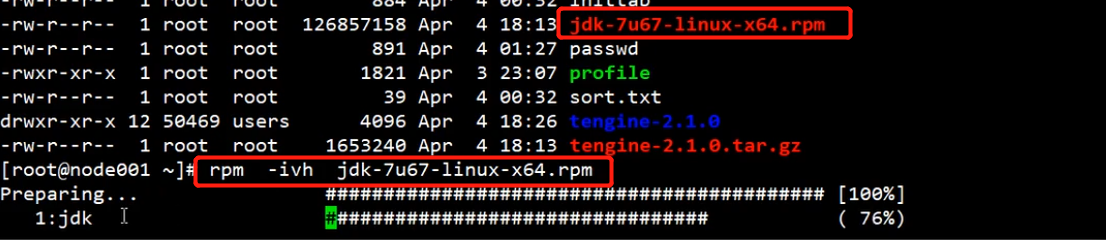
# rpm -qa 查询all信息
# rpm -ql python 查看指定包安装后生成的文件列表
# whereis ifconfig 可以知道是在 /sbin/ifconfig里
# rpm -qf /sbin/ifconfig 逆向思维,从命令找到是哪个包带来的

通过 -qf 就可以知道命令ifconfig是由 net-tools带来的。
卸载:
# rpm -e pkgname
rpm安装的不便之处
当有其他依赖时,必须手动安装。
由此引出yum

不用外网的repo,而是使用光盘里的软件 ------
P16视频I里
脚本编程 shell & linux kernel
和java编程不同,
脚本编程是命令的堆砌,一切皆命令,linux中一切皆文件。
# cat file1.txt
echo "hello world"
echo $$
echo $abc
运行脚本方式1:source 和 . 在本进程里
# abc=111 给abc赋值
# source file1.txt # source: Execute commands from a file in the current shell.注意是在当前进程里。
# . file1.txt 功能和source一样
方式2:bash。重开一个进程
# bash file1.txt 会重开一个进程,运行里面的命令
方式3:
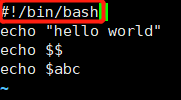 在文件里的首行,添加 #!/bin/bash 或 #!/bin/python 之后,该文件就会变成可执行程序了。
在文件里的首行,添加 #!/bin/bash 或 #!/bin/python 之后,该文件就会变成可执行程序了。
具体在运行该文件时,会先启动解释器,然后解释该文件每一行再执行
# chmod 755 file1.txt 增添x权限
# ./file1.txt 运行,会新开一个进程,然后读取每一行 执行
定义方法
文本流,重定向
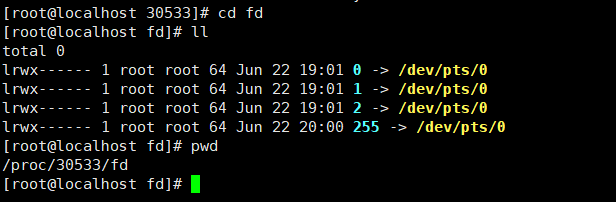
下图是:nginx进程的 fd(文件描述)文件夹
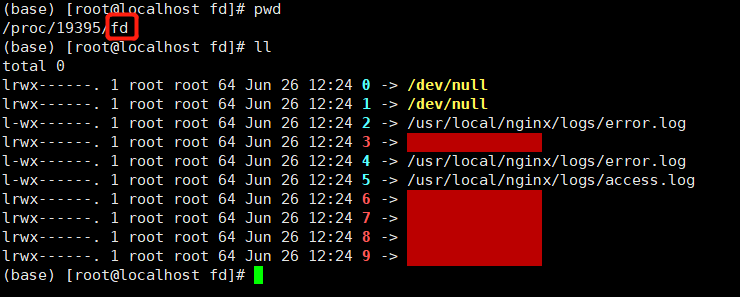 0/1/2 是I/O/Error流,这3个是基本的。
0/1/2 是I/O/Error流,这3个是基本的。
其他的都是流,多开启一个io就会多一个流。
# ll / 1> ls.txt 其中1是output,把流重定向到ls.txt文件。即把 ll /的结果输出到 ls.txt
上面这个 1> 是覆盖类型的命令,会把旧的覆盖。
# ls -l / 1>>ls.txt 是追加
>, >> 是重定向操作符
# ls -l /no 1>ls.txt 如果没有no目录的话,会报错,不应该用1.
# ls -l /no 2>ls.txt 使用2,对error信息进行重定向到文件
# ll / /god 1>ok.txt 2>error.txt 把正确的output输出到ok.txt,错误的输出到error.txt
# ll / /god 2>& 1 1>both.txt 把2指向1,再把1指向txt。
注意使用>&,因为1/2都是文件描述符,如果不写&,那么1会被当成文件名。
但是:上面的有问题
修改为:
# ll / /god 1>both.txt 2>& 1 因为有先后顺序,先把1指向文件,再把2指向1.
最终,1 2 的输出都定向到了 txt
简写方式:
# ll /god / >& both.txt 这是简写方式。把标准输出和error都输出到到文件。
# ll /god / &> both.txt 也可以
输入流0:
# read abc 0<<<"hello" 3个< ,把字符串输入到abc里。
# read abc 0<<ooxx 后面需要手动输入,但只有第一行的内容会被输入到abc里。因为read的原因,当遇到换行时,就停止了。
可以使用cat替代read。接收多行数据。
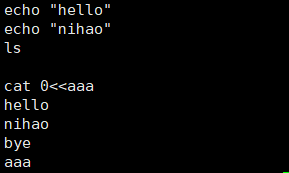
# cat 0< file 等价于 cat file
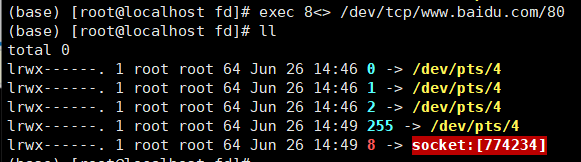
需求:把www.baidu.com主页显示到流里,不用浏览器,直接shell操作
# exec 8<> /dev/tcp/www.baidu.com/80 其中8是fd即文件描述符。
# cd /proc/$$/fd 查看
# echo -e "GET / HTTP/1.0\n" 1>&8 发送GET请求
# cat 0<&8 打印响应结果
Shell 变量
- 本地。当前shell拥有的。生命周期随shell。 name=god
- 局部。是在函数内部的。使用local定义。如果不用local,则会对函数外的变量有影响。
- 位置。 $1, $2, ${11}
- 特殊, $#, $?, $*, $@, $$. 注意 $BASHPID, 管道的父子进程
- $* 会把args当成一个字符串
- $@ 会把args进程拆分
- 环境变量。export 可以给子shell使用。
- 但是export并不是共享,父子进程之间不会相互影响,体现在:使用bash,开子线程修改这个变量的值时,并不会影响到父进程的这个变量值。同理,父进程修改这个var时,子进程也不会感知。
- 原理是fork()。
函数会对外部变量有影响:
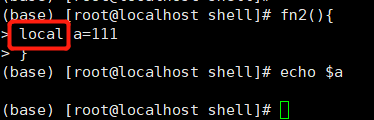
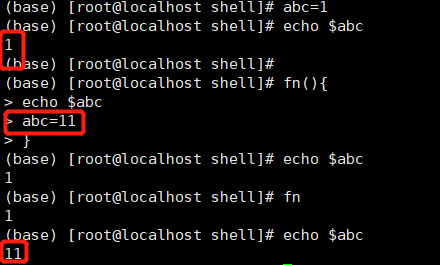 使用local在函数内定义局部变量:
使用local在函数内定义局部变量:
# abc=100
# vi file
echo $abc
# . file 输出100
# bash file 没有结果。因为bash会新开一个进程执行,而abc不在进程之间共享。
解决:
# export abc 导出变量,是的不同进程之间可以拿到。但这不是共享
# bash file 输出100
特殊变量
$# 位置参数个数
$* 参数列表,
$@ 参数列表
$$ 当前shell的PID
$? 取出上一个执行命令的exit code。0则success。非0则failed。
管道的父子进程
# abc=100
# echo $abc
# abc=200 | echo ok 会创建两个子进程,打通两个子。abc=200
这个行为是在子进程里做的,不影响父。
子进程的结果不能带给父。
# echo $abc 注意结果是100.不是200、
注意:
# echo $$ | cat 打印的是父进程的pid,因为$$ 优先级高于管道
# echo $BASHPID | cat。打印的是子进程的pid。
shell - 引用,命令替换
引用:
- 单引号 # echo ‘$abc’ 输出字符处$abc
- 双引号 # echo “$abc” 等同于 # echo $abc
- 花括号扩展不能被引用
- 命令执行前删除引用
命令替换的多种方式:
- 反引号 `ls -l /`
- $(ls -l /) 使用小括号
- 可以嵌套
# var01=`echo $abc` 命令替换
退出状态,逻辑判断
# echo $? 查看上一个命令的退出状态
&&
||
表达式
算数表达式
# let c=$a+$b
# c=$[$a+$b]
# c=$((a+b))
# c=`expr $a + $b` 注意空格需要
条件表达式
# test 3 -gt 2 && echo ok
# [ 3 -gt 2 ] && echo ok 注意空格必须
# help test 查看文档
练习题
- 添加用户
- 用户密码 同用户名
- 静默运行脚本
- 避免捕获用户接口
- 程序自定义输出
1 #!/bin/bash
2 [ ! $# -eq 1 ] && echo "args error" && exit 2
3 id $1 &> /dev/null && echo "user exists..." && exit 3
4
5
6 useradd $1 &> /dev/null && echo $1 | passwd --stdin $1 &> /dev/null && echo "user ad d ok" && exit 0
7
8 echo "error..." && exit 9
注意:
- 第2行,[] 是条件表达式
- 第6行里,意思:把$1内容作为密码输出流,输入到后面的passwd交给$1用户。
&> /dev/null指的是:对于1/2输出到/dev/null,而null如同黑洞,并不会存储资源也不能从中读取。 - 第8行作用,当因为权限问题创建不了user时,会error。
流程控制
shell里一切皆命令。
在分支里写的也是命令。
# if ls -l /abc >& /dev/null ; then echo "ok" ; else echo "bad"; fi
# for ((i=0; i<10; ++i)); do echo $i ; done
# for i in abc jkjk dafda ; do echo $i ; done
# for i in `seq 10`; do echo $i; done
# while ls -l god; do echo "ok"; rm -rf god ; done
练习题:找最大文件
- 用户给定路径
- 输出文件大小最大的文件
- 递归子目录
#!/bin/bash
oldIFS=$IFS
IFS=$'\n' #设置只用换行符split
for i in `du -a $1 | sort -rn` ; do # 这里有排序
echo $i
fileName=`echo $i | awk '{print $2}'`
if [ -f $fileName ]; then
echo $fileName #因为已经排序了,取第一个即可
exit 0
fi
done
IFS=$oldIFS # 还原
练习题:遍历文件
- 循环遍历文件每一行:流程控制语句
- 定义一个计数器num
- 打印num正好是文件行数
#!/bin/bash
oldIFS=$IFS
num=0
IFS=$'\n' # 使得只用换行符进行split。默认是换行、空格、t 都会
for i in `cat $1`; do
echo $i
((num++))
done
echo num:$num
IFS=$oldIFS
echo "--------------------------------"
lines=`cat $1 | wc -l`
for ((i=1; i<=lines; i++)) ;do
line=`head -$i $1 | tail -1`
echo $line
done
echo num:$lines
echo "---------------------------------"
num=0
while read line; do
echo $line
((num++))
done < $1 # 对while的输入,只读取文件一次。每次循环read一行
echo num:$num
echo "------------------------------"
num=0
cat $1 | ( while read line; do # 使用管道。输出流 到 输入流
echo $line
((num++))
done
echo num:$num ) # 使用小括号,会新开一个子进程运行
echo "------------------------------"
num=0
cat $1 | { while read line; do # 使用管道。输出流 到 输入流
echo $line
((num++))
done
echo num:$num ;} # 使用大括号,会在当前子进程里运行
总结
Linux中一切皆命令。
命令分成:
- 内部命令,比如 help
- 外部命令
- 配置Path的目录里的 可执行程序
- 脚本。自己写的 #!/bin/bash
- 函数方法
# echo $abc
# echo ${abc} 准确的做法是这个
# touch a.txt mv a.txt a2.txt 连续写即可,多个命令按照顺序执行
# touch a.txt & 后台运行
7步扩展
- 花括号 # mkdir -p abc/{a,b,c}jkjkj
- 波浪线 cd ~god
- 变量&参数 $, $$, ${}
- 命令替换 $ ls -l `echo $path`
- 算术扩展 num=$((3+4))
- word拆分, $IFS
- 路径 * (零到多个任意字符)
- 引用删除 # echo “hello”,会把双引号删除
*, 重定向>
# man bash 查看帮助文档















 12万+
12万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









