







问题背景
uftmdb_tools在支持解析不连续的redo日志后,发现解析的速度变得很慢。
如下图是对150+M的redo进行解析时,耗时5分钟多还没解析完

问题分析
使用pstack查看进程的位置,发现连续很多次都是停留在该位置。
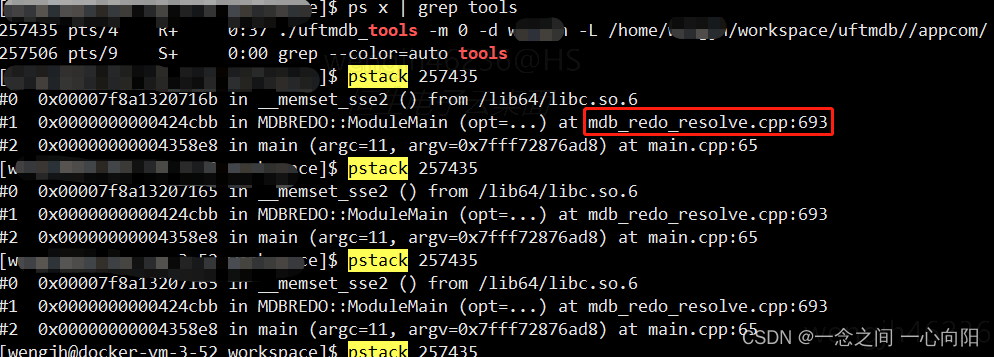
查看代码发现,该位置是对内存进行memset

底层原因
在底层实现上,memset 通常使用汇编指令或内存操作函数来进行内存填充操作。具体实现方式可能根据不同的编译器、体系结构和操作系统的实现而有所不同。
一种常见的实现方式是使用循环来逐个字节地对内存赋值。例如,以下是 memset 的简化实现示例:
void *memset(void *s, int c, size_t n) {
unsigned char *p = s;
for (size_t i = 0; i < n; i++) {
*p++ = (unsigned char)c;
}
return s;
}
在上述示例中, memset 函数使用指针 p 将传入的目标内存区域 s 强制转换为 unsigned char 类型的指针。然后使用循环来逐个字节地将指定的值 c 写入内存地址,直到达到填充的长度 n。
因此,加上一个对1M空间的memset,实际上执行了 1M 次的循环。
结论
memset底层是一个循环,因此执行的时间复杂度不是O(1),而是与空间大小成正比的 O(N) 的复杂度















 532
532











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









