







MapReduce的编程模型
如何使用MapReduce使用集群处理几百GB的问文件数据?
首先将数据放到HDFS文件系统中(被均分到不同的节点中),然后使用map操作,则每一个数据节点就会对本地的数据进行计算得到(key, value)的值,这样数据就能够被处理。然后通过shuffle操作(先进行排序,然后合并相同的key后形成的结果value用list表示,使用shuffle是为了减少通信连),最后进行reduce操作,通过网络将上述结果进行汇总然后合并相同的key中的值,并形成一个大的数据表。这样可以根据程序要求的目的取出最大值等。最后的数据可以再重新放到HDFS中,将数据分散到不同的节点中。
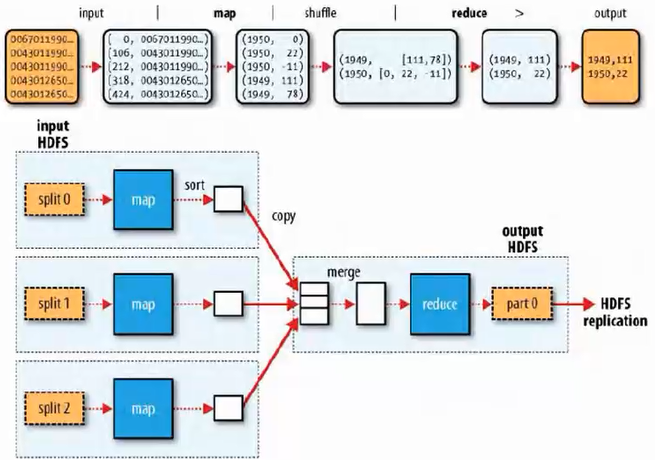
reducer可以有多个,也可以没有。一个作业可以包含多个任务,一个任务就是一个reduce操作。
性能调优
1. 究竟需要多少个reducer;
2. 输入:大文件优于小文件
3. 减少网络传输:压缩map的输出,去掉不需要的数据。
4. 优化每个节点能运行的任务数:mapred.tasktracker.map.tasks.maximum和mapred.tasktracker.reduce.tasks.maximum(缺省值均为2)
MapReduce的工作机制
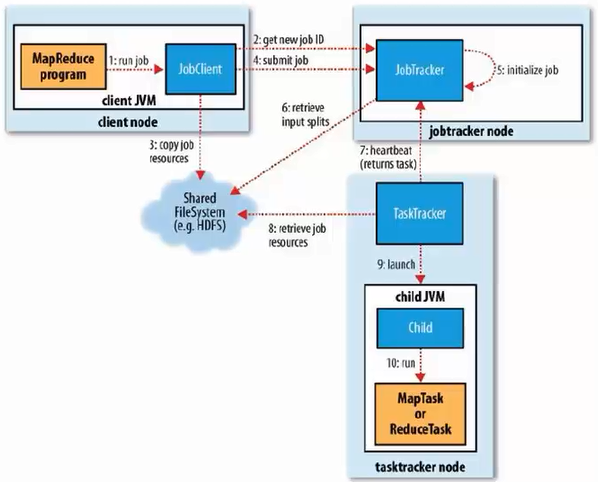
在Jobtracker中的调度机制是FIFC作业调度,同时还支持公平调度器,容量调度器。
任务执行优化

事实上不是java程序运行慢, 而是由于JVM启动需要许多时间。并且需要解释执行,因此速度回变慢。因此如果能够重用JVM将能够提高运行的效率。
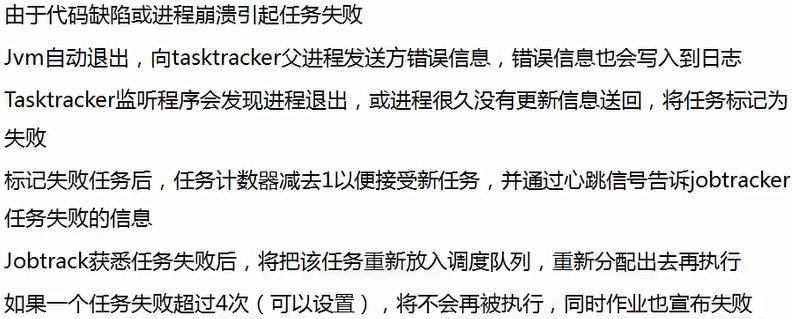
错误处理机制:
1. 硬件故障

后面两点说明:
2. 任务失败
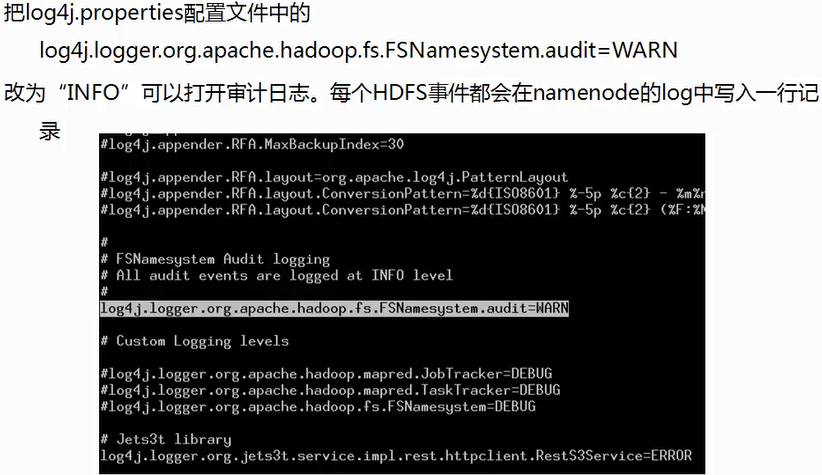
Hadoop审计日志
修改后需要重启hadoop
第三方工具运维hadoop















09-02
 267
267
267
07-16
238
238
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









