






mysql索引
索引诞生的背景是数据随着用户的使用,数据不断积累,到了一定的量之后,对于数据的查询会变慢直到无法满足需求的程度。
本篇内容以介绍mysql的索引,本文章的排序规则都是从小到大
mysql索引的数据结构使用的是B+树这种数据结构来存储
B+树的发明也是基于B树、平衡二叉查找树、二叉树、树这一系列更基础的数据结构而来
树
树是由n(n>=1)个有限结点组成一个具有层次关系的集合
下图是一个典型的树结构的图

树有且只有一个根节点
二叉树
二叉树是n个有限元素的集合,该集合或者为空、或者由一个称为根(root)的元素及两个不相交的、被分别称为左子树和右子树的二叉树组成,是有序树。
假如初始数据为,【3,6,9,2,7】,使用二叉树表示如下图

如果查询值为9的元素,只需查询3次。
此时如果再插入13,则变成如下

如果查询值为13的元素,需查询4次。
再插入27,则树的变成如下图

如果查询值为25的元素,需查询5次。
由此可以看出,二叉树的查询复杂度会随着树的高度变化而变化,如果数据极端的情况下,长度为N的数据,会形成一个高度为N的树,那么查询的复杂度会变成O(n),由此发明了平衡二叉查找树。
平衡二叉查找树
平衡二叉搜索树是一种结构平衡的二叉搜索树,即叶节点高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。
上面的数据【2、3、6、7、9、13、25】用平衡二叉查找树可表示为下图

可以看出平衡二叉查找树能够使树的高度动态调整达到平衡的状态,而且中序遍历可以输出一个顺序的结果。平衡二叉查找树的查询复杂度也就是树的高度,假如N个数据的可以形成一个高度为logN的平衡二叉查找树,所以平衡二叉查找树的查询复杂度是O(logN),比如一个100,000,000的数据,其高度约等于26,如果数据库使用平衡二叉树查询作为索引的话,仅仅对比索引都需要26次,显然不符合需求。这时考虑到B树,下面我们看看B树
B树
B树属于多叉树又名平衡多路查找树,且会包含指向对应大小范围的指针,简单点理解是每个节点可以有多个子节点,其子节点存放数据
我们将【2、3、6、7、9、13、25】构造成B树,如下图

B树的增、删、改都会引起结构的变化,其变化规则如下
- 排序方式:所有节点关键字是按递增次序排列,并遵循左小右大原则;
- 子节点数:非叶节点的子节点数>1,且<=M ,且M>=2,空树除外(注:M阶代表一个树节点最多有多少个查找路径,M=M路,当M=2则是2叉树,M=3则是3叉);
- 关键字数:枝节点的关键字数量大于等于ceil(m/2)-1个且小于等于M-1个(注:ceil()是个朝正无穷方向取整的函数 如ceil(1.1)结果为2);
- 所有叶子节点均在同一层、叶子节点除了包含了关键字和关键字记录的指针外也有指向其子节点的指针只不过其指针地址都为null对应下图最后一层节点的空格子;
下面我们看插入的影响,这里我们一4阶B树为例子
下面我们插入10,变化如下

继续插入11,则变化如下

插入18,变化如下
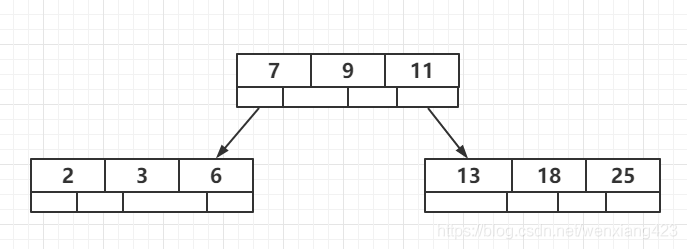
同理我们可以推出修改和删除情况下的构建逻辑,以上我们可以看出M阶B树的构建逻辑
由于B树的特性,子节点可存储索引,所以B树的查询次数每次是不固定的,最大为树的高度。
B树的优势
- 相对于B+树只有叶子节点才能存储索引,B树子节点可以存储索引,所以可以节省一定的空间
- 相对于平衡二叉查找树,每个子节点最多能有M-1个子节点,这样大大减少了树的高度,减少了查询需要的次数
B树的劣势
- 相对于B+树B树每次查询的次数不固定,最大为树的高度
- B树在范围查询的时候需要逐个查询,而B+树则可以通过最大最小值来查询范围,以此更好的支撑范围查找
接下来我们来介绍B+树
B+树
B+树是一种树数据结构,通常用于数据库和操作系统的文件系统中。B+树的特点是能够保持数据稳定有序,其插入与修改拥有较稳定的对数时间复杂度
B+树构建的规则如下
- B+跟B树不同B+树的非叶子节点不保存关键字记录的指针,只进行数据索引,这样使得B+树每个非叶子节点所能保存的关键字大大增加;
- B+树叶子节点保存了父节点的所有关键字记录的指针,所有数据地址必须要到叶子节点才能获取到。所以每次数据查询的次数都一样;
- B+树叶子节点的关键字从小到大有序排列,左边结尾数据都会保存右边节点开始数据的指针。
- 非叶子节点的子节点数=关键字数(来源百度百科)(根据各种资料 这里有两种算法的实现方式,另一种为非叶节点的关键字数=子节点数-1(来源维基百科),虽然他们数据排列结构不一样,但其原理还是一样的Mysql 的B+树是用第一种方式实现);
以4阶B+树构建一个组数据,初始如【2、3、6、7、9、11、13、18、25】,如图

此时插入12,变化如下
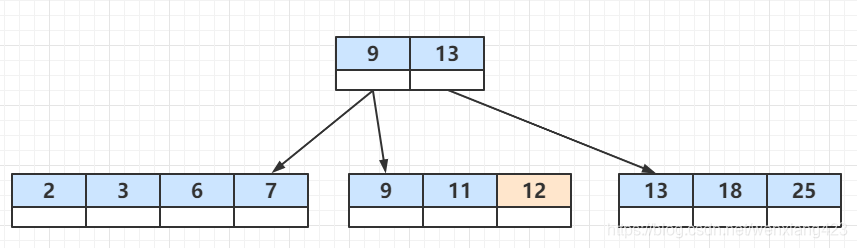
插入14,变化如下

插入10,变化如下

插入15,变化如下

同理我们可以推出删除和修改情况下树的变动情况
插入5,变化如下

插入16,变化如下

插入17,变化如下

由此我们知道B+树的优势和劣势
优势
- B+树的层级更少:相较于B树B+每个非叶子节点存储的关键字数更多,树的层级更少所以查询数据更快;
- B+树查询速度更稳定:B+所有关键字数据地址都存在叶子节点上,所以每次查找的次数都相同所以查询速度要比B树更稳定;
- B+树天然具备排序功能:B+树所有的叶子节点数据构成了一个有序链表,在查询大小区间的数据时候更方便,数据紧密性很高,缓存的命中率也会比B树高。
- B+树全节点遍历更快:B+树遍历整棵树只需要遍历所有的叶子节点即可,,而不需要像B树一样需要对每一层进行遍历,这有利于数据库做全表扫描。
上面已经对一些常见的树进行了介绍,而我们现在讨论的MySql索引使用的数据结构也就是B+树
MySql中使用B+树存储索引的形式如下

里面的数据库data指向具体的数据行
索引分为单列索引、复合索引和覆盖索引
单列索引
单列索引的数据插入修改更新,对数据结构的影响如上面B+树数据图
复合索引
以两列复合索引为例更多列的以此类推,复合索引需符合最左匹配原则
举例复合索引(A,B),展示在一个为4阶B+树的行为,插入(7,9),(4,11),(3,6),(10,22),(18,33),(13,1)
变化如图

插入(10,18),变化如图

插入(13,4),变化如下

插入(11,34),变化如下

插入(14,6),变化如下

插入(15,8),变化如下

插入(16,6),变化如下

插入(17,7)变化如下

由上可以类推复合索引的改查对于其结构的影响
索引的使用
我们创建一个测试表如下
create table t(
a int ,
b int ,
c int ,
key `idx_a` (`a`) using btree,
key `idx_a_b` (`a`,`b`) using btree
)ENGINE=INNODB;
这里我们创建了一个单列索引idx_a和一个复合索引idx_a_b,
1.通过单列索引来查询数据,select * from t where a = xx;
2.通过复合索引来查询数据,select * from t where a = xx and b = xx;
避免索引失效的情况
1.使用索引的时候尽量不去对索引进行函数运算,比如
比如:select * from t where a+1 = xxx
2.使用复合索引的时候尽量按其顺序来
比如:select * from t where b = xxx and a = xxx
3.使用or会引起索引失效
比如:select * from t where a = xx or b = xx
覆盖索引
如果查询的数据被包含在where条件的索引中,则不需要回表查询数据,减少了io的次数,加快了查询的速度
比如:select a from t where a = xxx 或者 select a,b from t where a = xx and b = xxx
总结
索引带来的好处
- 极大的加快了查询的速度
影响
- 索引需要一定的存储空间和内存
- 插入修改删除数据的时候,会更新索引数据的结构,导致插入修改删除操作变慢














 103
103











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









