







前言
在软件开发的世界里,遇到各种奇奇怪怪的bug是在所难免的。今天,我就遭遇了一个看似简单实则棘手的问题——用户反馈账号无法登录,系统一直提示“账号不存在”。一番抽丝剥茧后,我发现问题竟然出在一个不起眼的字符上:ⅰ与i的混淆。下面,我将详细记录这次bug的发现、排查过程及最终解决方案,希望能给同行们一些启示。
问题背景
用户通过客户端输入账号信息尝试登录,但系统反复提示账号不存在。初步检查时,一切看似正常:数据库查询逻辑无误,账号字段的唯一性约束也正确设置,用户的输入也没有明显的格式错误。然而,问题就隐藏在这不显眼的细节之中。
排查过程
- 复现问题:首先尝试复现用户的操作,使用相同的账号信息登录,结果一致,确实无法登录。
- 日志审查:查看登录失败时的日志记录,注意到系统记录的账号与用户提供的完全一致,但依然查询失败。
- 数据比对:直接在数据库中查询该账号,发现数据库中确实存在该记录。这让我开始怀疑,是否是字符编码的问题。
- 字符编码检查:使用字符编码检测工具仔细对比用户输入的账号与数据库中的账号,终于发现了差异:用户输入的账号中包含的是一个看似普通“i”,实则是Unicode字符“ⅰ”(Unicode编码U+2170),而数据库中存储的是ASCII字符“i”(ASCII编码73)。这两个字符在外形上几乎难以区分,但在计算机处理时却是完全不同的字符。
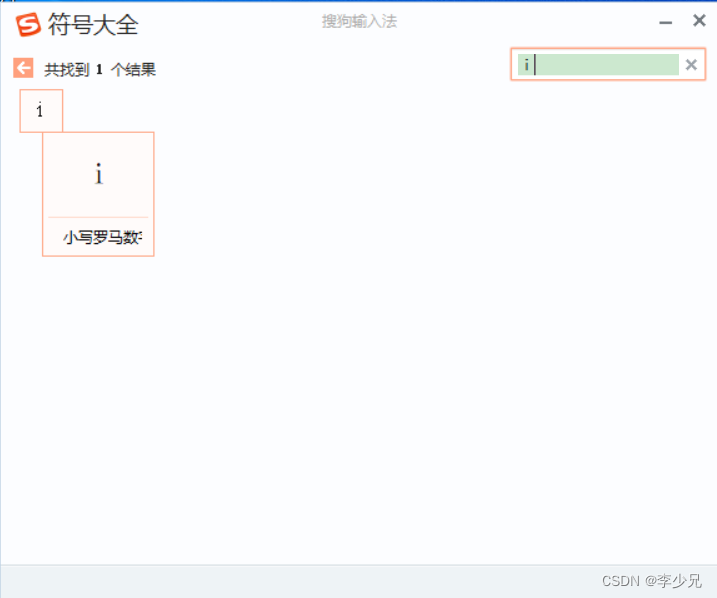
问题解析
这个问题的根本在于不同字符编码的误解。在某些文本编辑器或输入法中,用户可能不经意间输入了特殊编码的字符,而这些字符虽然视觉上与常见字符相似,但在计算机内部处理时却遵循不同的编码规则。当系统按照预期的编码(如ASCII)去数据库查询时,自然找不到用其他编码(如Unicode全角字符)存储的数据,从而导致了“账号不存在”的错误提示。
解决方案
- 字符规范化:在用户输入时进行字符规范化处理,将所有可能引起混淆的字符统一转换为标准ASCII或Unicode编码。可以使用编程语言提供的字符串处理函数,如Python中的
unicodedata.normalize(),将字符转换为标准形式。 - 前端验证:在前端增加输入验证,对于账号这类关键信息,可以限制只接受标准ASCII字符,或者在用户输入时即时替换掉非预期的字符,减少后台处理的复杂度。
- 用户教育:虽然这不是直接的技术解决方案,但可以通过用户指南或提示信息,告知用户避免使用特殊字符输入,以预防此类问题的发生。
总结
这次经历提醒我们,在处理用户输入时,字符编码的差异不容忽视。即使是最不起眼的一个字符,也可能成为阻碍程序正常运行的“隐形障碍”。通过加强输入验证、字符规范化处理,以及适时的用户引导,可以有效减少此类问题的发生,提升系统的稳定性和用户体验。在软件开发的道路上,每一个小bug都是成长的阶梯,让我们在解决问题中不断前行。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









