







 本文介绍了Pearson相关系数的概念及其在协同过滤推荐系统中的应用,包括基于用户和基于物品的推荐方法,并讨论了Pearson系数的优点与局限。
本文介绍了Pearson相关系数的概念及其在协同过滤推荐系统中的应用,包括基于用户和基于物品的推荐方法,并讨论了Pearson系数的优点与局限。


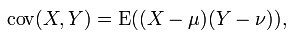

纯粹的协同方法的输入数据只有给定的user-item的评分矩阵,输出数据通常有下列类型:
1)标识当前user对于item喜欢或是不喜欢程度的预测数据
2)n项推荐item的列表,这是topN的列表,当前user购买过的item不会在此列表内
下面说说user-based nearest neighbor recommendation.
基于user的最近邻推荐的基本思想是:
1)给定一个user-item构成的评分矩阵,找出与当前user在过去有相似偏好的其他用户,也就是找近邻的过程
2)对于当前user没有见过的item,利用user的近邻对item的历史评分来计算user对item的偏好程度的预测值
上述思想的隐含假设是:
1)假如user间过去有相似的偏好,那么这些user将来也会有相似的偏好
2)user对item的偏好不会随时间而变化
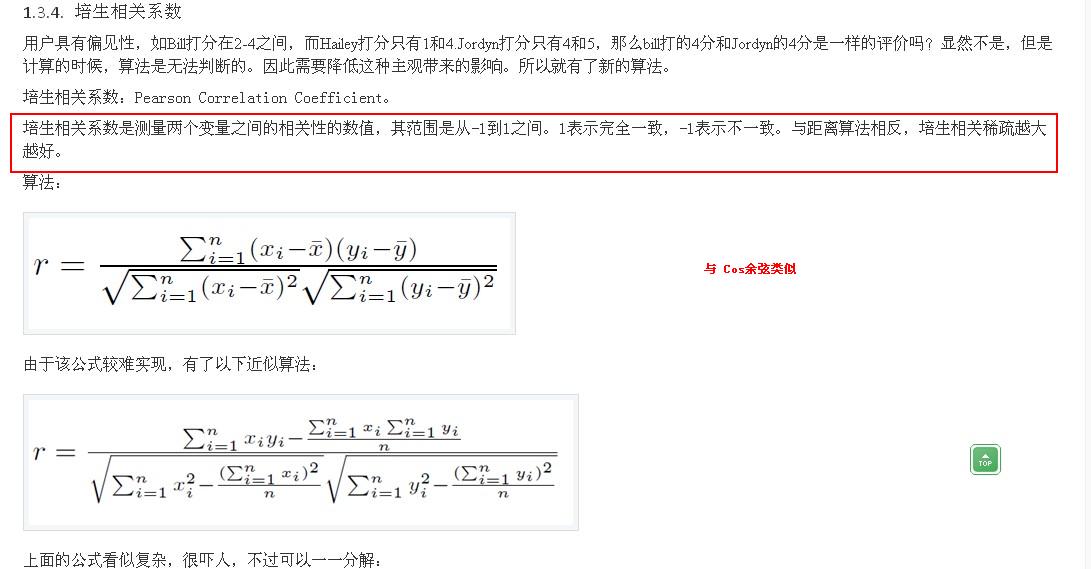
至于如何确定相似user set,推荐系统中常用的方法是Pearson相关系数。
Pearson相关系数取值从强正相关(+1)到强负相关(-1)。
Pearson方法充分考虑到了user对item的评分标准并不相同,有些user喜欢只给item高分,而另一些user从不任何item满分。同时,Pearson相关系数在计算中未考虑user对item偏好评分的平均值的差异使得user可比,也就是说即使两个user对item偏好的绝对评分值完全不同,但仍然可以发现user对item的评分值之间相当明显的线性相关性,进而得出两个user相似的结论。【Pearson系数对绝对数值不敏感】
在实际应用中,评分数据集通常非常大,而且包括了成千上万甚至百万级的user和item,这就要求必须考虑时间复杂度。此外,评分矩阵通常非常稀疏,每个user只对所有有效item的非常小的一个子集评分。还需要考虑给新的user推荐什么item,该如何处理没有评分的新item。
除了Pearson相关系数衡量user间的相似度,改进的余弦相似度、Spearman秩相关系数、均方差等也能用于计算user间的相似度。
但是实验分析显示,对于user-based推荐系统来说,Pearson相关系数比其它对比方法更胜一筹。但是Pearson方法发现近邻以及为这些近邻的评分赋权可能还不是最好的选择。
比如,很多领域会有一些所有user都会喜欢的item,让两个user对有争议的item达成共识会比对广受欢迎的item达成共识更有价值,但Pearson这样的相似度方法无法将这种情况考虑在内。当然IUF和方差权重因子等可以解决这样的问题。
另外,对于近邻评分的预测方法在遇到当前user只为非常少的共同item评分时会出错,导致不准确的预测。重要性赋权和样本扩展等方法都在探索此类问题的解决。
在user近邻选择时不用考虑use的所有近邻。为了减少计算与测试时的时间复杂度,只包括了那些与当前user有正向关联的user。降低近邻集合规模的通常方法是为user相似度定义一个具体的最小阈值,或者将规模大小限制为一个固定值,而且只考虑k近邻。当然相似度阈值过高,近邻规模就会很少,也就降低了覆盖率。如果太低,近邻规模就不会显著降低。对于k近邻,k太高,太多只有有限相似度的近邻会给预测带来额外的“噪声”;k太小,预测质量会受到负面影响。对MovieLens数据集的分析发现:在大多数情况下,20-50个近邻比较合理。
三 浅述协同过滤之基于物品的最近邻推荐
在很多领域都使用了user-based CF的方法。但是user-based CF的方法也存在问题。
item-based CF的主要思想是基于用户的历史数据来计算物品的相似度,利用物品间的相似度取代用户间的相似度进行推荐,然后把和用户偏好的物品非常相似的物品推荐给用户。
1)基于余弦的相似度计算,通过计算两个向量之间的夹角余弦值来计算物品之间的相似度,计算公式如下:
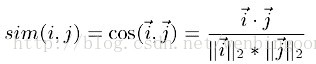
其中,分子为两个向量的内积,即两个向量相同位置的数字相乘。分母是两个向量的欧式长度的乘积,即向量自身点积的平方根的乘积。计算得到的相似度取值介于0和1之间,越接近于1表示两个物品越相似。这种基本的余弦相似度的计算方法并没有考虑用户评分平均值的差异,用户打分起点有差异。
2)基于关联的相似度计算,计算两个向量之间的Pearson-r关联度,计算公式如下:
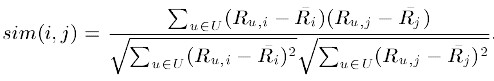
其中![]() 表示用户u对物品i的打分,
表示用户u对物品i的打分,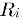 表示第i个物品打分的平均值。。
表示第i个物品打分的平均值。。
3)调整的余弦相似度计算,以为基于余弦的相似度计算方法未考虑用户的差异性打分情况,有些用户偏倾向于打高分,而有些用户倾向于打低分,在计算相似度时通过减去用户各种打分的均值以消除不同用户打分起点的影响,公式如下:
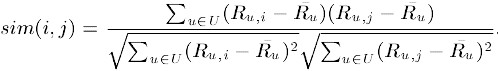
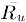 表示用户u打分的均值。相应地,改进的余弦方法的取值在-1和+1之间,就像pearson方法一样。
表示用户u打分的均值。相应地,改进的余弦方法的取值在-1和+1之间,就像pearson方法一样。
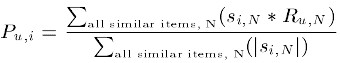
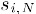 为物品i与物品N的相似度,
为物品i与物品N的相似度,
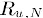 为用户u对物品N的打分。这种方法会有一个问题:不同用户的打分习惯会有差异,有的倾向于打高分,有的倾向于打低分,这就导致不同用户对喜欢的相同物品给分不会相同。使用余弦相似度计算时,欧式距离就会很大,但事实是相似度本应很高。在这种情况下使用用户原始的相似物品打分值进行计算会严重影响实际的预测结果。
,而是通过线性回归的方式重新估算新的
值,然后依然使用上面的方法进行预测。重新计算
的方法如下:
为用户u对物品N的打分。这种方法会有一个问题:不同用户的打分习惯会有差异,有的倾向于打高分,有的倾向于打低分,这就导致不同用户对喜欢的相同物品给分不会相同。使用余弦相似度计算时,欧式距离就会很大,但事实是相似度本应很高。在这种情况下使用用户原始的相似物品打分值进行计算会严重影响实际的预测结果。
,而是通过线性回归的方式重新估算新的
值,然后依然使用上面的方法进行预测。重新计算
的方法如下:
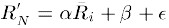
 和
和
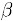 通过对物品N和i的打分向量进行线性回归计算得到,
通过对物品N和i的打分向量进行线性回归计算得到,
 为回归模型的误差。
为回归模型的误差。
传统基于用户协同过滤的问题是,算法不能很好的适应大规模用户和物品的数据。给定M个用户和N个物品,在最坏的情况下,必须评估最多包含这N个物品的所有M个用户的记录。在实际情况下,由于大多数用户只评分或购买了非常少量的物品,实际复杂度非常低。尽管如此,当用户的数据M打到几百万是,线上环境要求必须在极端事件内返回结果时,实时计算预测值仍不可行。
参考:
http://www.xiutx.cn/


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









