






在介绍TreeMap和TraaSet之前我们先来介绍一下Map和Set这样便于大家后续理解。
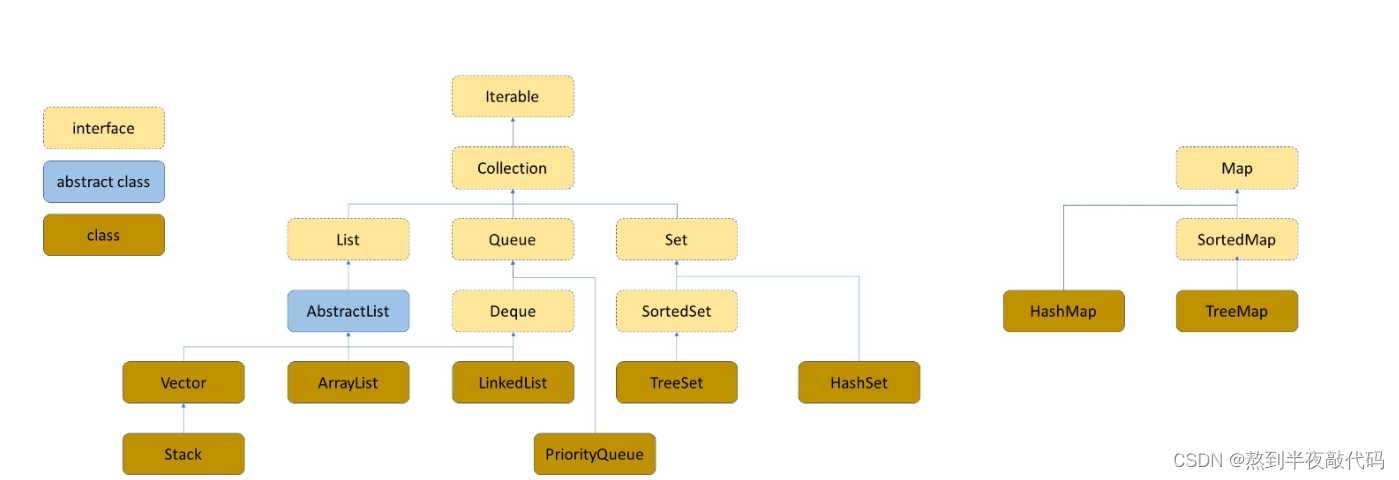
有这张图我们可以看出Set是继承Collection而Map没有继承任何的类,了解这一点对于后续的学习 是比较有帮助的。
TreeMap和TreeSet实现的底层原理(数据结构)是相同的的属于红黑蛋树,也可以说是一颗二叉搜索树。
二叉搜索树:它或者是一棵空树,或者是具有下列性质的二叉树:若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值;若它的右子树不空,则右子树上所有结点的值均大于它的根结点的值;它的左、右子树也分别为二叉搜索树。
Map的常用方法和说明:

注意:
1. Map是一个接口,不能直接实例化对象,如果要实例化对象只能实例化其实现类TreeMap或者HashMap
2. Map中存放键值对的Key是唯一的,value是可以重复的
3. 在TreeMap中插入键值对时,key不能为空,否则就会抛NullPointerException异常,value可以为空。但
是HashMap的key和value都可以为空。
4. Map中的Key可以全部分离出来,存储到Set中来进行访问(因为Key不能重复)。
5. Map中的value可以全部分离出来,存储在Collection的任何一个子集合中(value可能有重复)。
6. Map中键值对的Key不能直接修改,value可以修改,如果要修改key,只能先将该key删除掉,然后再来进行
重新插入。
7. TreeMap和HashMap的区别【HashMap之后的博客中会讲到】
对于TreeMap来说:

TreeSet的常用方法和使用:
boolean add(E e) 添加元素,但重复元素不会被添加成功
void clear() 清空集合
boolean contains(Object o) 判断 o 是否在集合中
Iterator iterator() 返回迭代器
boolean remove(Object o) 删除集合中的 o
int size() 返回set中元素的个数
boolean isEmpty() 检测set是否为空,空返回true,否则返回false
Object[] toArray() 将set中的元素转换为数组返回
boolean containsAll(Collection c) 集合c中的元素是否在set中全部存在,是返回true,否则返回 false
boolean addAll(Collection c) 将集合c中的元素添加到set中,可以达到去重的效果
注意:
1. Set是继承自Collection的一个接口类
2. Set中只存储了key,并且要求key一定要唯一
3. TreeSet的底层是使用Map来实现的,其使用key与Object的一个默认对象作为键值对插入到Map中的
4. Set最大的功能就是对集合中的元素进行去重
5. 实现Set接口的常用类有TreeSet和HashSet,还有一个LinkedHashSet,LinkedHashSet是在HashSet的基础
上维护了一个双向链表来记录元素的插入次序。
6. Set中的Key不能修改,如果要修改,先将原来的删除掉,然后再重新插入
7. TreeSet中不能插入null的key,HashSet可以。
8. TreeSet和HashSet的区别【HashSet之后的博客中会讲到】
















 2571
2571











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











