






在mysql中索引(index)可以 同下标进行类比但又有所差别。
索引的背后数据结构是B+树,在讲解B+树之前我们先来讲解B-树这样可以使我们更好的理解B+树。
B-树是n叉搜索树,想必大家都了解过二叉搜索树但两者的存储规则有所不同,在B-树中一个节点可以储存多可key值,在B-数中将key分成了几个区间,例如在一个节点中有N个key那么就会有N+1个区域:如图所示:
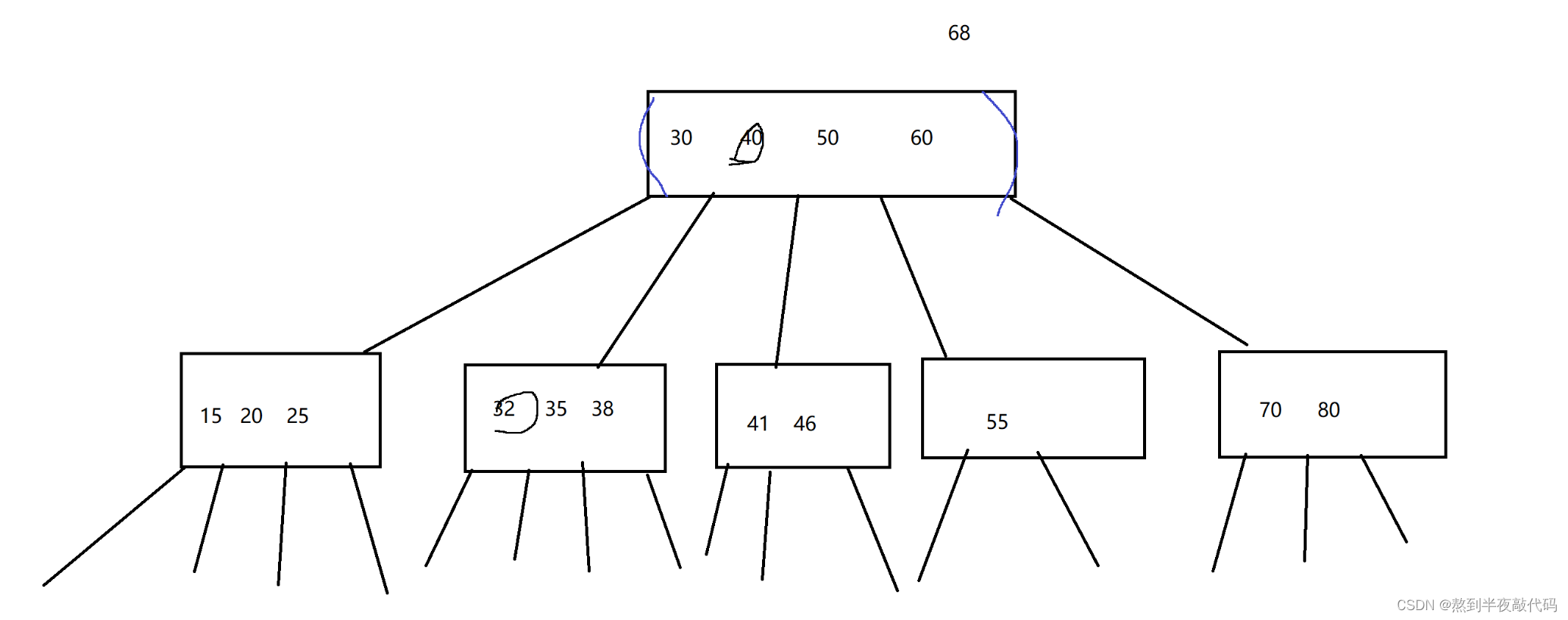
我们以第二层的节点为例,他所包含的空间为(x<15,15<=x<20,22<=x<25,x>=25),想必大家通过这个例子可以充分理解区域的划分。
B-树和二叉树相比真的具有优势吗?其实并不尽然,这种查询方式 也需要进行多次比较进而确定查询空间,这种结构虽然使树的结构变低了但是每个节点比较的次数变多了,因此相比于二叉树在某些方面优势并不明显。
注意:B-树和二叉数想必还是有很大优势的,虽然B-树中每个节点的比娇次数变多了但是硬盘IO变小了,B-树一次硬盘IO是将整个区间内的值都取出来,明显降低了硬盘IO的次数,因此B-树的主要目的不是改变比较次数,而是降低硬盘IO的次数。
由于B-数在某些方面的不足因此出现了B+树,B+树是对B-树的一种改进。
B+树的本质也是N叉搜索树,它与B-树十分相似却又独具特点,相比于B-树B+树当向下延伸时,会将双亲节点中的值作为最大值进行添加到叶子结点,同B-树不同的是如果B+树中有N个节点那么会形成N个节点:
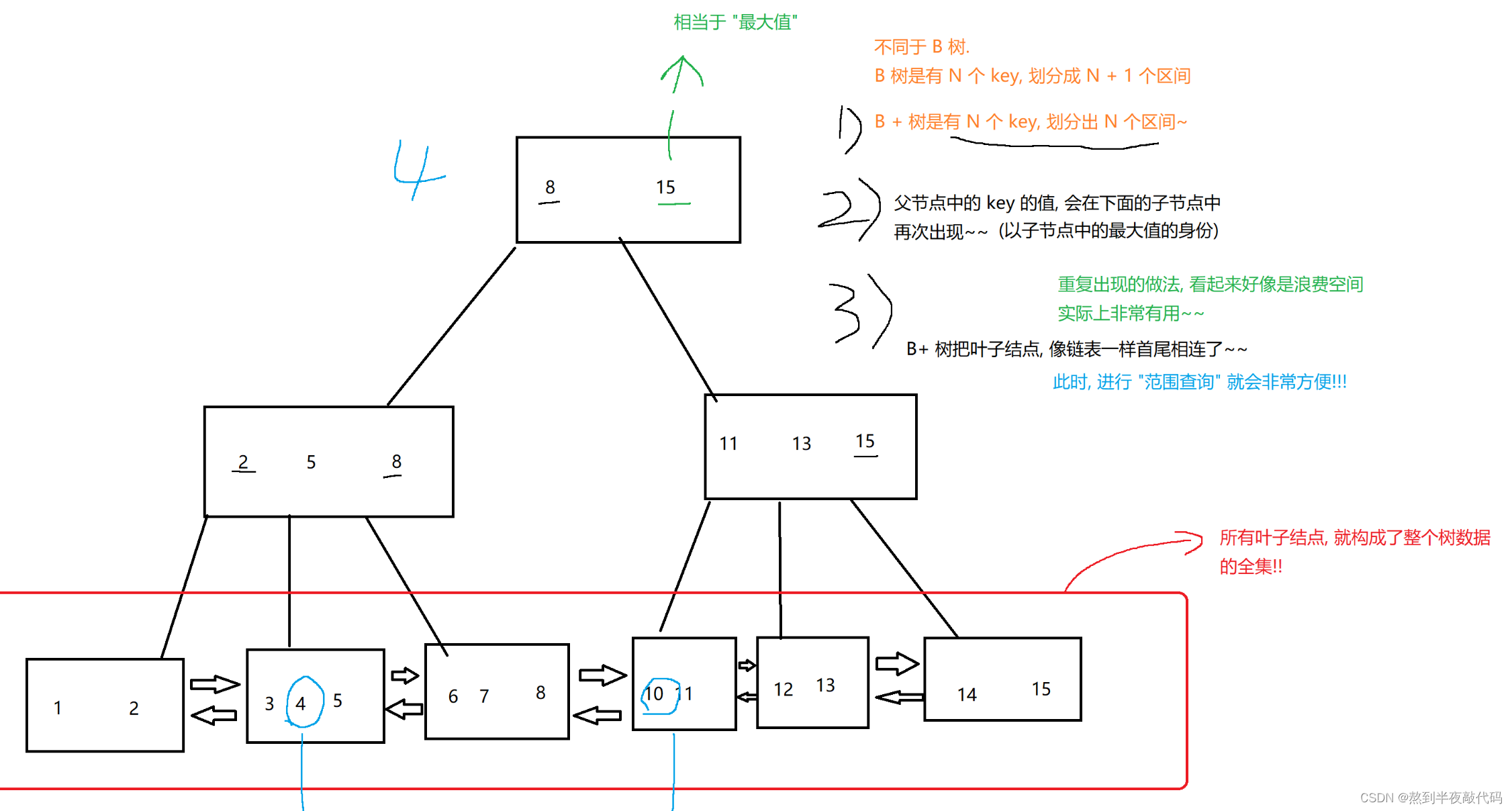
需要特别注意的是,所有的叶子结点构成了珍格格数据的全集。
B+树的优点:
1,高度较低,硬盘IO较少。
2,叶子结点是全集并用链表进行连接,非常便于范围查询。
3,由于B+树,叶子结点是全集,非叶子节点上不必存储“数据行”,只需要存储索引列的key即可,使得非叶子节点小号的空间比较小。
4,B+树所有的查询都是要落到叶子结点上完成的,任何一次查询,经历的IO次数和比较次数是差不多的,查询的开销稳定。
注意:稳定以一个非常难能可贵的优势,许多的数据结构中算法等都是不稳定的,在一个稳定的结构中,我们几乎可以准确的预估成本和时间。
















 10万+
10万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











