






一、集中一切资源
转个图:
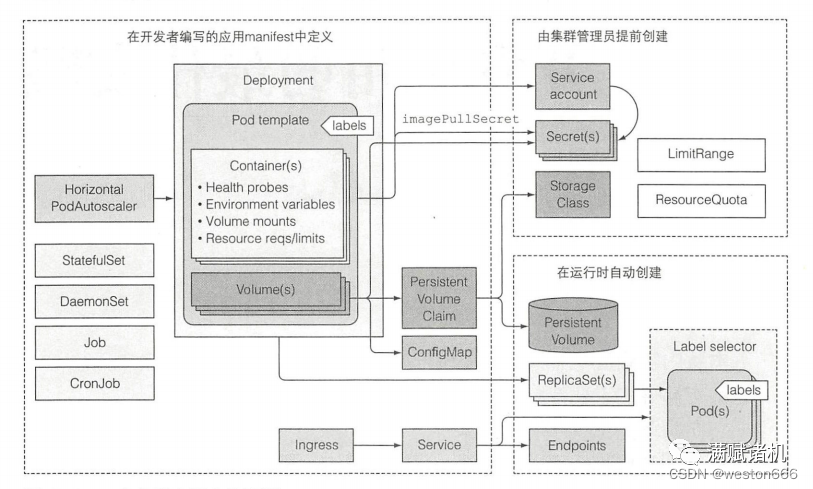
1、以pod作为应用的最小运行单元,其中包括container和volume
2、pod需要权限、拉镜像的密钥等
3、卷可以是configmap、emptydir、gitrepo、PVC持久卷等类型
4、方便其他应用或集群外访问pod,需要建立service
5、label方便管理
6、deployment方便高可用、多副本运行、滚动升级
7、可能需要用到job等资源
二、了解pod生命周期
1、应用必须预料到会被杀死或者重新调度
(1)预料到本地ip和主机名会发生变化
pod被重新调度后的ip和所运行的节点都会变化,statefulset可以持久化pod的状态,但是ip还是会变,所以集群应用不应该依赖彼此的ip地址构建关系
(2)预料到写入磁盘的数据会消失
使用存储卷持久化数据
2、重新调度死亡的或者部分死亡的pod
如果一个pod中的部分容器一直启动不了,kubelet会一直重启这个pod,但实际上这个pod已经被判定为死亡了,因为就是起不来,所以要重新调度这个pod
3、以固定顺序启动pod
场景:podA需要在podB启动后才能启动
最佳实践:使用initContainer,作用:在podA的主容器启动前初始化一些配置,阻塞主容器的启动

4、增加生命周期钩子
(1)启动后生命周期钩子(类似于就绪探针)
在容器的主进程启动后立刻并行执行,即便并行,也会影响容器:钩子执行完之前,容器会停留在waiting状态,pod状态为pending;如果钩子运行失败或者返回非零状态码,主进程会被杀死
一般想做什么事情就会在代码里写好,除非是使用别人的镜像,又想加自己的功能才会使用启动后钩子
(2)停止前生命周期钩子
停止pod时,先执行这个钩子,无论成功失败,再向容器主进程发送SIGTERM信号
生命周期钩子是针对容器而不是pod
5、了解pod的关闭
要删除pod时,api-server不会立马删除pod,而是设置pod的deletionTimestamp值,拥有这个值的pod就开始以下执行步骤:
(1)执行停止前钩子,等待执行完毕
(2)向容器主进程发送SIGTERM信号
(3)等待容器优雅关闭或者等待终止宽限期超时
(4)如果容器没有优雅关闭,使用SIGKILL信号强制终止进程
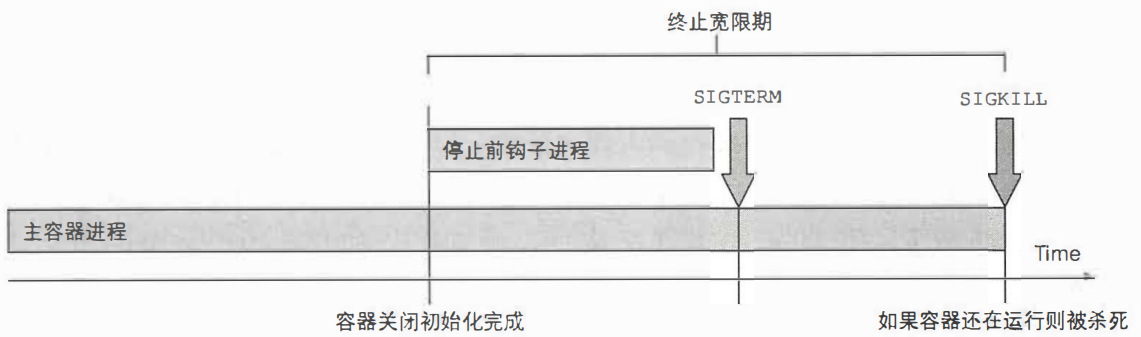
指定终止宽限期:
pod.spec.terminationGracePeriod=30
kubectl delete pod xxx --grace-period=5
kubectl delete pod xxx --grace-period=0 --force三、确保所有客户端请求得到妥善处理
1、pod启动时保证能提供服务
容器启动需要时间,可以设置就绪探针,探针执行成功后才能对外提供服务
2、pod关闭时保证请求不出错
了解pod删除时发生了什么
两串事件:
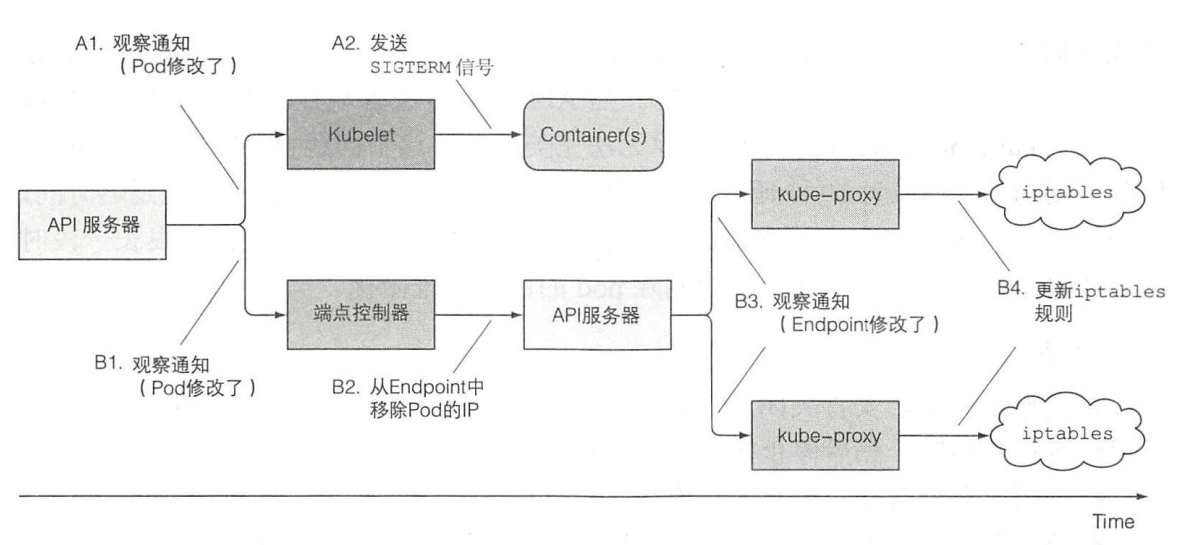
如果B3未执行但是A2已经执行了,那外部的请求还会被分配到该pod上
解决办法:无法完美解决,只能设置等待时间,延迟容器的关闭

四、让应用在k8s中方便运行和管理
1、构建可管理的容器镜像
2、合理使用标签
3、使用多维度而不是单维度的标签
4、通过注解描述每个资源
5、给进程终止提供更多信息:把终止原因写入文件,这样使用kubectl describe pod时就可以看到了容器为什么死亡了,这个文件默认路径是/dev/termination-log,也可以指定pod.spec.terminationMessagePath
6、处理日志
五、开发测试的最佳实践
1、本地调试,不用每次调试都打包上环境
2、真的需要集群时,可以使用minikube
3、写manifest部署应用
4、不会写yaml就写Ksonnet
5、使用CI/CD、Devops风格















 588
588

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









