






一、介绍
1、什么是pod的状态
举例:无状态:假设草原上有很多头牛,不健康的牛可以被替换掉,用户无感知
有状态:每一只牛我都知道它的名字、生什么病、眼睛啥颜色,无法找到一个一模一样的牛来替换它
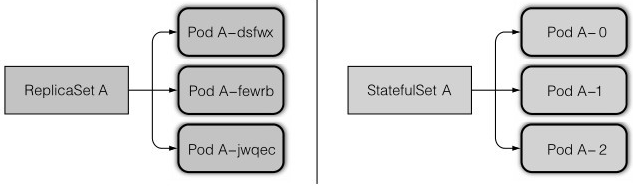
对应用来说,新的pod要和旧的pod拥有完全一致的状态和标识,体现在网络标识、存储卷等特性上,RC和RS管理的pod,重新调度后与之前的pod完全不一致,是一个全新的pod,而StatefulSet管理的pod,重新调度后依然拥有旧pod的状态
2、pod稳定标识状态
RS管理的pod每次重新调度后会有新的IP 和 pod名称,如果一个应用要维护一份所有pod的网络标识,就只能一个pod一个service,因为service的ip不变,这样很冗余(但是为什么还是使用pod-service这种模式,而不是statefulset呢?因为管理起来,前者只需要管理RS即可,后者因为每个pod都不一样并且要记录状态,用户需要对每个pod管理,反而增加了工作量,所以它适用于副本数量比较少的情况)
StatefulSet的处理是这样的:
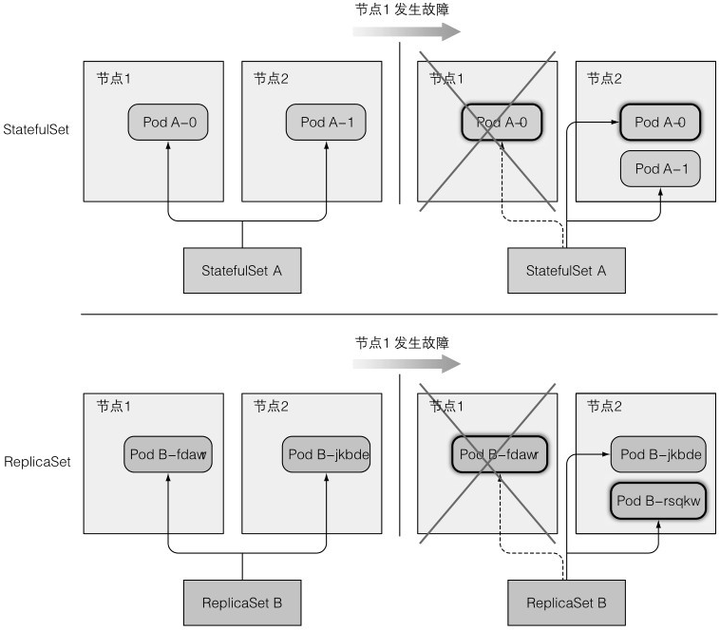
StatefulSet创建的pod都有一个从0开始的顺序索引,某个pod丢失后,会创建一个同名的pod,实际上不仅仅是同名,所有状态都是相同的,即便调度到其他节点上
缩容:顺序索引往下减,先删索引最大的那个
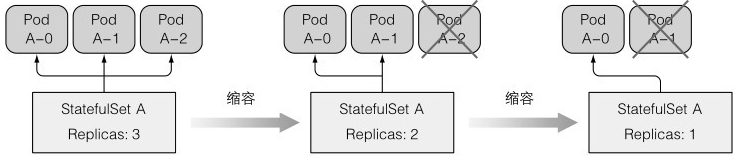
缩容每次只会操作一个pod,因为一次性下线多个pod,容易造成数据丢失,所以有不健康的pod时,statefulSet也不能进行缩容
扩容:顺序索引往上加
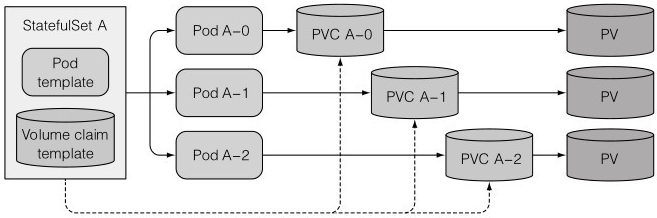
3、存储卷状态
通过RS创建的多副本pod是共享一个持久化卷的
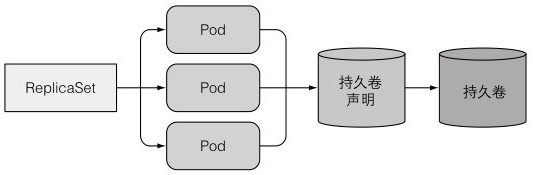
如果想要一个pod对应一个PVC,只能多创建几个RS,每个RS管理1个pod
而StatefulSet不用,StatefulSet可以直接在模板中添加PVC模板,这样每个pod就会有自己的专属存储
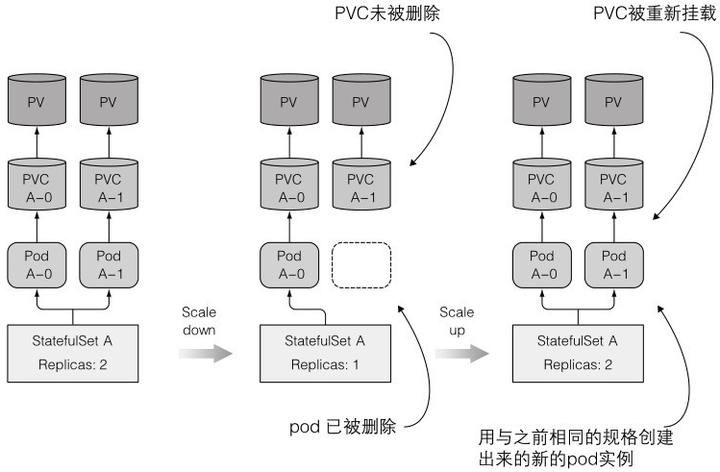
缩容时,不会删除PVC,因为再扩容时,还要挂载到之前的PVC,否则状态就不一样了
扩容:PVC可能挂到之前同名的已缩容的pod对应的PVC上,这也是缩容时为什么不删PVC的原因
4、StatefulSet保障
at-most-one语义保证具有相同状态的pod只能存在一个
假设k8s认为某个pod挂了(实际没挂),启动了一个相同状态的pod,于是这两个相同状态的pod绑定了同一个PVC,存储时容易造成并发问题。而ReplicaSet虽然也是多个pod对应一个PVC,但它会以一个随机的标识来创建pod,不可能存在两个相同标识的进程同时运行
二、使用
部署statefulset例子的步骤:
1、存储你数据文件的持久卷PV(当集群不支持持久卷的动态供应时,需要手动创建)
2、Statefulset必需的一个控制Service
3、Statefulset本身
1、创建PV:

2、创建service
用于在有状态的pod之间提供网络标识的headless Service(在pod就绪之前,服务发现就可以匹配pod)
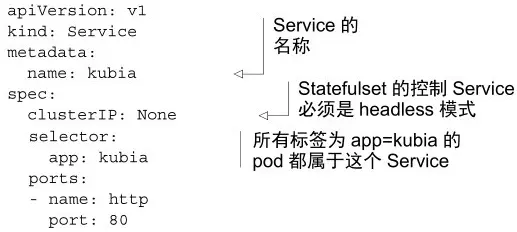
指定了clusterIP为None,这就标记了它是一个headless Service。它使得pod之间可以彼此发现
3、创建statefulset

4、创建时:
pod会一个一个启动,总是在前一个pod就绪后,才启动后一个
5、删除一个pod,会自动拉起被删除的pod,并且状态都一致

三、发现伙伴节点
集群中pod与pod如何直接通信?尤其是同一个statefulset或ReplicaSet管理的pod
这时不应该向k8s的API发送查询请求找到伙伴节点,而是用DNS域名解析来直接请求其他节点,/etc/hosts里每一条记录都是一个SRV(Service Record)记录
1、书上的例子
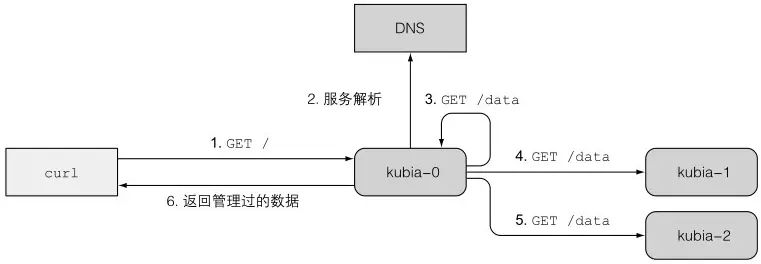
一个数据存储集群,分布式的三个pod,每个pod存储的数据不一样,当客户端需要查询数据时,光把请求发送到一个pod上只能查到部分数据,于是在pod中设置DNS,把所有伙伴节点的域名IP都配置好,请求来时,遍历每个域名,把请求转发出去,并汇总查询数据返回客户端。
扩容或缩容Statefulset,服务于客户端请求的pod都会找到所有的伙伴节点,因为SRV会随着statefulset的扩缩容而改变
这个例子比较老旧,因为现在不会把数据分开存储,每个pod存储的基本都是一样的数据,通过共识来保证数据的一致性
2、自己项目的例子:涉密不写
四、了解Statefulset如何处理节点失效
正常情况:一个pod失效了(节点挂了、pod被删了、pod挂了),kubelet会清理这个节点,并重新启动新的,statefulset管理的pod,会重启一个状态相同的pod
异常情况:失效的pod没有清理
场景模拟:节点断网
1、pod-0运行在node1上,把node1的网络断了
2、node1的kubelet无法上报pod状态,控制台一段时间后标记node状态为NotReady,pod状态为unkonw
3、unkonw状态下,如果一段时间后pod恢复运行,状态继续标记为running,如果没恢复,控制器会删除pod,重新调度
4、删除pod的请求发送不到node1,因为断网了,但已经标记了该pod为terminating状态,这时候,旧pod删不掉,新pod运行不了,而且实际上这个旧pod还是在运行的
5、手动删除,kubectl delete pod xxx,提示成功,但请求还是没到node1上
6、强制删除:
kubectl delete po xxx --force --grace-period 0--grace-period 指定删除时的宽限时间,0代表立马删除
pod重新被调度















 672
672











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









