






获取文本数据
纯文本 text
import os
# Read in a plain text file
with open(os.path.join("data", "hieroglyph.txt"), "r") as f:
text = f.read()
print(text)
表格
import pandas as pd
# Extract text column from a dataframe
df = pd.read_csv(os.path.join("data", "news.csv"))
df.head()[['publisher', 'title']]
# Convert text column to lowercase
df['title'] = df['title'].str.lower()
df.head()[['publisher', 'title']]
在线资源
import requests
import json
# Fetch data from a REST API
r = requests.get(
"https://quotes.rest/qod.json")
res = r.json()
print(json.dumps(res, indent=4))
# Extract relevant object and field
q = res["contents"]["quotes"][0]
print(q["quote"], "\n--", q["author"])
清理 html
re
import re
# Remove HTML tags using RegEx
pattern = re.compile(r'<.*?>') # tags look like <...>
print(pattern.sub('', r.text)) # replace them with blank
beautifulsoup
from bs4 import BeautifulSoup
# Remove HTML tags using Beautiful Soup library
soup = BeautifulSoup(r.text, "html5lib")
print(soup.get_text())
# Find all articles
summaries = soup.find_all("tr", class_="athing")
summaries[0]
# Extract title
summaries[0].find("a", class_="storylink").get_text().strip()
# Find all articles, extract titles
articles = []
summaries = soup.find_all("tr", class_="athing")
for summary in summaries:
title = summary.find("a", class_="storylink").get_text().strip()
articles.append((title))
print(len(articles), "Article summaries found. Sample:")
print(articles[0])
删除标点
import re
# Remove punctuation characters
text = re.sub(r"[^a-zA-Z0-9]", " ", text)
print(text)
NLTK
import os
import nltk
nltk.data.path.append(os.path.join(os.getcwd(), "nltk_data"))
# Another sample text
text = "Dr. Smith graduated from the University of Washington. He later started an analytics firm called Lux, which catered to enterprise customers."
print(text)
from nltk.tokenize import word_tokenize
# Split text into words using NLTK
words = word_tokenize(text)
print(words)
from nltk.tokenize import sent_tokenize
# Split text into sentences
sentences = sent_tokenize(text)
print(sentences)
# List stop words
from nltk.corpus import stopwords
print(stopwords.words("english"))
# Reset text
text = "The first time you see The Second Renaissance it may look boring. Look at it at least twice and definitely watch part 2. It will change your view of the matrix. Are the human people the ones who started the war ? Is AI a bad thing ?"
# Normalize it
text = re.sub(r"[^a-zA-Z0-9]", " ", text.lower())
# Tokenize it
words = text.split()
print(words)
# Remove stop words
words = [w for w in words if w not in stopwords.words("english")]
print(words)
句子解析
import nltk
# Define a custom grammar
my_grammar = nltk.CFG.fromstring("""
S -> NP VP
PP -> P NP
NP -> Det N | Det N PP | 'I'
VP -> V NP | VP PP
Det -> 'an' | 'my'
N -> 'elephant' | 'pajamas'
V -> 'shot'
P -> 'in'
""")
parser = nltk.ChartParser(my_grammar)
# Parse a sentence
sentence = word_tokenize("I shot an elephant in my pajamas")
for tree in parser.parse(sentence):
print(tree)
词干提取
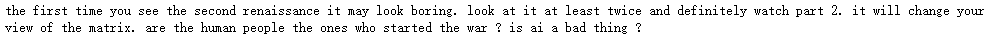
from nltk.stem.porter import PorterStemmer
# Reduce words to their stems
stemmed = [PorterStemmer().stem(w) for w in words]
print(stemmed)

词性还原
from nltk.stem.wordnet import WordNetLemmatizer
# Reduce words to their root form
lemmed = [WordNetLemmatizer().lemmatize(w) for w in words]
print(lemmed)

# Lemmatize verbs by specifying pos
lemmed = [WordNetLemmatizer().lemmatize(w, pos='v') for w in lemmed]
print(lemmed)
















 1002
1002











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









