






OCR

前面四项是用来控制读取数据的超参。
5-7个比较直观,
第8个–Transformation是用来控制是否使用STN,
第9个–FeatureExtraction是提取图像特征的网络结构,
第10个–SequenceModeling是图1中‘Shared Encoder’的结构。
–Prediction是预测的时候选择图1中的CTC的分支或者Attention Decoder分支。
–mtl是选择模型的训练方式,是选择一个任务进行训练还是训练多任务模型。
–without_prediction是指模型加载的方式是否需要预测模块。
CTC
CTC(Connectionist Temporal Classification)适用于输入与输出长度变化且不相等很难手动对齐的情况,用CTC替换softmax loss,训练样本无需对齐,适用于OCR、语音识别、机器翻译中。
给定输入序列X,CTC给出所有可能的Y的输出分布。
torch.nn.CTCLoss(blank=0,reduction=‘mean’,zero_infinity=False)
对齐
将X分为若干个部分,每个部分对应一个输出。最简单策略是合并连续重复出现的字符y。
缺点:1)不可能连续出现y,中间可能出现噪声、停顿现象;
2)不能处理有连续重复字符出现的情况,如hello,输出为helo。
因此需要引入空白字符∈。
最大化x关于y的后验概率P(Y|X)。
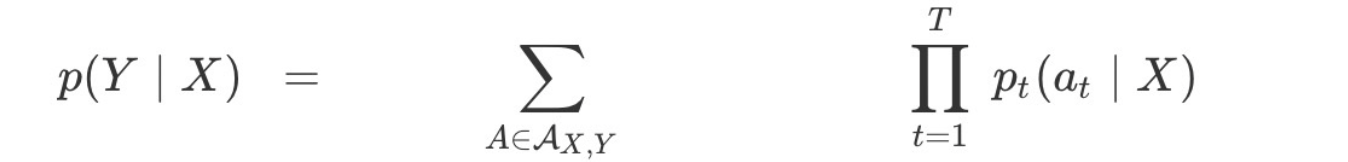
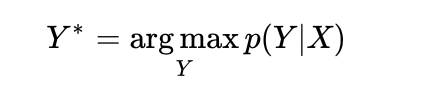
Beam search
beam search是 全局搜索和greedy search在查找时间和模型精度的一个折中,每个时间片计算是所有可能假设的概率,并从中挑出最高的几个作为一组,然后在这组假设的基础上,产生概率最高的几个作为一组,依次进行,直到达到最后一个时间片。

CTC的特征
- 假设每个时间片是相互独立的,OCR中各个时间片之间含有语义信息,加入LM,可以提升效果;
- X与Y之间单调对齐,在OCR和语音识别中成立,但在机器翻译中,不成立;
- 多对一映射,X一定大于Y的长度。
STN
transmation == TPS 时,采用STN
STN(Spatial Transformer Networks)用于专门训练网络的平移不变性。
FeatureExtraction
可选有VGG、RCNN、ResNet
attention输出
采用Image caption的生成模型进行预测,训练时,预测第i+1个时间片的输出时,对GT的前i个内容进行one-hot编码后输入,得到输出;
decoder则使用预测阶段的结果作为当前时间片的输入
CTPN
检测横向分布的文字(横向分为n个等宽的anchor,所以只需要纵坐标y和高),由Faster RCNN结合LSTM改进而来。
首先VGG提取(N,C,H,W)特征图,然后由3*3滑动窗口的RCNN,学习空间特征,得到(N,9C,H,W)的特征向量,将该特征向量reshape为(NH,W,9C),以batch=NH,Tmax=W的数据序列,输入双向LSTM,学习每一行的序列特征,输出为(NH,W,256),最后reshape恢复size:(N,256,H,W)。
LSTMCell
torch.nn.LSTMCell(input_size,hidden_size,bias=True)
一个LSTM单元,相当于一个time step的处理,LSTMCell参数中没有num_layers(层数)、bidirectional(双向)、dropout选项。需要手动处理每个time step的迭代过程。同一层会共享这一个Cell,多层LSTM则需要构建多个cell
torch.nn.LSTM()
参数列表
input_size:x的特征维度
hidden_size:隐藏层的特征维度
num_layers:lstm隐层的层数,默认为1
bias:False则bih=0和bhh=0. 默认为True
batch_first:True则输入输出的数据格式为 (batch, seq, feature)
dropout:除最后一层,每一层的输出都进行dropout,默认为: 0
bidirectional:True则为双向lstm默认为False
输入:input, (h0, c0)
输出:output, (hn,cn)
输入数据格式:
input(seq_len, batch, input_size)
h0(num_layers * num_directions, batch, hidden_size)
c0(num_layers * num_directions, batch, hidden_size)
输出数据格式:
output(seq_len, batch, hidden_size * num_directions)
hn(num_layers * num_directions, batch, hidden_size)
cn(num_layers * num_directions, batch, hidden_size)
Pytorch里的LSTM单元接受的输入都必须是3维的张量(Tensors).每一维代表的意思不能弄错。第一维体现的是序列(sequence)结构,也就是序列的个数,嘿嘿,也就是这一串的输入中,多少个明确的单元数,第二维度体现的是小块(mini-batch)结构,第三位体现的是输入的元素(elements of input)。如果在应用中不适用小块结构,那么可以将输入的张量中该维度设为1,但必须要体现出这个维度。















 414
414











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









