






 本文介绍了智能体的概念,包括其结构、感知序列和代理者方程,强调了代理者如何根据环境信息做出行为。接着讨论了理性行为,指出理性智能体总是追求最大化表现评测的期望值。文章还列举了不同类型的智能体,如简单反射智能体、基于目标的智能体和效用智能体,并阐述了它们的特点和局限性。此外,还探讨了探索与开发在学习智能体中的平衡问题。
本文介绍了智能体的概念,包括其结构、感知序列和代理者方程,强调了代理者如何根据环境信息做出行为。接着讨论了理性行为,指出理性智能体总是追求最大化表现评测的期望值。文章还列举了不同类型的智能体,如简单反射智能体、基于目标的智能体和效用智能体,并阐述了它们的特点和局限性。此外,还探讨了探索与开发在学习智能体中的平衡问题。
智能代理者
一. 代理者
首先什么是代理者(agent): 代理者可以是人,可以是机器,甚至你说是温度计也行,即代理者是利用传感器(sensors)来感知环境并利用感受器(effectors)来做出行为. 举个例子人类作为代理者有眼睛,耳朵,利用眼睛你看到有人要扇你耳光(环境),从而你要做出防御行为(action).最多说一句,好像有的人也喜欢把代理者称作智能体,这俩一样的不同叫法.
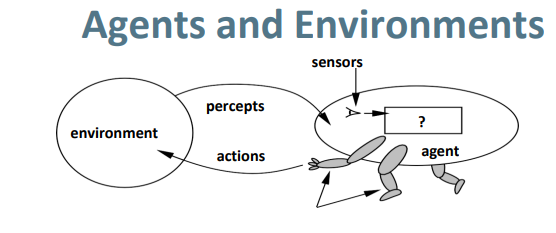
上图可能被老师,前辈们都讲烂了,小弟这还是啰嗦两句,代理者利用传感器从环境中获取感知,从而做一系列行为来改变环境状态. 就像你看到有一碗饭,这一碗饭就是个环境状态,你吃了,饭碗空了,你吃的这个动作就将环境状态改变了,即饭碗变空了.
感知(percepts): 代理者利用传感器只能感知环境的一部分信息即环境信息的子集,获取环境的所有信息是不可能的,当在不同时间下,代理者都能感知环境的一部分信息,那么根据时间或者历史,代理者可以获得一串感知序列(percepts sequence),即感知的一系列历史信息.然后代理者可以根据这感知序列来做点行为.
代理者方程(agent function): 就如小弟上述,代理者根据感知序列来做一系列行为:
f
:
P
∗
→
A
f:P^∗→A
f:P∗→A
P
∗
P^∗
P∗:输入感知序列,即为输入
A
A
A: 输出行为
f
f
f: 方程,这是你自己编写的,就像如果代理者看见饭碗,就做行为吃.
代理者方程就是个数学表达式子
代理者程序(agent program): 应用代理者方程的玩意,就是个在硬件上跑的程序:
代
理
者
(
a
g
e
n
t
)
=
结
构
(
a
r
c
h
i
t
e
c
t
u
r
e
)
+
程
序
(
p
r
o
g
r
a
m
)
代理者(agent)=结构(architecture)+程序(program)
代理者(agent)=结构(architecture)+程序(program)
结
构
(
a
r
c
h
i
t
e
c
t
u
r
e
)
=
设
备
(
c
o
m
p
u
t
e
r
d
e
v
i
c
e
)
+
传
感
器
(
s
e
n
s
o
r
s
)
+
制
动
器
(
a
c
t
u
a
t
o
r
s
)
结构(architecture)=设备(computer\ \ device)+传感器(sensors)+制动器(actuators)
结构(architecture)=设备(computer device)+传感器(sensors)+制动器(actuators)
代 理 者 方 程 ( a g e n t f u n c t i o n ) 在 代 理 者 程 序 里 代理者方程(agent function)在代理者程序里 代理者方程(agentfunction)在代理者程序里
二.合理行为(rationality)
讲合理行为之前,先和大家聊聊什么是表现评测(performance measure):
当一个代理者(agent)在某个环境中,根据感知序列,它做出一系列的行为(action sequence).这一系列行为会使环境经历一系列的状态(sequence states或者也叫做environment sequence环境序列).如果这个环境序列的状态就是我们想要的,那就说明代理者做的不错,所以表现评测其实就是用来评价环境序列的.
理性代理者(rational agent),理智代理者总是做对的事情,代理者在一个环境中依据感知生成一系列动作,这一系列动作引发环境有一系列状态,(环境序列)如果环境序列是我们期望的,则智能体表现好. 那么正确的行为即为理性合理的行为(rational action),在给个明确的合理性为定义,即理性动作:给定感知序列,表现评测是用来评价环境序列 ,使表现评测的期望值为最大.啥意思,举个大家都讲烂的例子,就是著名的智能清洁机.
简单的介绍下,清洁机的感知是目前的位置,和目前位置的干净状态,写作: [A, 脏]. 当然了如果这个机子在B区域,我们能看到B区域有点石子,那就是垃圾,那么它的感知为 [B,脏]. 这机子的行为有这么几个,向左走,向右走,吸尘,和啥也不干,这4个行为. 还要就是我们假设就这俩A,B区域,我们的机子就在这俩区域里吸尘保持俩区域卫生.
| 感知序列 | 行为 |
|---|---|
| [A,干净] | 向右走 |
| [A,脏] | 吸尘 |
| [B,干净] | 向左走 |
| … | … |
| [A,干净],[A,干净] | 向右走 |
| [A,干净],[A,脏] | 吸尘 |
| … | … |
我们具体看下第5行和第6行,竟然可以有俩感知,这个别惊讶,这个时间段,智能体感知时间久点.反正就是感知到了.
我们现在来感受下表现评测的期望值为最大是啥意思.

举个例子,如上图,我没从左往右看这个环境状态的变换,一开始清洁机在A区域,我们能看到A区域和B区域均有垃圾. 我们来制定个分数规则,清理干净后的房间+1分, 所有行为,除了啥也不干行为,均+0.5分. 好我们来看看上图,一开始环境状态俩房间都有垃圾,但是这个是初始环境状态,所以我们定0分,之后吸尘(suck)+0.5,这个行为做后,房间干净了+1,那么现在我们有1.5分.当然了,如果我们从初始状态不做上述行为,你说一开始我就叫清洁机往右走,但这样0+0.5(右走)=0.5,你才0.5分,如果啥也不干,那更低才0分. 大家可以自己继续算算评测分数达到最后的环境状态即俩房间都干净,最后的得分2.5.
其实智能体就是要做出一系列行为使表现评测分数最高,而这个表现评测分数又是基于环境状态,其实就是在说希望智能体做一系列行为达到我们想要的环境状态. 当然了如果制定分数其实逃不了这个想法,即我想要你做的或者这个环境状态我想要就“+”分,我不想要你做的或者这个环境状态我不想要就"-"分,例如如果清洁机做出3个行为后有k个房间有垃圾,那么就 -k 分.
我们回到话题,那么理智智能体(rational agent)即总在做对的事情,做合理行为.
三.理智智能体的特征
既然理智智能体(rational agent)即总在做对的事情,做合理行为,也就是说理智代理者会做出一些行为使表现评测分数为最大.
理性≠全知全能:首先智能体肯定比人要次很多,我们人在一个环境中,你能保证你能感知环境的各种细节信息么么,如果你说我能,那我只能说你可能是吸血鬼甚至能感知到蚊子扇动翅膀,吸血鬼这样才是全知. 智能体也是感知序列只是环境信息的子集. 啥是全能,就是你会知道所有行为所造成的结果,从而根据情况来做出这些行为,说白了就是干啥都干的很好. 总之理性智能体做不了.
理性≠预测未来,明察秋毫: 能做到预测未来和明察秋毫,那是如来佛祖能做的,我们理性智能体做不了.
所以理性比不意味着成功.我们做的智能体不意味着可以做好一个事情.
理性的4个定义:
(1)定义成功标准的表现评测
(2)智能体对环境的先验知识
(3)智能体能够完成的动作
(4)智能体最新的感知序列
四.智能体特性和环境
智能体有4个特性即(PEAS)
举个大家举烂的例子,智能车,智能车作为智能体有这么4个特性:
-Performance measure(表现评测): 安全,快速,守法,舒适.
-Environment(环境):道路,行人,交通
-Actuators(制动器,动作器): 油门,刹车,显示器
-Sensors(传感器,感受器):摄像头,声纳
环境种类:
(1)全可察和半可察(fully vs partially observable):
是否代理人的传感器可以采集到所有相关信息关于环境状态(environment state),那么环境是全可察 智能体的传感器在每个时间点上可访问环境的完整状态,那么任务环境是完全可观测的.
(2) Deterministic vs stochastic:(确定性 vs 随机性)
环境的下一个状态完全由当前状态和该智能体执行的动作所决定,那么该环境是确定性的.
(3)Known vs unknown(可知vs不可知)
代理人是否了解环境的法则规则.在已知的环境下,所有动作的结果都是给定的,如果环境未知,则智能体需要学习如何动作,以便做出正确的决策
(4) Episodic(独立事件,偶发环境) vs sequential(连续环境)
下一个决定是否与之前一个决定互相独立
智能体的动作过程被分为不可再分的片段,且每个片段的动作选择仅仅依赖于片段本身
(5)Static(静态) vs dynamic(动态)
当智能体正在思考时(deliberating),环境是否随着时间可以改变,如果环境随智能体的行为而改变,则智能体的环境是动态的,否则为静态.
semi-dynamic(半动态):仅仅performance score改变 chess with clock.如果环境本身不随时间的推移而改变,但智能体的性能(performance score)发生改变.
(6) Discrete vs continuous(离散vs连续):
时间,状态,行为,感知是连续的还是离散的.
(7)Single vs multi-agent(单个vs多个智能体)
由一个代理人作决定,还是由计算机统筹多个代理人合作做出决定.一个智能体在一个环境内自运行,那么他就是一个单智能体.
五.智能体的种类
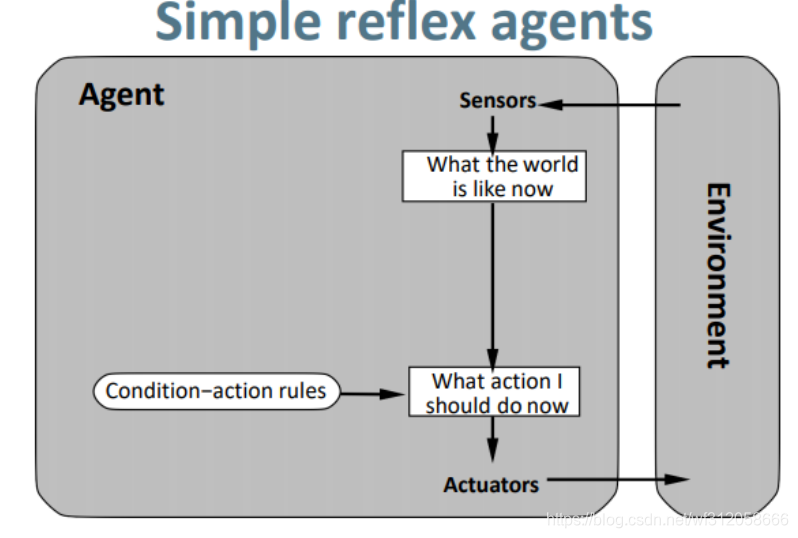
(1)simple reflex agent (简单反射智能体)
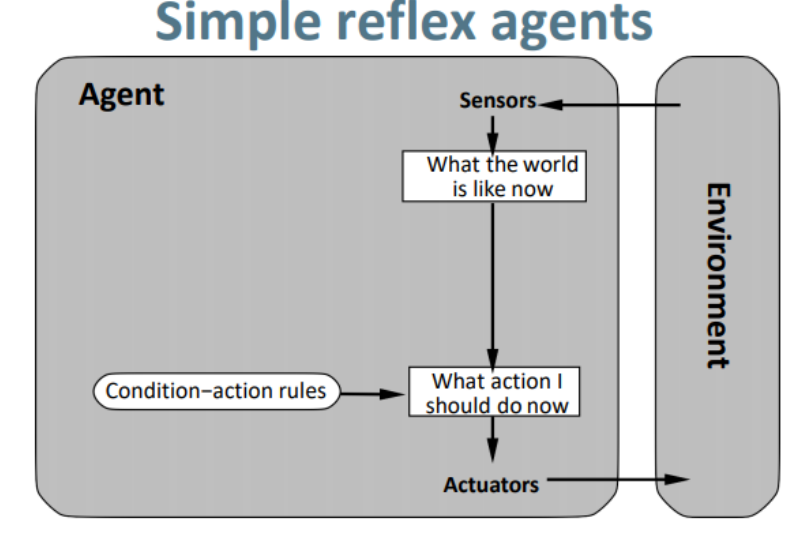
它的特点是忽视过去的感知信息,所以它根本没有内存去存储过去的感知信息.不关心上个感知的东西. 只基于条件动作规则.
(I):先看看当前环境得到的感知信息是啥,上个时间的环境感知信息毫不关心
(II):基于当前环境的感知信息,根据条件动作规则看看要做什么动作,例如: 脏就吸尘, 见饭就吃.
(III):执行动作.
这样的智能体,大家看看是不是用途很局限,根据感知信息根据条件做动作: 见饭就吃,天黑睡觉,白天起床,口渴喝水. 写码时疯狂写 if, else… 有时候条件行为是不容易写的,小弟之后更新逻辑哲学博客会提到一种叫做模糊逻辑的东西(fuzzy logic),在这提两句边界和度的问题,举个简单例子,多少头发算光头,如果0根头发是光头,那1根头发叫啥,你说叫有头发感觉不太多,如果叫光头,那2根头发叫啥…依次类推, 那多少根头发是光头和有头发的界限,那你怎么写这个if和else来设定条件.总之一句话单纯用条件来做动作行不通的.
所以简单反射智能体的缺点还有就是它的行为只基于目前的感知信息,就像清洁机,如果有多个房间,但你只能观察到俩房间,如果垃圾会随着时间增加会再生垃圾,那么你只能做眼下的事情,其他房间或者更远的房间产生垃圾了你依然不知道,也不会去清理. 所以部分可查的环境会使我们的智能体陷入循环,即循环动作,例如清洁机就在它眼下的俩房间来回清理,更远的房间它观察不到.如果智能体可以随机产生其他动作,使可以从无限循环中摆脱出来,这是个解决方法,但依然杯水车薪.
大家来具体看看关于简单反射智能体的条件行为代码(condition-action rules)
function SIMPLE-REFLEX-AGENT((location,status)):
if status==Dirty return suck
else if location==A return Right
else if location==B return Left
总而言之简单反射智能体只能基于当前感知,和部分可察环境容易引起循环行为. 无内存去存过去的感知信息.
(2)reflex agents with state (基于状态的反射智能体)
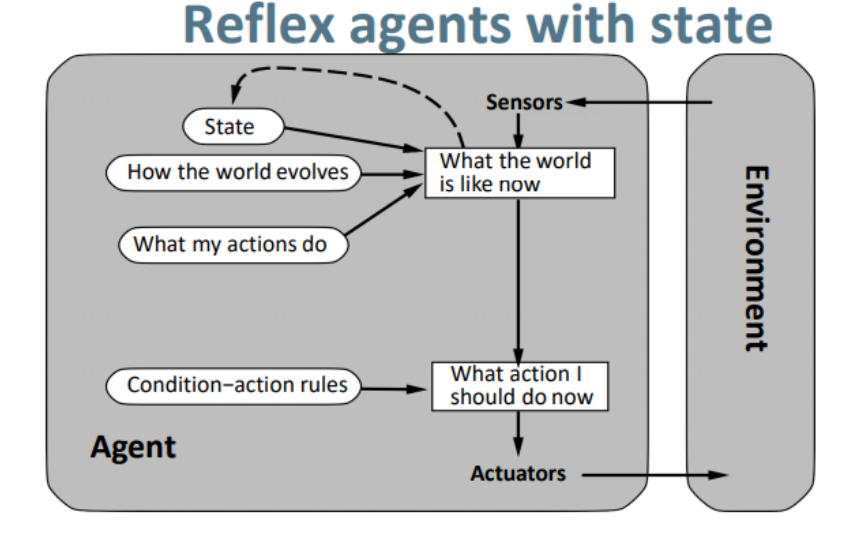
How the world evolves: environment model,how the environment works.例如扫地机器人,如果B区域长时间不去,那么B区域会变脏.
它和上面哪个智能体的区别在于,它可以处理部分可观测环境,也就是说它有个内存 internal
state: 来更新Internal State里的信息,从而判断目前环境状态. 这两个how the world evolves和what my actions do 是需要编写代码到智能体程序里的这两个也叫做internal model. 例如长时间不去清理某个地区的垃圾,那么那个地区会脏从而更新state来判断出Unobservable environment(看不见的环境感知信息).依赖感知历史,反射某些当前状态无法观测的方面. 从感知器获取到目前的局部感知序列 + environment model,来更新state.所以,internal state keeps track of relevant unobservable aspects of the environment.
**What my actions do:**更新后state后,agent有了目前的state和环境模型,那么接下来需要思考要做哪些行为,如果做了的话,会对未来环境造成什么影响,那么未来状态是怎样的.
Condition-action rules:
当知道要做哪些行为会对未来环境造成什么影响,还要结合condition-action rules,去决定最终要做的行为.
function REFLEX-AGENT-WITH-STATE(percept):
#state:当前感知的信息或者当前环境状态
#model:下个环境状态,基于当前状态和动作
#rule: 条件行为
#action: 行为
state=Update-State(state,action,percept,model)
rule=Rule(state,rules)
action=rule.action
return action
缺点:
即使你知道了目前环境的状态(environment state)但不足以确定是否我要做什么.你只知道干活吸尘,左右走,却不明白干活的目的是为了清洁.
(3) Goal-Based agent基于目标的智能体
简而言之就是需要写个目标给他.啥是目标,目标就是我们想要的状态,就像旅游,我们目标是到上海. 就像清洁机的目标是所有房间都是干净的.根据环境的目前状态还是不足够决定要做什么。例如,公路堵车,车只能往右和往左开,正确的选择是要根据goal information:即车目的地.
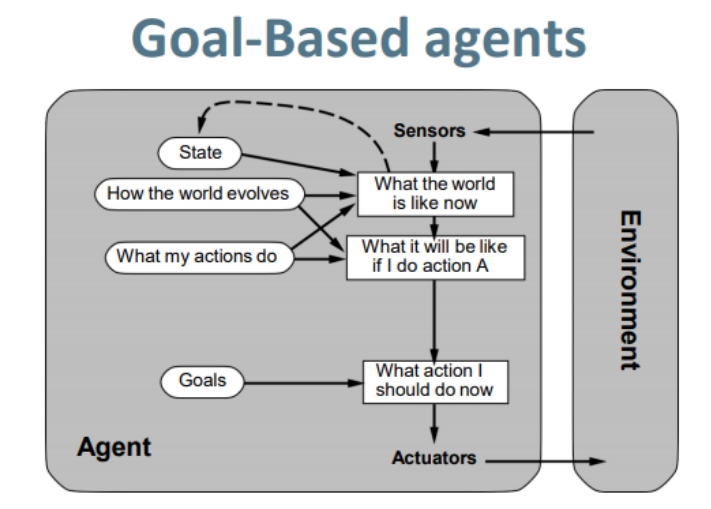
缺点:
有了目标,但不足以保证你完成这个目标是最有效率的,或者最好的.去上海旅游,方法千千万,选一个花钱最少的方法可以到上海.
(4) Utility(实用)-Based agent效用智能体
效用智能体就是来完善目标智能体的.
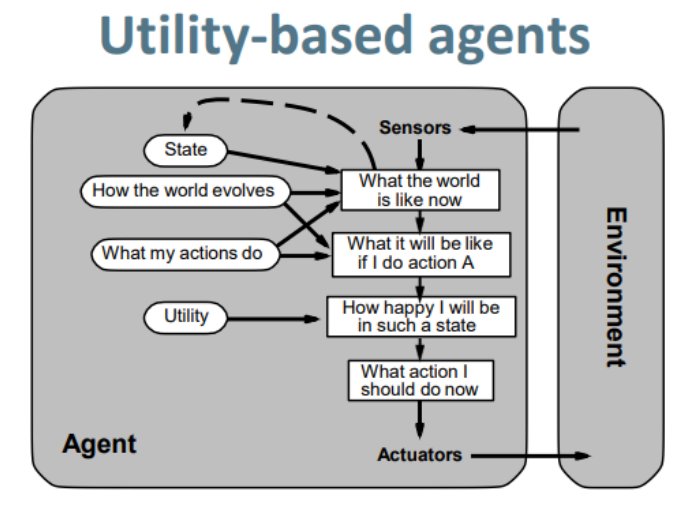
上图种我们可以看到它有个utility function(效用方程)这玩意就是个表现评测,它就是来叫智能体做些可以增大效用值得行为.
当然了,有时候根据增大效用值所作得行为可能会和部分目标(可能有多个目标)产生冲突,这时候就有个trade off了举个例子速度和安全,看你是想达成大部分目标用最小得代价还是全达成但代价高.
再举个例子,来计算下效用值
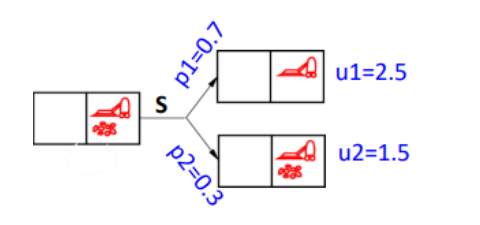
计算吸尘(suck,简写s)这个行为得效用值. 如果清洁机吸尘,那么有70%概率吸干净,30%吸不干净. 那么会有俩状态,一个吸干净了,一个还有垃圾,如果吸干净了,加1分,那么最终得分2.5分.如果吸不干净了,就不给分了,那么最终得分1.5分. 那么效用值得期望为0.72.5+0.31.5=2.2. 同理计算其他行为,小弟在这就乱编几个行为效用值了,假如啥也不操作效用期望值为0,向左走效用期望值为1.5. 那么很明显智能体会做效用期望值最大得行为,即吸尘.
(5).Learning agents学习智能体
首先,上述所有类型得智能体都能变成学习智能体.学习智能体允许智能体在未知的环境中运行,并且与最初的知识相比越来越胜任.
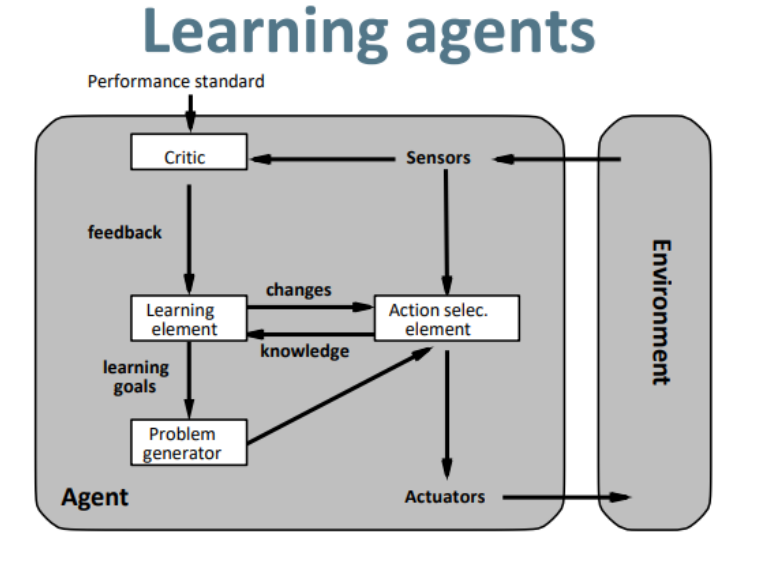
-
critic: 对智能体的动作反馈
-
Action selection element: 由学习要素改变行为,从而讲改变的行为所做出的结果作为知识反馈回学习要素,进而更新总结学习要素. 根据性能标准来告诉学习元件:智能体(agent)的成功程度,即feedback—好,坏.例如:下棋将死对谁,但它需要一个性能标准来确定这是一步好棋.
-
Learning element(学习要素): 根据critic的反馈来改变行为选择要素(action selection element).利用评论元件的反馈(feedback),并决定该如何修改执行元件(Action selec element)以在未来做的更好.执行元件做完后的结果作为反馈(Knowledge)返还给学习元件.
-
Problem generator:就是产生新的做法,从而进行学习获取这个做法做后的效果经验.
-
Performance standard:来评测你做的好不好,对外部的环境加以评价,并找到要学习的要素,从而更新行为.提出可以导致新的有信息价值的经验的行动.
六.Exploration(探索) vs Exploitation(开发)
探索和开发这俩话题是针对于学习智能体来说的.
(1).Exploration(探索):利用已知的经验和知道的手段,做出最好的效果.
(2).Exploration(开发):尝试着出点新招数或手段,你可以随机做出点行为,看看环境状态改变好不好,从而变成学习要素来进化你的行为选择.
在实践中, 探索一般会卡在某个子优解的行为,但开发呢会消耗大量的代价例如时间.智能体需要更多的探索,从而避免卡在某个局部优解的行为,但探索花费的更多.
七.结语
这一章带大家粗略的理解下什么是智能体,小弟希望大家能看的开心,毕竟难的干货在后面,珍惜本章的快乐时光.
若有谬误请指出,在此感谢


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









