







 本文详细介绍C++在算法竞赛中的应用,包括基本语法、STL容器、常用函数及C++11新特性等内容,帮助初学者快速掌握C++编程技巧。
本文详细介绍C++在算法竞赛中的应用,包括基本语法、STL容器、常用函数及C++11新特性等内容,帮助初学者快速掌握C++编程技巧。
说实话,用c语言来写算法竞赛(蓝桥杯,acm)也是完全没有问题的,说是转型c++,其实并不是,只是借助了c++的一些STL容器(听起来很高级,其实就是栈,队列啥的)和一些库函数,例如sort函数,比快速排序啥的都要快,c++只需要一行就搞定了,不用再像c语言一样写很多,并不是真正的转型,也没必要担心自己学不会,还是c语言那老一套,只不过scanf printf换成cin cout等等。不过,用c++来写,确实省时省劲,还是很值得去学的!
有很多教程和视频都做得十分晦涩难懂,生怕你学会了…所以我今天来做个简单版的,希望能帮到你!文章可能会有些长,但是请相信我,绝对实用!
一.基本语法
这一部分都很基础也很简单,基本上看一遍就记住了,主要是多打几遍代码
1.C++基本格式
#include <iostream>//必写,其实就是c的#include <stdio.h>
#include <bits/stdc++.h>//万能头文件,强烈建议必写
using namespace std;//必写,声明使用std名称空间,不用理解
int main()//主框架和c一样
{
return 0;
}
2.输入输出和变量声明
#include <iostream>
#include <bits/stdc++.h>
using namespace std;
int main()
{
int a,b;
cin>>a>>b;//输入,就是这个格式 cin和>>
cout<<a<<b;//输出,就是这个格式 cin和<<
int c[10];
for(int i=1;i<=10;i++)//变量声明也很简单,可以在for前面定义i,
//也可以直接在for循环后面定义i,和c就这点不一样
{
cin>>c[i];
}
for(int i=1;i<=10;i++)
{
cout<<c[i]<<endl;//endl就是c中的\n,换行用的
}
return 0;
}
3.bool变量和const定义常量
bool类型也很简单,就俩变量true和false。0是false,非0数就是true。没啥太大用处…
#include <iostream>
#include <bits/stdc++.h>
using namespace std;
int main()
{
bool a=true,b=0,c=-1,d=false;
cout<<a<<" "<<b<<" "<<c<<" "<<d;
return 0;
}
运行结果

const就类似于c中的宏定义,const定义的就是常量了,不能改变其值,尝试改变就报错

#include <iostream>
#include <bits/stdc++.h>
using namespace std;
int main()
{
const int MAX=100;//就是#define int MAX=100;
cout<<MAX;
return 0;
}
4.string类
其实就是字符串…
主要操作有 s=s1+s2,getline(sin,s),s.length,s.substr(n,m)
#include <iostream>
#include <bits/stdc++.h>
using namespace std;
int main()
{
string s1="hello ";//hello后面有个空格
cout<<s1<<endl;
string s2="world!";
string s=s1+s2;//超级方便,直接把俩字符串合并在一起了
cout<<s<<endl;
string s3;
//cin>>s3不能读空格,输入a b,只录入a
cout<<"输入s3"<<endl;
getline(cin,s3);//读空格,输入a b,录入a b
cout<<"s3:"<<s3;
return 0;
}
运行结果

s.length()是算字符串长度,和s.size()一样
s.substr(n,m)表示从第n个开始截取(算它本身),截m个
s.substr(n)表示从第n个开始截取(算它本身),一直截到尾
#include <iostream>
#include <bits/stdc++.h>
using namespace std;
int main()
{
string s="hello world!";
cout<<s.length()<<endl;//和s.size()一样
string s1,s2;
s1=s.substr(6,5);//表示从第6个开始截取(算它本身),截5个
//别忘了数组是从0开始的!
s2=s.substr(6);//表示从第6个开始截取(算它本身),一直截到尾
cout<<s1<<endl<<s2<<endl;
return 0;
/*运行结果就是
12
world
world!
*/
}
5.结构体
结构体就是不用和c一样定义的时候加struct了,直接结构体名 变量,省去了c中的typedef
#include <iostream>
#include <bits/stdc++.h>
using namespace std;
struct stu{
string name;
int age;
};
int main()
{
//c的写法
struct stu a[100];
//c++的写法
stu a[100];
return 0;
}
6.引用(&)
c++里面的 & 和c中的取地址符没关系,不重要,了解一下就行
#include <iostream>
#include <bits/stdc++.h>
using namespace std;
void c1(int a)
{
a=a+1;
}
void c2(int &a)
{
a=a+1;
}
int main()
{
int a=1;
c1(a);
cout<<a<<endl;
c2(a);
cout<<a;
return 0;
}
运行结果

说明引用会改变变量的值
二.STL容器
STL容器也很简单,不要被这个高大上的名字给吓到。容器就是用来装东西的,比如栈,队列这种,其主要操作无非是“增 删 改 查”这种。
STL容器所用的头文件直接用#include <bits/stdc++.h>就行,很简单,不用挨个记。
它们的长度计算基本上是用size函数,例如
queue <int> q;
q.size();
然后定义它们基本上就是 STL容器名 <类型> 名字,例如queue <int> q。
还有就是有的容器输出会使用迭代器,这个也很简单,看一看就知道了。
for(auto p=q.begin();p!=q.end();p++)//这个就是迭代器
{
cout<<*p<<" ";
}
1.vector
vector叫动态数组,基本用法如下
#include <iostream>
#include <bits/stdc++.h>
using namespace std;
int main()
{
vector <int> q;//创建名为q的一个int型动态数组,默认值是0
vector <int> a(10);//创建一个长度为10的动态数组,默认值是0
vector <int> b(10,2);//创建一个长度为10,元素值均为2的动态数组
cout<<"分配前长度"<<q.size()<<endl;
q.resize(10);//为q分配10个空间
cout<<"分配后长度"<<q.size()<<endl;
q.push_back(1);//往q里增加一个1
cout<<"追加后长度"<<q.size()<<endl;
for(auto p=q.begin();p!=q.end();p++)//不用知道q多长,很方便
{
cout<<*p<<" ";
}
//这个for循环很独特,它叫迭代器,就是遍历输出q中的元素
//最大的好处是不需要知道数组的长度,通用性很高,许多容器都能用
return 0;
}
运行结果

2.set
set叫集合,和数学上那个集合一样,所以里面的元素各不相同,并且会按从小到大帮你自动排好,基本用法如下
#include <iostream>
#include <bits/stdc++.h>
using namespace std;
int main()
{
set <int> s;//s后面不能加内容!!集合怎么能规定大小呢?
s.insert(4);//插入
s.insert(3);
s.insert(2);
s.insert(1);
for(auto p=s.begin();p!=s.end();p++)//也是可以用迭代器遍历输出
{
cout<<*p<<" ";
}
//从小到大自动排好序,所以应输出1 2 3 4
cout<<endl;
//find()是查找函数,其返回值是一个指针,所以只能用比较的方法来输出
//要是找到了就说明在end()之前,反之则不在集合里,这个记住就行了
cout<<"删除前 "<<(s.find(2)!=s.end())<<endl;
s.erase(2);//删除操作,把s里面的2删除了
cout<<"删除后 "<<(s.find(2)!=s.end())<<endl;
for(auto p=s.begin();p!=s.end();p++)
{
cout<<*p<<" ";
}
return 0;
}
运行结果

3.map
map叫键值对,类似于结构体,比如一个名字对应一个学号,键值对中两个元素是对应的,这个也会按从小到大(键的值,就是前面那个)帮你自动排好,基本用法如下
#include <iostream>
#include <bits/stdc++.h>
using namespace std;
int main()
{
map <string,int> m;//创建名为m的键值对
m["hello"]=2;
m["world"]=3;
m["apple"]=4;
cout<<m["hello"]<<endl;//这样是输出后面的值,这里就是2
//有时候不知道它里面都有哪些东西,这时候迭代器就派上用场了
cout<<"迭代器输出:"<<endl;
for(auto p=m.begin();p!=m.end();p++)
{
cout<<p->first<<" "<<p->second<<endl;
}
//这个迭代器有点不一样 ,因为键值对和结构体很像
//struct指针用p->,map也用p->
//p->first就是键,p->second就是值
cout<<"m的长度为 "<<m.size()<<endl;
return 0;
}
运行结果
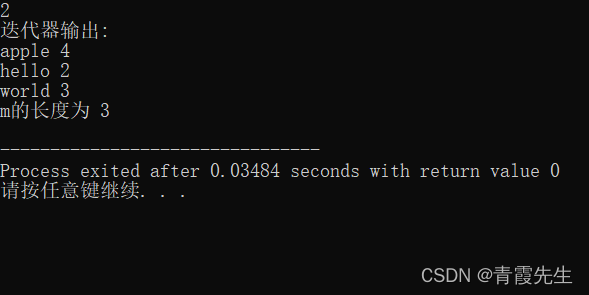
按从小到大(键的值,就是前面那个)帮你自动排好,apple<hello<world,所以先输出apple
4.undered_set和undered_map
这俩就是不自动排序的set和map,其余和set map一模一样
5.stack
stack叫栈,栈和队列是最常用的两个容器,这俩都不支持迭代器,栈是先进后出,类似于这样

1先进去的,但是底是封死的,所以1只能最后拿出来;4最后进去的,所以4是第一个拿出来
基本操作如下
#include <iostream>
#include <bits/stdc++.h>
using namespace std;
int main()
{
stack <int> s;
for(int i=1;i<=4;i++)
{
s.push(i);//压栈,就是往里加元素
}
cout<<"栈的长度为:"<<s.size()<<endl;
for(int i=1;i<=4;i++)
{
cout<<s.top()<<" ";//访问栈顶
s.pop();//出栈 (栈顶出去)
}
//栈的结构就导致了它只能获取栈顶
//所以想要遍历输出就得边读栈顶边出栈顶
//意思就是读一个栈顶紧接着把它弹出
return 0;
}
运行结果

因为按1 2 3 4顺序入栈,所以出栈顺序为4 3 2 1
6.queue
queue叫队列,非常常用,和栈不同,其原理是先进先出

1先进去的,其两端都是开的,所以1也是第一个出去的;4最后进去的,所以4是最后出来的
基本操作如下
#include <iostream>
#include <bits/stdc++.h>
using namespace std;
int main()
{
queue <int> q;
for(int i=1;i<=4;i++)
{
q.push(i);//入队
}
cout<<q.front()<<endl;//访问队首
cout<<q.back()<<endl;//访问队尾
q.pop();//出队
cout<<"出队后"<<endl;
cout<<q.front()<<endl;//访问队首
cout<<q.back()<<endl;//访问队尾
return 0;
}
运行结果

其遍历方法如下
#include <iostream>
#include <bits/stdc++.h>
using namespace std;
int main()
{
queue <int> q;
for(int i=1;i<=4;i++)
{
q.push(i)//入队
}
while(q.size()!=0)//q.size()是求其长度
{
cout<<q.front()<<" ";
q.pop();//出队
}
return 0;
}
三.常用函数
这一部分也很简单,主要是排序函数sort,其余两个不太重要,他们头文件都用#include <bits/stdc++.h>就行,不用单独记
1.sort函数
sort函数是用来排序的,主要功能是对一个数组(int a[i]或者vector进行排序。vector是容器,需要用v.begin()表示头,v.end()表示尾;而int a[i]使用a表示数组的首地址,a+n表示尾部。有时候数组的长度难以确认,所以推荐用vect动态数组,sort默认是从小到大排序
//普通数组的sort函数应用
#include <iostream>
#include <bits/stdc++.h>
using namespace std;
int main()
{
int a[100];
for(int i=0;i<=9;i++)
{
a[i]=10-i;
}
sort(a,a+10);//排序
for(int i=0;i<=9;i++)
{
cout<<a[i]<<" ";
}
return 0;
}
运行结果是1 2 3 4 5 6 7 8 9 10
//动态数组的sort函数应用
#include <iostream>
#include <bits/stdc++.h>
using namespace std;
int main()
{
vector <int> v;
for(int i=1;i<=10;i++)
{
v.push_back(11-i);
}
sort(v.begin(),v.end());//排序
for(auto p=v.begin();p!=v.end();p++)
{
cout<<*p<<" ";
}
return 0;
}
运行结果为1 2 3 4 5 6 7 8 9 10
如何自定义排序顺序呢?用cmp函数,它是一个布尔类型的函数,直接记住这个格式就行了
其写法如下
bool cmp(int x,int y)
{
return x>y;//只能有>和<,不能出现=,>=和<=也不行!!!
}
注意,return x>y;是从大到小排序,return x<y;是从小到大排序
#include <iostream>
#include <bits/stdc++.h>
using namespace std;
bool cmp(int x,int y)
{
return x>y;//只能有>和<,不能出现=
}
int main()
{
vector <int> v;
for(int i=1;i<=10;i++)
{
v.push_back(i);
}
sort(v.begin(),v.end(),cmp);//直接cmp就行,什么也别加
for(auto p=v.begin();p!=v.end();p++)
{
cout<<*p<<" ";
}
return 0;
}
运行结果为10 9 8 7 6 5 4 3 2 1
2.cctype头文件的一些函数
意思就是要在前面添加#include <cctype>才能用这些函数,很遗憾,万能头文件#include <bits/stdc++.h>依旧支持cctype包括的这些函数,所以直接写万能头文件即可…
其主要函数如下
isalpha()判断此字符是否为字母
islower()判断此字符是否为小写字母
isupper()判断此字符是否为大写字母
isalnum()判断此字符是否为字母或数字
isspace()判断此字符是否为空格或转换符
如果是则输出1,不是就输出0
tolower()将此字符转为小写字母
toupper()将此字符转为大写字母
#include <iostream>
//#include <bits/stdc++.h>
#include <cctype>
using namespace std;
int main()
{
char c='A';
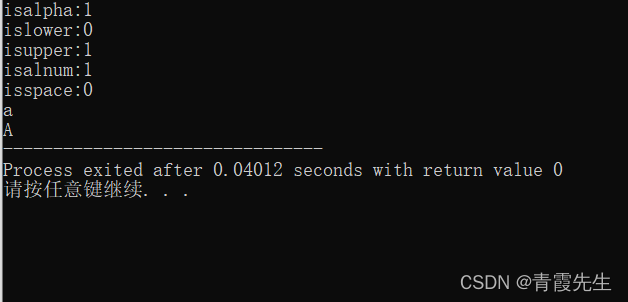
cout<<"isalpha:"<<isalpha(c)<<endl;//字母?
cout<<"islower:"<<islower(c)<<endl;//小写字母?
cout<<"isupper:"<<isupper(c)<<endl;//大写字母?
cout<<"isalnum:"<<isalnum(c)<<endl;//字母或数字?
cout<<"isspace:"<<isspace(c)<<endl;//空格或转换符?
char a=tolower(c);//转小写
cout<<a<<endl;
char b=toupper(c);//转大写
cout<<b;
return 0;
}
运行结果
3.bitset
bitset叫位运算,处理二进制比较方便,内容有点杂。
其定义为bitset <长度> 名称,例如bitset <5> b。
bitset类似一个字符数组,但是它是从二进制的低位到高位依次为b[0]、b[1]…所以按照b[i]的方式输出和直接输出 b的结果相反。
例如输入00111,则b[0]=1,b[1]=1…b[4]=0。
主要函数如下
#include <iostream>
#include <bits/stdc++.h>
using namespace std;
int main()
{
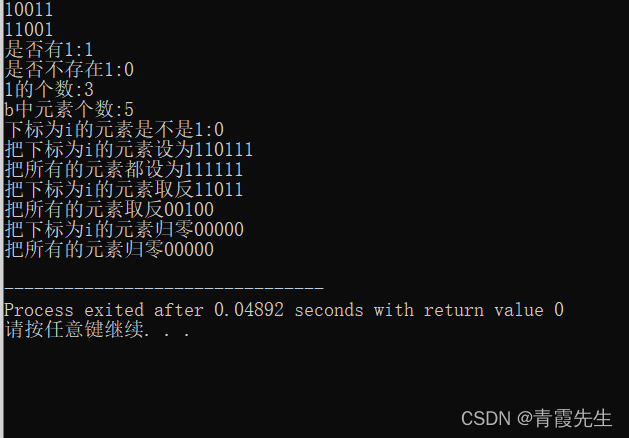
bitset <5> b1;//初始化为0,所以此处b1=00000
bitset <5> b(19);//b为19的二进制表示
//所以此处b=10011
cout<<b<<endl;
for(int i=0;i<=4;i++)
{
cout<<b[i];
}
cout<<endl;
cout<<"是否有1:"<<b.any()<<endl;
cout<<"是否不存在1:"<<b.none()<<endl;
cout<<"1的个数:"<<b.count()<<endl;
cout<<"b中元素个数:"<<b.size()<<endl;
cout<<"下标为i的元素是不是1:"<<b.test(2)<<endl;//b[2]=0
//set,flip,reset函数是直接返回新的二进制代码
//类似于cout<<b<<endl
//而且()里面为空就代表所有元素都操作
cout<<"把下标为i的元素设为1"<<b.set(2)<<endl;
cout<<"把所有的元素都设为1"<<b.set()<<endl;
cout<<"把下标为i的元素取反"<<b.flip(2)<<endl;
cout<<"把所有的元素取反"<<b.flip()<<endl;
cout<<"把下标为i的元素归零"<<b.reset(2)<<endl;
cout<<"把所有的元素归零"<<b.reset()<<endl;
return 0;
}
运行结果
两个关于字符串的操作
#include <iostream>
#include <bits/stdc++.h>
using namespace std;
int main()
{
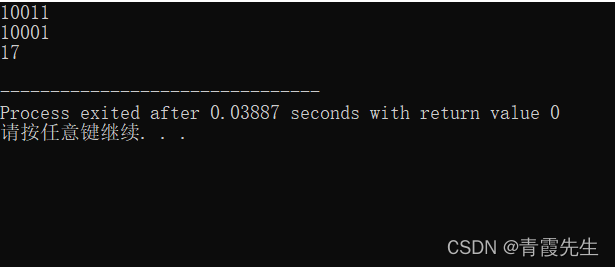
string m="1001010101";
bitset <8> b(m);//截取前8位,也就是10010101
cout<<b<<endl;
bitset <8> c(m,3,7);//1010101,但是前面定义了长度为8
//所以用0来补一位,就成了01010101
cout<<c<<endl;
return 0;
}
运行结果为
10010101
01010101
还有一个操作是unsigned long a=b.to_ulong(),这个很实用,就是把二进制转为十进制
#include <iostream>
#include <bits/stdc++.h>
using namespace std;
int main()
{
bitset <5> b(19);
cout<<b<<endl;
b.reset(1);
cout<<b<<endl;
unsigned long a=b.to_ulong();
cout<<a<<endl;
return 0;
}
运行结果
想一下bitset <5> b(19);,如果不是19,而是一个其二进制值长度超过5的数,会发生什么?
四.C++11
c++11有很多新特性,例如auto,to_srting(),stoi,stof等等,这些东西用起来也是很方便的,注意,用这些东西,还是要加万能头文件
1.auto声明
这个东西之前已经出现过了,在迭代器那里
for(auto p=s.begin();p!=s.end();p++)
{
cout<<*p<<" ";
}
除了迭代器以外,它还能声明一个变量
#include <iostream>
#include <bits/stdc++.h>
using namespace std;
int main()
{
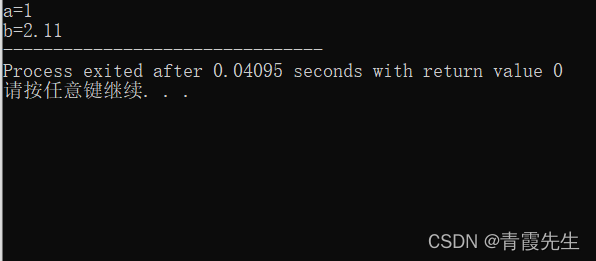
auto a=1;
auto b=2.11;
//注意,如果直接auto a;则会报错
//因为auto需要知道变量的数值才能声明变量的类型
cout<<"a="<<a<<endl;
cout<<"b="<<b;
return 0;
}
运行结果
2.基于范围的for循环
这个名字听起来有点不知所云,但是代码却很简单,有3种结构
int a[n] for(int i:a),for(int &i:a)和for(auto i:a)
//for(int i:a)和for(int &i:a)
#include <iostream>
#include <bits/stdc++.h>
using namespace std;
int main()
{
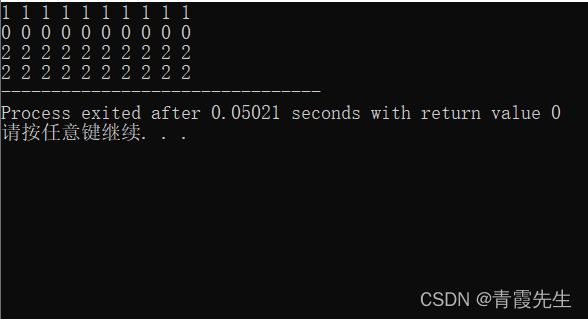
int a[10]={0};//默认都为0
for(int i:a)//仅传值,不改变数组元素本身的值
{
i++;//此处+1仅在这个循环内有效
cout<<i<<" ";
}
cout<<endl;
for(int i:a)
{
cout<<i<<" ";
}
cout<<endl;
for(int &i:a)//传址,改变数组元素本身的值
{
i=i+2;//此处+2会直接改变数组元素的值
cout<<i<<" ";
}
cout<<endl;
for(int i:a)
{
cout<<i<<" ";
}
return 0;
}
运行结果
for(auto i:a),auto就是上面讲的那个auto,也是能自动声明,有了auto就不用写int char之类的了,直接写auto就行。还有就是,所有的容器都可以使用这种方式来循环。(配合auto)
#include <iostream>
#include <bits/stdc++.h>
using namespace std;
int main()
{
vector <int> v(5,2);
for(auto i:v)
{
cout<<i<<" ";
}
return 0;
}
3.to_string
这个很简单,也很实用,功能就是把一个数字转化为字符串
#include <iostream>
#include <bits/stdc++.h>
using namespace std;
int main()
{
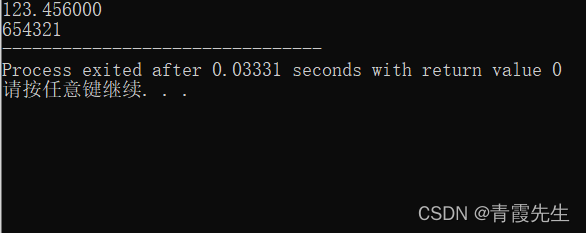
auto a=123.456;
auto b=654321;
string s1=to_string(a);
//转化时小数点后默认为6位,所以是123.456000
string s2=to_string(b);
cout<<s1<<endl;
cout<<s2;
return 0;
}
运行结果
如果用printf输出,则需要printf("%s",s.c_str());,固定的格式,记住就好。
还有就是,应该不难猜到,其实有to_string肯定也会有to_chars等等,不过不太常用,就不提了…
4.stoi和stod等等
stoi的意思是把字符串转化为int型变量,stod的意思是把字符串转化为double型变量,以此类推stof,stol,stold,stoll…
#include <iostream>
#include <bits/stdc++.h>
using namespace std;
int main()
{
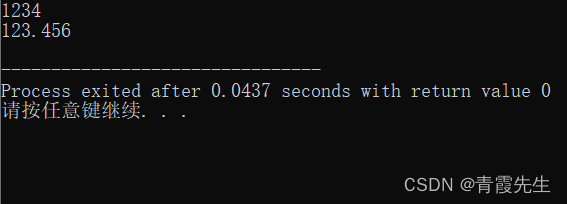
auto s1="1234";
auto s2="123.456";
auto a=stoi(s1);
auto b=stod(s2);
cout<<a<<endl;
cout<<b<<endl;
return 0;
}
运行结果
五.总结
到这里就算写完了,一共是4大类,共19个部分,总体来说都很简单,也算是把之前学的知识进行了一次系统的总结,基本上也算是把基础的东西全都概括了一遍。针对这些内容还有一个概括图,我放到另外一篇博客上了,有需要的可以去看看。

















 1539
1539

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









