






摘要
- 由于人体解析巨大的应用潜力,引起了广泛的研究。但是现存的数据集只有有限的图像和标注,缺乏人类外观的多变性;
- 本论文引入了一个新的benchmark,“Look into Person (LIP)”, 在可扩展性、多样性和难度方面取得了重大进展,对未来以人为中心的研究具有重大贡献;
- 这个全面的数据集包含50000多幅经过精心标注的图像,其中包含19个语义部件标签,它们是从更广泛的视角、遮挡和复杂背景中捕获的。
- 考虑到这些丰富的标注,我们对主要的人体解析方法进行了详细的分析,从而深入了解了这些方法的成功和失败。
- 此外,与现有的提高特征识别能力的工作相比,我们通过探索一种新的自我监督结构敏感学习方法来解决人体解析问题,这种方法将人体姿态结构引入解析结果,而不需要额外的监督(即在模型训练中不需要专门标记人体关节)。
- 我们的自我监督学习框架可以被注入到任何高级神经网络中,以帮助从全局的角度整合关于人类关节的丰富的高级知识,并改进解析结果。
- 在LIP和公共Pascal-Person部件数据集的验证了我们方法的优越性。
1. 引言
人体解析的目的是用细粒度的语义将人体图像分割成多个部分,并提供对图像内容的更详细的理解。可以应用在人再识别,人类行为分析。
近年来,卷积神经网络(CNNs)在人体解析中取得了令人振奋的成功。[13、17、15]。然而,正如在许多其他问题中所展示的,例如对象检测。[14]和语义分割。这些基于cnn的方法的性能在很大程度上取决于是否有带标注的训练图像。为了训练一个在实际应用中具有实际价值的人体解析网络,就需要一个大型数据集:具有衣服外观变化大,存在部分遮挡,图像边界存在断裂,丰富视角,背景复杂等特点的代表性实例。虽然存在一些具有特殊场景的训练集,比如时尚图片[30、9、13、17]和环境受限制的人(例如直立)[6],这些数据集的覆盖范围和可伸缩性有限,如图1所示。最大的公共人类解析数据集[17],到目前为止只有17000张时尚图片,而其他只有数千张。

此外,据我们所知,没有人试图建立一个标准的有代表性的benchmark,旨在为人体解析任务涵盖广泛的挑战。现在的数据集没有提供可以避免过拟合的用于评价的测试集,这阻碍了该任务的进一步发展。因此,我们提出了一个新的基准“Look into Person (LIP)”和一个自动报告评估结果的公共server。我们的基准在外观可变性和复杂性方面有较大优势,其中包括50462幅人体图像,其中像素级标注的19个语义部分。
最近的关于人体解析方法[ 5, 28, 31,30, 9, 25,19, 17 ],大都利用卷积神经网络和递归神经网络提高特征表达能力。为了获取丰富的结构信息,它们将cnn和图模型(例如条件随机场(Crfs))结合起来,类似于一般的对象分割方法 [35、4、27]。然而,现存的方法在新的LIP数据集上效果不太好。这种自下而上的产生式方法有时产生不合理的结果,图2,右胳膊和左肩膀相连
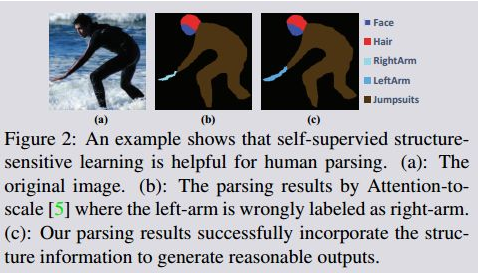
人体结构信息在人类姿态估计(32, 7)中已经得到了充分的探索,人体姿态估计提供了密集的关节点标注。然而,由于人体解析需要比姿态估计更广泛和更详细的预测,因此很难直接利用基于关节点的姿势估计模型在像素预测中包含复杂的结构约束。为了使生成的解析结果在语义上与人的姿态/关节结构一致,我们提出了一种新的结构敏感学习方法。除了使用传统的像素级部件标注作为监督外,我们还引入了一种结构敏感损失,从关节结构的角度来评估预测解析结果的质量。这意味着一个令人满意的解析结果应该能够保持一个合理的关节结构特征(例如,人体部件的空间布局)。值得注意的是,像素级解析标注和像素级姿态关节标注都是昂贵的,并且可能会导致模糊。因此我们直接从解析标注中产生近似的人体关节信息,并用这两个标注作为结构敏感损失函数的监督信号,因此称为自监督策略,记为Self-supervised Structure sensitive Learning (SSL) 。
我们的贡献概括为以下三个方面。1)提出了一种新的大规模benchmark和evaluation server,在19个语义部件标签上提供了50462幅具有像素级标注的图像。2)通过在基准测试上的实验,对现有的人工解析方法进行了详细的分析,以了解这些方法的成功和失败之处。3)提出了一种新的自监督结构敏感学习框架,该框架能够显式地增强解析结果与人的关节结构之间的一致性。在现有的pascal-Person部分数据集上和新的LIP数据及上,我们提出的框架明显优于以前的方法。
1.1 相关工作
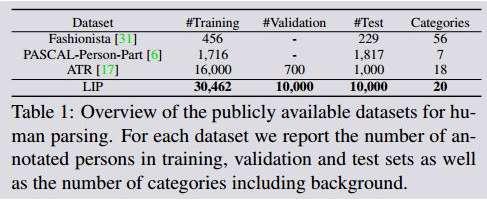
人体解析数据集 : 公用人体解析数据集概括如表1. 之前的数据集图像数量或者类别有限。我们的LIP数据集包括50462张图像,20类别,是目前为止最大的最复杂的人体解析数据集。其他数据集可以应用在检索,姿态估计等视觉任务中,而我们的数据集只关注人体解析。
人体解析方法: 最近,许多研究致力于人体解析[ 17, 31, 30,25, 19, 28,5 ]。例如,梁等人[ 17 ]提出了一种新的Co-CNN结构,该网络加入了多层上下文特征。除了人类分析之外,也有很多的研究关于其他物体(如动物或汽车)的分割[ 26, 27, 22 ]。为了获取丰富的结构信息基于先进cnn体系结构的,常用的解决方案包括cnn和crf的结合[4,35],采用多尺度特征表达[4、5、28]。Chen等人[5]提出了一种学习在每个像素位置加权多尺度特征的注意机制。以前的研究通过产生“pose-guided”的part 分割候选区域探索人体姿态信息,以引导人体解析。为了更高效、更有效地利用人类的结构,我们的方法是一种新的自我监督结构敏感的学习方法,它可以嵌入到任何网络中。
2. Look into Person Benchmark
在这一节中,我们将介绍我们的新的“Look into Person (LIP)”,这是一种新的大规模数据集,侧重于对人体的语义理解, 它具有几个吸引人的特性。首先,对于50462张带标注的图像,Lip比以前的类似尝试要大一个数量级,而且更具挑战性[31、6、17]。第二,对LIP进行了详细的像素标注,其中包含19个语义人体部件标签和一个背景标签. 第三,从真实世界场景中收集到的图像包含了具有挑战性的姿势和视角、严重的遮挡、各种外观和各种分辨率。此外,LIP数据集背景更复杂多样。我们还提出了一个适合人体解析的新的benchmark。
2.1. Image Annotation
LIP数据集中的人体图像是从microsoft coco训练集和验证集中裁剪的[18]。我们定义了19个人体部件或衣服标签,它们是帽子、头发、太阳镜、上衣、衣服、外套、袜子、裤子、手套、围巾、裙子、连体裤、脸、右臂、左臂、右腿、左腿、右脚、右脚鞋、左鞋,以及背景标签。
2.2. Dataset splits
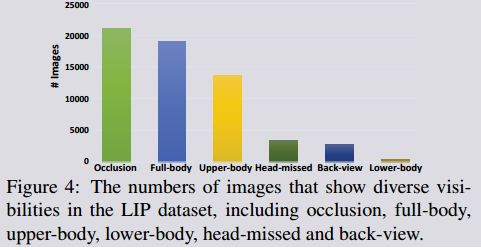
总的来说,数据集中共有50462张图像,其中包括19081张全身图像、13672张上身图像、403张下身图像、3386张头部丢失的图像、2778张后视图图像和21028张有遮挡的图像。我们将图像分成不同的训练、验证和测试集。在随机选择之后,我们得到了一个唯一的分割,包括30462个训练、10000个验证图像,以及10000个测试图像,其中的注释是为了基准测试而保留的。
2.3. Dataset statistics
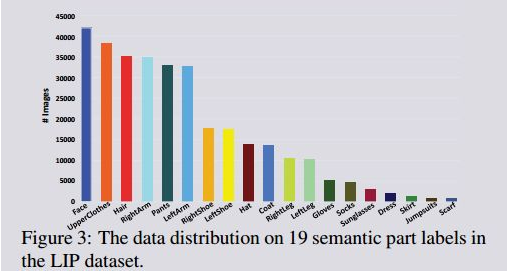
在这一部分中,我们详细分析了LIP数据集中的图像和类别。一般情况下,脸部、手臂和腿是人体中最显著的部分。然而,人类分析的目的是分析一个人的每一个区域,包括不同的身体部位以及衣服的不同类别。因此,我们定义了6个身体部分和13个衣服类别。在这6个身体部位中,以便进行更精确的分析,我们将手臂和腿分成左、右两部分,这也增加了任务的难度。至于服装类别,我们不仅有普通的衣服,如上衣、裤子和鞋子,而且也不常见的种类,如裙子和连衣裙。此外,小规模的附件,如太阳镜,手套和袜子也被考虑在内。图3给出了每个语义部件标签的图像数量。
LIP数据集中的图像包含不同的人体外观、视角和遮挡。此外,超过一半的图像会出现不同程度的遮挡。如果图像中出现了19个语义部分中的任何一个,但遮挡或不可见,则认为出现了遮挡。在更具挑战性的情况下,图像中人体实例是从后面拍的,这会导致左、右空间布局更加模糊。图4,概括了不同外观(遮挡、全身、上身、头部丢失、后视角和下体)的图像数量。
3. Empirical study of state-of-the-arts
在这一部分中,我们分析先进的人体解析或语义目标分割方法的性能了在我们的benchmark上。我们利用我们丰富的注释,并对影响结果的各种因素进行了详细的分析,如外观、foreshortening和观点。该分析的目的是评估现有方法在人体解析的各种挑战中的鲁棒性,并找出现有的局限性,以刺激进一步的研究发展。
在我们的分析中,我们充分考虑卷积网络[ 21 ](fcn-8s),深度编码解码结构[ 3 ](为),(deeplabv2)[ 4 ]和注意机制[ 5 ](注意),这些方法都取得了优异的性能。为了进行公平的比较,我们在LIP训练集上对每种方法进行了30次迭代,并在验证集和测试集进行了评估。对于Depplabv 2,我们使用的vgg-16模型而没有CRF。同[5,28],采用IoU和pixel-wise accuracy 作为评价指标。
3.1. Overall performance evaluation
我们首先分析每个方法的总体性能,概括在表2和表3。在LIP验证集,在这四种方法中,[5]通过对多尺度特征进行加权的注意模型,获得了最佳结果,平均精度是54.39%,Iou是42.92%。而fcn-8s[21](28.29%)和SegNet[3](18.17%)表现明显差。在LIP上也观察到了类似的性能。这一比较的有趣结果是,所取得的性能大大低于其他分割基准(如pascal voc)上当前的最佳结果[10]。这表明,由于大部分部件尺度较小,标签类别多样,所以人体解析比其他对象层级的分割更有挑战性,未来也更值注意。
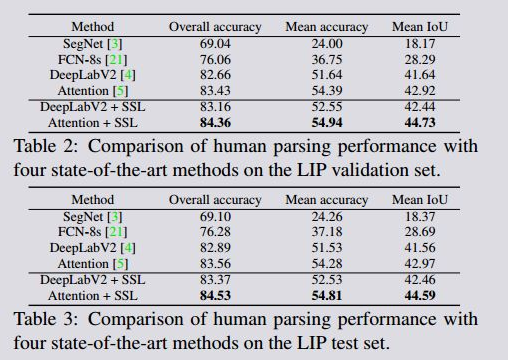
3.2. Performance evaluation under different challenges
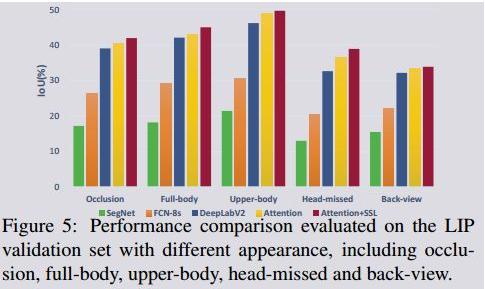
我们进一步分析了每种方法在以下五个挑战性因素方面的性能:遮挡、全身、上身、头部丢失和后视野(back-view)(见图5)。我们在LIP数据集上对以上4中方法进行评估,包含4277张包含遮挡的图像,452张全身图像,793张上身图像,112张头部丢失图像和661张背面图像.。正如预期的那样,在受到不同因素的影响时,性能会有所不同。Back-view显然是最具挑战性的案例。
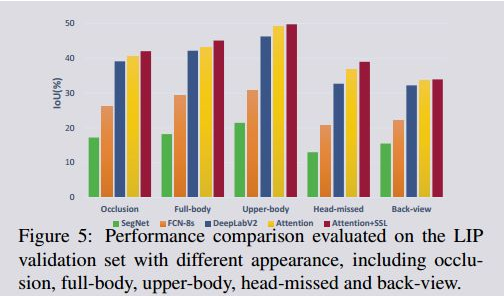
例如,注意[5]从42.92%降到了33.50%。第二大影响因素是头部的外观。所有方法的得分都比整组平均分数低得多。这种表现也因遮挡而受到很大的影响。全身图像的结果最接近平均水平。相比之下,上半身相对来说是最简单的情况,在这种情况下,语义部分较少,部件区域通常更大。从这些结果中,我们可以得出结论:Head(或Face)是现有人体解析方法的重要线索。如果头部部分在图像或在back-view中消失,则出现模糊结果的概率会增加。此外,由于存在,小尺度部件的存在(如,鞋子,袜子),导致下半身部件解析要比上半生更难。在这种情况下,人体关节结构在人体解析中会起到更重要的作用。
3.3. Per-class performance evaluation
为了更详细地讨论和分析LIP数据集中的20个标签中每个类别,我们进一步报告了IOU在LIP验证集上每个类别的性能,如表4所示。我们观察到,对于较大区域的标签,如脸、上装、外套和裤子,其效果要比太阳镜、围巾和裙子等小区域标签的效果要好得多。Attention[[5]和DeepLabV2[4), 由于使用了多尺度特性,小标签的性能更好。

3.4. Visualization comparison
图8给出了四种方法的定性比较结果,并给出了五种影响因素下的解析结果。对于稍微遮挡的上身图像(a),四种方法都表现良好,误差较小.。对于back-view(b),所有四种方法都错误地将右臂标记为左臂。最糟糕的结果出现在头部漏掉的图像(c)上。SegNet [3]和FCN-8 [21]不能识别手臂和腿,而DeepLabV2 [4]和Attention [5] 在手臂、腿和鞋子上都出现错误。此外,严重的遮挡(d)对性能影响也很大。全身性不那么具有挑战性,但像鞋子这样的全身图像中的小物体也很难精确预测。而且,从(c)和(d)观察可知,从人体配置的角度来看,由于现存的方法缺少人体结构信息,使得一些解析结果不合理,(例如,脚上的两只鞋)。总的来说,人体解析比一般的目标分割还要更困难。特别,为了增强对人体部位和服装结构的预测能力,我们应该更过注意的人体结构,才能使得分割结果会更合理,更符合人体配置。因此,我们考虑将人的解析结果和身体关节结构联系起来,以找到一种更好的人的解析方法。

4. Self-supervised Structure-sensitive Learning
4.1. Overview
如前所述,现有的人体解析方法的一个主要缺陷是缺乏对人体形态(human body configuration )的考虑,该问题主要是在人体姿态估计问题上研究的。人体解析和姿态估计的旨在对每幅图像进行不同粒度的标记,即像素级语义标注和逐关节结构预测。像素级标记可以解决更细节的问题,而关节结构提供了更高层次的结构信息.。然而,最领先的姿态估计模型[32,7]仍然有许多问题。与从解析注释中提取的关节点相比,其预测的关节没有足够高的质量来指导人体的解析。此外,位姿估计中的节点与解析注释不一致。此外,位姿估计中的节点与解析标注的关节点是不一致。例如,只有在没有任何衣服覆盖的情况下,手臂才被标记为ARM,而姿态标注则与衣服无关。为了解决这些问题,在本工作中,我们将研究如何利用信息丰富的高层结构信息来guid像素级预测。我们提出了一种新的自监督结构敏感学习方法,它引入了自监督结构敏感损失函数,从关节点结构的角度评价预测分析结果的质量,如图6所示。

具体来说,为了使用传统的像素级标注作为监督,我们还直接从解析标注生成近似人的关节,这样也可以引导人体解析的训练。为了显式地使产生的解析结果与人体的结构语义上更一致,我们将关节结构损失作为分割损失的一部分,我们称之为结构敏感损失。
4.2. Self-supervised Structure-sensitive Loss
一般来说,对于人体解析任务,除了像素级注释之外,没有提供其他广泛的信息。这意味着在不使用辅助信息的情况下,我们必须从解析标注中找到结构敏感监督信息。由于人体解析的结果是具有像素级标签的语义部件,因此我们试图探索人体解析结果中包含的位姿信息。定义9个关节构成姿态结构,分别是头部、上身、下身、左臂、右臂、左腿、右腿、左脚、左脚和右脚的中心部位。头部区域是通过合并帽子、头发、太阳镜和脸的解析标签来生成的。同样地,上衣、外套和围巾被合并为上身、裤子和下半身裙则是下半身。其他区域也可以通过相应的标签获得。图7示为不同人体生成的人体关节的一些例子。同[24],对于每一个解析结果和相应的ground truth (GT),我们计算区域的中心点,以获得以热图表示的关节,以使训练更加顺利。然后利用欧几里德度量来评价生成的节点结构的质量,同时反映了预测的解析结果与GT之间的结构一致性。最后,通过加权关节结构信息获得像素级分割损失函数。因此,整个人体解析网络就成为了结构敏感损失自我监督的网络。


是第i个关节热度图,是根据解析结果计算的得到。同样,
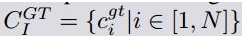
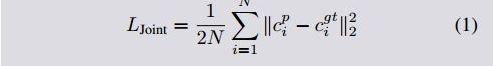
最终的结构敏感损失函数即为

是关节损失函数和解析分割损失函数的组合,具体如下:

其中,

是根据解析结果计算的逐像素的softmax损失函数。
我们将我们的学习框架称为“自我监督”,因为上述结构敏感的损失可以从现有的解析结果中产生,而不需要任何额外的信息。因此,我们的自我监督学习框架具有良好的适应性和可扩展性,可以被应用到任何网络中,从而有助于从全局的角度整合有关人体关节的丰富高层信息。
5. Experiments
5.1. Experimental Settings
Dataset: 我们在两个具有挑战性的数据集上评估我们的self-supervised结构敏感的学习方法。一个是公共的PASCAL-Person-part 数据集,其中有1716个训练图像,1817测试图像。根据[ 5, 28 ],6种部件标签:背景,头,躯干,上下手臂和上/下腿。另一个是LIP数据集,该数据集考虑了姿态,遮挡,身体断裂等多种影响因素。
Network architecture: 我们利用公开的模型,Attention[5] ,以其领先的精度和竞争效率成为基础结构。我们还训练了一个vgg-16,基于Depplabv 2的网络[4],该网络采用Atrous卷积、多尺度输入和Atrous空间金字塔池。
Training: 我们使用的是由Depplabv 2[4] 提供的预训练的模型和网络设置。Attention[5],输入图像的比例为321×321。采用两个训练step进行培训: 首先,在基础网络上用LIP数据集训练30epochs,大约需要两天。然后采用“自我监督”策略对模型进行结构敏感损失的微调.。我们对网络进行了大约20个epochs的微调,大约需要一天半的时间。我们使用随机梯度下降训练所有模型,batch size是10张图像,动量为0.9,权重衰减为0.0005。在测试阶段,一幅图像平均需要0.5秒。
Reproducibility: 该方法采用Caffe 框架,GTX TITAN X GPU 12G 内存。代码及模型在https://github.com/Engineering-Course/LIP_SSL
5.2. Results and Comparisons
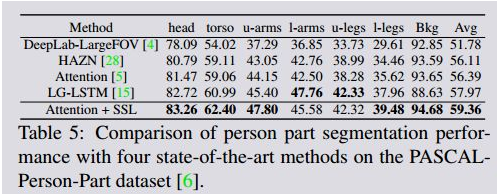
PASCAL-Person-Part dataset 数据集:
LIP dataset数据集:


5.3. Qualitative Comparison
















 5424
5424











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









