






首先呢,这是一个非监督算法,因此它约束的方式就是左右一致性检测,用warp来处理左右图,详见3.1。作者声情并茂的讲述自己就是不要gt。。
网络结构

五部分组成 特征提取 交叉特征向量融合 3D特征匹配 soft-argmin 最后通过图像warp来做约束。
特征提取
有了特征提取,就可以不虚那些复杂区域啦。以往传统的方法相当于是取像素域的原始特征,而深度学习取得特征则是自己去学的
具体特征怎么取的呢,是跟GC-Net一样的。
构建特征向量
通过学习的特征来构建匹配代价空间,需要先对视差范围做一个确定,然后将左右特征图片concated起来,从而生成最终的特征向量
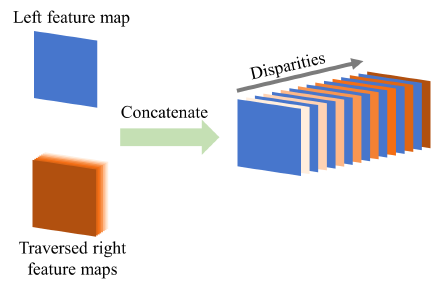
左图复制D份,右图平移D。然后相间的concat。
对3D特征进行regularization
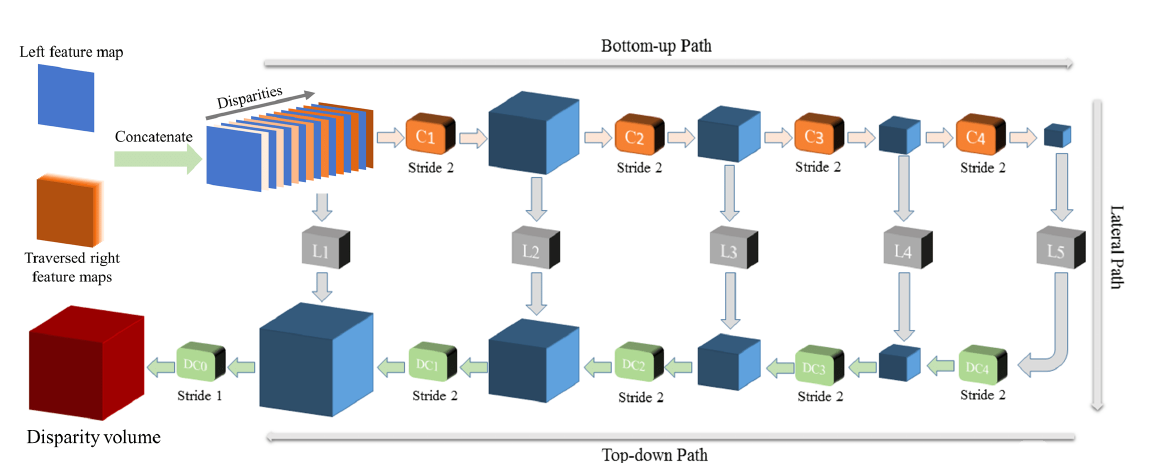
3D卷积反卷积
所以这篇文章就是非监督的GC-Net
简直一模一样~~~
真的是醉了
浪费了时间读这篇文章。。















 3754
3754

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









