







第十章 系统级I/O
输入/输出是在主存和外部设备之间复制数据的过程:
- 输入从 IO 设备复制数据到主存
- 输出从主存复制数据到 IO 设备
在 Linux 系统中,C/C++ 等高级语言的 I/O 函数都是通过内核提供的系统及 Unix I/O 实现的。
学习 Unix I/O 的意义:
- I/O 是系统操作不可或缺的一部分。如 I/O 在进程的创建和执行中扮演者关键的角色。
- 有时只能使用 Unix I/O,比如读取文件的元数据(如文件大小、文件创建时间等)。
10.1 UnixI/O
一个 Linux 文件就是一个字节序列,所有的 I/O 设备都被模型化为文件,如网络、磁盘等,所有的输入和输出都被当做对相应文件的读和写来执行。
Linux 使用 Unix I/O 来作为处理文件的接口,它以一种统一且一致的方式来执行所有的输入和输出:
- 打开文件:应用程序通过要求内核打开相应的文件来访问一个 I/O 设备,内核返回一个用非负整数表示的描述符来标识这个文件。内核会记录有关这个打开文件的所有信息,应用程序只需记住描述符。
- Linux shell 创建的每个进程开始时都有三个打开的文件:标准输入(描述符为 0),标准输出(描述符为 1),标准错误(描述符为 2)
- 关闭文件:内核关闭文件时,释放打开文件时创建的数据结构,并将描述符恢复到可用的描述符池中。当一个进程终止,内核就会关闭所有打开的文件并释放它们的内存资源。
- 读文件:一个读操作就是从文件复制数据到内存。当读取到文件末尾会触发一个 EOF(end of file) 条件。
- 写文件。
- 改变当前的文件位置:对于每个打开的文件,内核保持着一个文件位置 k,它是从文件开头起始的字节偏移量,初始为 0。可以通过 seek 函数来显式设置当前位置 k。
int open(char *filename, int flags, mode_t mode); //若成功则返回文件描述符,若出错返回 -1
int close(int fd); // fd 是一个文件描述符
ssize_t read(int fd, void *buf, size_t n); //若成功则返回读的字节数,若 EOF 则返回 0,若出错返回 -1
ssize_t write(int fd, const void *buf, size_t n); //若成功返回写的字节数,若出错返回 -1
int stat(const char *filename, struct stat *buf);
int fstat(int fd, struct stat *buf);
lseek(); //更改当前文件位置,这里没细讲。
10.2 文件
Linux 文件有不同的类型:
- 普通文件:包含任意数据。应用程序常会将普通文件进一步分为文本文件(只包含 ASCII 或 Unicode 字符的文件)和二进制文件(其他所有文件)。对内核而言,两者没有区别。
- **目录:**包含一组链接的文件,其中每一个链接都是一个文件名。每个目录至少含有两个条目:“.” 表示到该目录自身的链接,“…” 表示到目录层次结构中父目录的链接。
- 套接字:用来与另一个进程进行网络通信的文件。
Linux 将所有的文件组织成一个目录层次结构,由根目录 (/) 确定
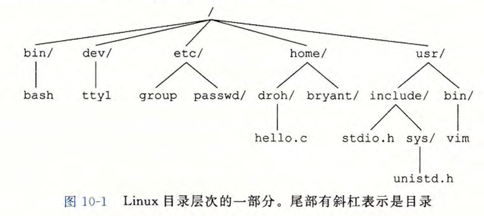
每个进程都有一个当前工作目录。
目录层次结构中的位置用路径名来指定,路径名有两种形式:
- **绝对路径名:**以一个斜杠开始,表示从根节点开始的路径
- 相对路径名:以文件名(包括目录)开始,表示从当前工作目录开始的路径。如 ./hello.c (斜杠前的点表示当前目录)
10.3 打开和关闭文件
进程通过调用 open 函数打开一个已存在的文件或创建一个新文件。
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int open(char *filename, int flags, mode_t mode); //若成功则返回文件描述符,若出错返回 -1
open 函数返回一个文件描述符,返回的描述符总是在进程中当前没有打开的最小描述符。
flag 参数指明进程如何访问这个文件:
- O_RDONLY:只读
- O_WRONLY:只写
- O_RDWR:可读可写
- O_CREAT:如果文件不存在,就创建它的一个截断的(空)文件
- O_TRUNC:如果文件已存在,就截断它
- O_APPEND:在写操作前,设置文件位置到文件的结尾处。
fd = open("foo.txt", O_WRONLY|O_APPEND, 0);
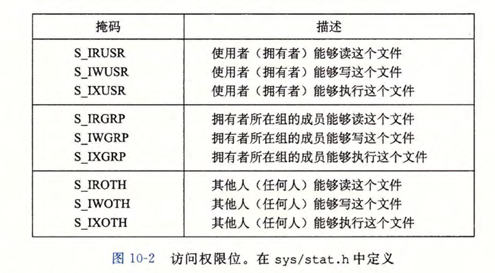
mode 参数指定新文件的访问权限位。
每个进程都有一个 umask,它是通过调用 umask 函数创建的,当进程通过带有 mode 参数的 open 函数来创建一个新文件时,文件的访问权限位被设置为 mode & ~umask。
umask(S_IRGRP, S_IROTH);
fd = open("foo.txt", O_WRONLY, S_IRUSER|S_IRGRP|SIROTH); //只有文件的拥有者能够读这个文件,其他用户都不能。
进程通过 close 函数关闭一个打开的文件,关闭一个已关闭的描述符会出错。
#include <unistd.h>
int close(int fd); // fd 是一个文件描述符
10.4 读和写文件
应用程序通过调用 read 和 write 函数来执行输入和输出。
#include<unistd.h>
ssize_t read(int fd, void *buf, size_t n); //若成功则返回读的字节数,若 EOF 则返回 0,若出错返回 -1
ssize_t write(int fd, const void *buf, size_t n); //若成功返回写的字节数,若出错返回 -1
read 函数从描述符为 fd 的当前文件位置复制最多 n 个字节到内存位置 buf。
write 函数从内存位置 buf 复制最多 n 个字节到描述符 fd 的当前文件位置。
ssize_t 和 size_t 的区别:
- size_t 是 unsigned long
- ssize_t 是 long
read 和 write 传送的字节少于 n (称为不足值)的情况:
- 读时遇到 EOF
- 从终端(键盘、显示器等)读文本行时,每个 read 函数一次传送一个文本行
- 读和写网络套接字。
10.5 用RIO包健壮地读写
RIO(Robust I/O) 包即健壮的 I/O 包,它会自动处理上下文的不足值。(这是本书的作者编写的一个包)
RIO 提供了两类不同的函数:
- **无缓冲的输入输出函数:**用于直接在内存和文件之间传送数据,没有应用级缓冲。
- 带缓冲的输入函数:可以高效地从文件读取文本行和二进制数据,文件的内容缓存在应用级缓冲区内。带缓冲的 RIO 输入函数是线程安全的。
10.5.1 RIO的无缓冲的输入输出函数
#include "csapp.h"
ssize_t rio_readn(int fd, void *usrbuf, size_t n); //若成功则返回字节数,若 EOF 则返回 0,若出错返回 -1。
ssize_t rio_writen(int fd, void *usrbuf, size_t n); //若成功则返回字节数,若出错返回 -1。
它们的参数、返回值与 Unix I/O 中的 read 和 write 的参数、返回值含义相同
对同一个描述符,可以任意交错地调用 rio_readn 和 rio_writen。
如果 rio_readn 和 rio_written 函数被一个从应用信号处理程序的返回中断,那么每个函数都会手动地重启 read 或 write。
rio_readn 函数的实现
ssize_t rio_readn(int fd, void *usrbuf, size_t n)
{
size_t nleft = n;
ssize_t nread;
char *bufp = usrbuf;
while(nleft > 0)
{
nread = read(fd, bufp, nleft);
if(nread < 0) //小于 0 即表示 read 函数遇到了错误
{
if(errno == EINTR) nread = 0; //如果被一个从应用信号处理程序的返回中断,就手动地重启 read
else return -1;
}
else if ( nread == 0 ) break; //等于 0 表示遇到了文件结束符 EOF
nleft -= nread;
bufp += nread;
}
return (n - nleft);
}
rio_writen 函数的实现
ssize_t rio_written(int fd, void *usrbuf, size_t n)
{
size_t nleft = n;
ssize_t nwriten;
char *bufp = usrbuf;
while (nleft > 0)
{
nwritten = write(fd, bufp, nleft);
if(nwritten <= 0)
{
if(errno == EINTR) nwritten = 0;
else return -1;
}
nelft -= nwriten;
bufp += nwriten;
}
return n;
}
理解:从 rio_readn 和 rio_writen 的实现看,它们似乎只是增加了一个处理中断的能力?
10.5.2 RIO的带缓冲的输入函数
缓冲的作用
比如要从文件读取一行数据,一种方法是用 read 函数来一次读取一个字节并检查是否是换行符,直到遇到换行符位置。这样效率不高,每读取一个字节都要陷入内核。
使用缓冲区是更好的方法。带缓冲的输入函数在函数内调用 read 来填满缓冲区,然后从缓冲区复制文本。当缓冲区变空就自动调用 read 重新填满缓冲区。
#include "csapp.h"
void rio_readinitb(rio_t *rp, int fd); //无返回值
ssize_t rio_readlineb(rio_t *rp, void *usrbuf, size_t maxlen); //若成功则返回字节数,若 EOF 则返回 0,若出错返回 -1。
ssize_t rio_readnb(rio_t *rp, void *usrbuf, size_t n); //若成功则返回字节数,若 EOF 则返回 0,若出错返回 -1。
rio_t 类型
RIO 中定义了一个类型 rio_t 来表示一个内部缓冲区(internal buf)
#defint RIO_BUFSIZE 8192 //定义一个宏表示缓冲区的大小
typedef struct{
int rio_fd; //缓冲区描述符
int rio_cnt; //缓冲区未读字节数
char *rio_bufptr; //缓冲区中下一个未读的字节
char rio_buf[RIO_BUFSIZE]; //缓冲区本身
} rio_t;
rio_readinitb 函数
每打开一个描述符,都会调用一次 rio_readinitb 函数,它将描述符 fd 和地址 rp 处的一个类型为 rio_t 的读缓冲区联系起来。
void rio_readinitb(rio_t *rp, int fd)
{
rp->rio_fd = fd; //缓冲区描述符即绑定的文件的描述符
rp->rio_cnt = 0;
rp->rio_bufptr = rp->rio_buf; //初始化时 rio_bufptr 指向缓冲区的第一个字节。
}
rio_read 函数
这是 RIO 中定义的一个工具函数,是 RIO 读程序的核心,rio_readlineb 和 rio_readnb 的实现调用了此函数。
函数的功能:从缓冲区读取 n 个字节到位置 usrbuf 处(读取前会首先检查缓冲区是否已空,如果已经空了,就先调用 read 填满缓冲区)。
static ssize_t rio_read(rio_t *rp, char *usrbuf, size_t n)
{
int cnt;
while (rp->rio_cnt <= 0) //如果缓冲区已经空了(即未读字节数<=0)
{
rp->rio_cnt = read(rp->rio_fd, rp->rio_buf, sizeof(rp->rio_buf));//填满缓冲区
if (rp->rio_cnt < 0)
if (errno != EINTR) return -1;
else if (rp->rio_cnt == 0)
return 0;
else
rp->rio_bufptr = rp->rio_buf;
}
cnt = n;
if (rp->rio_cnt < n)
cnt = rp->rio_cnt;
memcpy(usrbuf, rp->rio_bufptr, cnt);
rp->rio_bufptr += cnt;
rp->rio_cnt -= cnt;
return cnt;
}
rio_readlineb 函数
rio_readlineb 函数从文件 rp 读出下一个文本行(包括行尾的换行符),将它复制到内存位置 usrbuf,并用 NULL(\0) 字符来结束这个文本行。
rio_readlineb 函数最多读 maxlen-1 个字节,余下的一个字符留给 NULL 字符。文本行中超过 maxlen-1 字节的部分被截断,并用一个 NULL 结束。
ssize_t rio_readlineb(rio_t *rp, void *usrbuf, size_t maxlen)
{
int n, rc;
char c, *bufp = usrbuf;
for (n = 1; n < maxlen; n++)
{
rc = rio_read(rp, &c, 1); //从缓冲区一个一个读取字符
if (rc == 1) //如果顺利读取了一个字符
{
*bufp++ = c;
if (c == '\n') { n++; break; }
}
else if (rc == 0) // 如果遇到 EOF
{
if (n == 1) return 0;
else break;
}
}
*bufp = 0; //以空字符结尾
return n - 1;
}
rio_readnb 函数
rio_readnb 函数从文件 rp 最多读 n 个字节到内存位置 usrbuf。
对同一描述符,对 rio_readlineb 和 rio_readnb 的调用可以任意交叉进行。但是对带缓冲的函数的调用不应该和无缓冲的 rio_readn 函数交叉使用。
ssize_t rio_readnb(rio_t *rp, void *usrbuf, size_t n)
{
size_t nleft = n;
ssize_t nread;
char *bufp = usrbuf;
while (nleft > 0)
{
nread = rio_read(rp, bufp, nleft);
if (nread < 0) return -1;
else if (nread == 0) break;
nleft -= nread;
bufp += nread;
}
return (n - nleft);
}
10.6 读取文件元数据
通过 stat 和 fstat 函数可以读取文件的元数据
#include <sys/stat.h>
#include <unistd.h>
int stat(const char *filename, struct stat *buf);
int fstat(int fd, struct stat *buf);
stat 函数以文件名为输入,填写 stat 结构体中的各个成员。fstat 函数与 stat 相似,但是以文件描述符为输入。

stat 数据结构中,st_mode 成员编码了文件访问许可位和文件类型,st_size 成员包含了文件的字节数大小。
Linux 在 sys/stat.h 中定义了宏谓词(谓词函数)来确定 st_mode 成员的数据类型:
- S_ISREG(mode_t m)。是否是一个普通文件
- S_ISGIR(mode_t m)。是否是一个目录文件
- S_ISSOCK(mode_t m)。是否是一个网络套接字
10.7 读取目录内容
可以使用 readdir 系列函数读取目录的内容。
opendir 函数
#include<sys/types.h>
#include<dirent.h>
DIR *opendir(const char *name); //若成功,返回指向目录流的指针;若出错,返回 NULL
流是对有序列表的抽象。
函数 opendir 以路径名为参数,返回指向目录流(即目录项的列表)的指针。
readdir 函数
#include<dirent.h>
struct dirent *readdir(DIR *dirp);//若成功,返回指向下一个目录项的指针;若没有更多的目录项或出错,返回 NULL
函数 readdir 返回指向流 dirp 中下一个目录项的指针。若没有更多的目录项或出错,返回 NULL。其中如果出错 readdir 还会设置 errno。
可以通过检查 errno 是否被修改过来区分是出错还是没有更多的目录项
每个目录项都是一个结构
struct dirent{
ino_t d_ino;//文件位置
char d_name[256];//文件名
}
closedir 函数
#include<dirent.h>
int closedir(DIR *dirp);
函数 closedir 关闭流并释放所有的资源。
10.8 共享文件
可以使用多种方式来共享 Linux 文件。
内核表示打开的文件的方式
内核使用三个相关的数据结构来表示打开的文件:
-
描述符表。每个进程都有自己独立的描述符表,表项是由进程打开的文件描述符索引的。每个打开的描述符表项指向文件表中的一个表项。
-
**文件表。**文件表中包含打开文件的集合,所有的进程共享一个文件表。文件表中的每个表项包括:当前的文件位置(在文件中的读取位置,而不是文件所在位置)、引用计数(当前指向该文件的描述符表项数),一个指向 v-node 表中对应表项的指针。
-
- 引用计数:关闭一个描述符会减少相应的文件表表项中的引用计数,当引用计数减到 0,内核就删除该表项。
-
**v-node 表。所有的进程共享一个 v-node 表。**每个表项包含 stat 结构(文件的元数据)中的大多数信息,包括 st_mode 和 st_size 成员。
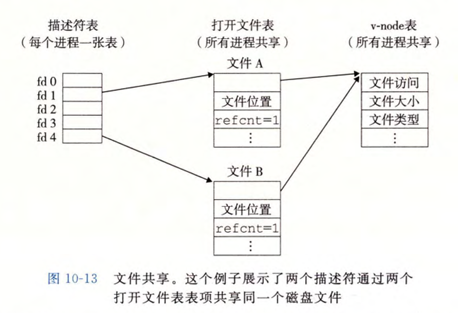
文件的共享
文件表中的不同表项可能表示同一文件。
多个描述符可以通过不同的文件表表项来引用同一个文件,每个描述符有各自的”当前文件位置“。如果以同一 filename 调用 open 函数两次,就会发生如此情况。
多个描述符也可以指向同一个文件表项来引用同一个文件,这时多个描述符具有相同的“当前文件位置”。比如调用 fork 生成的子进程有一个父进程描述符表的副本。父子进程中的描述符都指向相同的文件表项。
理解:多个描述符具有相同的文件位置意味着它们读取文件的进度会互相影响。
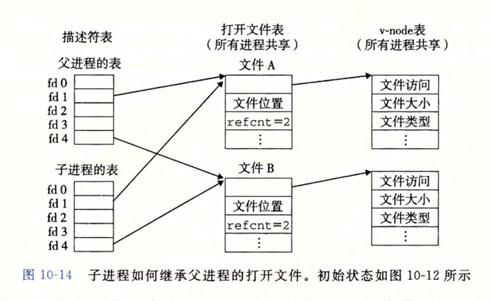
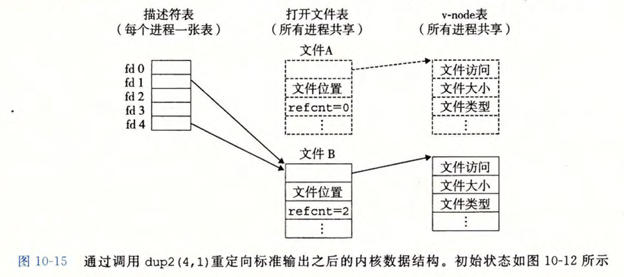
10.9 I/0重定向
Linux shell 提供了 I/O 重定向操作符,允许用户将磁盘文件和标准输入联系起来。
linux> ls > foo.txt // shell 将加载和执行 ls 程序并将标准输出重定向到磁盘文件 foo.txt
当一个 Web 服务器代表客户端运行 CGI 程序时也会执行一种相似的重定向。
dup2函数
I/O 的重定向的工作方式是使用 dup2 函数
#include<unistd.h>
int dup2(int oldfd, int newfd); //若成功返回描述符,若失败返回 -1。
dup2 函数赋值描述符表的表项 oldfd 到另一个表项 newfd,覆盖 newfd 之前的内容。如果 newfd 已经打开了,它会在复制 oldfd 之前关闭 newfd。
例子:标准输入在该进程的描述符表中对应了一个描述符 fd1,该描述符原本指向了表示文件 A 的文件表项,重定向后指向了描述符 fd4 所指向的表示文件 B 的文件表项。
10.10 标准I/O
C 语言定义了一个标准 I/O 库,为程序员提供了 Unix I/O 的较高级别的替代,它包括(但不止以下这些):
- **fopen 和 fclose :**打开和关闭文件
- fread 和 fwrite :读字节和写字节
- **fgets 和 fputs :**读字符串和写字符串
- **scanf 和 printf :**复杂的格式化的 I/O 函数
标准 I/O 库将一个打开的文件模型化为一个流,一个流就是一个指向 FILE 类型的结构的指针。每个 ANSI C 程序开始时都有三个打开的流:stdin, stdout, stderr
#include<stdio.h>
extern FILE *stdin; //标准输入(描述符为0)
extern FILE *stdout; //标准输出(描述符为1)
extern FILE *stderr; //标准错误(描述符为2)
类型为 FILE 的流是对文件描述符和流缓冲区的抽象。
流缓冲区的目的和 RIO 读缓冲区的目的一样:使开销较高的 Linux I/O 系统调用的数量尽可能小。
一个示例
比如有个程序要反复调用标准 I/O 的 getc 函数,每次读取一个字符。当第一次调用 getc 时,库通过调用一次 read 函数来填充缓冲区,然后将缓冲区中的第一个字节返回给应用程序。只要缓冲区还有未读字节,接下来 getc 都直接从流缓冲区得到服务。
10.11 综合:我该使用哪些I/O函数?
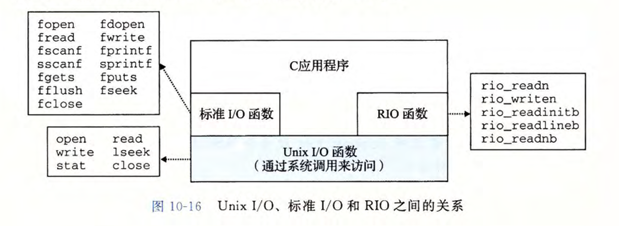
Unix I/O 是在操作系统内核里实现的。RIO 函数是本书作者编写的 read 和 write 的健壮的包装函数。
在程序中使用哪种函数遵循以下指导原则:
- 只要有可能就使用标准 I/O。
- 不要使用 scanf 和 readlineb 来读二进制文件。二进制文件中 0xa 字节并不表示换行符。
- 对网络套接字的 I/O 使用 RIO 函数。
套接字
Linux 对网络的抽象是一种叫做套接字的文件类型。套接字由文件描述符来引用,称为套接字描述符。进程通过读写套接字描述符来与其他计算机上进程通信。
标准 I/O 流的限制
标准 I/O 流有两个限制:
- 输入函数不能紧跟在输出函数之间,除非中间插入对 fflush, fseek, fsetpos 或 rewind 的调用。fflush 清空缓冲区,后三个函数调用 Unix I/O 中的 lseek 来重置当前的文件位置。
- 输出函数也不能紧跟在输入函数后。除非中间插入对 fseek, fsetpos 或 rewind 的调用,或输入函数遇到了文件结束符。
O 是在操作系统内核里实现的。RIO 函数是本书作者编写的 read 和 write 的健壮的包装函数。
在程序中使用哪种函数遵循以下指导原则:
- 只要有可能就使用标准 I/O。
- 不要使用 scanf 和 readlineb 来读二进制文件。二进制文件中 0xa 字节并不表示换行符。
- 对网络套接字的 I/O 使用 RIO 函数。
套接字
Linux 对网络的抽象是一种叫做套接字的文件类型。套接字由文件描述符来引用,称为套接字描述符。进程通过读写套接字描述符来与其他计算机上进程通信。
标准 I/O 流的限制
标准 I/O 流有两个限制:
- 输入函数不能紧跟在输出函数之间,除非中间插入对 fflush, fseek, fsetpos 或 rewind 的调用。fflush 清空缓冲区,后三个函数调用 Unix I/O 中的 lseek 来重置当前的文件位置。
- 输出函数也不能紧跟在输入函数后。除非中间插入对 fseek, fsetpos 或 rewind 的调用,或输入函数遇到了文件结束符。
对套接字不能使用 lseek 函数,所以标准 I/O 流难以用来处理套接字。















 150
150

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









