







CSDN爬虫(三)——网络爬虫模拟登陆两种策略
说明
- 开发环境:jdk1.7+myeclipse10.7+win74bit+mysql5.5+webmagic0.5.2+jsoup1.7.2
- 爬虫框架:webMagic
- 建议:建议首先阅读webMagic的文档,再查看此系列文章,便于理解,快速学习:http://webmagic.io/
- 开发所需jar下载(不包括数据库操作相关jar包):点我下载
- 该系列文章会省略webMagic文档已经讲解过的相关知识。
两种策略概述
- 策略一:模拟浏览器登录,用代码模拟表单填写,然后获取登陆后的信息,用apache的“HttpClients”进行信息保存。特点:操作复杂,需要有足够深的http相关的知识,才能灵活运用,并且许多网站有很多加密规则,需要具体问题具体解决;不过,不需要考虑cookie失效问题。
- 策略二:直接拿去cookie信息,进行设置。特点:操作简单,只要将登陆后的页面的cookie信息拿过来即可;不过,可能会用时间限制,超过一定时间就不能再使用了,需要重新设置。
- 推荐:第二种,对于开发小白,学习成本低。
策略一:模拟浏览器登录
- 注:代码参考网上,具体位置不祥。
代码预览
package com.wgyscsf.spider; import java.io.BufferedReader; import java.io.IOException; import java.io.InputStream; import java.io.InputStreamReader; import java.util.ArrayList; import java.util.List; import org.apache.http.HttpResponse; import org.apache.http.NameValuePair; import org.apache.http.client.ClientProtocolException; import org.apache.http.client.methods.HttpPost; import org.apache.http.client.methods.HttpUriRequest; import org.apache.http.message.BasicNameValuePair; import org.jsoup.Jsoup; import org.jsoup.nodes.Document; import org.jsoup.nodes.Element; import com.wgyscsf.utils.HttpUtils; /** * @author wgyscsf</n> * 编写日期 2016-9-24下午7:25:36</n> * 邮箱 wgyscsf@163.com</n> * 博客 http://blog.csdn.net/wgyscsf</n> * TODO</n> */ public class SimulateLoginPolicy1 { static boolean result = false; public static void main(String[] args) { // 登录页面,获取以及给服务器传递必要信息 loginCsdnPager(); // 登陆后即可以进入登陆后的页面。 try { loginedPager(); } catch (ClientProtocolException e) { // TODO Auto-generated catch block e.printStackTrace(); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } } /** * 登陆后的页面获取,全局可以用,比如http://my.csdn.net/wgyscsf也是可以用的。 */ private static void loginedPager() throws IOException, ClientProtocolException { //构造需要访问的页面 HttpUriRequest httpUriRequest = new HttpPost( "http://blog.csdn.net/wgyscsf"); // 添加必要的头信息 httpUriRequest .setHeader("Accept", "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8"); httpUriRequest.setHeader("Accept-Encoding", "gzip,deflate,sdch"); httpUriRequest.setHeader("Accept-Language", "zh-CN,zh;q=0.8"); httpUriRequest.setHeader("Connection", "keep-alive"); // 模拟浏览器,否则CSDN服务器限制访问 httpUriRequest .setHeader( "User-Agent", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.1916.153 Safari/537.36"); // 【特别注意】:这个一定需要和登录用同一个“httpClient”,不然会失败。登陆信息全部在“httpClient”中保存 HttpResponse response = HttpUtils.httpClient.execute(httpUriRequest); InputStream content = response.getEntity().getContent(); // 将inputstream转化为reader,并使用缓冲读取,还可按行读取内容 BufferedReader br = new BufferedReader(new InputStreamReader(content)); String line = ""; String result = ""; while ((line = br.readLine()) != null) { result += line; } br.close(); // 这里是获取的页码,就可以进行界面解析处理了。 System.out.println(result); } /** * 登录页面 */ private static void loginCsdnPager() { String html = HttpUtils .sendGet("https://passport.csdn.net/account/login?ref=toolbar");// 这个是登录的页面 Document doc = Jsoup.parse(html); // 获取表单所在的节点 Element form = doc.select(".user-pass").get(0); // 以下三个是服务器给的标记信息,必须具有该信息登录才有效。 String lt = form.select("input[name=lt]").get(0).val(); String execution = form.select("input[name=execution]").get(0).val(); String _eventId = form.select("input[name=_eventId]").get(0).val(); // 开始构造登录的信息:账号、密码、以及三个标记信息 List<NameValuePair> nvps = new ArrayList<NameValuePair>(); nvps.add(new BasicNameValuePair("username", "wgyscsf@163.com")); nvps.add(new BasicNameValuePair("password", "wanggaoyuan")); nvps.add(new BasicNameValuePair("lt", lt)); nvps.add(new BasicNameValuePair("execution", execution)); nvps.add(new BasicNameValuePair("_eventId", _eventId)); // 开始请求CSDN服务器进行登录操作。一个简单封装,直接获取返回结果 String ret = HttpUtils.sendPost( "https://passport.csdn.net/account/login?ref=toolbar", nvps); // ret中会包含以下信息,进行判断即可。 if (ret.indexOf("redirect_back") > -1) { System.out.println("登陆成功。。。。。"); result = true; } else if (ret.indexOf("登录太频繁") > -1) { System.out.println("登录太频繁,请稍后再试。。。。。"); return; } else { System.out.println("登陆失败。。。。。"); return; } } }结果预览
- 没有模拟登陆
- 模拟登陆
- 没有模拟登陆
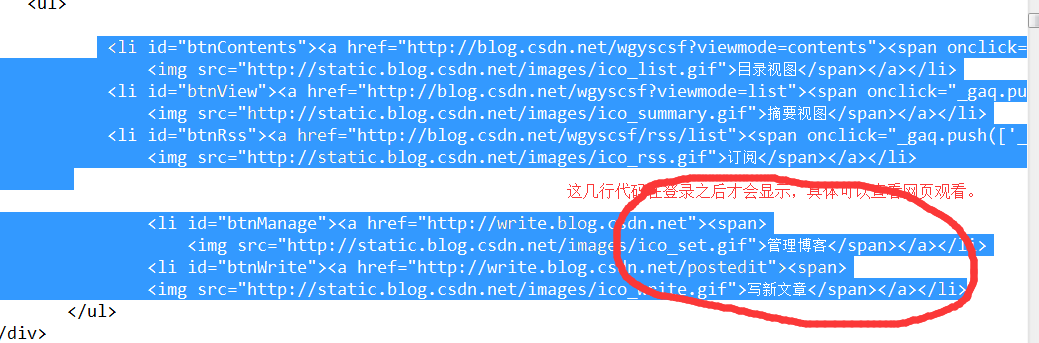
策略二:获取cookie
获取方式如下图
代码预览
package com.wgyscsf.spider; import us.codecraft.webmagic.Page; import us.codecraft.webmagic.Site; import us.codecraft.webmagic.Spider; import us.codecraft.webmagic.processor.PageProcessor; /** * @author wgyscsf</n> 编写日期 2016-9-24下午7:25:36</n> 邮箱 wgyscsf@163.com</n> 博客 * http://blog.csdn.net/wgyscsf</n> TODO</n> */ public class SimulateLoginPolicy2 implements PageProcessor { private Site site = Site .me() .setDomain("blog.csdn.net") .setSleepTime(300) .setUserAgent( "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_2) AppleWebKit/537.31 (KHTML, like Gecko) Chrome/26.0.1410.65 Safari/537.31") // 【重要】:以下信息可以模拟登陆,信息全部来自于浏览器 .addCookie("AU", "CA9") .addCookie("BT", "1475675181189") .addCookie("UD", "self-control%2Cself-free") .addCookie("UE", "wgyscsf@163.com") .addCookie("UN", "wgyscsf") .addCookie( "UserInfo", "*****") .addCookie("UserName", "wgyscsf") .addCookie("UserNick", "%E5%89%A9%E8%8F%9C%E5%89%A9%E9%A5%AD") .addCookie("__message_cnel", "0") .addCookie("__message_district_code", "00000") .addCookie("__message_gu_msg_id", "0") .addCookie("__message_in_school", "0") .addCookie("__message_sys_msg_id", "0") .addCookie("access-token", "****") .addCookie("dc_session_id", "****") .addCookie("dc_tos", "oeku99") .addCookie("uuid", "****") .addCookie("uuid_tt_dd", "****"); @Override public void process(Page page) { // 打印网页源码查看和登录之前有何区别,下面就可以进行页面解析了。 System.out.println(page.toString()); } @Override public Site getSite() { return site; } public static void main(String[] args) { Spider.create(new SimulateLoginPolicy2()).addPipeline(null) .addUrl("http://blog.csdn.net/" + "wgyscsf").run(); } }结果预览
同策略一结果

















 5023
5023

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









