







软件生命周期
一个软件产品或软件系统经历孕育、诞生、成长、成熟、衰亡等阶段,一般称为软件生存周期(软件生命周期)。
根据软件所处的状态和特征,划分软件生存周期。
需求定义、软件设计、软件实现、软件维护
使用角度
提出需求
用户根据需求,提出要解决的问题和需要的软件。
获取软件
这个过程主要是对获取软件的最佳途径做出决策并选择最佳的供应商。
- 购买软件
- 定制或开发软件
- 租赁软件或租赁服务
使用软件
一旦获得软件之后,用户将操作软件使之为其服务。
开发角度
软件生存周期的一些活动构成了软件开发生命周期,即从决定开发软件产品到交付软件产品。
- 定义软件:理解问题、可行性研究、需求分析
- 开发软件:软件设计、软件实现、软件测试
- 维护软件:软件交付、软件维护、软件退役
软件开发过程
瀑布式开发过程
适用于需求比较明确、小系统开发项目。
六个基本活动
制定计划、需求分析、软件设计、程序编写、软件测试、运行维护
特点
1,自上而下,相互衔接,固定次序
2,当前活动接收上一项活动的工作结果,将之作为下一项活动的输入,否则返回修改。
3,强调文档作用,每个阶段都需要仔细验证。
核心思想
按工序将问题化简,将功能的实现和设计分开,便于分工协作,即采用结构化的分析与设计方法将逻辑实现和物理实现分开。
缺点
1,阶段划分僵硬,产生大量文档,增加工作量。
2,开发是线性的,到整个过程的末期才能看到可运行软件,不利于快速相应变化的需求。
3,早期的错误要等到开发后期的测试阶段才能发现,增加了开发的风险。
4,瀑布模型的突出缺点是不适应用户需求的变化。
⭐增量开发模型
定义
指的是待开发的软件不是一次就能完成的,而是把软件分成一系列增量,完成一部分就交付一部分。
特点
1,引进了增量包的概念,无需等到所有需求明确,只需要某个需求明确了,就可进行开发。
增量的类型及其开发不止一种,可行的方式是首先实现那些明确的、核心的需求,也可以对需求按优先级排序,或者按照用户的要求实现增量。
2,本质是迭代开发的,反复执行**【分析——设计——编码——测试】**的过程。
3,最好是再架构设计完成之后再进行增量,保证系统的健壮性和可扩展性。
4,把瀑布模型的顺序特征与快速原型法的迭代特征相结合。
优点
1,短时间内向用户提交一个可运行软件,提供用户急需的部分功能。
2,每次只提交部分功能,用户有充分的时间学习、适应新的产品。
3,使软件适应需求的变化。
4,有利于系统维护。
能在较短的时间内向用户提交可完成部分工作的产品。
将待开发的软件系统模块化,可以分批次地提交软件产品,使用户可以及时了解软件项目的进展。
以组件为单位进行开发降低了软件开发的风险。一个开发周期内的错误不会影响到整个软件系统。
开发顺序灵活。开发人员可以对组件的实现顺序进行优先级排序,先完成需求稳定的核心组件。当组件的优先级发生变化时,还能及时地对实现顺序进行调整。
缺点
1,每次增加的部件可能会破坏已构造好的系统(避免则需要软件具备开放式的体系结构,否则系统将失去文档的结构)
2,容易退化为边做边改模型,使软件过程的控制失去整体性。
3,难以定义软件开发中的“增量”,界定它的工作量、需求范围、功能或特性。
由于各个构件是逐渐并入已有的软件体系结构中的,所以加入构件必须不破坏已构造好的系统部分,这需要软件具备开放式的体系结构。
在开发过程中,需求的变化是不可避免的。增量模型的灵活性可以使其适应这种变化的能力大大优于瀑布模型和快速原型模型,但也很容易退化为边做边改模型,从而是软件过程的控制失去整体性。
如果增量包之间存在相交的情况且未很好处理,则必须做全盘系统分析,这种模型将功能细化后分别开发的方法较适应于需求经常改变的软件开发过程。
作用
1, 开发初期的需求定义只是用来确定软件的基本结构,使得开发初期用户只需要对软件需求进行大概的描述;而对于需求的细节性描述,则可以延迟到增量构件开发时进行,以增量构件为单位逐个地进行需求补充。这种方式能够有效适应用户需求的变更。
2, 软件系统可以按照增量构件的功能安排开发的优先顺序,并逐个实现和交付使用。不仅有利于用户尽早用上系统,能够更好地适应新的软件环境,而且在以增量方式使用系统的过程中,还能获得对软件系统后续构件的需求经验。
3, 软件系统是逐渐扩展的,因此开发者可以通过对诸多构件的开发,逐步积累开发经验。实际上,增量式开发还有利于技术复用,前面构件中设计的算法、采用的技术策略、编写的源码等,都可以应用到后面将要创建的增量构件中去。
4, 增量式开发有利于从总体上降低软件项目的技术风险。个别的构件或许不能使用,但一般不会影响到整个系统的正常工作。
5, 实际上,在采用增量模型时,具有最高优先权的核心增量构件将会被最先交付,而随着后续构件不断被集成进系统,这个核心构件将会受到最多次数的测试。这意味着软件系统最重要的心脏部分将具有最高的可靠性,这将使得整个软件系统更具健壮性。
敏捷开发
适用于需求不明确的项目、创新性的项目或者需要抢占市场的项目。 期限紧迫。
定义
面对快速变化需求的一种软件开发能力。以用户的需求进化为核心,采用迭代、循序渐进的方式开发 。
在敏捷开发中,增量开发的迭代周期一般为1~6周。
基本技术
敏捷开发使用的UML符号主要是类图和时序图。
敏捷开发遵循软件开发的基本原则,同时也总结出了11条面向对象设计的原则,例如单一职责原则,里氏代换原则。
敏捷开发加强和推广了一些经典的实践,例如【意图导向编程】,指的是假设当前这个对象中已经有了一个理想的方法,它可以准确无误的完成想做的事情,而不是直接盯着每一点要求来编写代码。
敏捷开发也创造了一些新的技术或实践,例如:测试驱动开发、结对编程、代码重构、持续集成。
(测试驱动开发TDD:在一个微循环中,首先确认并且自动化进行一个失败的测试,然后编写足够的代码通过测试,在下一轮前重构代码。)
四个核心价值观
(1)个体和互动胜过流程和工具。
(2)工作的软件胜过详尽的文档。
(3)客户合作胜过合同谈判。
(4)响应变化胜过遵循计划。
十二条原则
(1)最优先要做的是通过尽早地、持续地交付有价值的软件满足客户需要。
(2)即使在开发后期也欢迎需求的变化,敏捷过程利用变化为客户创造竞争优势。
(3)经常交付可以工作的软件,从几星期到几个月,时间越短越好。
(4)业务人员和开发人员应该在整个项目过程中始终朝夕在一起工作。
(5)要善于激励项目人员,给他们以所需要的环境和支持,并相信他们能够完成任务。
(6)在开发小组中最有效率、也最有效果的信息传达方式是面对面的交谈。
(7)工作的软件是进度的主要度量标准。
(8)责任人、开发者和用户应该维持长期、恒等的开发节奏。
(9)对卓越技术与良好设计的不断追求将有助于提高敏捷性。
(10)简单——尽可能减少工作量的艺术——至关重要。
(11)最好的架构、需求和设计都源于自组织的团队。
(12)每隔一定时间,团队都要总结、反省工作效率,然后相应地调整自己的行为。
认识面向对象
类图表示法
下图表示一个Employee类,它包含name,age和address这3个属性,以及work()方法。

属性/方法名称前加的加号和减号表示了这个属性/方法的可见性,UML类图中表示可见性的符号有三种:
+:表示public
-:表示private
#:表示protected
属性的完整表示方式是: 可见性 名称 :类型 [ = 缺省值]
方法的完整表示方式是: 可见性 名称(参数列表) [ : 返回类型]
举例
类和类之间的六种关系
关联、聚合、组合、依赖、继承、实现
其中,聚合和组合 属于关联关系。
几种关系所表现的强弱程度依次为:组合 > 聚合 > 关联 > 依赖。
关联
是对象之间的一种引用关系。
单向关联
在UML类图中单向关联用一个带箭头的实线表示。上图表示每个顾客都有一个地址,这通过让Customer类持有一个类型为Address的成员变量类实现。
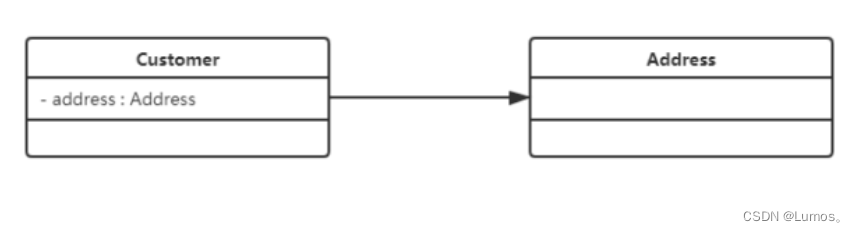
双向关联
双方各自持有对方类型的成员变量。
在UML类图中,双向关联用一个不带箭头的直线表示。上图中在Customer类中维护一个List<Product>,表示一个顾客可以购买多个商品;在Product类中维护一个Customer类型的成员变量表示这个产品被哪个顾客所购买。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bipUZNRN-1653721625842)(E:\嗷嗷嗷\image-20220523152940468.png)]](https://img-blog.csdnimg.cn/0a91798e9087450d8ad93ebe1fdfe6f3.png)
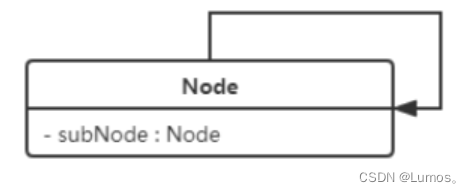
自关联
自关联在UML类图中用一个带有箭头且指向自身的线表示。上图的意思就是Node类包含类型为Node的
成员变量,也就是【自己包含自己】。
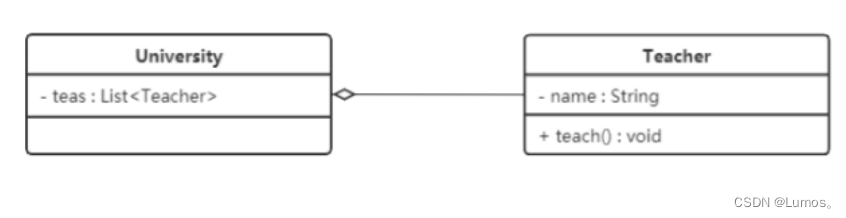
聚合
聚合关系是关联关系的一种,是强关联关系,是整体和部分之间的关系。
聚合关系也是通过成员对象来实现的,其中成员对象是整体对象的一部分,但是成员对象可以脱离整体对象而独立存在。例如,学校与老师的关系,学校包含老师,但如果学校停办了,老师依然存在。
在 UML 类图中,聚合关系可以用带空心菱形的实线来表示,菱形指向整体。下图所示是大学和教师的关系图。
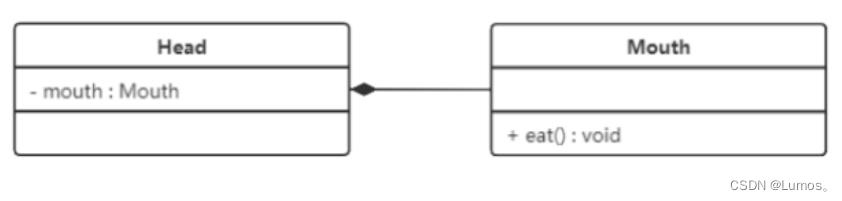
组合
组合表示类之间的整体与部分的关系,但它是一种更强烈的聚合关系。
在组合关系中,整体对象可以控制部分对象的生命周期,一旦整体对象不存在,部分对象也将不存在,部分对象不能脱离整体对象而存在。例如,头和嘴的关系,没有了头,嘴也就不存在了。
在 UML 类图中,组合关系用带实心菱形的实线来表示,菱形指向整体。下图所示是头和嘴的关系图:
依赖
依赖关系是一种使用关系,它是对象之间耦合度最弱的一种关联方式,是临时性的关联。在代码中,某个类的方法通过局部变量、方法的参数或者对静态方法的调用来访问另一个类(被依赖类)中的某些方法来完成一些职责。
在 UML 类图中,依赖关系使用带箭头的虚线来表示,箭头从使用类指向被依赖的类。下图所示是司机和汽车的关系图,司机驾驶汽车(Driver通过drive方法的参数访问Car类):
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BOHNBKJo-1653721625847)(E:\嗷嗷嗷\image-20220523153307449.png)]](https://img-blog.csdnimg.cn/09dea82ccc8c4823a6b033614d8f3b6e.png)
继承
继承关系是对象之间耦合度最大的一种关系,表示一般与特殊的关系,是父类与子类之间的关系,是一种继承关系。
在 UML 类图中,泛化关系用带空心三角箭头的实线来表示,箭头从子类指向父类。在代码实现时,使用面向对象的继承机制来实现泛化关系。例如,Student 类和 Teacher 类都是 Person 类的子类,其类图如下图所示:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-m4RDGtDG-1653721625848)(E:\嗷嗷嗷\image-20220523153527988.png)]](https://img-blog.csdnimg.cn/c19d2bc9c0694264b9e74028db6faafb.png)
实现
实现关系是接口与实现类之间的关系。在这种关系中,类实现了接口,类中的操作实现了接口中所声明的所有的抽象操作。
在 UML 类图中,实现关系使用带空心三角箭头的虚线来表示,箭头从实现类指向接口。例如,汽车和船实现了交通工具,其类图如图 9 所示。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-D4tE7Yj6-1653721625849)(E:\嗷嗷嗷\image-20220523153711322.png)]](https://img-blog.csdnimg.cn/c1ce100f7f19481fb27aa774ffd469e0.png)
面向对象的设计原则
单一职责原则
一个类只能由单一一种功能,不要实现过多的功能。
该原则可以视为面向对象程序对低耦合、高内聚原则的实践。
开放封闭原则
软件实体可以扩展,但是不能修改。在程序需要进行拓展的时候,不能去修改原有的代码。
**对扩展开放,对修改封闭。**是面向对象所有原则的核心。解决程序修改问题的核心是模块化。
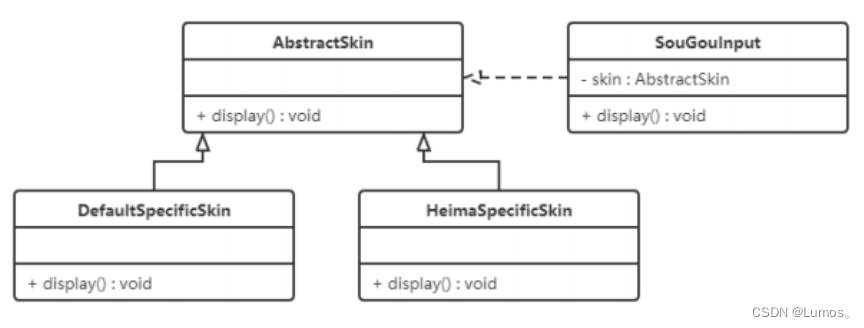
【例】搜狗输入法的皮肤是输入法背景图片、窗口颜色和声音等元素的组合。用户可以根据自己的喜爱更换自己的输入法的皮肤,也可以从网上下载新的皮肤。这些皮肤有共同的特点,可以为其定义一个抽象类(AbstractSkin),而每个具体的皮肤(DefaultSpecificSkin和HeimaSpecificSkin)是其子类。用户窗体可以根据需要选择或者增加新的主题,而不需要修改原代码,所以它是满足开闭原则的。
依赖倒转原则
高层模块不应该依赖低层模块,两者都应该依赖其抽象;**具体不应该依赖于细节,细节应该依赖于抽象。**该原则与传统的结构化分析和设计方法对立。
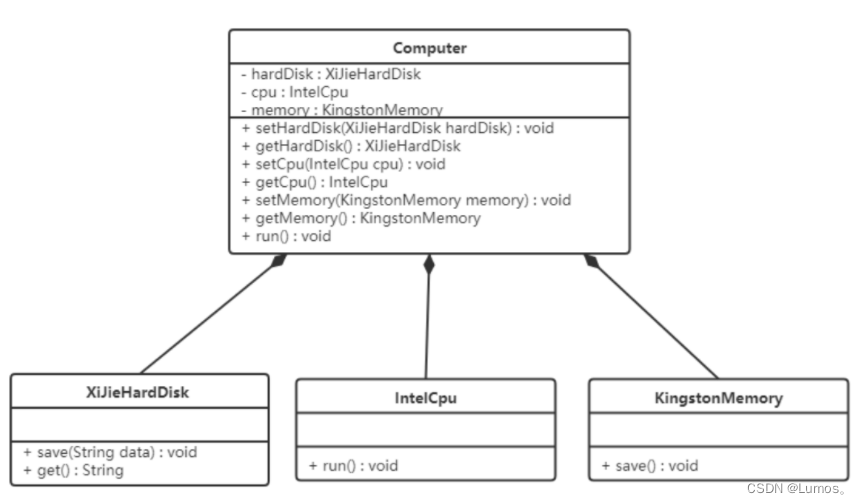
【例】组装电脑
现要组装一台电脑,需要配件cpu,硬盘,内存条。只有这些配置都有了,计算机才能正常的运行。选择cpu有很多选择,如Intel,AMD等,硬盘可以选择希捷,西数等,内存条可以选择金士顿,海盗船等。
希捷硬盘类(XiJieHardDisk):
public class XijieHardDisk implements HardDisk {
public void save(String data) {
System.out.println("使用希捷硬盘存储数据" + data);
}
public String get() {
System.out.println("使用希捷硬盘获取数据");
return "数据";
}
}
Intel处理器(IntelCpu):
public class IntelCpu implements Cpu {
public void run() {
System.out.println("使用Intel处理器");
}
}
金士顿内存条(KingstonMemory):
public class KingstonMemory implements memory {
public void save() {
System.out.println("使用金士顿作为内存条");
}
}
电脑(Computer):
public class Computer {
private XijieHardDisk hardDisk;
private IntelCpu cpu;
private KingstonMemory memory;
public XijieHardDisk getHardDisk() {
return hardDisk;
}
public void setHardDisk(XijieHardDisk hardDisk) {
this.hardDisk = hardDisk;
}
public IntelCpu getCpu() {
return cpu;
}
public void setCpu(IntelCpu cpu) {
this.cpu = cpu;
}
public KingstonMemory getMemory() {
return memory;
}
public void setMemory(KingstonMemory memory) {
this.memory = memory;
}
public Computer() {
}
public Computer(XijieHardDisk hardDisk, IntelCpu cpu, KingstonMemory memory) {
this.hardDisk = hardDisk;
this.cpu = cpu;
this.memory = memory;
}
public void run() {
System.out.println("计算机工作");
cpu.run();
memory.save();
String data = hardDisk.get();
System.out.println("从硬盘中获取的数据为:" + data);
}
}
测试类(TestComputer):
public class TestComputer {
public static void main(String[] args) {
Computer computer = new Computer();
computer.setHardDisk(new XiJieHardDisk());
computer.setCpu(new IntelCpu());
computer.setMemory(new KingstonMemory());
computer.run();
}
}
测试类用来组装电脑。
上面代码可以看到已经组装了一台电脑,但是似乎组装的电脑的cpu只能是Intel的,内存条只能是金士顿的,硬盘只能是希捷的,这对用户肯定是不友好的,用户有了机箱肯定是想按照自己的喜好,选择自己喜欢的配件。
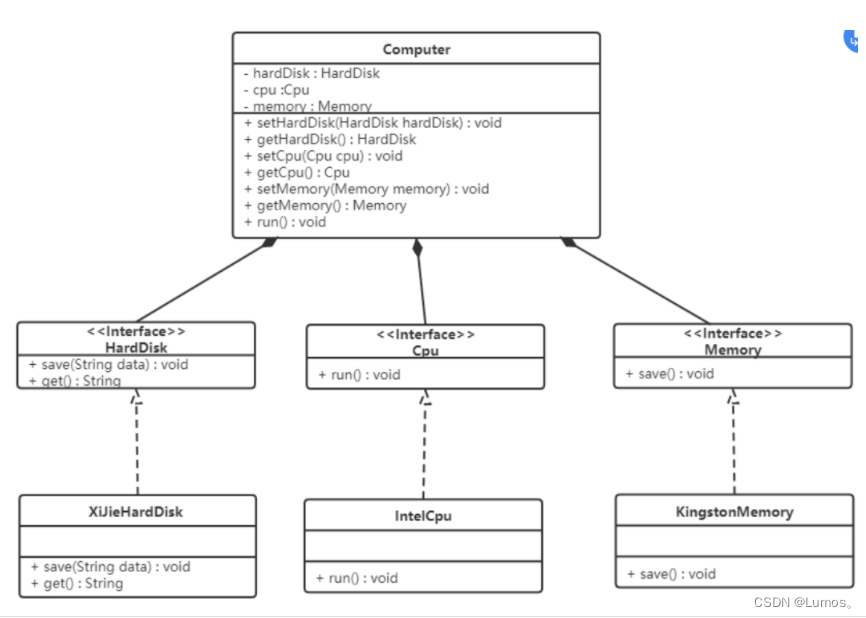
根据依赖倒转原则进行改进:
代码我们只需要修改Computer类,让Computer类依赖抽象(各个配件的接口),而不是依赖于各个组件具体的实现类。
类图如下:
里氏代换原则
子类可以扩展父类的功能,但不能改变父类原有的功能。
子类继承父类时,除添加新的方法完成新增功能外,尽量不要重写父类的方法。
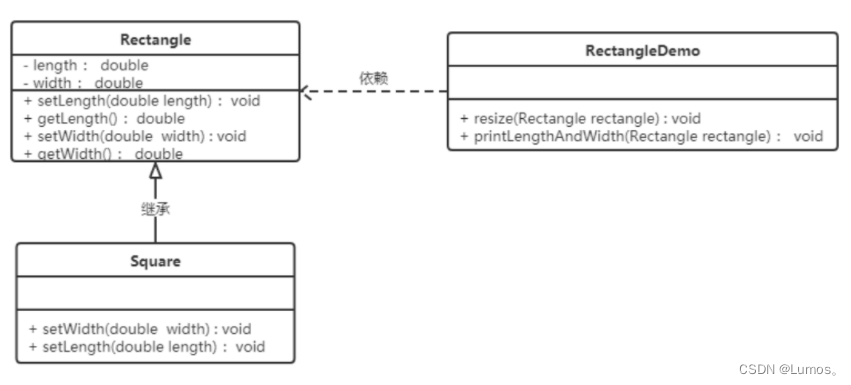
【例】正方形不是长方形。
在数学领域里,正方形毫无疑问是长方形,它是一个长宽相等的长方形。所以,我们开发的一个与几何图形相关的软件系统,就可以顺理成章的让正方形继承自长方形。
长方形类(Rectangle):
public class Rectangle {
private double length;
private double width;
public double getLength() {
return length;
}
public void setLength(double length) {
this.length = length;
}
public double getWidth() {
return width;
}
public void setWidth(double width) {
this.width = width;
}
}
正方形类(Square):
由于正方形的长和宽相同,所以在方法setLength和setWidth中,对长度和宽度都需要赋相同值。
public class Square extends Rectangle {
public void setWidth(double width) {
super.setLength(width);
super.setWidth(width);
}
public void setLength(double length) {
super.setLength(length);
super.setWidth(length);
}
}
类RectangleDemo是我们的软件系统中的一个组件,它有一个resize方法依赖基类Rectangle,resize方法是RectandleDemo类中的一个方法,用来实现宽度逐渐增长的效果。
public class RectangleDemo {
public static void resize(Rectangle rectangle) {
while (rectangle.getWidth() <= rectangle.getLength()) {
rectangle.setWidth(rectangle.getWidth() + 1);
}
}
//打印长方形的长和宽
public static void printLengthAndWidth(Rectangle rectangle) {
System.out.println(rectangle.getLength());
System.out.println(rectangle.getWidth());
}
public static void main(String[] args) {
Rectangle rectangle = new Rectangle();
rectangle.setLength(20);
rectangle.setWidth(10);
resize(rectangle);
printLengthAndWidth(rectangle);
System.out.println("============");
Rectangle rectangle1 = new Square();
rectangle1.setLength(10);
resize(rectangle1);
printLengthAndWidth(rectangle1);
}
}
假如我们把一个普通长方形作为参数传入resize方法,就会看到长方形宽度逐渐增长的效果,当宽度大于长度,代码就会停止,这种行为的结果符合我们的预期。
假如我们再把一个正方形作为参数传入resize方法后,就会看到正方形的宽度和长度都在不断增长,代码会一直运行下去,直至系统产生溢出错误。所以,普通的长方形是适合这段代码的,正方形不适合。
我们得出结论:在resize方法中,Rectangle类型的参数是不能被Square类型的参数所代替,如果进行了替换就得不到预期结果。因此,Square类和Rectangle类之间的继承关系违反了里氏代换原则,它们之间的继承关系不成立,正方形不是长方形。
此时我们需要重新设计他们之间的关系。抽象出来一个四边形接口(Quadrilateral), 让Rectangle类和Square类实现Quadrilateral接口。
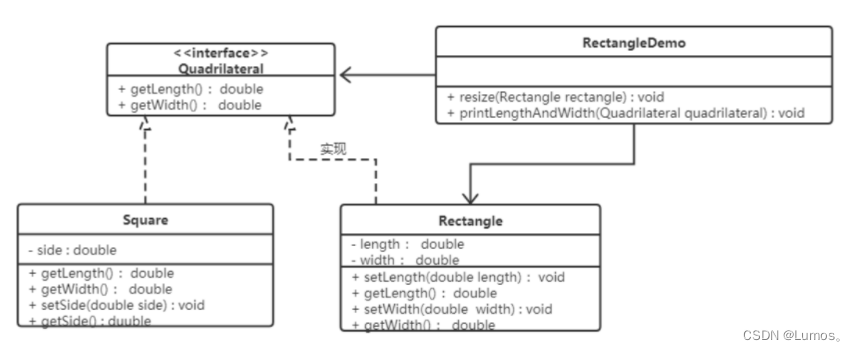
接口隔离原则
不应该强迫客户依赖于他们不用的方法。接口属于客户,不属于他所在的类层次结构。
一个类对另一个类的依赖应该建立在最小的接口上。
【例】安全门案例
我们需要创建一个 黑马 品牌的安全门,该安全门具有防火、防水、防盗的功能。可以将防火,防水,防盗功能提取成一个接口,形成一套规范。类图如下:
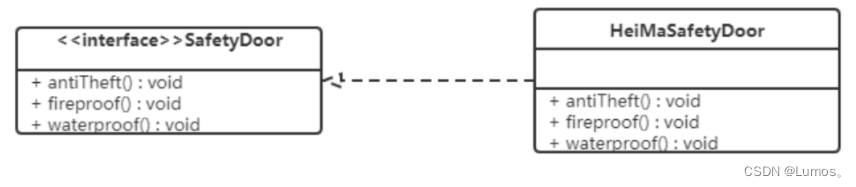
上面的设计我们发现了它存在的问题,黑马品牌的安全门具有防盗,防水,防火的功能。现在如果我们还需要再创建一个传智品牌的安全门,而该安全门只具有防盗、防水功能呢?
很显然如果实现SafetyDoor接口就违背了接口隔离原则,那么我们如何进行修改呢?看如下类图
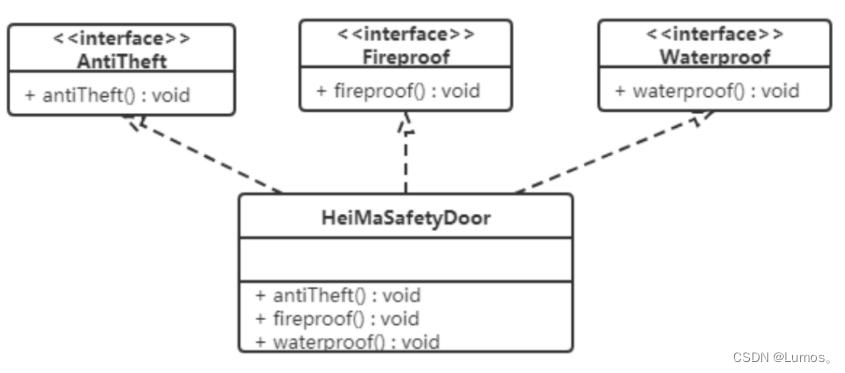
AntiTheft(接口):
public interface AntiTheft {
void antiTheft();
}
Fireproof(接口):
public interface Fireproof {
void fireproof();
}
Waterproof(接口):
public interface Waterproof {
void waterproof();
}
HeiMaSafetyDoor(类):
public class HeiMaSafetyDoor implements AntiTheft, Fireproof, Waterproof {
public void antiTheft() {
System.out.println("防盗");
}
public void fireproof() {
System.out.println("防火");
}
public void waterproof() {
System.out.println("防水");
}
}
ItcastSafetyDoor(类):
public class ItcastSafetyDoor implements AntiTheft, Fireproof {
public void antiTheft() {
System.out.println("防盗");
}
public void fireproof() {
System.out.println("防火");
}
}
迪米特法则
迪米特法则又叫最少知识原则。
只和你的直接朋友交谈,不跟“陌生人”说话。
其含义是:**如果两个软件实体无须直接通信,那么就不应当发生直接的相互调用,可以通过第三方转发该调用。**其目的是降低类之间的耦合度,提高模块的相对独立性。
迪米特法则中的“朋友”是指:当前对象本身、当前对象的成员对象、当前对象所创建的对象、当前对象的方法参数等,这些对象同当前对象存在关联、聚合或组合关系,可以直接访问这些对象的方法。
【例】明星与经纪人的关系实例
明星由于全身心投入艺术,所以许多日常事务由经纪人负责处理,如和粉丝的见面会,和媒体公司的业务洽淡等。这里的经纪人是明星的朋友,而粉丝和媒体公司是陌生人,所以适合使用迪米特法则。
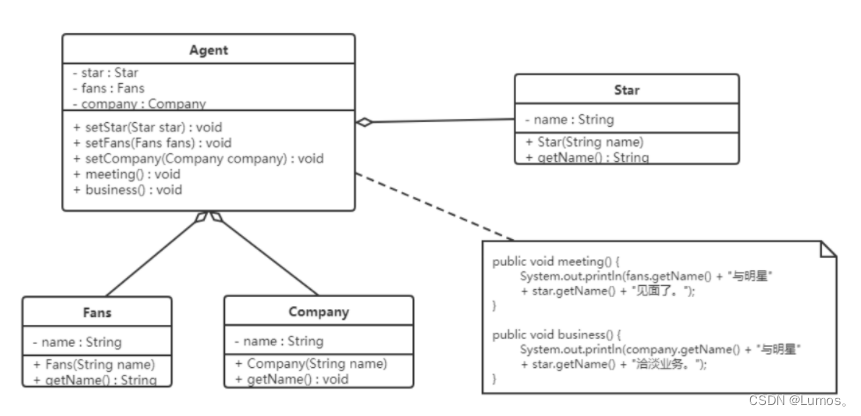
明星类(Star)
public class Star {
private String name;
public Star(String name) {
this.name = name;
}
public String getName() {
return name;
}
}
粉丝类(Fans)
public class Fans {
private String name;
public Fans(String name) {
this.name = name;
}
public String getName() {
return name;
}
}
媒体公司类(Company)
public class Company {
private String name;
public Company(String name) {
this.name = name;
}
public String getName() {
return name;
}
}
经济人类(Agent)
public class Agent {
private Star star;
private Fans fans;
private Company company;
public void setStar(Star star) {
this.star = star;
}
public void setFans(Fans fans) {
this.fans = fans;
}
public void setCompany(Company company) {
this.company = company;
}
public void meeting() {
System.out.println(fans.getName() + "与明星" + star.getName() + "见面 了。");
}
public void business() {
System.out.println(company.getName() + "与明星" + star.getName() + "洽淡业务。");
}
}
合成复用原则
合成复用原则是指:尽量先使用组合或者聚合等关联关系来实现,其次才考虑使用继承关系来实现。
通常类的复用分为继承复用和合成复用两种。
继承复用虽然有简单和易实现的优点,但它也存在以下缺点:
继承复用破坏了类的封装性。因为继承会将父类的实现细节暴露给子类,父类对子类是透明的,所以这种复用又称为“白箱”复用。
子类与父类的耦合度高。父类的实现的任何改变都会导致子类的实现发生变化,这不利于类的扩展与维护。
它限制了复用的灵活性。从父类继承而来的实现是静态的,在编译时已经定义,所以在运行时不可能发生变化。
采用组合或聚合复用时,可以将已有对象纳入新对象中,使之成为新对象的一部分,新对象可以调用已有对象的功能,它有以下优点:
它维持了类的封装性。因为成分对象的内部细节是新对象看不见的,所以这种复用又称为“黑箱”复用。
对象间的耦合度低。可以在类的成员位置声明抽象。
复用的灵活性高。这种复用可以在运行时动态进行,新对象可以动态地引用与成分对象类型相同的对象。
【例】汽车分类管理程序
汽车按“动力源”划分可分为汽油汽车、电动汽车等;按“颜色”划分可分为白色汽车、黑色汽车和红色汽车等。如果同时考虑这两种分类,其组合就很多。
类图如下:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zChZhmgG-1653721625859)(E:\嗷嗷嗷\image-20220524093829081.png)]](https://img-blog.csdnimg.cn/8be9f80eb652454dad312f3f11b99c30.png)
从上面类图我们可以看到使用继承复用产生了很多子类,如果现在又有新的动力源或者新的颜色的话,就需要再定义新的类。我们试着将继承复用改为聚合复用看一下。
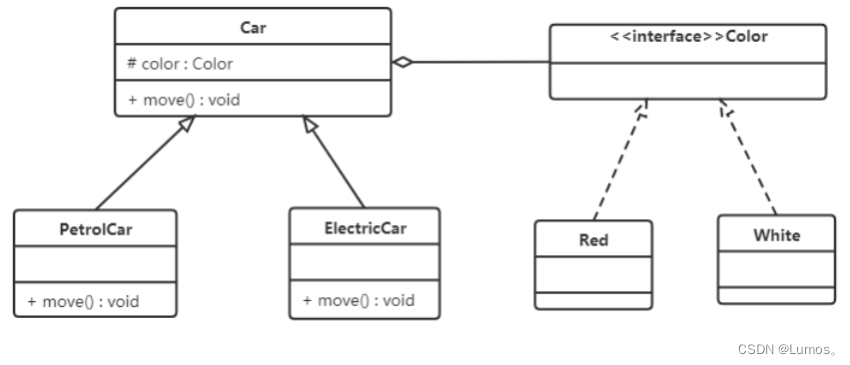
基于复用的软件构造
软件复用
软件复用的概念
软件复用,是指在两次或多次不同的软件开发过程中重复使用相同或相近的软件或软件模块的过程。该软件可以是已经存在的软件,也可以是专门的可复用软件,简称构件。
软件复用是在软件开发中避免重复劳动的解决方案,使得应用系统的开发不再采用一切“从零开始”的模式,而是在已有工作基础上,充分利用过去应用系统开发中积累的知识和经验,从而将开发的重点集中于应用的特有构成成分上。
优点:
1, 提高生产率。软件开发生产率的提高体现在软件开发的各个阶段。使用经过实践检验、高度优化的可复用件构造系统,可以提高系统的性能和可靠性。
2,减少维护代价。由于使用经过检验的软构件,减少了可能的错误;同时由于复用的增加,软件中需要维护的部分也减少了。
3,提高互操作性。通过使用接口的同一个实现,系统将更有效地实现与其它系统之间的互操作。
4,支持快速原型。利用软构建库,可以快速有效地构造出应用程序的原型。
参考:便于开发,提高生产效率,生成可复用的软构建,降低耦合。
软件产品复用
软件产品的复用包括代码、设计、测试数据和需求规格书等。
- 可执行代码和源代码成为软构件或构件。
- 设计复用的三种基本途径:
- 第一种途径:从现有系统的设计结果中提取一些可以复用的设计构件,并把它们直接应用到新系统的设计中。
- 第二种途径:把现有系统的设计结果用新的语言或在新的平台上重新实现。
- 第三种途径:综合现有系统,或者根据需求重新开发一些专门用于复用的设计构件。
设计构件分为构件级和架构级。最常用的可复用设计是设计模式和架构模式。
- 测试数据和测试代码是典型的可复用件。
- 需求规格是提取用户需求、用某种符号记录用户需求的结果,比设计更抽象,也更容易复用。
- 可复用件必须组成复用库。库的内容有不同的组织和定义方式,分为以下三种
- 通用构件
- 特殊领域构件
- 特殊应用代码
基于复用的软件开发
基于复用的软件开发改变了传统的软件开发过程和技术,它包括两个相关的过程:
- 可复用软构件的开发或面向复用的软件开发,是产生软件资产的过程。称为领域工程。
- 基于软构件的应用系统构造(集成或组装)或基于复用的软件开发。是使用软件资产生产新系统的过程。也称为应用工程。
设计模式
设计模式的定义
模式设计是对给定环境下反复出现问题的一个通用的、可复用的解决方案。在很多场合用以解决问题的一种描述或样板。
设计模式的优势
- 在软件开发中提供了一种公共的词汇和理解
- 是软件设计建立文档的一种手段
- 通过支持软件的功能属性和质量属性来构造软件
- 有助于建立一个复杂的和异构的软件结构
- 有助于降低管理软件的复杂度
工厂模式
背景引入
【例】设计一个咖啡店点餐系统。
设计一个咖啡类(Coffee),并定义其两个子类(美式咖啡AmericanCoffee和拿铁咖啡LatteCoffee);再设计一个咖啡店类(CoffeeStore),咖啡店具有点咖啡的功能。
具体类的设计如下:
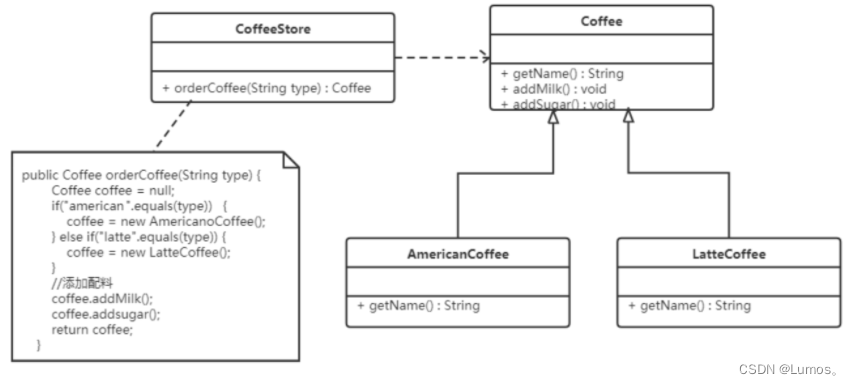
如果创建的时候直接new该对象,就会对该对象耦合严重,假如我们要更换对象,所有new对象的地方都需要修改一遍,这显然违背了软件设计的开闭原则。
如果我们使用工厂来生产对象,我们就只和工厂打交道就可以了,彻底和对象解耦。如果要更换对象,直接在工厂里更换该对象即可,达到了与对象解耦的目的;所以说,工厂模式最大的优点就是:解耦。
工厂方法模式的核心思想是:有一个专门的类负责创建实例的过程,将对象的创建和使用分离。
工厂模式的优点
- 平行连接类的层次结构
- 一个类想让其子类说明对象
- 一个类不预计子类,但必须创建子类
- 一簇对象需要用不同的接口分隔开
- 代码要处理接口而不是实现的类
- 连接子类的方式比直接创建对象更加灵活
- 对客户隐藏具体的类
JDK中使用工厂方法设计模式的例子
valueOf()方法返回工厂创建的对象,等同于参数传递的值getInstance()方法会使用单例模式创建类的实例java.lang.Class中的方法newInstance()每次调用工厂方法时创建新实例java.lang.Class中的方法forName()java.lang.Object中的方法toString()
⭐简单工厂模式
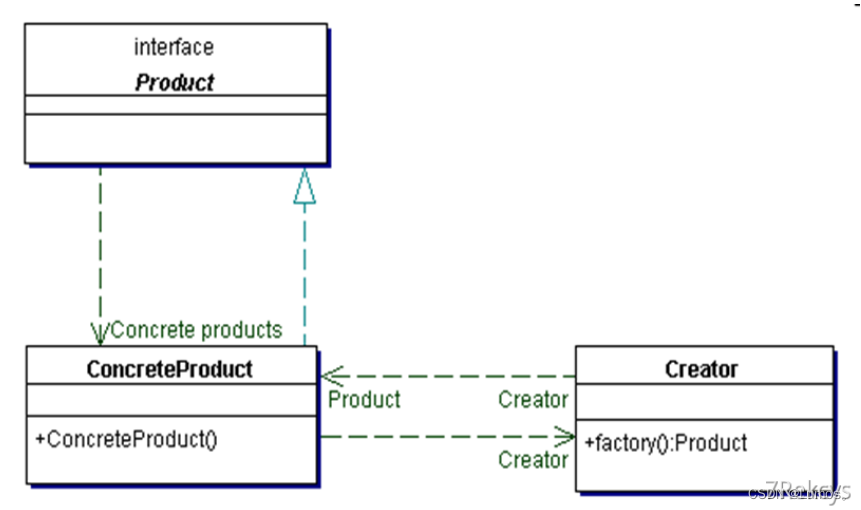
简单工厂包含如下主要角色:
- 抽象产品 :定义了产品的规范,描述了产品的主要特性和功能。
- 具体产品 :实现或者继承抽象产品的子类
- 具体工厂 :提供了创建产品的方法,调用者通过该方法来获取产品。
简单工厂模式的类图:
【例】
代码
// 抽象产品:咖啡抽象类 Coffee
public abstract class Coffee {
public abstract String getName();
public void addSugar() {
System.out.println("加糖");
}
public void addMilk() {
System.out.println("加奶");
}
}
// 具体产品:美式咖啡、拿铁咖啡
public class AmericanCoffee extends Coffee {
public String getName() {
return "美式咖啡";
}
}
public class LatteCoffee extends Coffee {
public String getName() {
return "拿铁咖啡";
}
}
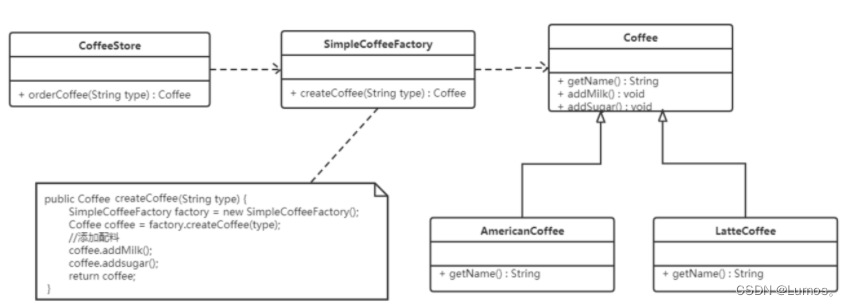
// 简单工厂类:用来生产咖啡
public class SimpleCoffeeFactory {
public Coffee createCoffee(String type) {
// 声明Coffee类型的变量,根据不同类型创建不同的coffee子类对象
Coffee coffee = null;
if ("american".equals(type)) {
coffee = new AmericanCoffee();
} else if ("latte".equals(type)) {
coffee = new LatteCoffee();
} else {
throw new RuntimeException("对不起,您所点的咖啡没有");
}
return coffee;
}
}
// 客户端,咖啡店:使用简单工厂来生产咖啡
public class CoffeeStore {
public Coffee orderCoffee(String type) {
// 生产咖啡的简单工厂
SimpleCoffeeFactory factory = new SimpleCoffeeFactory();
// 调用生产咖啡的方法
Coffee coffee = factory.createCoffee(type);
// 加配料
coffee.addMilk();
coffee.addSugar();
return coffee;
}
}
说明
工厂(factory)处理创建对象的细节,一旦有了SimpleCoffeeFactory,CoffeeStore类中的orderCoffee()就变成此对象的客户,后期如果需要Coffee对象直接从工厂中获取即可。这样也就解除了和Coffee实现类的耦合,同时又产生了新的耦合,CoffeeStore对象和SimpleCoffeeFactory工厂对象的耦合,工厂对象和商品对象的耦合。
后期如果再加新品种的咖啡,我们势必要需求修改SimpleCoffeeFactory的代码,违反了开闭原则。工厂类的客户端可能有很多,比如创建美团外卖等,这样只需要修改工厂类的代码,省去其他的修改操作。
优点:
封装了创建对象的过程,可以通过参数直接获取对象。把对象的创建和业务逻辑层分开,这样以后就避免了修改客户代码,如果要实现新产品直接修改工厂类,而不需要在原代码中修改,这样就降低了客户代码修改的可能性,更加容易扩展。
- 避免创建者和具体产品之间的紧密耦合。
- 单一职责原则。 你可以将产品创建代码放在程序的单一位置, 从而使得代码更容易维护。
- 开闭原则。 无需更改现有客户端代码, 你就可以在程序中引入新的产品类型。
- 应用工厂方法模式需要引入许多新的子类, 代码可能会因此变得更复杂。 最好的情况是将该模式引入创建者类的现有层次结构中。
缺点:
增加新产品时还是需要修改工厂类的代码,违背了“开闭原则”。
扩展
静态工厂
在开发中也有一部分人将工厂类中的创建对象的功能定义为静态的,这个就是静态工厂模式,它也不是23种设计模式中的。代码如下:
public class SimpleCoffeeFactory { public static Coffee createCoffee(String type) { // 声明Coffee类型的变量,根据不同类型创建不同的coffee子类对象 Coffee coffee = null; if ("american".equals(type)) { coffee = new AmericanCoffee(); } else if ("latte".equals(type)) { coffee = new LatteCoffee(); } else { throw new RuntimeException("对不起,您所点的咖啡没有"); } return coffee; } }
工厂方法模式
定义一个用于创建对象的接口,让子类决定实例化哪个产品类对象。工厂方法使一个产品类的实例化延迟到其工厂的子类。
工厂方法模式的主要角色:
-
抽象工厂(Abstract Factory):提供了创建产品的接口,调用者通过它访问具体工厂的工厂方法来创建产品。
-
具体工厂(ConcreteFactory):主要是实现抽象工厂中的抽象方法,完成具体产品的创建。
-
抽象产品(Product):定义了产品的规范,描述了产品的主要特性和功能。
-
具体产品(ConcreteProduct):实现了抽象产品角色所定义的接口,由具体工厂来创建,它同具体工厂之间一一对应。
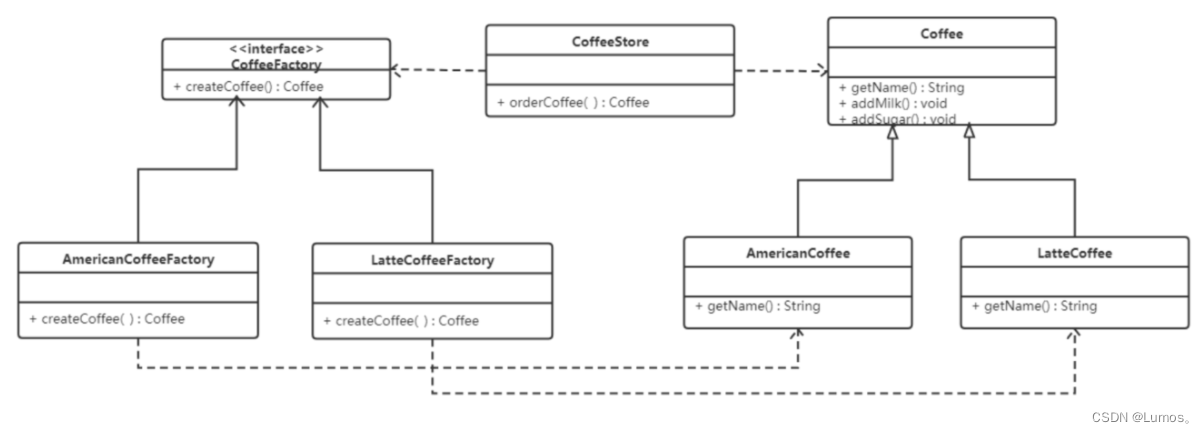
代码
// 抽象产品:咖啡抽象类 Coffee
public abstract class Coffee {
public abstract String getName();
public void addSugar() {
System.out.println("加糖");
}
public void addMilk() {
System.out.println("加奶");
}
}
// 具体产品:美式咖啡、拿铁咖啡
public class AmericanCoffee extends Coffee {
public String getName() {
return "美式咖啡";
}
}
// 抽象工厂
public interface CoffeeFactory {
//创建咖啡对象的方法
Coffee createCoffee();
}
// 具体工厂:美式咖啡工厂对象,专门用来生产美式咖啡
public class AmericanCoffeeFactory implements CoffeeFactory{
@Override
public Coffee createCoffee() {
return new AmericanCoffee();
}
}
// 咖啡店
public class CoffeeStore {
private CoffeeFactory factory;
public void setFactory(CoffeeFactory factory) {
this.factory = factory;
}
public Coffee orderCoffee() {
Coffee coffee = factory.createCoffee();
coffee.addMilk();
coffee.addSugar();
return coffee;
}
}
// 客户端
public class Client {
public static void main(String[] args) {
CoffeeStore store = new CoffeeStore();
CoffeeFactory factory = new AmericanCoffeeFactory();
store.setFactory(factory);
Coffee coffee = store.orderCoffee();
System.out.println(coffee.getName());
}
}
工厂方法模式是简单工厂模式的进一步抽象。由于使用了多态性,工厂方法模式保持了简单工厂模式的优点,而且克服了它的缺点。
优点:
用户只需要知道具体工厂的名称就可得到所要的产品,无须知道产品的具体创建过程;
在系统增加新的产品时只需要添加具体产品类和对应的具体工厂类,无须对原工厂进行任何修改,满足开闭原则;
缺点:
每增加一个产品就要增加一个具体产品类和一个对应的具体工厂类,这增加了系统的复杂度。
抽象工厂模式
前面介绍的工厂方法模式中考虑的是一类产品的生产,这些工厂只生产同种类产品,同种类产品称为同等级产品。但是在现实生活中许多工厂是综合型的工厂,能生产多等级(种类) 的产品。
本节要介绍的抽象工厂模式将考虑多等级产品的生产,将同一个具体工厂所生产的位于不同等级的一组产品称为一个产品族。
是一种为访问类提供一个创建一组相关或相互依赖对象的接口,且访问类无须指定所要产品的具体类就能得到同族的不同等级的产品的模式结构。抽象工厂模式是工厂方法模式的升级版本,工厂方法模式只生产一个等级的产品,而抽象工厂模式可生产多个等级的产品。
抽象工厂模式的主要角色如下:
-
抽象工厂(Abstract Factory):提供了创建产品的接口,它包含多个创建产品的方法,可以创建多个不同等级的产品。
-
具体工厂(Concrete Factory):主要是实现抽象工厂中的多个抽象方法,完成具体产品的创建。
-
抽象产品(Product):定义了产品的规范,描述了产品的主要特性和功能,抽象工厂模式有多个抽象产品。
-
具体产品(ConcreteProduct):实现了抽象产品角色所定义的接口,由具体工厂来创建,它同具体工厂之间是多对一的关系。
【例】
现咖啡店业务发生改变,不仅要生产咖啡还要生产甜点,如提拉米苏、抹茶慕斯等,
-
其中拿铁咖啡、美式咖啡是一个产品等级,都是咖啡;提拉米苏、抹茶慕斯也是一个产品等级;
-
拿铁咖啡和提拉米苏是同一产品族(也就是都属于意大利风味),美式咖啡和抹茶慕斯是同一产品族(也就是都属于美式风味)。
所以这个案例可以使用抽象工厂模式实现。
类图如下:
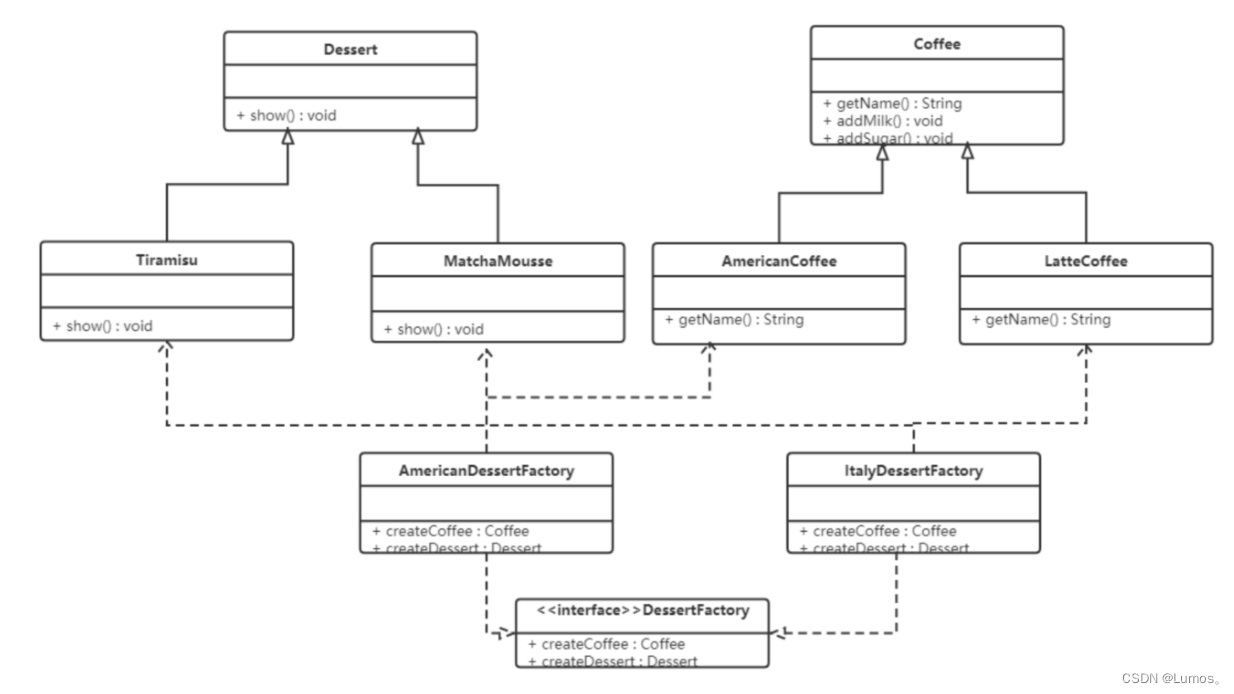
代码
// 抽象工厂
public interface DessertFactory {
// 生产咖啡的功能
Coffee createCoffee();
// 生产甜品的功能
Dessert createDessert();
}
// 具体工厂
public class ItalyDessertFactory implements DessertFactory {
public Coffee createCoffee() {
return new LatteCoffee();
}
public Dessert createDessert() {
return new Trimisu();
}
}
public class AmericanDessertFactory implements DessertFactory {
public Coffee createCoffee() {
return new AmericanCoffee();
}
public Dessert createDessert() {
return new MatchaMousse();
}
}
// 测试类
public class Client {
public static void main(String[] args) {
// 创建的是意大利风味甜品工厂对象
ItalyDessertFactory factory = new ItalyDessertFactory();
// 获取拿铁咖啡和提拉米苏甜品
Coffee coffee = factory.createCoffee();
Dessert dessert = factory.createDessert();
dessert.show();
}
}
如果要加同一个产品族的话,只需要再加一个对应的工厂类即可,不需要修改其他的类。
优点:
当一个产品族中的多个对象被设计成一起工作时,它能保证客户端始终只使用同一个产品族中的对象。
缺点:
当产品族中需要增加一个新的产品时,所有的工厂类都需要进行修改。
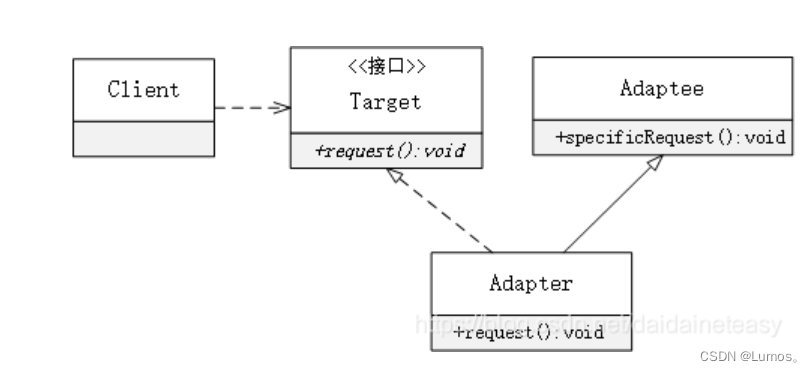
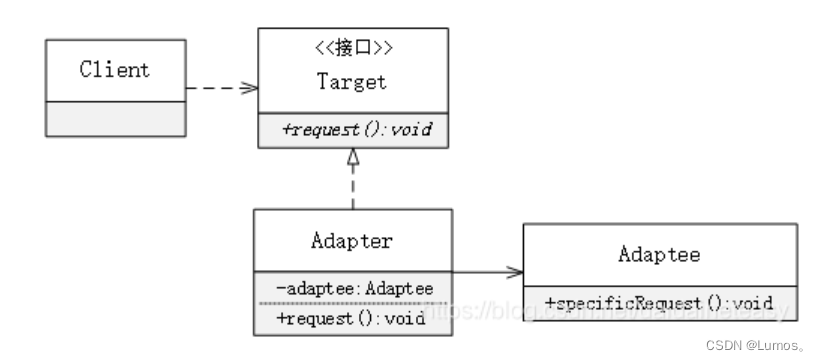
适配器模式
将一个类的接口转换成客户希望的另外一个接口,使得原本由于接口不兼容而不能一起工作的那些类能一起工作。
适配器模式分为类适配器模式和对象适配器模式,前者类之间的耦合度比后者高,且要求程序员了解现有组件库中的相关组件的内部结构,所以应用相对较少些。
适配器模式(Adapter)包含以下主要角色:
-
目标(Target)接口:当前系统业务所期待的接口,它可以是抽象类或接口。
-
适配者(Adaptee)类:它是被访问和适配的现存组件库中的组件接口。
-
适配器(Adapter)类:它是一个转换器,通过继承或引用适配者的对象,把适配者接口转换成目标接口,让客户按目标接口的格式访问适配者
应用场景
- 想使用一个已经存在的类,而他的接口不符合目前的需求。
- 想创建一个可以复用的类,该类可以和其他不相关的类或不可预见的类协同工作。
- 想使用一些已经存在的子类,但是不可能对每个都进行子类化以匹配他们的接口。对象适配器可以匹配他们的父类接口。
JDK中的应用
javax.swing.JTable(TableModel):返回一个JTablejava.io.InputStreamReader(InputStream):返回一个Readerjava.io.OutputStreamWriter(OutputStream):返回一个Writer
【例】
如果去欧洲国家去旅游的话,他们的插座如下图最左边,是欧洲标准。而我们使用的插头如下图最右边的。因此我们的笔记本电脑,手机在当地不能直接充电。所以就需要一个插座转换器,转换器第 1 面插入当地的插座,第 2 面供我们充电,这样使得我们的插头在当地能使用。生活中这样的例子很多,手机充电器(将 220v 转换为 5v 的电压),读卡器等,其实就是使用到了适配器模式。
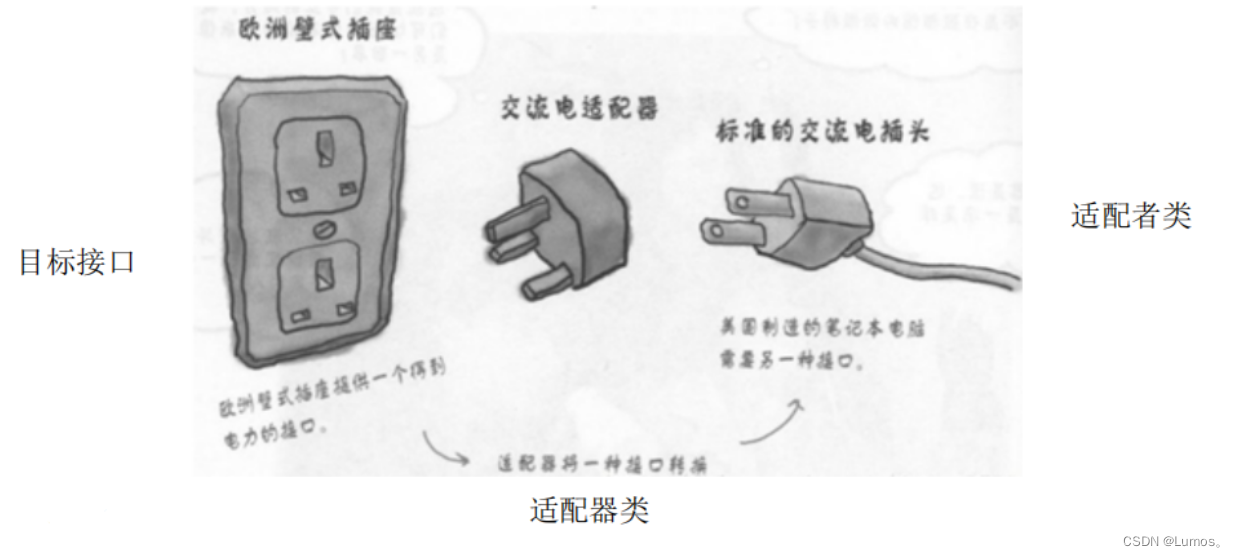
类适配器模式
【例】读卡器
现有一台电脑只能读取SD卡,而要读取TF卡中的内容的话就需要使用到适配器模式。创建一个读卡器,将TF卡中的内容读取出来。
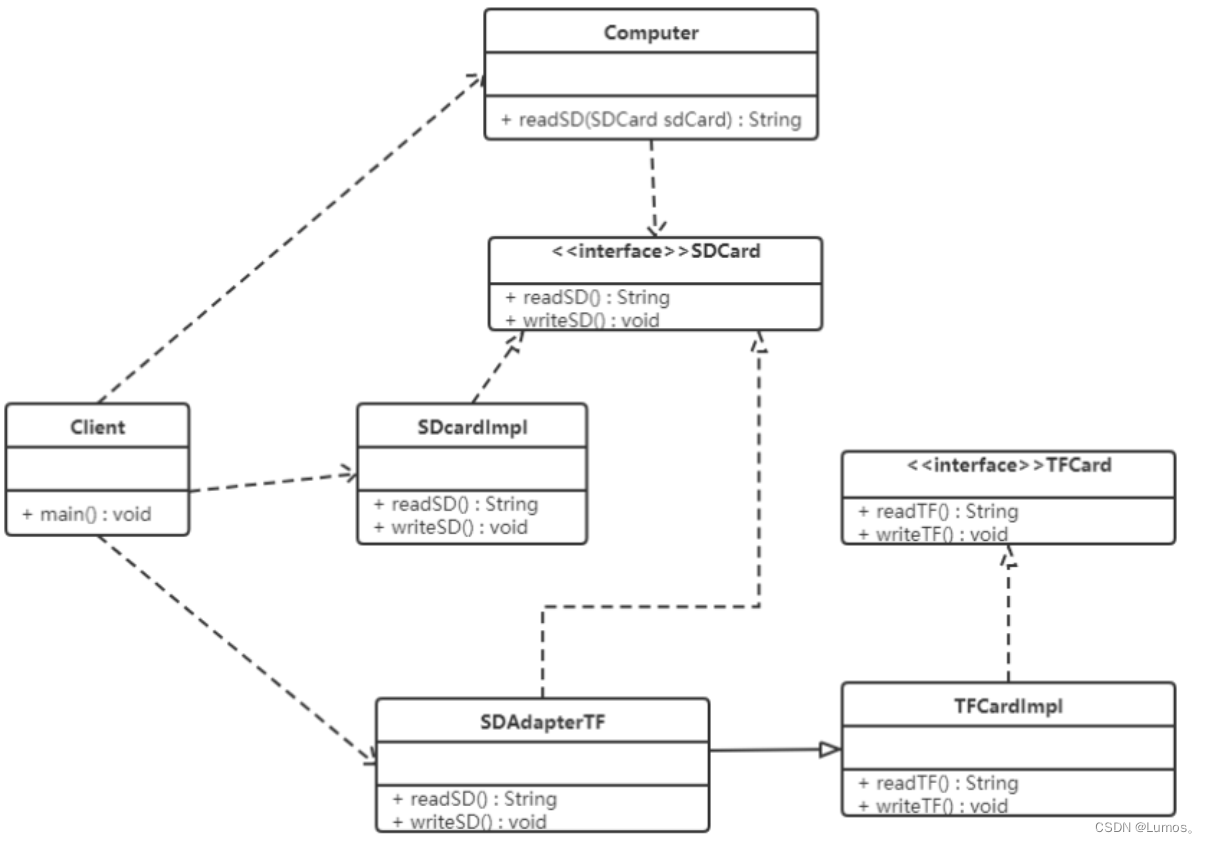
类图如下:
代码:
// Computer:可以直接访问 SDCard,但是不能直接访问 TFCard,即将通过适配器去访问 TFCard
public class Computer {
// 从SD卡中读取数据
public String readSD(SDCard sdCard) {
if (sdCard == null) {
throw new NullPointerException("sd card can not be null");
}
return sdCard.readSD();
}
}
// 目标接口:SDCard 是 Computer 期望访问的接口
public interface SDCard {
// 从SD卡中读取数据
String readSD();
// 往SD卡中写数据
void writeSD(String msg);
}
public class SDCardImpl implements SDCard {
public String readSD() {
String msg = "sd card read a msg :hello word SD";
return msg;
}
public void writeSD(String msg) {
System.out.println("sd card write msg : " + msg);
}
}
// 适配者类:TFCard 是要被适配的接口,适配成可以通过 SDCard 来访问
public interface TFCard {
// 从TF卡中读取数据
String readTF();
// 往TF卡中写数据
void writeTF(String msg);
}
public class TFCardImpl implements TFCard {
public String readTF() {
String msg = "TFCard read msg: hello word TFCard";
return msg;
}
public void writeTF(String msg) {
System.out.println("TFCard write msg: " + msg);
}
}
// 适配器类:实现业务接口,继承已有组件
// 本质上还是要执行 TFCard 的功能,因此 extends TFCardImpl
// 但是又可以让 Computer 通过 SDCard 接口来访问,因此 implements SDCard
public class SDAdapterTF extends TFCardImpl implements SDCard {
public String readSD() {
System.out.println("adapter read tf card");
return readTF();
}
public void writeSD(String msg) {
System.out.println("adapter write tf card");
writeTF(msg);
}
}
// 测试类
public class Client {
public static void main(String[] args) {
// 创建计算机对象
Computer computer = new Computer();
// 电脑读取SD卡中的数据(可直接读)
String msg = computer.readSD(new SDCardImpl());
System.out.println(msg);
System.out.println("===============");
// 使用电脑读取TF卡中的数据(无法直接读)
// 定义适配器类
String msg1 = computer.readSD(new SDAdapterTF());
System.out.println(msg1);
}
}
类适配器模式违背了合成复用原则。类适配器是客户类有一个接口规范的情况下可用,反之不可用。
对象适配器模式
【例】
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-p1IEPVRm-1653721625866)(E:\嗷嗷嗷\image-20220524155732947.png)]](https://img-blog.csdnimg.cn/4014a6e7ffd24993a6e30998b5c5dbbe.png)
代码
// 适配器类:通过聚合一个适配者类,来使用它的方法
public class SDAdapterTF implements SDCard {
// 声明适配者类
private TFCard tfCard;
public SDAdapterTF(TFCard tfCard) {
this.tfCard = tfCard;
}
public String readSD() {
System.out.println("adapter read tf card");
return tfCard.readTF();
}
public void writeSD(String msg) {
System.out.println("adapter write tf card");
tfCard.writeTF(msg);
}
}
// 测试类
public class Client {
public static void main(String[] args) {
// 创建计算机对象
Computer computer = new Computer();
// 电脑读取SD卡中的数据(可直接读)
String msg = computer.readSD(new SDCardImpl());
System.out.println(msg);
System.out.println("===============");
// 使用电脑读取TF卡中的数据(无法直接读)
// 创建适配器类对象
SDAdapterTF sdAdapterTF = new SDAdapterTF(new TFCardImpl());
String msg1 = computer.readSD(sdAdapterTF);
System.out.println(msg1);
}
}
补充
还有一个适配器模式是接口适配器模式。当不希望实现一个接口中所有的方法时,可以创建一个抽象类Adapter ,实现所有方法。而此时我们只需要继承该抽象类即可。
设计模式总结
工厂模式
定义
定义一个用于创建对象的接口或抽象类,让子类根据条件或参数决定实例化哪一个类或调用哪一个方法。
工厂方法模式使一个类的实例化延迟到其子类。
模式结构见上。
核心思想
有一个专门的类来负责创建实例的过程。它把产品视为一系列的类的集合,这些类是由某个抽象类或接口派生出来的一个对象树。
而工厂类用来产生一个合适的对象来满足客户的要求。
如果工厂方法模式所涉及的具体产品之间没有共同的逻辑,就可以使用接口来扮演抽象产品的角色;如果具体产品之间有共同的逻辑,就必须把这些共同的东西提取出来,放在一个抽象类中,然后让具体产品继承抽象类。
场合及益处
平行连接类的层次结构
一个类想让其子类说明对象
一个类不预计子类,但必须创建子类
一簇对象需要用不同的接口分隔开
代码要处理接口而不是实现的类
连接子类的方式比直接创建对象更加灵活
对客户隐藏具体的类
JDBC是工厂方法模式的一个很好的例子,数据库应用程序不需要知道它将使用哪种数据库,所以它也不知道应该使用什么具体的数据库驱动类。
相反,它使用工厂方法来获取连接、语句和其他对象,这使得改变后台数据库变得非常灵活,同时并不会改变应用的数据模型。
⭐迭代器模式
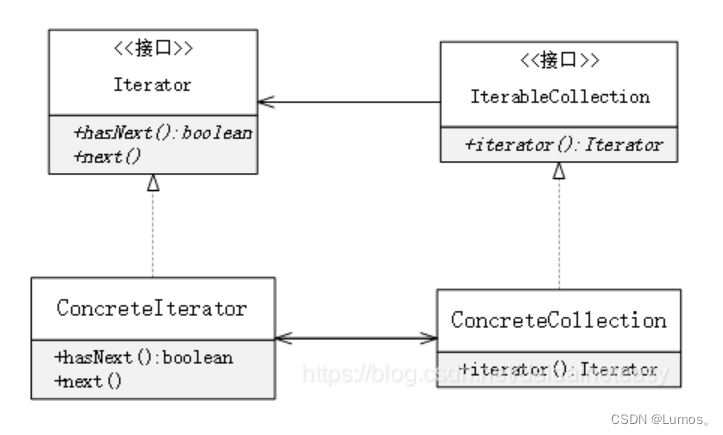
核心思想
提供一种方法来按顺序访问一个聚合对象中的一系列数据或各个成员对象,而不暴露聚合对象的内部表示。
模式特点
迭代抽象——访问一个聚合对象的内容而无须暴露它的内部表示。
迭代多态——为遍历不同的集合结构提供一个统一的接口,从而支持同样的算法在不同的集合结构上进行操作。
健壮性考虑——遍历的同时有可能更改迭代器所在的集合结构,导致问题。
适用场合
将一种聚集变换为另一种聚集时,不想修改客户端代码。
- 访问一个聚合对象的内容而无须暴露它的内部表示。
- 需要为聚合对象提供多种遍历方式。
- 为遍历不同的聚合结构提供一个统一的接口。
迭代器模式的主要角色:
- Aggregate,抽象聚合角色:定义存储、添加、删除聚合元素以及创建迭代器对象的接口。
- ConcreteAggregate,具体聚合角色:实现抽象聚合类,返回一个具体迭代器的实例。
- Iterator,抽象迭代器角色:定义访问和遍历聚合元素的接口,通常包含 hasNext()、next() 等方法。
- Concretelterator,具体迭代器角色:实现抽象迭代器接口中所定义的方法,完成对聚合对象的遍历,记录遍历的当前位置。
即:迭代器接口Iterator定义实现迭代功能的最小方法集,比如提供hasNext()、next()、add()等方法。具体迭代器Concretelterator是Iterator的实现类,可以根据具体情况加以实现。容器接口Aggregate定义创建相应迭代器对象的接口。容器ConcreteAggregate实现创建相应迭代器的类,返回迭代器实现类一个适当的实例。
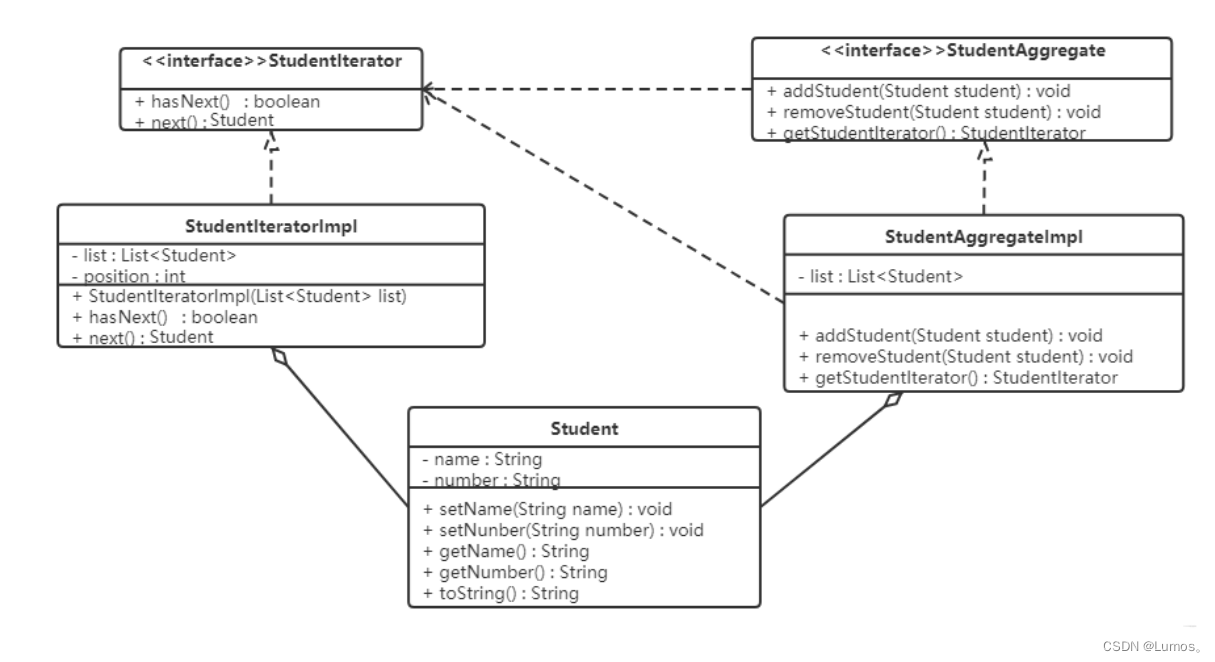
【例】
定义一个可以存储学生对象的容器对象,将遍历该容器的功能交由迭代器实现,涉及到的类如下:
// 实体类
@Data
@ToString
@AllArgsConstructor
@NoArgsConstructor
public class Student {
private String name;
private String number;
}
// 抽象迭代器角色:拥有 hasNext 和 next 方法
public interface StudentIterator {
// 判断是否还有元素
boolean hasNext();
// 获取下一个元素
Student next();
}
// 具体迭代器角色:重写抽象方法
public class StudentIteratorImpl implements StudentIterator {
private final List<Student> list;
private int position = 0; // 记录遍历时的位置
public StudentIteratorImpl(List<Student> list) {
this.list = list;
}
public boolean hasNext() {
return position < list.size();
}
public Student next() {
// 从集合中获取指定位置的元素
return list.get(position++);
}
}
// 抽象聚合角色:包含添加元素,删除元素,获取迭代器对象的方法
public interface StudentAggregate {
// 添加学生功能
void addStudent(Student stu);
// 删除学生功能
void removeStudent(Student stu);
// 获取迭代器对象功能
StudentIterator getStudentIterator();
}
// 具体聚合角色:重写抽象方法
public class StudentAggregateImpl implements StudentAggregate {
private List<Student> list = new ArrayList<>();
public void addStudent(Student stu) {
list.add(stu);
}
public void removeStudent(Student stu) {
list.remove(stu);
}
// 获取迭代器对象
public StudentIterator getStudentIterator() {
return new StudentIteratorImpl(list);
}
}
// 测试类
public class Client {
public static void main(String[] args) {
// 创建聚合对象
StudentAggregateImpl aggregate = new StudentAggregateImpl();
// 添加元素
aggregate.addStudent(new Student("张三", "001"));
aggregate.addStudent(new Student("李四", "002"));
aggregate.addStudent(new Student("王五", "003"));
aggregate.addStudent(new Student("赵六", "004"));
// 遍历聚合对象
// 1,获取迭代器对象
StudentIterator iterator = aggregate.getStudentIterator();
// 2,遍历
while (iterator.hasNext()) {
// 3,获取元素
Student student = iterator.next();
System.out.println(student);
}
}
}
优点:
支持以不同的方式遍历一个聚合对象,在同一个聚合对象上可以定义多种遍历方式。在迭代器模式中只需要用一个不同的迭代器来替换原有迭代器即可改变遍历算法,我们也可以自己定义迭代器的子类以支持新的遍历方式。
迭代器简化了聚合类。由于引入了迭代器,在原有的聚合对象中不需要再自行提供数据遍历等方法,这样可以简化聚合类的设计。
在迭代器模式中,由于引入了抽象层,增加新的聚合类和迭代器类都很方便,无须修改原有代码,满足 “开闭原则” 的要求。
缺点:
增加了类的个数,这在一定程度上增加了系统的复杂性。
JDK中使用:
1,Java的Collections Framework是迭代器模式的典型实现。它的接口Collection和Iterator分别对应模式中的Aggregate和Iterator。
策略模式
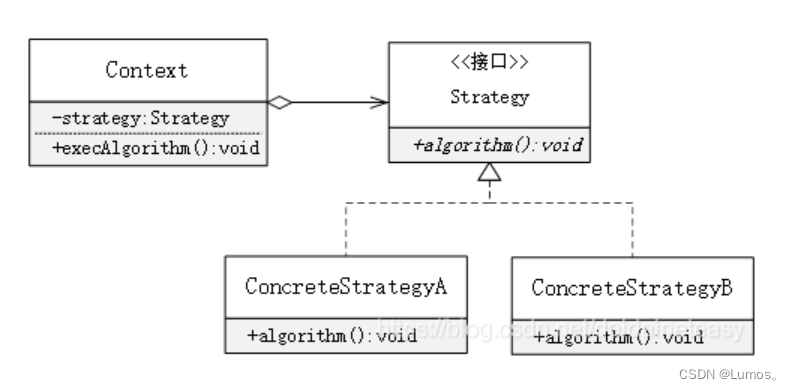
该模式定义了一系列算法,并将每个算法封装起来,使它们可以相互替换,且算法的变化不会影响使用算法的客户。
策略模式属于对象行为模式,它通过对算法进行封装,把使用算法的责任和算法的实现分割开来,并委派给不同的对象对这些算法进行管理。
模式特点
策略类及其子类提供了一系列可重用的封装算法,通过面向对象的多态、动态绑定技术,对象在运行时根据需要在各个算法之间进行切换。
策略模式的主要角色如下:
-
抽象策略(Strategy)类:这是一个抽象角色,通常由一个接口或抽象类实现。此角色给出所有的具体策略类所需的接口。
-
具体策略(Concrete Strategy)类:实现了抽象策略定义的接口,提供具体的算法实现或行为。
-
环境(Context)类:持有一个策略类的引用,最终给客户端调用。
**【例】 **促销活动
一家百货公司在定年度的促销活动。针对不同的节日(春节、中秋节、圣诞节)推出不同的促销活动,由促销员将促销活动展示给客户。类图如下:
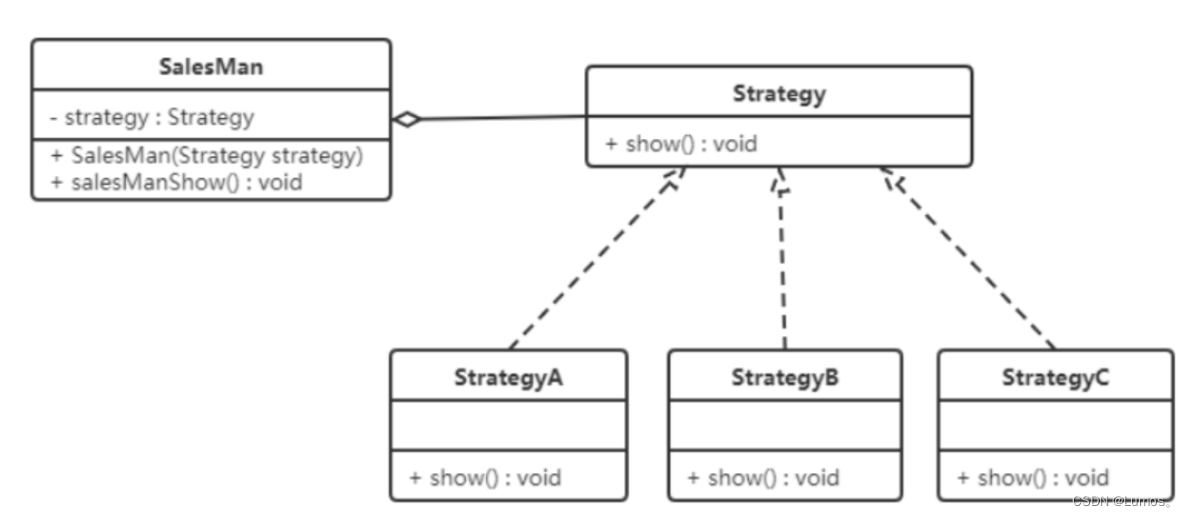
代码
// 定义百货公司所有促销活动的共同接口
public interface Strategy {
void show();
}
// 定义具体策略角色(Concrete Strategy):每个节日具体的促销活动
// 为春节准备的促销活动A
public class StrategyA implements Strategy {
public void show() {
System.out.println("买一送一");
}
}
//为中秋准备的促销活动B
public class StrategyB implements Strategy {
public void show() {
System.out.println("满200元减50元");
}
}
//为圣诞准备的促销活动C
public class StrategyC implements Strategy {
public void show() {
System.out.println("满1000元加一元换购任意200元以下商品");
}
}
// 定义环境角色(Context):用于连接上下文,即把促销活动推销给客户,这里可以理解为销售员
public class SalesMan {
//持有抽象策略角色的引用
private Strategy strategy;
public SalesMan(Strategy strategy) {
this.strategy = strategy;
}
//向客户展示促销活动
public void salesManShow() {
strategy.show();
}
}
// 测试类
public class Client {
public static void main(String[] args) {
// 春节来了,使用春节促销活动
SalesMan salesMan = new SalesMan(new StrategyA());
// 展示促销活动
salesMan.salesManShow();
// 中秋节到了,使用中秋节的促销活动
salesMan.setStrategy(new StrategyB());
// 展示促销活动
salesMan.salesManShow();
// 圣诞节到了,使用圣诞节的促销活动
salesMan.setStrategy(new StrategyC());
// 展示促销活动
salesMan.salesManShow();
}
}
优点:
策略类之间可以自由切换:由于策略类都实现同一个接口,所以使它们之间可以自由切换。
易于扩展:增加一个新的策略只需要添加一个具体的策略类即可,基本不需要改变原有的代码,符合“开闭原则“
避免使用多重条件选择语句(if else),充分体现面向对象设计思想。
同时满足“依赖倒转”原则。
缺点:
客户端必须知道所有的策略类,并自行决定使用哪一个策略类。
策略模式将造成产生很多策略类,可以通过使用享元模式在一定程度上减少对象的数量。
使用场景
一个系统需要动态地在几种算法中选择一种时,可将每个算法封装到策略类中。
一个类定义了多种行为,并且这些行为在这个类的操作中以多个条件语句的形式出现,可将每个条件分支移入它们各自的策略类中以代替这些条件语句。
系统中各算法彼此完全独立,且要求对客户隐藏具体算法的实现细节时。
系统要求使用算法的客户不应该知道其操作的数据时,可使用策略模式来隐藏与算法相关的数据结构。
多个类只区别在表现行为不同,可以使用策略模式,在运行时动态选择具体要执行的行为。
JDBC
Java程序访问数据库的一般流程。
- 加载驱动
Class.forName("com.mysql.jdbc.Driver"); - 建立连接
Connection conn = DriverManger.getConnection(url,account,password); - 建立Statement对象
Statement stmt = conn.createStatement(ResultSet.TYPE_FORWARD_ONLY); - 执行SQL语句
ResultSet rs = stmt.executeUpdate(sql); - 处理结果集
rs.getString('');/rs.getString(1); - 关流
rs.close();stmt.close();conn.close();
import java.sql.*;
public class Main {
public static void main(String[] args) {
String url = "jdbc:mysql://localhost:3306/test";
String user = "root";
String password = "root";
Statement stmt = null;
Connection conn = null;
ResultSet rs = null;
try{
Class.forName("com.mysql.cj.jdbc.Driver");
conn = DriverManager.getConnection(url,user,password);
stmt = conn.createStatement();
String sql = "select * from student";
rs = stmt.executeQuery(sql);
while(rs.next()){
System.out.println(rs.getString(1)
+ " " + rs.getString(2)
+ " " + rs.getString(3)
);
}
rs.close();
stmt.close();
conn.close();
} catch (Exception e){
e.printStackTrace();
}
}
}
数据库的增、删、改、查等操作方法:
增:String sql = "INSERT INTO USER (user_name,user_password,user_age) VALUES('老王','123456',18)";
删:String sql = "DELETE FROM USER WHERE USER.user_name = '老王'";
DELETE FROM Question WHERE CategoryID = (Select CategoryID FROM Category where Name = 'Top');
改:String sql = "UPDATE USER SET USER.user_name = '老李'";
UPDATE Question
SET Operator = '*'
WHERE CategoryID = (SELECT CategoryID
FROM Category
WHERE Name = 'Junior');
查:String sql = "SELECT * FROM USER";
SELECT Factor1,Operator,Factor2,Result
FROM Question
WHERE Operator = '+'
AND Result<50;
Statement属性
| 属性 | 含义 |
|---|---|
| ResultSet.TYPE_FORWARD_ONLY | 表示结果集只能向下滚动 |
| ResultSet.TYPE_SCROLL_INSENSITIVE | 表示结果集的游标可以上下滚动,当数据库变化时,当前结果集不变 |
| ResultSet.TYPE_SCROLL_SENSITIVE | 表示结果集的游标可以上下滚动,当数据库变化时,当前结果集同时改变 |
| ResultSet.CONCUR_READ_ONLY | 不能用结果集更新数据库中的表 |
| ResultSet.CONCUR_UPDATABLE | 可以用结果集更新数据库中的表 |
倒序输出
import java.sql.*;
public class Conn {
public static void main(String[] args) throws ClassNotFoundException {
Class.forName("com.mysql.jdbc.Driver");
Connection conn;
Statement stmt;
ResultSet rs;
String sql = "select * from info";
ResultSetMetaData rsmd;
int columnCount;//ResultSet的总列数
try{
conn = DriverManager.getConnection("jdbc:mysql://121.36.86.90/train", "XX", "XX");
stmt = conn.createStatement(ResultSet.TYPE_SCROLL_INSENSITIVE,ResultSet.CONCUR_READ_ONLY);
rs = stmt.executeQuery(sql);
rsmd = rs.getMetaData() ;
columnCount = rsmd.getColumnCount();
rs.last();
rs.afterLast();
while(rs.previous()){
// 当rs.getString不为空时
for(int i = 1; i < columnCount + 1; i++){
System.out.print(rs.getString(i)+" ");
}
System.out.println();
}
rs.close();
stmt.close();
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
常用的驱动代码
连接mysql
Driver类:com.mysql.jdbc.Driver
URL:jdbc:mysql://localhost:3306/test
连接Oracle
Driver类:oracle.jdbc.driver.OracleDriver
URL:jdbc:oracle:thin:@localhost:1521:[sid]
连接SQLServer 2000
Driver类:com.microsoft.jdbc.sqlserver.SQLServerDriver
URL:jdbc:microsoft:sqlserver://localhost:1433;DatabaseName=[database]
连接SQLServer 2005
Driver类:com.microsoft.sqlserver.jdbc.SQLServerDriver
URL:jdbc:sqlserver://localhost;DatabaseName=[database]
使用JTDs连接SQLServer
Driver类:net.sourceforge.jtds.jdbc.Driver
URL:jdbc:jtds:sqlserver://localhost:1433/[database];tds=8.0;lastupdatecount=true
连接PostgreSql
Driver类:org.postgresql.Driver
URL:jdbc:postgresql://localhost/[database]
连接Sybase
Driver类:com.sybase.jdbc.SybDriver
URL: jdbc:sybase:Tds:localhost:5007/[database]
连接DB2
Driver类:com.ibm.db2.jdbc.app.DB2Driver
URL: jdbc:db2://localhost:5000/[database]
连接HsqlDB
Driver类:org.hsqldb.jdbcDriver
URL:jdbc:hsqldb:mem:generatorDB
连接Derby
Driver类:org.apache.derby.jdbc.ClientDriver
URL:jdbc:derby://localhost/databaseName
连接H2
Driver类:org.h2.Driver
URL:jdbc:h2:tcp://localhost/~/test
了解哪些常用的数据库管理系统?
MySQL、Oracle、DB2、SQL server。
简要介绍一个你比较熟悉的数据库管理系统。
MySQL 是一款安全、跨平台、高效的,并与 PHP、Java 等主流编程语言紧密结合的数据库系统。
如果要访问其他数据库管理系统,需要对项目进行哪些修改?
修改:驱动,jar包,url;
查询数据库数据和删除数据库数据调用的方法相同吗?如果不同,其返回值各有什么作用?
不相同,
查询:executeQuery方法的返回该查询生成的 ResultSet 对象。
删除:executeUpdate 方法的返回值是一个整数,指示受影响的行数(即更新计数)。
如果要添加数据,应该用什么方法?executeUpdate 方法
根据上述代码分析,登录功能的实现是否需要访问数据库?如果需要,登录时访问数据库的目的是什么即执行的具体操作是什么?
需要,与输入的用户信息对比实现登录while(rs.next()){ String name = rs.getString("name"); String pw = rs.getString("password"); if(username.equals(name)&&password.equals(pw)){ return 1; }else if(username.equals(name)){ return 0; }
实现注册功能时是否需要访问数据库?如果需要,注册时访问数据库的目的是什么即执行的具体操作是什么?
需要,与输入的用户信息对比实现登录。添加用户信息具体代码与登录时访问数据库的代码有什么不同?
……假如数据表user的字段为name1、password,新注册用户的姓名为Tomcat,密码为12356,试写出将该用户信息写入数据库的核心代码。访问数据库时,JDBC能完成哪些工作?要利用JDBC访问数据库,程序员通常遵循的基本流程是什么?
JDBC可以实现SQL语句在数据库中的执行,也就是说,**数据库的所有操作,包括对数据库,对表格,对记录**都可以进行相应的操作
习题
-
运用面向对象方法设计软件,并用UML表示类之间的关系:一个网上购物系统,客户(Customer)可以从商品目录(Category)中浏览商品(Item),把挑选的商品放进购物车(shopping_cart),并且可以说明同一商品的数量。如果不如意,也可以随时从购物车拿出一件或若干商品。客户付款(Payment)时,系统计算购物车中所有商品的价格,客户选择E-bao、Band_card或货到付款(Cash)等付款方式。系统根据付款方式和金额为客户增加积分(Reward),并根据年度消费总金额把客户划分成三类:Type_A、Type_B和Type_C,以便提供针对性的服务和营销。客户能浏览自己的积分、一年采购的所有商品,但是不知道自己在网站的客户分类。
-
解释下面用UML类图表示的设计
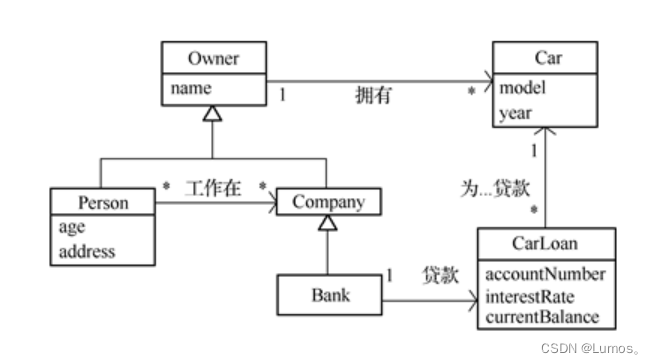
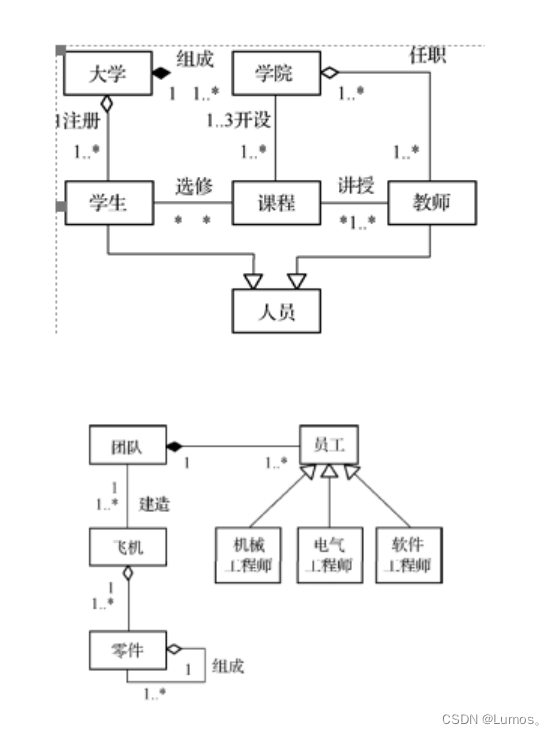
-
正在运行的程序使用NEC NP-CD1100 型号的投影仪output 文件,现在又购置了爱普生CH-TW7000 型号的投影仪,但是它提供了不同的输出函数disply()。如果不想改变当前程序的编码,想使用新的类、但又不能改变它,如何设计?
1,根据以上描述,请问该题解决方案应该采用适配器模式还是工厂方法模式?(3分)
2,用UML类图表达它的解决方案。
3,给出解决方案实现代码。
4,依据以上解析,请概括出所用设计模式的核心思想。
5,请概括出所用设计模式适合的场合。
-
针对下面的而求,后用面问对象方法设计软件。井用UML表示类之间的关系。某书店为方便客户通过internet购实相关图书,开发一个“网上购书系统”,客户可以通过Web页面注册并登录,通过web页面查看、选择图书,系统根据用户选择的图书单价、数量,自动生成订单并计算总价格。客尸在提交订单之前,必预填写关于寄送地址和发票及付款方式等细节。一旦订单被提交,系统显示确认信息,用附上详细信息。客户可以在线查询订单的状态。系统管理人员查看客户的订单,验证客户的信用和付款方式,向仓库请求所购买的图书,打印发票并发货。
需求可能不完善、不正确,大家首先进行一个简单的需求分析,用分析模型表示或用文字表示分析过程
然后进行设计、设计建模有多种图。设想至少用类图体现一下你的设计结果。
-
某软件公司为某电影院开发了一套影院售票系统,在该系统中需要为不同类型的用户提供不同的电影票打折方式,具体打折方案如下:
1,学生凭学生证可享受票价8折优惠。
2,年龄在10周岁及以下的儿童可享受每张票碱免10元的优惠(原始票价需大于等于30元)
3,影院vIP用户除享受票价半价优惠外还可进行积分,积分累计到一定额度可换取电影院赠送的奖品。
4,军人免费
5,60岁以上老人半价
该系统在将来可能还要根据需要引入新的打折方式。现使用策略模式设计该影院售票系统的打折方案并代码实现。
注意:
1,先给出设计类图2,再用JAVA代吗实现
3,必须满足依赖倒转原则















 257
257











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









