







0: 友情提示
1:结合算法手写推导实验原理分析,再去跑程序,虽然我的备注已经很清晰。
1: 线性可分支持向量机算法–最大间隔法
1.1:二次规划问题的标准形式

(1):上式中,
x
x
x为所要求解的列向量,其中
x
T
x^T
xT为列向量
x
x
x的转置;
(2):将问题化为标准的
Q
P
QP
QP问题,得到
P
/
q
/
G
/
h
/
A
/
b
P/q/G/h/A/b
P/q/G/h/A/b;
(3):直接使用
c
v
x
o
p
t
.
s
o
l
o
v
e
r
s
.
q
p
(
P
,
q
,
G
,
h
,
A
,
b
)
cvxopt.solovers.qp(P,q,G,h,A,b)
cvxopt.solovers.qp(P,q,G,h,A,b)函数求解即可。
1.2:注意事项
(1):若所求的目标函数为
m
a
x
max
max,则可以通过乘以
−
1
-1
−1,将最大值问题化为最小值问题;
(2):
G
x
≤
h
Gx \leq h
Gx≤h表示所有不等式约束式,若存在诸如
x
≥
0
x \geq 0
x≥0的形式,可以转换为
−
x
≤
0
-x\leq 0
−x≤0;
(3):
A
x
=
b
Ax=b
Ax=b表示所有等式约束式。
1.3:详细算法

2:本次实验基于的数据线性可分
2.1:数据下载网站
https://archive.ics.uci.edu/ml/index.php
初次使用该网站,感觉检索体验不是很友好,估计是自己不熟,后期会补充文章如何使用该网站获取合适数据。
此处,贴出数据下载网盘链接:
https://pan.baidu.com/s/1GhwOSu9Qa-gDYzgs8ZWwvA
提取码:nice
3:实验原理分析
3.1:转换二次规划问题的形式
本次数据格式为
(
x
i
1
,
x
i
2
,
y
i
)
。
其
中
y
i
为
标
签
,
y
1
…
y
50
=
+
1
,
y
51
…
y
100
=
−
1
(x_{i1}, x_{i2}, y_i)。其中y_i为标签,y_1\ldots y_{50} = +1,y_{51}\ldots y_{100} = -1
(xi1,xi2,yi)。其中yi为标签,y1…y50=+1,y51…y100=−1
min
w
,
b
1
/
2
(
w
1
2
+
w
2
2
)
s
.
t
.
−
y
i
(
w
1
x
i
1
+
w
2
x
i
2
+
b
)
≤
−
1
\min\limits_{w, b} \quad1/2(w_1^2 + w_2^2)\\ s.t. \quad -y_i(w_1 x_{i1}+ w_2 x_{i2}+ b) \leq -1\\
w,bmin1/2(w12+w22)s.t.−yi(w1xi1+w2xi2+b)≤−1
则通过二次规划求解得到输出为
(
w
1
,
w
2
,
b
)
(w_1, w_2, b)
(w1,w2,b)
3.2:最终分离超平面方程应为:
w 1 x 1 + w 2 x 2 + b = 0 w_1 x_1+ w_2 x_2+ b = 0 w1x1+w2x2+b=0
3.3:写成矩阵乘法的形式有
min
w
,
b
1
2
(
w
1
w
2
b
)
T
(
1
0
0
0
1
0
0
0
0
)
(
w
1
w
2
b
)
\min \limits_{w, b} \quad \frac{1}{2} \left(\begin{array}{cccc} w_1 \\ w_2 \\ b \\ \end{array} \right) ^T \left(\begin{array}{cccc} 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 0 \\ \end{array} \right) \left(\begin{array}{cccc} w_1 \\ w_2 \\ b \\ \end{array} \right)
w,bmin21⎝⎛w1w2b⎠⎞T⎝⎛100010000⎠⎞⎝⎛w1w2b⎠⎞
s
.
t
.
(
−
y
1
x
11
−
y
1
x
12
−
y
1
−
y
2
x
21
−
y
2
x
22
−
y
2
−
y
3
x
31
−
y
3
x
32
−
y
3
⋮
⋮
⋮
−
y
100
x
1001
−
y
100
x
1002
−
y
100
)
(
w
1
w
2
b
)
≤
(
−
1
−
1
−
1
⋮
−
1
)
s.t. \quad \left(\begin{array}{cccc} -y_1x_{11} & -y_1x_{12} & -y_1 \\ -y_2x_{21} & -y_2x_{22} & -y_2 \\ -y_3x_{31} & -y_3x_{32} & -y_3 \\ \vdots & \vdots & \vdots \\ -y_{100}x_{1001} & -y_{100}x_{1002} & -y_{100} \\ \end{array} \right) \left(\begin{array}{cccc} w_1 \\ w_2 \\ b \\ \end{array} \right) \leq \left(\begin{array}{cccc} -1 \\ -1 \\ -1 \\ \vdots\\ -1 \\ \end{array} \right)
s.t.⎝⎜⎜⎜⎜⎜⎛−y1x11−y2x21−y3x31⋮−y100x1001−y1x12−y2x22−y3x32⋮−y100x1002−y1−y2−y3⋮−y100⎠⎟⎟⎟⎟⎟⎞⎝⎛w1w2b⎠⎞≤⎝⎜⎜⎜⎜⎜⎛−1−1−1⋮−1⎠⎟⎟⎟⎟⎟⎞
3:详细代码及分析
'''
Objects : 对SVM支持向量机基本型的算法,用现成的优化计算包求解二次规则(Convex Quadratic Programming)问题
将形式转换为二次规划的标准形式,不使用核函数
数据集与PLA & Pocket PLA数据集保持一致
调用优化函数:solvers.qp(P,q,G,h,A,b)
Version : V1.4
Author : Haoger
Date : 2020/12/10
Location : Long Room
'''
# 最佳做法,只导入需要的函数,或者导入整个模块并使用句点表示法
import pandas as pd
import numpy as np
from cvxopt import solvers
from cvxopt import matrix
import matplotlib
import matplotlib.pyplot as plt
# time.process_time()
# 只计算了程序运行CPU的时间,返回值是浮点数,记录开始和结束时间,做差即可
import time
start = time.process_time()
# 定义函数,读取txt文档,参数为文件名称及格式
def loadDataSet(fileName):
# 定义两个空列表,一个用于存储数据,一个用于存储标签
dataMat = []
labelMat = []
file_object = open(fileName)
# 读取所有行(直到结束符EOF)并返回列表
for line in file_object.readlines():
# 以'\t'为分隔符,对字符串进行切片(要求txt文档是以'\t'为分隔符)
# 将每行的前两个元素组合成一个列表,分配给dataMat列表;第三个元素分配给labelMat
lineArr = line.strip().split('\t')
dataMat.append([float(lineArr[0]), float(lineArr[1])])
labelMat.append(float(lineArr[2]))
# 返回两个列表
return dataMat,labelMat
# 其中data以列表嵌套列表的形式显示坐标信息[[x1,x2],...]
# 其中label以列表的形式显示数据对应的类别标签信息[y1,y2...]
# 将下载的数据置于data文件夹中,将data文件夹与.py文件置于同一个文件夹中
data,label = loadDataSet('data/data1.txt')
# 打印的是数据data的维度,即坐标(x1,x2)的维度2
dataDimention = len(data[0])
plt.figure()
'''
本次参考的数据集,前50个label为1,后50个label为-1
[:50,0]前50行第1列,[:50,1]前50行第2列。本次数据的label前50为+1,后50为-1
color是点的颜色,marker是点的形状、label是标记
'''
# 绘制输入数据的散点图
# loadDataSet返回的是两个列表,为什么还是需要转换一次?
# Python中只有列表List和元组tuple,Numpy库中有数组array.
# Python列表可以存储一维数组,通过列表的嵌套可以实现多维数组;而Numpy中的数组array专门用于数组,List不具有array的全部属性
# 因为通过下表读取列表时,需要的是numpy的array而不是python自己的列表格式,所以即使data是列表,也需要使用numpy.array()强制转换一下
datanp = np.array(data)
labelnp = np.array(label)
plt.scatter(datanp[:50, 0], datanp[:50, 1], marker = 'x', color = 'm', label='1', s = 30)
plt.scatter(datanp[50:, 0], datanp[50:, 1], marker = 'o', color = 'r', label='-1', s = 15)
"""
体会列表list与数组array的区别
print(data) # 列表是以方括号“[]”包围的数据集合,不同成员以“,”分隔
print(datanp) # numpy库中的array是以方括号“[]”包围的数据集合,不同成员以空格“ ”分隔
"""
"""
调用优化函数:solvers.qp(P,q,G,h)
分析问题:本次数据为二维,则得到的分离超平面为:w1 * x1 + w2 * x2 + b = 0
即求列向量[w1, w2, b]
故:
P为3*3的矩阵,正定
q为3*1的0矩阵
G为100*3的矩阵
h为100*1的label矩阵
生成cvxopt里面对应的参数矩阵/向量
默认zeros创建的列表元素类型是浮点型的,如果要使用其他类型,可以设置dtype(data-type, optional)参数进行声明
"""
# 对角线为1的矩阵,其他元素均为0
p1 = np.eye(dataDimention)
# 生成元素均为0的列向量和行向量
p2 = np.zeros((dataDimention,1))
p3 = np.zeros((1, dataDimention+1))
# 垂直叠堆列表
ptmp = np.hstack((p1,p2))
# 水平叠堆列表
p = np.vstack((ptmp,p3))
# 强制转换,将列表转换为矩阵
P = matrix(p)
'''
矩阵
1. 0. 0.
0. 1. 0.
0. 0. 0.
'''
q = matrix(np.zeros((dataDimention+1,1)))
'''
矩阵
0.
0.
0.
'''
# 此循环的作用
# 标签为-1的坐标(x1, x2)元素符号不变,标签为+1的坐标(x1, x2)元素全部取相反数(结合3.3中的行列式G进行理解)
# m = 100
m = len(label)
# 定义一个空的列表a
a = []
for i in range(m):
# 将两个列表的元素合并产生一个新的列表,此处data[i]是一个2*1的列表,[1]是一个元素为1的列表,则tmp的第0列全为1
# append是list中特有的方法,故此处选择类型为list的data
tmp = data[i] + [1]
# print(data[i]) data为2维列表
# print(tmp) tmp为3维列表
for j in range(dataDimention+1):
# dataDimention的值为2,j取值为0,1,2
'''
分析下面语句的作用:
即如果label[i]为正,则3维列表[1] + data[i]全部取相反数
即如果label[i]为负,则3维列表[1] + data[i]全部不变
本次试验中前50个label为正,后50个label均为负
'''
tmp[j] = -1 * label[i] * tmp[j]
a.append(tmp)
G = matrix(np.array(a))
# print(G)
h = matrix(np.zeros((m,1))-1)
# h为100*1的矩阵,元素全部为-1
# 打印信息
# print(P)
# print(q)
# print(G)
# print(h)
# 求解凸二次规划问题
sol = solvers.qp(P,q,G,h)
'''
Returns a dictionary with keys 'status', 'x', 's', 'y', 'z','primal objective', 'dual objective', 'gap', 'relative gap',
'primal infeasibility, 'dual infeasibility', 'primal slack','dual slack'.
'''
# 打印信息
# The 'status' field has values 'optimal'(最佳的) or 'unknown'.
print(sol['status'])
# If the status is 'optimal', 'x', 's', 'y', 'z' are an approximate solution of the primal and dual optimal solutions.
print(sol['x'])
# 绘制数据散点图,使用原始数据绘制散点图即可
# data1 = datanp[labelnp==1]此语句什么意思?
'''
data1 = datanp[labelnp==1]
data2 = datanp[labelnp==-1]
plt.figure()
plt.scatter(data1[:,0],data1[:,1], marker = 'x', color = 'm', label='1', s = 30)
plt.scatter(data2[:,0],data2[:,1], marker = 'o', color = 'r', label='-1', s = 15)
'''
plt.figure()
plt.scatter(datanp[:50, 0], datanp[:50, 1], marker = 'x', color = 'm', label='1', s = 30)
plt.scatter(datanp[50:, 0], datanp[50:, 1], marker = 'o', color = 'r', label='-1', s = 15)
# 打印分割平面:w1 * x1 + w2 * x2 + b = 0
# QP求解得到的三个参数
w1 = sol['x'][0]
w2 = sol['x'][1]
b = sol['x'][2]
"""
两点确定一条直线
选取两个点,本次选取的为x1的最大值和最小值
然后由分割平面方程w1 * x1 + w2 * x2 + b = 0可知x2 = -1.0 * ( b + w1 * x1 ) / w2
再利用plot绘制直线即可
"""
xmin = min(datanp[:,0])
xmax = max(datanp[:,0])
x2_1 = -1.0*(b+w1*xmin)/w2
x2_2 = -1.0*(b+w1*xmax)/w2
plt.plot([xmin,xmax],[x2_1,x2_2])
plt.show()
# 打印运行时间
end = time.process_time()
print('Running time: %s Seconds'%(end-start))
4:实验结果
4.1:运行结果
pcost dcost gap pres dres
0: 3.1330e-01 1.3808e+01 3e+02 2e+00 2e+02
1: 2.5064e+00 -3.5092e+01 5e+01 3e-01 4e+01
2: 2.5721e+00 -5.3928e+00 8e+00 5e-02 6e+00
3: 1.7081e+00 8.9516e-01 8e-01 1e-15 3e-12
4: 1.8311e+00 1.3537e+00 5e-01 8e-16 8e-13
5: 1.6548e+00 1.6402e+00 1e-02 8e-16 7e-13
6: 1.6529e+00 1.6527e+00 3e-04 8e-16 1e-11
7: 1.6529e+00 1.6529e+00 1e-05 8e-16 1e-10
8: 1.6529e+00 1.6529e+00 1e-06 7e-16 7e-09
Optimal solution found.
optimal
[ 1.04e-03]
[ 1.82e+00]
[-4.46e+00]
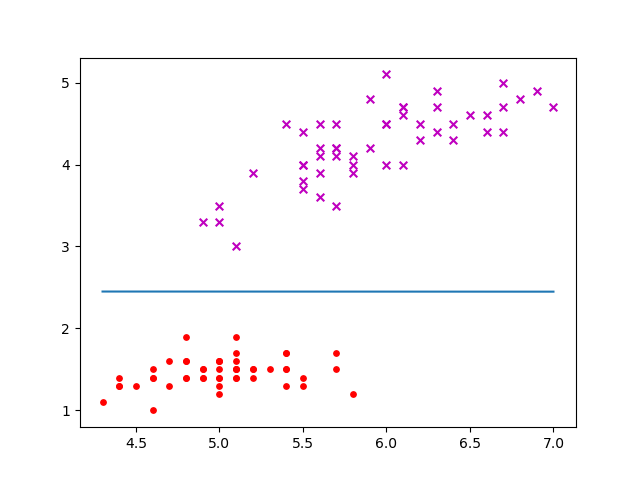
4.2:分离超平面方程
0.00104 x 1 + 1.82 x 2 − 4.46 = 0 0.00104x_1 + 1.82x_2 -4.46 = 0 0.00104x1+1.82x2−4.46=0















 2424
2424











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









