







Kubernetes的基础概念和网络通信方式(二)
Kubernetes的基础概念pod
在国外的一个博主里面有提到两个pod的分类感觉他的想法不错就拿过来演示了,一个是 自主式pod ,一个是 控制管理的pod ,当然在官方的定义下是没有这两个概念的。
自主式pod的定义就是不是控制器管理的pod,自主式pod它被创建以后一旦死亡是没有’人‘将他拉起,也不会创建新的一个pod来满足它的期望值
这里对于pod可能没有什么想法,没事我画一个简单图就清楚了
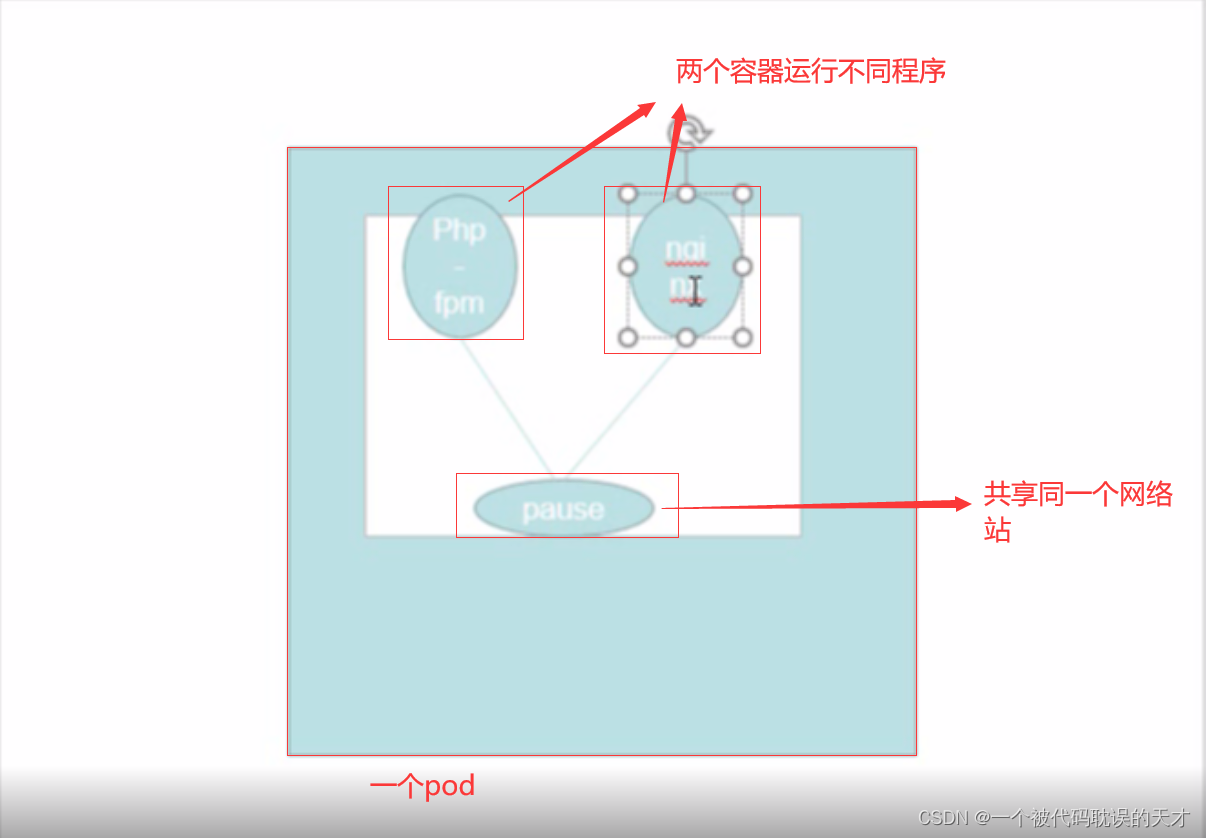
一个pod里面可以有一个以上的容器,里面的数据卷、网络共享同一个
控制器管理的pod
1.ReplicationController & ReplicaSet & Deployment 控制器
ReplicationController
ReplicationController用来确保容器应用的副本数始终保持在用户定义的副本数,即如果有容器异常退出,会自动创建新的Pod来替代;而如果异常多出来的容器也会自动回收。在新版本的Kubernetes 中建议使用ReplicaSet 来取代ReplicationController
ReplicaSet
ReplicaSet跟ReplicationController 没有本质的不同,只是名字不一样,并且ReplicaSet支持集合式的selector
Deployment
虽然ReplicaSet 可以独立使用,但一般还是建议使用Deployment 来自动管理ReplicaSet,这样就无需担心跟其他机制的不兼容问题(比如ReplicaSet 不支持rolling- update但Deployment 支持)
Deployment不支持pod创建,他是通过创建ReplicaSet来创建pod
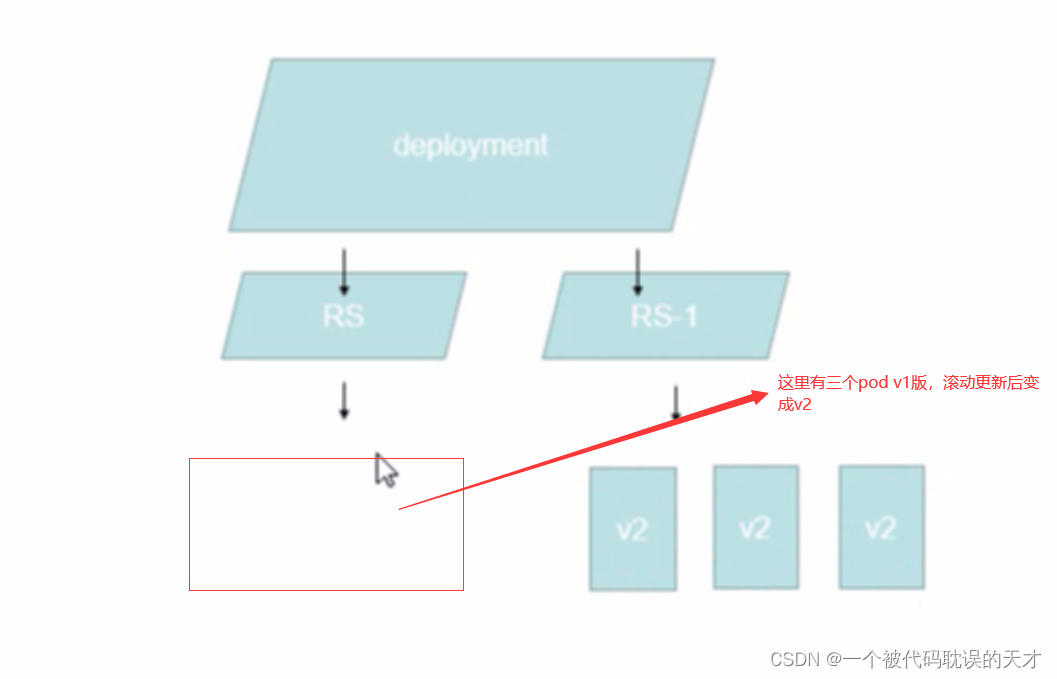
更新时,停用RS,启用RS-1。支持回滚,重新启用RS
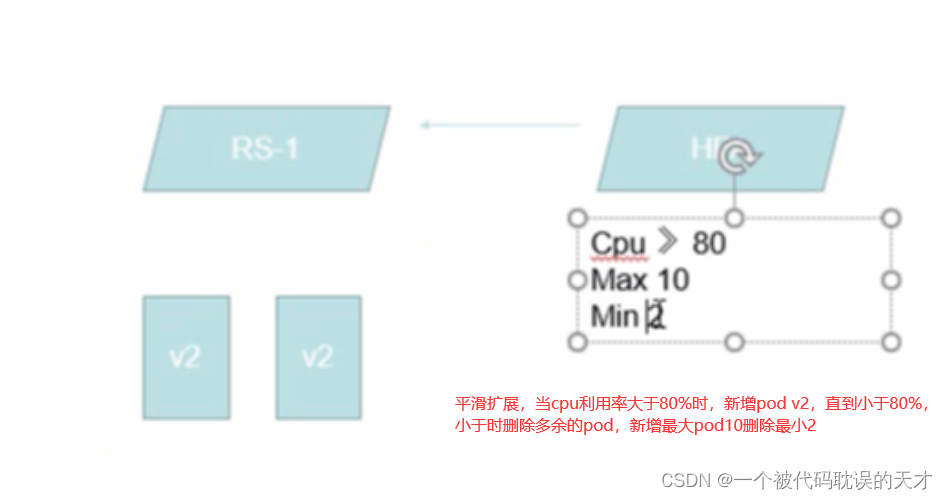
2.HPA ( Hori zontalPodAutoScale ) 控制器
平滑扩展,HorizontalPodAutoscaling仅适用于Deployment 和ReplicaSet ,在V1版本中仅支持根据Pod
的CPU利用率扩所容,在v1alpha 版本中,支持根据内存和用户自定义的metric 扩缩容(目前不太稳定)
3.StatefullSet 控制器
StatefulSet是为了解决有状态服务的问题(对应Deployments 和ReplicaSets 是为无状态服务而设计),其应用场景包括:
- 稳定的持久化存储,即Pod重新调度后还是能访问到相同的持久化数据,基于PVC来实现
- 稳定的网络标志,即Pod重新调度后其PodName 和HostName 不变,基于Headless Service(即没有Cluster IP的Service )来实现
- 有序部署,有序扩展,即Pod是啊續序的,在部署或者扩展的时候要依据定义的顺序依次依次进行(即从0到N-1,在下一个Pod运行之前所有之前的Pod必须都是Running 和Ready状态),基于init containers 来实现
- 有序收缩,有序删除(即从N-1到0)
4.DaemonSet 控制器
DaemonSet确保全部(或者-一些) Node上运行- 一个Pod的副本。当有Node 加入集群时,也会为他们新增一个Pod。当有Node从集群移除时,这些Pod也会被回收。删除DaemonSet 将会删除它创建的所有Pod
使用DaemonSet 的- - 些典型用法:
- 运行集群存储daemon, 例如在每个Node. 上运行glusterd、 ceph。
- 在每个Node.上运行 日志收集daemon, 例如fluentd、 logstash。
- 在每个Node. 上运行 监控daemon, 例如Prometheus Node Exporter
5.Job,Cron job 控制器
Job负责批处理任务,即仅执行- -次的任务,它保证批处理任务的一一个或多个Pod成功结束
Cron Job管理基于时间的Job,即:
- 在给定时间点只运行一次
- 周期性地在给定时间点运行
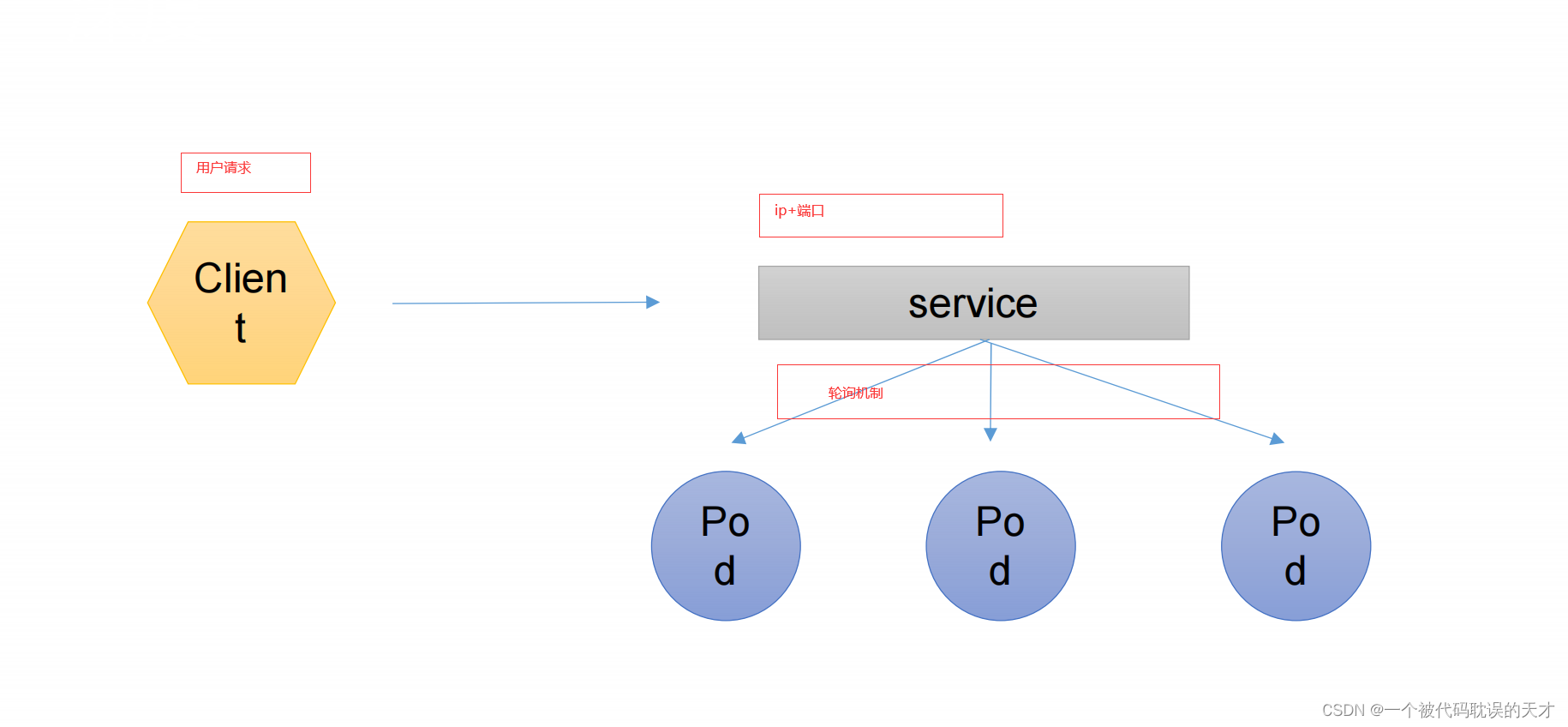
服务发现
客户端向访问一组pod,pod需要有相关性才能被访问
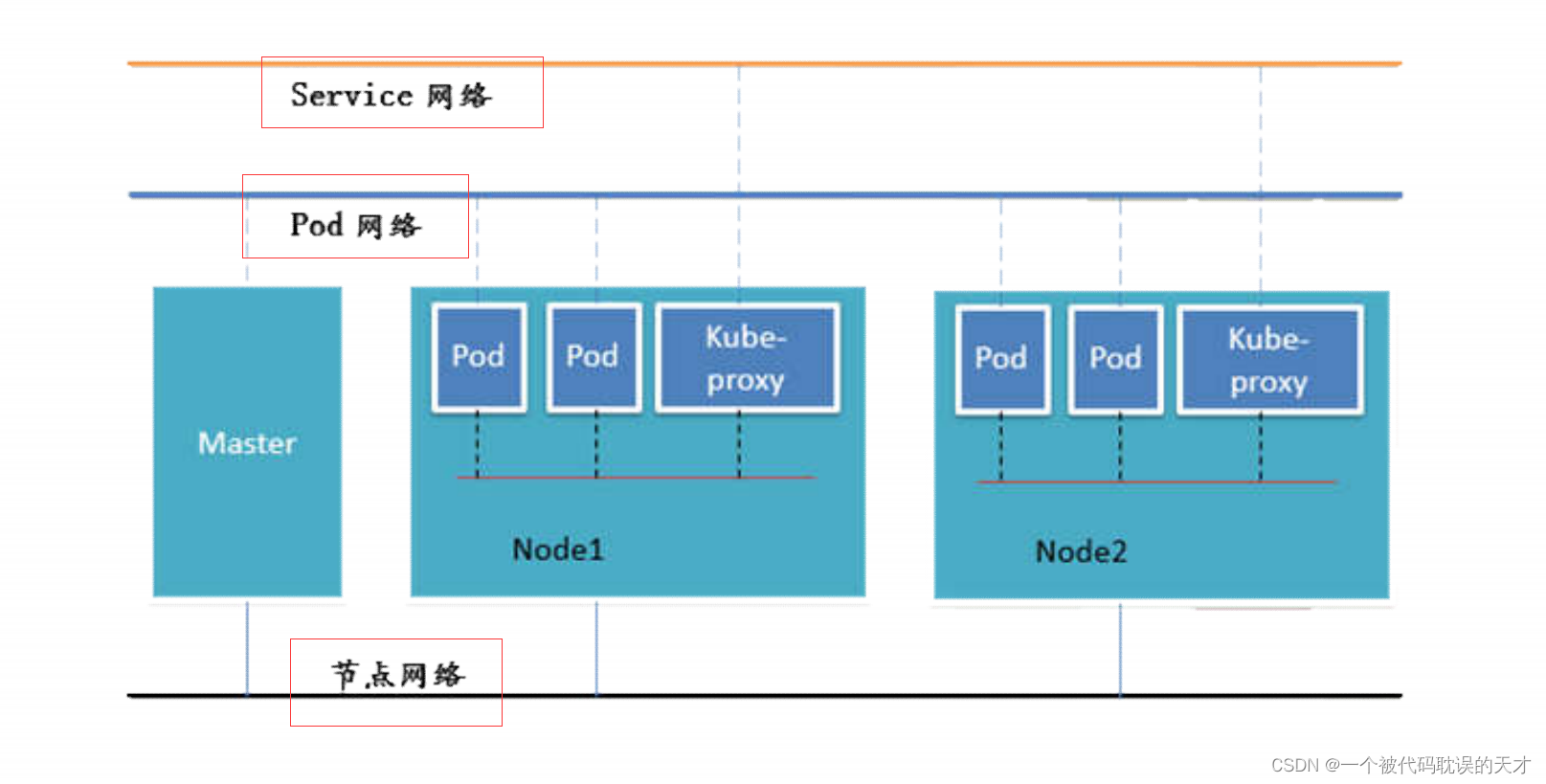
网络通信方式
Kubernetes的网络模型假定了所有Pod都在一个可以直接连通的扁平的网络空间中(所有的pod可以通过IP直接访问),这在GCE (Google Compute Engine) 里面是现成的网络模型,Kubernetes 假定这个网络已经存在。而在私有云里搭建Kubernetes 集群,就不能假定这个网络已经存在了。我们需要自己实现这个网络假设,将不同节点上的Docker 容器之间的互相访问先打通,然后运行Kubernetes
不同情况下的pod通信方式
- 同一个Pod内部通讯:同- 一个Pod 共享同-一个网络命名空间,共享同-一个 Linux协议栈
- Pod1至Pod2
Pod1与Pod2不在同一台主机,Pod的地址是与docker0在同一个网段的,但docker0网段与宿主机网卡是两个完全不同的IP网段,并且不同Node之间的通信只能通过宿主机的物理网卡进行。将Pod的 IP和所在Node的IP关联起来,通过这个关联让Pod可以互相访问
Pod1 与Pod2 在同一台机器,由Docker0 网桥直接转发请求至Pod2, 不需要经过Flannel - Pod至Service 的网络:目前基于性能考虑,全部为iptables 维护和转发
- Pod到外网: Pod 向外网发送请求,查找路由表,转发数据包到宿主机的网卡,宿主网卡完成路由选择后,iptables执行Masquerade,把源IP更改为宿主网卡的IP,然后向外网服务器发送请求
外网访问Pod: Service
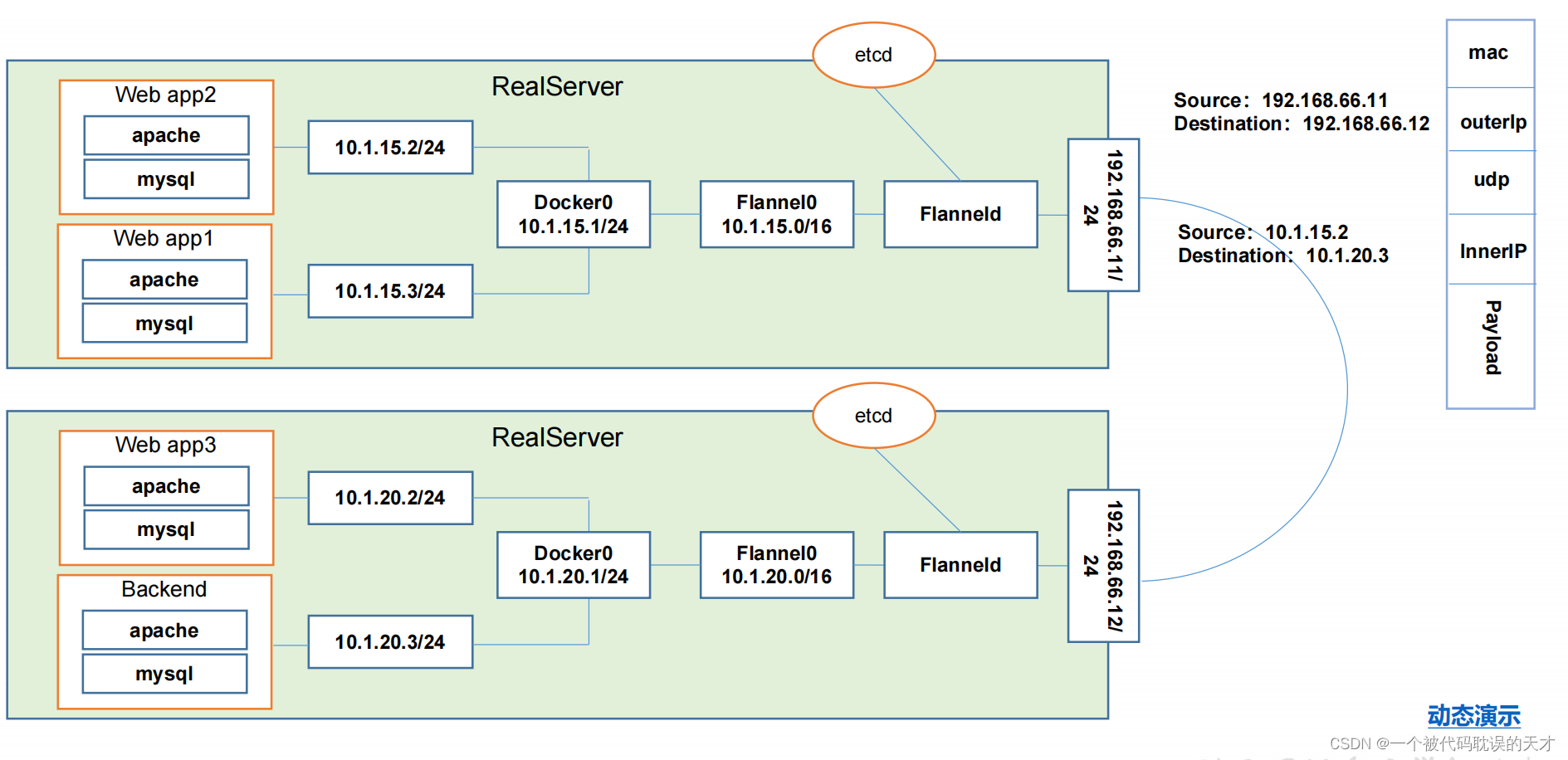
这里的etcd封装了右侧的信息,flanneld组件
ETCD之Flannel 提供说明:
存储管理Flannel可分配的IP地址段资源
监控ETCD中每个Pod的实际地址,并在内存中建立维护Pod 节点路由表














 891
891











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









