







如何优化百万级别数据导出(excel 文件)
哈喽,小伙伴们,大家好,我是爱抄中间件代码的水货码农,路人丙;
今天想跟大家分享一下,自己在参与公司项目优化的一个接口的复盘心得,先说结果:优化之后,接口响应速度平均提高了10倍。
- 设计到的技术:
- 自定义线程池
- CountDownLatch
- 大分页sql优化
- 优化过程中遇到的困难:多线程操作共享资源条件分页对象时,导致并发的问题(有多种解决方案哦,相信你看完一定会有收获)
- 放心今天,我也抄了开源的代码(jvm钩子函数、netty线程池参数配置参考,高性能mysql)
背景
其实就是优化一个excel导出接口
未优化前存在的问题
- 接口响应时间长(这个还好,至少还能用,只是体验差了一点而已)
- 数据全量加载到内存导致进程oom,不可用(这个危害就大了,幸好及时发现,不然得被leader公开鞭刑)
业务接口流程
看到这里小伙伴可能会问了,就这?就这?就这?(确实就这!)
业务流程很简单是吧?
我先说优化思路:
- 用户角度:暂时没什么优化,其实也有,给个友情提示(转圈圈,整好看点!)
- db:全量查询的sql好像也没有什么优化的,其实也有,查询的时候尽量只写需要的字段
- 导出处理环节:之前一个线程干活,那多几个线程干活可不可以呢?(确实可以)
优化后
业务接口流程(优化版v1)
这下就优点详细了
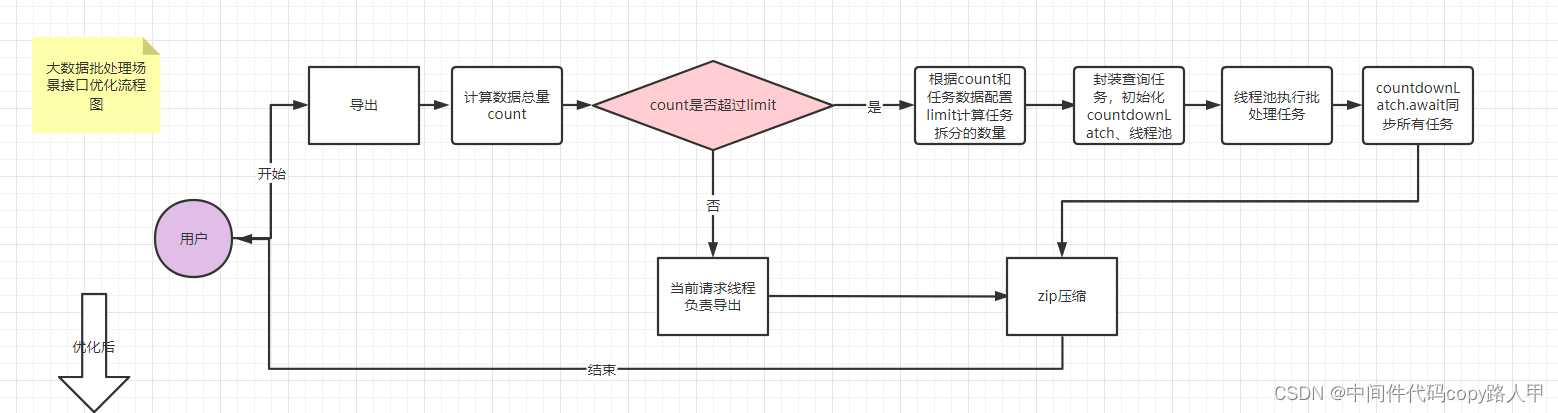
相信能读到我的文章的小伙伴都是聪明人,肯定能够猜懂图上的意思(有问题可以评论区@我)
思想就是:分而治之的思想
通过可以配置的limit字段(代码里用的是exportExcel字段)来进行任务的拆分,代码统一粘贴到后面
业务接口流程(优化版v2)
任务拆分后,我们称之为task,此时我们会发现,每个任务就是一个大的page分页查询,针对大的分页查询sql使用limit字段会全表扫描,所以建议先把所有任务分割点的主键查出来,sql通过任务的主键范围来进行查询(参考高性能mysql书)
优化效果
(1)避免了导出数据全部加载到内存导致oom的潜在风险–这个比较重要
(2)提高了导出接口的响应速度,在硬件条件以及测试数据不变的情况下,响应速度快了10倍(线上环境效果应该会更好)
复盘
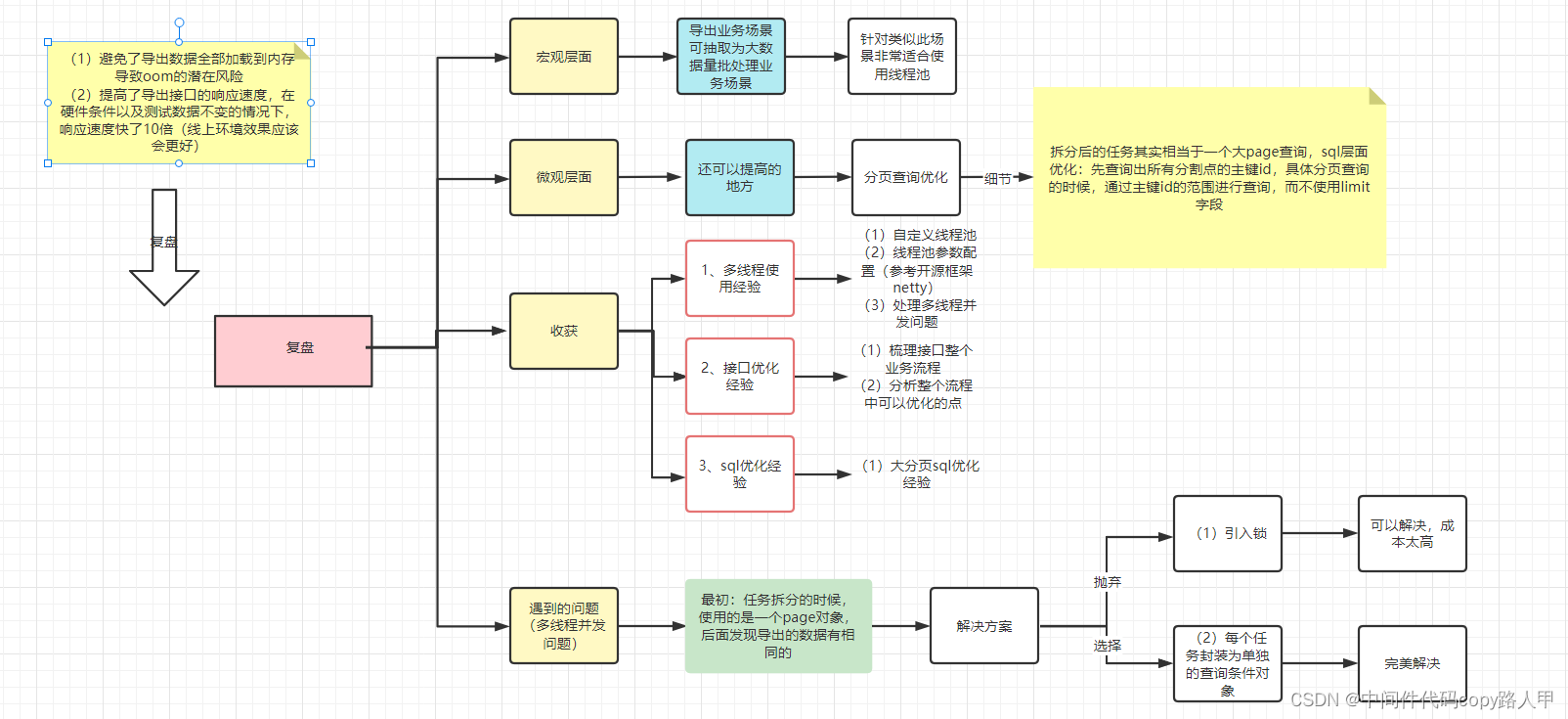
宏观层面
导出业务场景可抽取为大数据量批处理业务场景--------简单一句话,以后只要遇到大数据批处理的场景,都采取分而治之的思想(如果你是Java选手,直接用线程池)
- 针对类似此场景非常适合使用线程池
遇到的困难
收获
1、多线程使用经验
(1)自定义线程池
(2)线程池参数配置(参考开源框架netty)
(3)处理多线程并发问题
2、接口优化经验
(1)梳理接口整个业务流程
(2)分析整个流程中可以优化的点
3、sql优化经验
(1)大分页sql优化经验
代码实现
压缩工具依赖
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-compress</artifactId>
<version>1.18</version>
</dependency>
导出核心代码
public void export(@ApiIgnore Searchable searchable, HttpServletResponse response, String rule,@ApiIgnore@CurrentUser User user){
SearchFilter searchFilter = null;
LogController.checkUser(user,searchFilter,searchable);
if (rule!= null && rule.trim().length() > 0){
String[] s = rule.split("_");
searchable.addSort("desc".equals(s[1].toLowerCase())?Direction.DESC:Direction.ASC,s[0]);
}
final int count = loginLogService.count(searchable);
if (exportExcel == 0){
//默认1000
exportExcel = SINGLE_MAX_COUNT;
}
//1、创建压缩目录
String tmpPath = zipDir + "/" + uuidUtil.getID16();
File tmp = new File(tmpPath);
// 没有就创建
if(!tmp.exists()) tmp.mkdirs();
if (count <= exportExcel){
//没有超过单线程导出数量阈值
loginLogService.export(loginLogService.findList(searchable),1L,tmpPath);
}else {
//批处理
int flag = count%exportExcel;
final int tasks = (count/exportExcel) + (flag == 0?0:1);
CountDownLatch latch = new CountDownLatch(tasks);
List<SearchRequest> taskQueue = new ArrayList<>();
for (int i = 1; i <= tasks; i++) {
final SearchRequest searchRequest = new SearchRequest();
searchRequest.setPage(i,exportExcel);
searchRequest.addSearchFilters(searchable.getSearchFilters());
searchRequest.addSearchFilter(searchFilter);
searchRequest.addSort(searchable.getSorts());
taskQueue.add(searchRequest);
}
taskQueue.forEach(task->{
ThreadPoolFactoryUtil.getInstance().submit(()->{
loginLogService.export(loginLogService.findPageList(task).getRecords(), task.getPage().getPn(), tmpPath);
latch.countDown();
});
});
try {
latch.await();
} catch (InterruptedException e) {
throw new CustomBusinessException("批处理导出异常!");
}
taskQueue = null;
}
//打包压缩
try {
fileUtils.doCompress("登录日志.zip", tmpPath, response);
} catch (IOException e) {
throw new CustomBusinessException("打包压缩失败!");
}
//删除临时目录
FileUtils.deleteFileDictory(new File(tmpPath));
}
FileUtils工具类
package com.unionbigdata.rdc.sys.util;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.compress.archivers.ArchiveEntry;
import org.apache.commons.compress.archivers.zip.Zip64Mode;
import org.apache.commons.compress.archivers.zip.ZipArchiveEntry;
import org.apache.commons.compress.archivers.zip.ZipArchiveOutputStream;
import org.springframework.stereotype.Component;
import javax.servlet.http.HttpServletResponse;
import java.io.*;
import java.net.URLEncoder;
/**
* @title: FileUtils
* @Description: TODO
* @Author Lmm
* @Date: 2022/10/31 14:34
* @Version 1.0
*/
@Slf4j
@Component
public class FileUtils {
public void doCompress(String zipName, String tmpPath, HttpServletResponse response) throws IOException {
File files = new File(tmpPath);
//不存在或者不是文件夹(不考虑当前是文件的情况)的情况
if(!files.exists()||!files.isDirectory()){
return;
}
//设置响应头,控制浏览器下载该文件
response.reset();
response.setHeader("Content-Type","application/octet-stream");
response.setHeader("Content-Disposition",
"attachment;filename="+ URLEncoder.encode(zipName, "UTF-8"));
OutputStream out = response.getOutputStream();
File[] fileslist = files.listFiles();
ZipArchiveOutputStream zous = new ZipArchiveOutputStream(out);
zous.setUseZip64(Zip64Mode.AsNeeded);
for (File file : fileslist) {
String fileName = file.getName();
InputStream inputStream = new FileInputStream(file);
ByteArrayOutputStream baos = new ByteArrayOutputStream();
byte[] buffer = new byte[1024];
int len;
while ((len = inputStream.read(buffer)) != -1) {
baos.write(buffer, 0, len);
}
if (baos != null) {
baos.flush();
}
byte[] bytes = baos.toByteArray();
//设置文件名
ArchiveEntry entry = new ZipArchiveEntry(fileName);
zous.putArchiveEntry(entry);
zous.write(bytes);
zous.closeArchiveEntry();
if (baos != null) {
baos.close();
}
inputStream.close();
}
if(zous != null) {
zous.close();
}
if (out != null) {
out.flush();
out.close();
}
}
public static void deleteFileDictory(File file) {
//文件的情况
if (file.isFile()) {
file.delete();
}
//文件夹的情况
if (file.isDirectory()) {
File[] files = file.listFiles();
for (File dfile : files) {
deleteFileDictory(dfile);
}
file.delete();
}
}
}
线程池工具类(部分代码来自JDK线程池默认工厂源码DefaultThreadFactory)
import org.apache.commons.lang3.StringUtils;
import javax.validation.constraints.NotNull;
import java.util.concurrent.LinkedBlockingQueue;
import java.util.concurrent.ThreadFactory;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicInteger;
/**
* @title: ThreadFactoryUtil
* @Description: 线程池工具类:自定义线程池
* @Author Lmm
* @Date: 2022/10/31 9:52
* @Version 1.0
*/
public class ThreadPoolFactoryUtil {
private volatile static ThreadPoolExecutor instance;
private final static int threadCounts = Runtime.getRuntime().availableProcessors();
private final static int threadTasks = 200;
private ThreadPoolFactoryUtil(){}
public static ThreadPoolExecutor getInstance(){
if (instance == null){
synchronized (ThreadPoolFactoryUtil.class){
if (instance == null){
instance = new ThreadPoolExecutor(threadCounts, threadCounts, 1, TimeUnit.MINUTES, new LinkedBlockingQueue<>(threadTasks),new MyThreadFactory("批处理导出"));
}
}
}
return instance;
}
public static void close(){
if (instance == null )
return;
instance.shutdown();
}
static class MyThreadFactory implements ThreadFactory{
private static final AtomicInteger poolNumber = new AtomicInteger(1);
private final ThreadGroup group;
private final AtomicInteger threadNumber = new AtomicInteger(1);
private final String namePrefix;
MyThreadFactory(String name) {
SecurityManager s = System.getSecurityManager();
group = (s != null) ? s.getThreadGroup() :
Thread.currentThread().getThreadGroup();
namePrefix = (StringUtils.isBlank(name)?"pool-":name+"-") +
poolNumber.getAndIncrement() +
"-thread-";
}
@Override
public Thread newThread(@NotNull Runnable r) {
Thread t = new Thread(group, r,
namePrefix + threadNumber.getAndIncrement(),
0);
if (t.isDaemon())
t.setDaemon(false);
if (t.getPriority() != Thread.NORM_PRIORITY)
t.setPriority(Thread.NORM_PRIORITY);
return t;
}
}
}
线程池优雅关闭(jvm钩子函数这段代码来自RocketMQ的源码)
//注册jvm钩子函数,关闭线程池资源
Runtime.getRuntime().addShutdownHook(new Thread(ThreadPoolFactoryUtil::close));















 2299
2299











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









