









hello 大家好,我是还没毕业就有1年工作经验且爱抄中间件代码的路人丙,今天想跟大家分享一下笔者“哪些年 ,抄过的中间件代码”,以及阅读RocketMQ源码剖析之注册中心NameServer的笔记记录。
源码版本:RocketMQ4.6
笔者学习过程的注释:后面会把笔者有注释的地址贴出来
如果你跟我一样也是菜鸟程序员,那一定要看这篇文章!
如果你跟我一样也是菜鸟程序员,那一定要看这篇文章!
如果你跟我一样也是菜鸟程序员,那一定要看这篇文章!
熟悉RocketMQ的小伙伴,都知道NameServer 是MQ的大脑,注册中心;了解注册中心的小伙伴都知道,注册中心有三大基本能力:服务发现、服务注册、元信息路由管理,本篇文章主要记录了笔者通过源码来剖析NameServer中的优与势,以及值得借鉴的编程经验分享
2.1 nameServer启动流程
老规矩,我们先找到程序的入口:相信聪明人已经找到了,代码位置:NamesrvStartup#main()
接下来给大家展示一下nameServer启动大概的流程图:
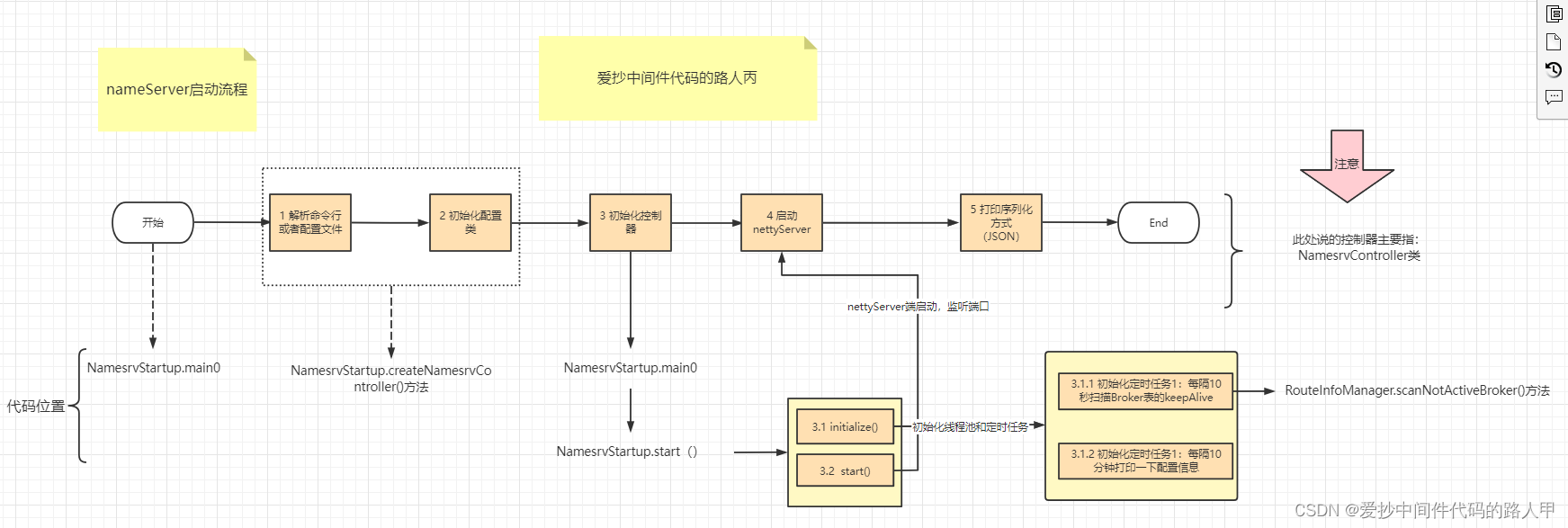
这个图大概已经画出了nameServer启动大概会做的3件事:
- (1)解析命令行以及配置文件,完成配置类的初始化
- (2)初始化nettyServer并启动端口9876
- (3)启动2大定时任务:心跳包扫描和打印配置信息
nameServer启动流程的源码比较简单,感兴趣的话,可以跟着图以及源码debug看一下具体的一些细节
笔者觉得比较感兴趣的点如下
- netty Server构造的编码,比如epoll 和 nio 适配,reactor 反应模型
- netty公共共享业务处理器抽取:比如编码、连接管理以及具体的请求处理
笔者任务,rpc请求处理写的比较好的原因如下:它把每一个请求都会封装成一个异步任务,并交给对应业务的线程池去执行,这样做法有3个好处:
- 第一个:采用异步方式,系统的吞吐量会比较好
- 第二个:采用线程池跟业务绑定同时业务之间隔离,可以方便更灵活的分配和使用资源
- 第三个:在公司从来没看到过类似的代码,遇到对吞吐量有要求的场景可以抄
这一块其实属于RocketMQ的rpc的内容,代码写的很nice,借鉴意义也比较大,总之比笔者自己写的rpc好太多了(苦笑!!!)
NettyRemotingAbstract
public void processRequestCommand(final ChannelHandlerContext ctx, final RemotingCommand cmd) {
//根据RemotingCommand中的code获取processor和ExecutorService
final Pair<NettyRequestProcessor, ExecutorService> matched = this.processorTable.get(cmd.getCode());
final Pair<NettyRequestProcessor, ExecutorService> pair = null == matched ? this.defaultRequestProcessor : matched;
//opaque 对应于request ID
//RemotingCommand会为每一个request产生一个request ID, 从0开始, 每次加1
final int opaque = cmd.getOpaque();
if (pair != null) {
//构造异步任务的执行目标target
Runnable run = new Runnable() {
@Override
public void run() {
try {
//before rpc hook
doBeforeRpcHooks(RemotingHelper.parseChannelRemoteAddr(ctx.channel()), cmd);
//processor处理请求
final RemotingCommand response = pair.getObject1().processRequest(ctx, cmd);
//after rpc hook
doAfterRpcHooks(RemotingHelper.parseChannelRemoteAddr(ctx.channel()), cmd, response);
if (!cmd.isOnewayRPC()) {
if (response != null) {
response.setOpaque(opaque);
response.markResponseType();
try {
//写入结果
ctx.writeAndFlush(response);
} catch (Throwable e) {
log.error("process request over, but response failed", e);
log.error(cmd.toString());
log.error(response.toString());
}
} else {
}
}
} catch (Throwable e) {
log.error("process request exception", e);
log.error(cmd.toString());
if (!cmd.isOnewayRPC()) {
final RemotingCommand response = RemotingCommand.createResponseCommand(RemotingSysResponseCode.SYSTEM_ERROR,
RemotingHelper.exceptionSimpleDesc(e));
response.setOpaque(opaque);
ctx.writeAndFlush(response);
}
}
}
};
if (pair.getObject1().rejectRequest()) {
final RemotingCommand response = RemotingCommand.createResponseCommand(RemotingSysResponseCode.SYSTEM_BUSY,
"[REJECTREQUEST]system busy, start flow control for a while");
response.setOpaque(opaque);
ctx.writeAndFlush(response);
return;
}
try {
//使用异步任务执行目标target,封装RequestTask
final RequestTask requestTask = new RequestTask(run, ctx.channel(), cmd);
//提交任务到线程池
pair.getObject2().submit(requestTask);
} catch (RejectedExecutionException e) {
if ((System.currentTimeMillis() % 10000) == 0) {
log.warn(RemotingHelper.parseChannelRemoteAddr(ctx.channel())
+ ", too many requests and system thread pool busy, RejectedExecutionException "
+ pair.getObject2().toString()
+ " request code: " + cmd.getCode());
}
if (!cmd.isOnewayRPC()) {
final RemotingCommand response = RemotingCommand.createResponseCommand(RemotingSysResponseCode.SYSTEM_BUSY,
"[OVERLOAD]system busy, start flow control for a while");
response.setOpaque(opaque);
ctx.writeAndFlush(response);
}
}
} else {
String error = " request type " + cmd.getCode() + " not supported";
final RemotingCommand response =
RemotingCommand.createResponseCommand(RemotingSysResponseCode.REQUEST_CODE_NOT_SUPPORTED, error);
response.setOpaque(opaque);
ctx.writeAndFlush(response);
log.error(RemotingHelper.parseChannelRemoteAddr(ctx.channel()) + error);
}
}
nameServer的启动流程到这里就结束了,比较简单,其中认为有学习价值的就是其rpc,netty这块的代码可以学习借鉴(抄抄抄)。
2.2 broker元数据注册流程
笔者阅读了broker元数据注册的源码之后,发现注册主要有2个场景:初始化时注册和周期性注册
关于broker注册的元信息有哪些?等后面再分享,这一小节只分析broker注册元信息的流程和相关的一些细节
至于broker的启动流程,就不给大家画了,类似nameServer启动流程
首先还是把源码入口给大家找出来:
BrokerController#start
public void start() throws Exception {
/ 。。。省略无关代码。。。/
if (!messageStoreConfig.isEnableDLegerCommitLog()) {
startProcessorByHa(messageStoreConfig.getBrokerRole());
handleSlaveSynchronize(messageStoreConfig.getBrokerRole());
//(1)初始化时注册
this.registerBrokerAll(true, false, true);
}
// (2)周期性心跳包上报自己的元信息:周期的 范围为10 -60s,不配置默认是30秒
this.scheduledExecutorService.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
try {
//registerBrokerAll 注册的核心方法
BrokerController.this.registerBrokerAll(true, false, brokerConfig.isForceRegister());
} catch (Throwable e) {
log.error("registerBrokerAll Exception", e);
}
}
}, 1000 * 10, Math.max(10000, Math.min(brokerConfig.getRegisterNameServerPeriod(), 60000)), TimeUnit.MILLISECONDS);
//默认30s
/ 。。。省略无关代码。。。/
}
这上面的代码主要展示了注册的2个时机:分别是if条件满足的代码(1)以及周期调度(2)
核心方法主要在registerBrokerAll()
接下来简单的画一下broker端注册大概的流程图:
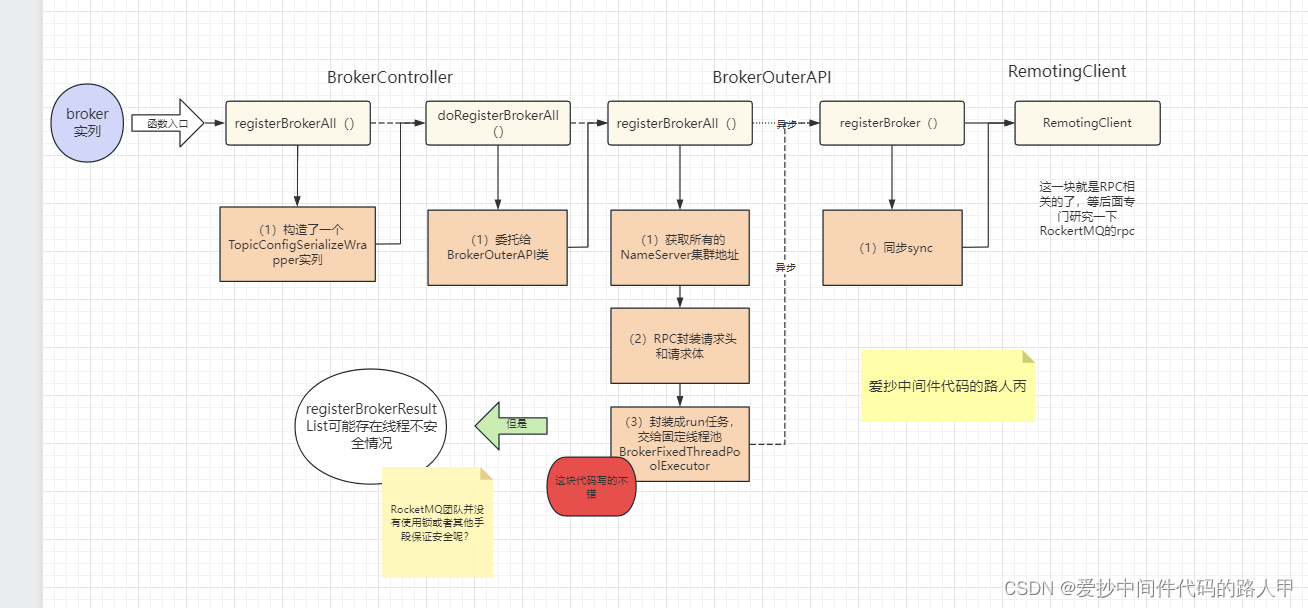
相对比较简单,这个流程中有一处的代码写的比较好,推荐大家抄起来:(笔者 优化百万级数据Excel文件导出接口 就是抄的这块代码:)
final List<RegisterBrokerResult> registerBrokerResultList = Lists.newArrayList();
/...省略代码../
final CountDownLatch countDownLatch = new CountDownLatch(nameServerAddressList.size());
//(1)遍历 nameServerAddressList 列表
// 分别向NameServer注册
for (final String namesrvAddr : nameServerAddressList) {
brokerOuterExecutor.execute(new Runnable() {
@Override
public void run() { // 封装成runnable任务
try {
// (2) 发起元信息注册RPC请求
// 这里肯定是发起RPC请求 向NameServer 注册 自己的元信息 rpc核心细节
RegisterBrokerResult result = registerBroker(namesrvAddr,oneway, timeoutMills,requestHeader,body);
if (result != null) {
// 可能有低并发问题
// 但是为什么没有保证其线程安全呢?
registerBrokerResultList.add(result);
}
log.info("register broker[{}]to name server {} OK", brokerId, namesrvAddr);
} catch (Exception e) {
log.warn("registerBroker Exception, {}", namesrvAddr, e);
} finally {
// 可以学习的点,放在finally代码块中
countDownLatch.countDown();
}
}
});
}
try {
// 默认6s超时 这些值都可以压测估算出来
countDownLatch.await(timeoutMills, TimeUnit.MILLISECONDS);
} catch (InterruptedException e) {
}
笔者为什么推荐抄这块代码呢?主要有以下3个原因:
- 笔者在实际业务做接口优化的时候,借鉴过这块代码,落地效果很显著
- 依稀记得之前美团技术博客也有一篇线程池相关的,也应用了类似这块代码的方案做业务链路rt的优化
- 你可以把 并发基础知识应用到实践
笔者在公司这么久,从来没见过类似的代码(可能是因为笔者的公司太小了)
这块代码主要应用线程池和countDownLatch工具类实现了异步并发,这样可以很好的提高接口的吞吐量
除此之外,这个流程中还比较关键的就是RemotingCommand类中封装的code =RequestCode.REGISTER_BROKER
RequestCode类(rpc 对应的业务处理器编码)
public static final int REGISTER_BROKER = 103; // 注册broker
在RocketMQ中rpc请求的RequestCode决定了服务端如何处理这个请求
2.3 nameServer元数据接受流程
上面小结,笔者跟着源码研究了一下broker注册的2大时机,分析了一下大概的流程,其中也分享了笔者认为值得借鉴和抄的代码,接下来,我们就看一下nameServer的netty服务怎么处理code为REGISTER_BROKER的请求
首先我们还是先找到nameServer接受broker注册请求的入口,大家还记的前面分析nameServer启动流程中会起一个nettyServer呢?没错,了解netty的小伙伴,应该都知道业务逻辑都写在业务处理器中:DefaultRequestProcessor
代码入口:
NamesrvController#initialize()-》#registerProcessor()
private void registerProcessor() {
if (namesrvConfig.isClusterTest()) {
this.remotingServer.registerDefaultProcessor(new ClusterTestRequestProcessor(this, namesrvConfig.getProductEnvName()),
this.remotingExecutor);
} else {
// 注册默认的通信处理器 核心方法:processRequest(),依据协定的code做相应的业务处理,code位于RequestCode
// 看到这里就明白了,其实如果我们想看nameServer的功能,我们直接看DefaultRequestProcessor 处理器
this.remotingServer.registerDefaultProcessor(new DefaultRequestProcessor(this), this.remotingExecutor);// 注册默认处理器,并绑定remotingExecutor线程池
}
}
所以我们可以直接去DefaultRequestProcessor中找:如何处理broker的注册请求
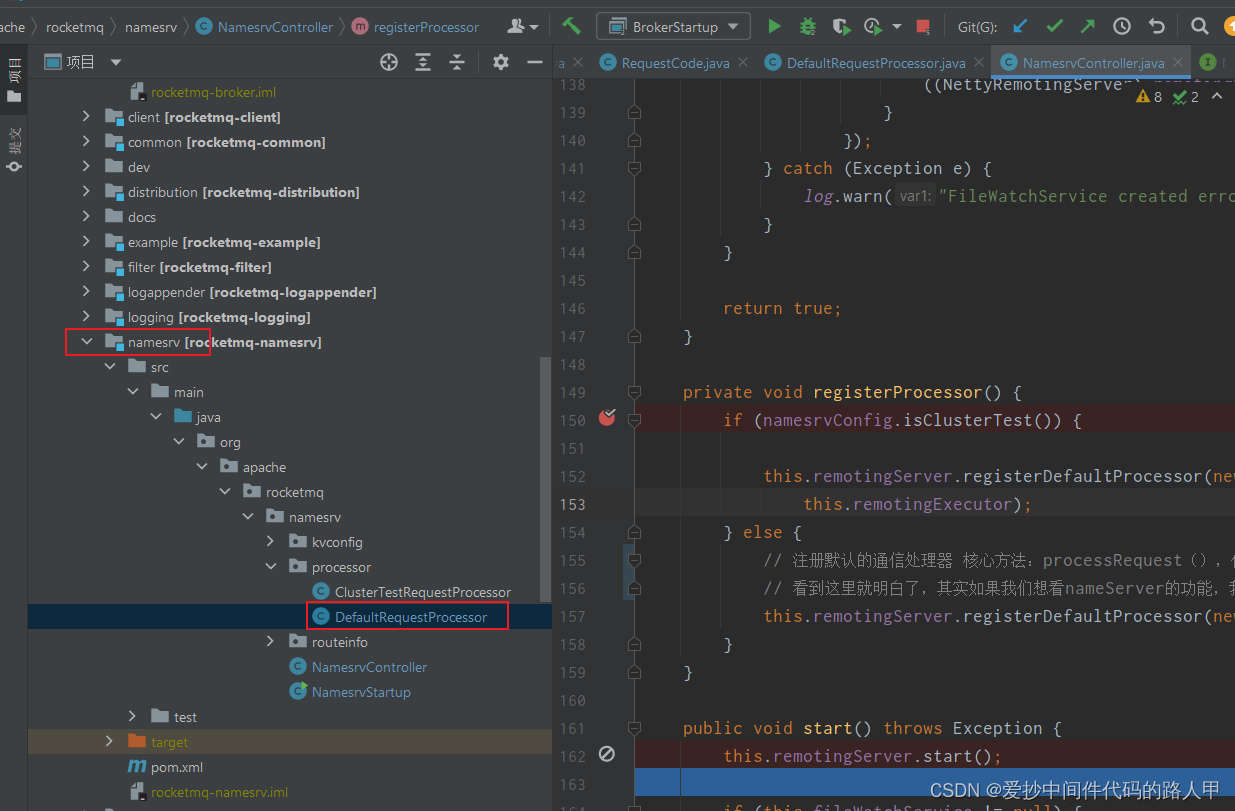
DefaultRequestProcessor 实现了 NettyRequestProcessor接口,直接进NettyRequestProcessor
public interface NettyRequestProcessor {
// 处理请求 定义
RemotingCommand processRequest(ChannelHandlerContext ctx, RemotingCommand request)
throws Exception;
//拒绝请求 定义
boolean rejectRequest();
}
我们直接看核心代码:processRequest()
public RemotingCommand processRequest(ChannelHandlerContext ctx,
RemotingCommand request) throws RemotingCommandException {
if (ctx != null) {
log.debug("receive request, {} {} {}",
request.getCode(),
RemotingHelper.parseChannelRemoteAddr(ctx.channel()),
request);
}
//看到这里其实大概也能明白为什么 RocketMQ-admin为什么只用配置NameServer集群地址即可
switch (request.getCode()) {
// 配置k v 配置
case RequestCode.PUT_KV_CONFIG:
return this.putKVConfig(ctx, request);
// 获取k v 配置
case RequestCode.GET_KV_CONFIG:
return this.getKVConfig(ctx, request);
// 删除 k v 配置
case RequestCode.DELETE_KV_CONFIG:
return this.deleteKVConfig(ctx, request);
// 获取数据版本
case RequestCode.QUERY_DATA_VERSION:
return queryBrokerTopicConfig(ctx, request);
//注册元数据 找到REGISTER_BROKER的code了
case RequestCode.REGISTER_BROKER:
Version brokerVersion = MQVersion.value2Version(request.getVersion());
if (brokerVersion.ordinal() >= MQVersion.Version.V3_0_11.ordinal()) {
return this.registerBrokerWithFilterServer(ctx, request);
} else {
return this.registerBroker(ctx, request);
}
// 移除元数据
case RequestCode.UNREGISTER_BROKER:
return this.unregisterBroker(ctx, request);
//通过topic获取路由信息
case RequestCode.GET_ROUTEINTO_BY_TOPIC:
return this.getRouteInfoByTopic(ctx, request);
// 获取broker集群信息
case RequestCode.GET_BROKER_CLUSTER_INFO:
return this.getBrokerClusterInfo(ctx, request);
case RequestCode.WIPE_WRITE_PERM_OF_BROKER:
return this.wipeWritePermOfBroker(ctx, request);
// 获取所有TOPIC_LIST
case RequestCode.GET_ALL_TOPIC_LIST_FROM_NAMESERVER:
return getAllTopicListFromNameserver(ctx, request);
// 删除topic
case RequestCode.DELETE_TOPIC_IN_NAMESRV:
return deleteTopicInNamesrv(ctx, request);
case RequestCode.GET_KVLIST_BY_NAMESPACE:
return this.getKVListByNamespace(ctx, request);
// 根据集群获取topic
case RequestCode.GET_TOPICS_BY_CLUSTER:
return this.getTopicsByCluster(ctx, request);
case RequestCode.GET_SYSTEM_TOPIC_LIST_FROM_NS:
return this.getSystemTopicListFromNs(ctx, request);
case RequestCode.GET_UNIT_TOPIC_LIST:
return this.getUnitTopicList(ctx, request);
case RequestCode.GET_HAS_UNIT_SUB_TOPIC_LIST:
return this.getHasUnitSubTopicList(ctx, request);
case RequestCode.GET_HAS_UNIT_SUB_UNUNIT_TOPIC_LIST:
return this.getHasUnitSubUnUnitTopicList(ctx, request);
case RequestCode.UPDATE_NAMESRV_CONFIG:
return this.updateConfig(ctx, request);
case RequestCode.GET_NAMESRV_CONFIG:
return this.getConfig(ctx, request);
default:
break;
}
return null;
}
看到Switch没,关键就是RequestCode,我们找到前面讲到broker发送的code REGISTER_BROKER
//注册元数据 找到REGISTER_BROKER的code了
case RequestCode.REGISTER_BROKER:
Version brokerVersion = MQVersion.value2Version(request.getVersion());
if (brokerVersion.ordinal() >= MQVersion.Version.V3_0_11.ordinal()) {
return this.registerBrokerWithFilterServer(ctx, request);
} else {
return this.registerBroker(ctx, request);
}
看到这个Switch,是不是也理解为什么RocketMQ Admin 只需要配置nameServer的地址就是实现扩展了吧
接下来就不给大家贴代码了,直接上图吧!
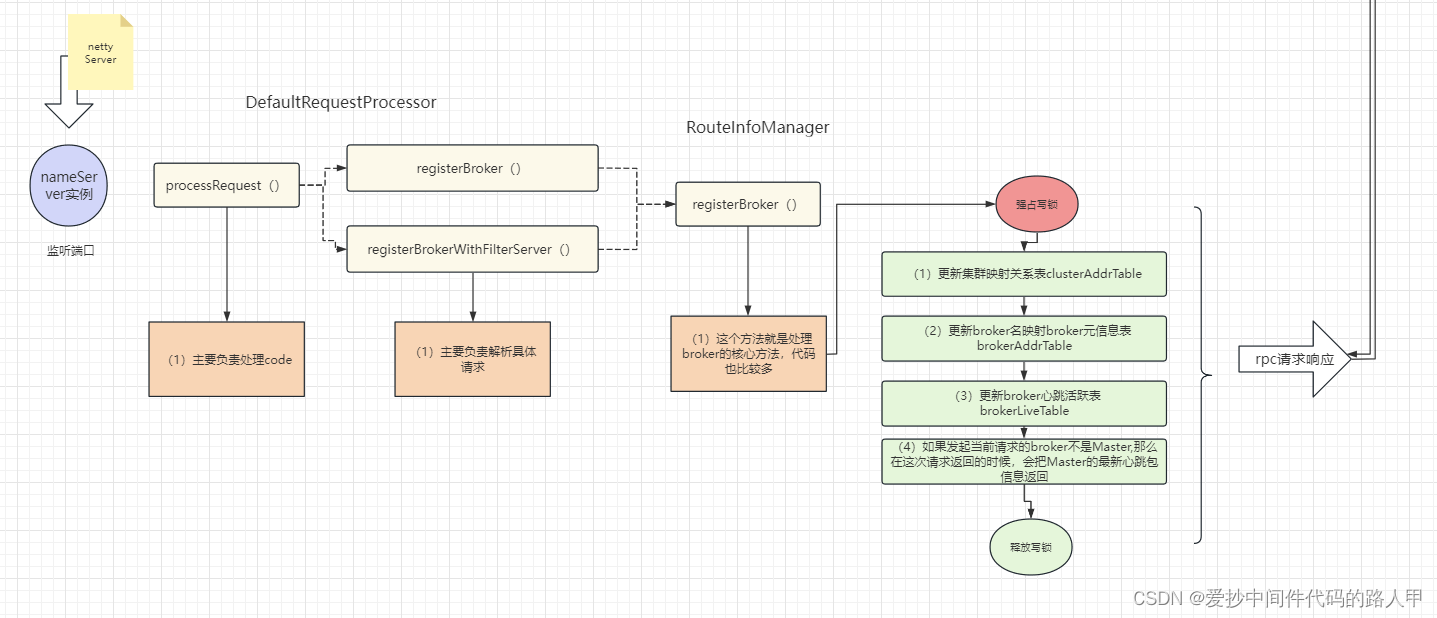
看到这里应该清楚了,原来nameServer的核心都在这个RouteInfoManager类里
接下来就详细的分析一下broker元数据管理类RouteInfoManager的源码
2.4 核心类分析:元数据管理类
上面一节主要分析了,nameServer是如何接收broker的注册请求并发现其核心就是RouteInfoManager类在维护,所以我们接下来就详细的看一下RouteInfoManager的源码
2.4.1RouteInfoManager的核心属性极其含义
private static final InternalLogger log = InternalLoggerFactory.getLogger(LoggerName.NAMESRV_LOGGER_NAME);
// private final static long BROKER_CHANNEL_EXPIRED_TIME = 1000 * 20;
// (1) broker 心跳包最大的间隔时间
private final static long BROKER_CHANNEL_EXPIRED_TIME = 1000 * 60 * 2; // nameserver 与 broker的空闲时长
// (2) 读写锁 负责维护下面几个map的读写安全
private final ReadWriteLock lock = new ReentrantReadWriteLock(); // 读写锁
// (3) key : broker名(broker配置文件中可配置),value:broker元信息 主从元信息
//核心Map: 集群影射: brokerName到Master/Slave机器列表
private final HashMap<String/* brokerName */, BrokerData> brokerAddrTable; // brokerName 和 broker元信息的映射
// (4) key:topic (生产者生产时设置的topic) value: topic的分区消息 topic 与 队列关系,记录同一个主题的消息分布在哪些broker上
//核心Map之1: topic到QueueData ,topic的分区消息或者消费队列信息
private final HashMap<String/* topic */, List<QueueData>> topicQueueTable;
// (5) key : 集群名 value:broker名(一般一个broker名都至少是一主一从)
//核心Map之3: 集群名称,到集群节点映射 : 1个cluster多个broker
private final HashMap<String/* clusterName */, Set<String/* brokerName */>> clusterAddrTable;// 每个集群包含哪些broker
// (6)broker 注册的心跳包元信息 (前面已经源码分析过broker注册的流程了)
//活跃Broker映射表,NameServer每次收到心跳包是会替换该信息
private final HashMap<String/* brokerAddr */, BrokerLiveInfo> brokerLiveTable; // 当前活跃的broker,不是实时存在至少120s延迟:存在的问题,假死继续接受消息,造成消息发送失败
// (7)笔者暂时不清楚
private final HashMap<String/* brokerAddr */, List<String>/* Filter Server */> filterServerTable;
RouteInfoManager核心属性的注释,都写在上面了,关于RouteInfoManager的方法基本上主要负责维护上面提到的(1)~(6)个map的维护,主要使用读写锁ReentrantReadWriteLock保证线程安全。
为什么使用读写锁呢?笔者认为:
注册中心,典型的读多写少的场景,使用ReentrantReadWriteLock能比较好的发挥读并发性能,所以如果你之前在生产环境没用过ReentrantReadWriteLock,可以参考这部分的代码,在类似的业务场景尝试使用读写锁提高程序的整体吞吐量,笔者也是参考了这块代码,才比较有信心在类似业务场景中使用
2.5 broker主动剔除场景(或者说 broker主动下线)
前面,已经提到broker主要通过初始时以及周期性定时2个时机向nameServer集群发送自己的心跳信息,称为注册;那么大家肯定和笔者猜到了,他肯定还有一个不注册的功能,熟悉注册中心的小伙伴,可能说:这不就是注册中心的基本更能嘛,确实如此哈。
接下来就带大家看一下入口:不知道大家还记不记得nameServer的启动流程有一个jvm的钩子函数,专业点:叫优雅的关闭,没错broker启动的时候也有这样的代码:
BrokerStartup#createBrokerController()
Runtime.getRuntime().addShutdownHook(new Thread(new Runnable() {
private volatile boolean hasShutdown = false;
private AtomicInteger shutdownTimes = new AtomicInteger(0);
@Override
public void run() {
synchronized (this) {
log.info("Shutdown hook was invoked, {}", this.shutdownTimes.incrementAndGet());
if (!this.hasShutdown) {
this.hasShutdown = true;
long beginTime = System.currentTimeMillis();
// (1)关闭
controller.shutdown();
long consumingTimeTotal = System.currentTimeMillis() - beginTime;
log.info("Shutdown hook over, consuming total time(ms): {}", consumingTimeTotal);
}
}
}
}, "ShutdownHook"));
接下来就不画图了,简单给大家标一下调用方法,因为这个流程跟注册流程差不太多
controller.shutdown(); //BrokerController
-》
this.unregisterBrokerAll(); //BrokerController
-》
unregisterBrokerAll() //BrokerOuterAPI
-》
unregisterBroker() //BrokerOuterAPI
-》
invokeSync() //RemotingClient netty client 封装的code RequestCode.UNREGISTER_BROKER
接下来就算不看源码,大家其实也能猜到最后肯定会调到RouteInfoManager的某个方法去维护上一节提到几个map集合,秉着学习的态度,我们还是简单看一下
承接上面梳理的入口,简单给大家标记一下nameServer是如何处理 broker下线的:
DefaultRequestProcessor
// broker主动下线入口
public RemotingCommand unregisterBroker(ChannelHandlerContext ctx,
RemotingCommand request) throws RemotingCommandException {
final RemotingCommand response = RemotingCommand.createResponseCommand(null);
final UnRegisterBrokerRequestHeader requestHeader =
(UnRegisterBrokerRequestHeader) request.decodeCommandCustomHeader(UnRegisterBrokerRequestHeader.class);
// (1)委托给RouteInfoManager
this.namesrvController.getRouteInfoManager().unregisterBroker(
requestHeader.getClusterName(),
requestHeader.getBrokerAddr(),
requestHeader.getBrokerName(),
requestHeader.getBrokerId());
response.setCode(ResponseCode.SUCCESS);
response.setRemark(null);
return response;
}
DefaultRequestProcessor这个类在前面已经讲过了,在初始化nameServer的netty Server时注册的默认处理器,主要负责基本的rpc code处理
那我们简单看一下,RouteInfoManager是如何处理broker主动下线的:
public void unregisterBroker(
final String clusterName,
final String brokerAddr,
final String brokerName,
final long brokerId) {
try {
try {
this.lock.writeLock().lockInterruptibly();
//(1) 移除心跳包
BrokerLiveInfo brokerLiveInfo = this.brokerLiveTable.remove(brokerAddr);
log.info("unregisterBroker, remove from brokerLiveTable {}, {}",
brokerLiveInfo != null ? "OK" : "Failed",
brokerAddr
);
this.filterServerTable.remove(brokerAddr);
boolean removeBrokerName = false;
BrokerData brokerData = this.brokerAddrTable.get(brokerName);
// (2)从BrokerData移除自己的addr
if (null != brokerData) {
String addr = brokerData.getBrokerAddrs().remove(brokerId);
log.info("unregisterBroker, remove addr from brokerAddrTable {}, {}",
addr != null ? "OK" : "Failed",
brokerAddr
);
if (brokerData.getBrokerAddrs().isEmpty()) {
// 如果主从集群都不在了,移除这个BrokerData集群信息
this.brokerAddrTable.remove(brokerName);
log.info("unregisterBroker, remove name from brokerAddrTable OK, {}",
brokerName
);
removeBrokerName = true;
}
}
if (removeBrokerName) {
// (3) 从集群映射信息中移除broker
Set<String> nameSet = this.clusterAddrTable.get(clusterName);
if (nameSet != null) {
boolean removed = nameSet.remove(brokerName);
log.info("unregisterBroker, remove name from clusterAddrTable {}, {}",
removed ? "OK" : "Failed",
brokerName);
if (nameSet.isEmpty()) {
this.clusterAddrTable.remove(clusterName);
log.info("unregisterBroker, remove cluster from clusterAddrTable {}",
clusterName
);
}
}
// (4)移除 broker相关的topic信息
this.removeTopicByBrokerName(brokerName);
}
} finally {
this.lock.writeLock().unlock();
}
} catch (Exception e) {
log.error("unregisterBroker Exception", e);
}
}
以上代码,大概做的事情:先拿锁,然后把自己的broker信息从nameServer上移除
2.6 被动剔除路由场景(broker被动下线)
在分析nameServer启动流程的时候,我们就知道,nameServer注册了一个定时器,定时扫描自己维护的brokerLiveTable 心跳表,那么我们就跟着源码,看看都做了些什么事情?
代码入口:
// 定时调度任务
this.scheduledExecutorService.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
// 委托给routeInfoManager
NamesrvController.this.routeInfoManager.scanNotActiveBroker();
}
}, 5, 10, TimeUnit.SECONDS);
public void scanNotActiveBroker() {
//获取broker的live信息表
Iterator<Entry<String, BrokerLiveInfo>> it = this.brokerLiveTable.entrySet().iterator();
//1 遍历存储所有存活broker的表
while (it.hasNext()) {
Entry<String, BrokerLiveInfo> next = it.next();
long last = next.getValue().getLastUpdateTimestamp();
//如果收到心跳包的时间距当时时间是否超过120s
//3 broker心跳间隔是否超过120s
if ((last + BROKER_CHANNEL_EXPIRED_TIME) < System.currentTimeMillis()) {
//3.1、关闭长连接
RemotingUtil.closeChannel(next.getValue().getChannel());
//3.2、移除当前broker在心跳表维护信息
it.remove();
log.warn("The broker channel expired, {} {}ms", next.getKey(), BROKER_CHANNEL_EXPIRED_TIME);
//3.3、维护路由表
this.onChannelDestroy(next.getKey(), next.getValue().getChannel());
}
}
}
推测清除broker相关信息的方法肯定在onChannelDestroy(),这个方法代码有点长,就不贴出来了,大概的逻辑类似于:前面说的broker主动下线的unregisterBroker()方法,先拿锁,然后清除心跳超时的broker相关信息;
提示:大家如果想看这块的细节的话,可以debug模拟心跳包过期场景来看
2.7 nameServer服务发现(难点)
笔者自己理解服务发现:其实服务发现主要是指服务调用方,以什么样的方式能够找到服务提供者
nameServer的服务发现功能主要提供给消费者和生产者使用:简单来说,就是消费者和生产者通过nameServer就知道有哪些broker可以提供服务,本质上就是生产者或者消费者怎样才能知道服务提供者broker相关的元信息
接下来,就简单研究一下RocketMQ中的服务发现是怎么实现的?
首先我们先从角色的维度来看一下:
- 生产者
首先我先跟着代码找到了生产者的send api,我直接把入口标出来:
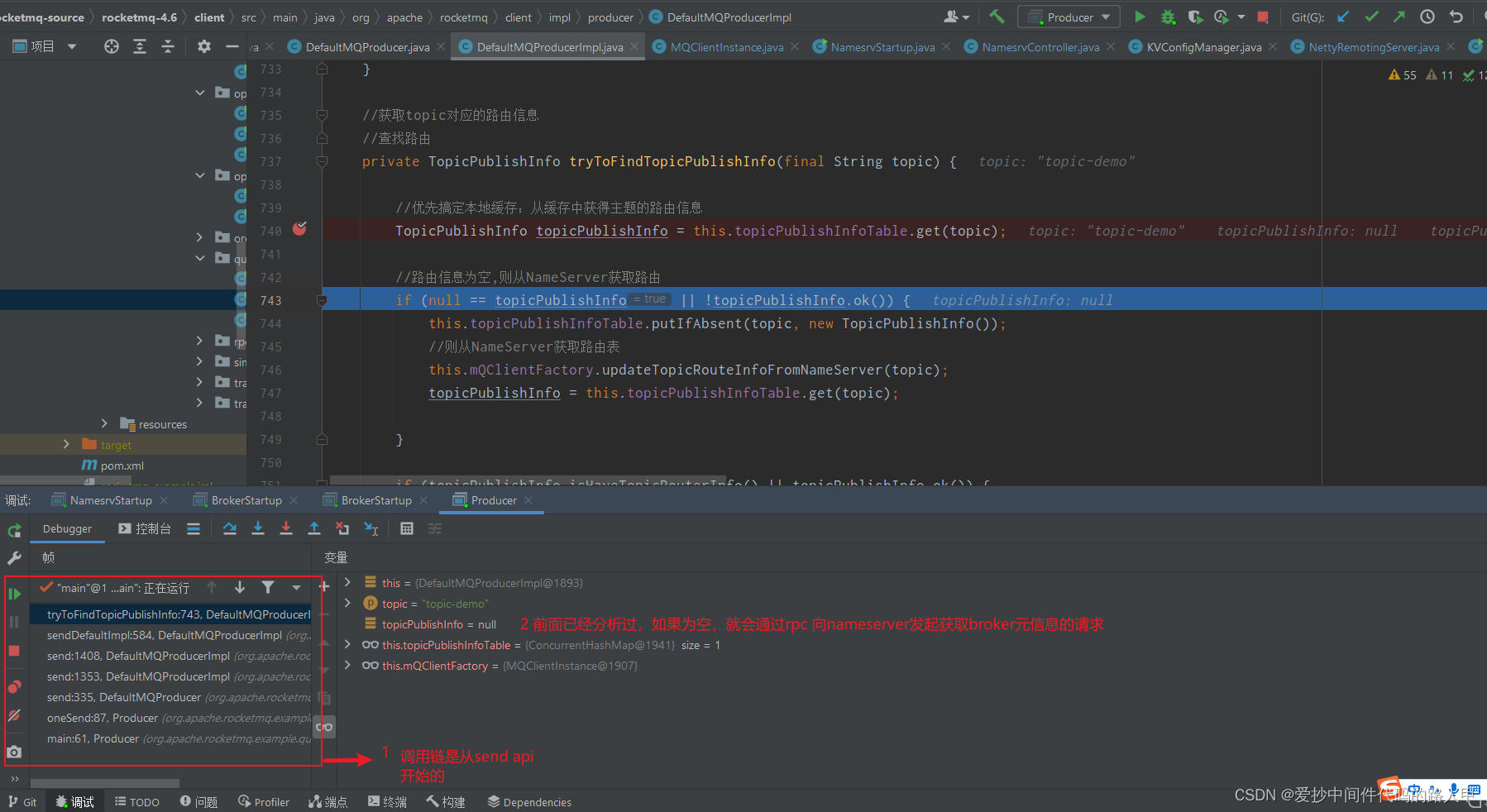
DefaultMQProducerImpl#sendDefaultImpl
//step2 查找路由, 找元数据
TopicPublishInfo topicPublishInfo = this.tryToFindTopicPublishInfo(msg.getTopic());
//获取topic对应的路由信息
//查找路由
private TopicPublishInfo tryToFindTopicPublishInfo(final String topic) {
//优先搞定本地缓存:从缓存中获得主题的路由信息
TopicPublishInfo topicPublishInfo = this.topicPublishInfoTable.get(topic);
//路由信息为空,则从NameServer获取路由
if (null == topicPublishInfo || !topicPublishInfo.ok()) {
this.topicPublishInfoTable.putIfAbsent(topic, new TopicPublishInfo());
//则从NameServer获取路由表
this.mQClientFactory.updateTopicRouteInfoFromNameServer(topic);
topicPublishInfo = this.topicPublishInfoTable.get(topic);
}
if (topicPublishInfo.isHaveTopicRouterInfo() || topicPublishInfo.ok()) {
return topicPublishInfo;
} else {
//如果未找到当前主题的路由信息,则用默认主题继续查找
this.mQClientFactory.updateTopicRouteInfoFromNameServer(topic, true, this.defaultMQProducer);
topicPublishInfo = this.topicPublishInfoTable.get(topic);
return topicPublishInfo;
}
}
最后我们会发现对应的rpc code 为RequestCode.GET_ROUTEINTO_BY_TOPIC
关于rpc处理的细节就不多说了
我们直接看核心方法:updateTopicRouteInfoFromNameServer()
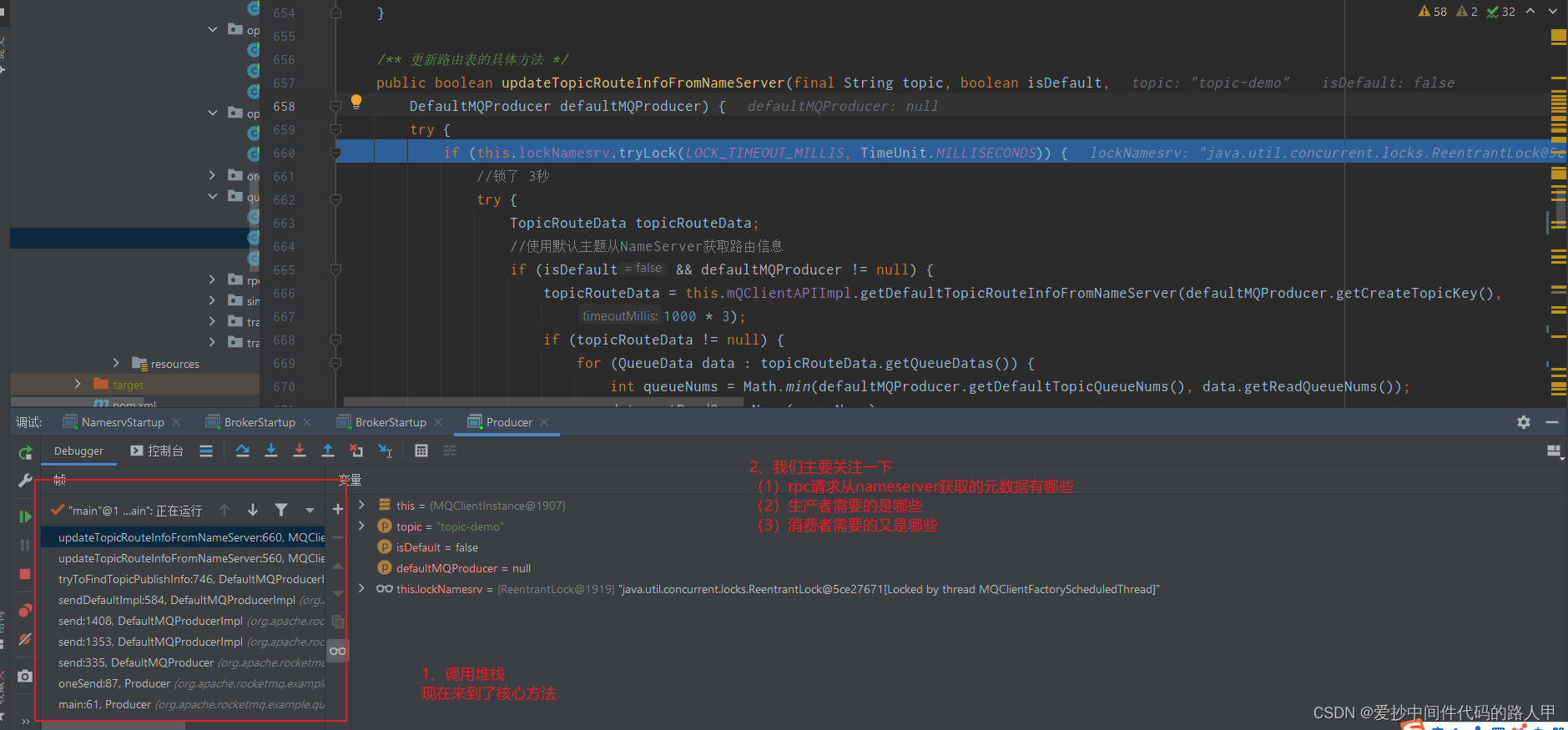
/** 更新路由表的具体方法 */
public boolean updateTopicRouteInfoFromNameServer(final String topic, boolean isDefault,
DefaultMQProducer defaultMQProducer) {
try {
if (this.lockNamesrv.tryLock(LOCK_TIMEOUT_MILLIS, TimeUnit.MILLISECONDS)) {
//锁了 3秒
try {
TopicRouteData topicRouteData;
//使用默认主题从NameServer获取路由信息
if (isDefault && defaultMQProducer != null) {
topicRouteData = this.mQClientAPIImpl.getDefaultTopicRouteInfoFromNameServer(defaultMQProducer.getCreateTopicKey(),
1000 * 3);
if (topicRouteData != null) {
for (QueueData data : topicRouteData.getQueueDatas()) {
int queueNums = Math.min(defaultMQProducer.getDefaultTopicQueueNums(), data.getReadQueueNums());
data.setReadQueueNums(queueNums);
data.setWriteQueueNums(queueNums);
}
}
} else {
//(1)使用指定主题从NameServer获取路由信息 和nameServer通信查询主题对应的路由元信息 这里就是发起rpc请求到 nameServer
topicRouteData = this.mQClientAPIImpl.getTopicRouteInfoFromNameServer(topic, 1000 * 3);
}
if (topicRouteData != null) {
//(2)这里判断路由是否被更改
TopicRouteData old = this.topicRouteTable.get(topic);
boolean changed = topicRouteDataIsChange(old, topicRouteData);
if (!changed) {
changed = this.isNeedUpdateTopicRouteInfo(topic);
} else {
log.info("the topic[{}] route info changed, old[{}] ,new[{}]", topic, old, topicRouteData);
}
if (changed) {
// 2.1 如果被更改了,怎么办
// 1) 复制一份路由信息
TopicRouteData cloneTopicRouteData = topicRouteData.cloneTopicRouteData();
// 2) 更新broker地址
for (BrokerData bd : topicRouteData.getBrokerDatas()) {
this.brokerAddrTable.put(bd.getBrokerName(), bd.getBrokerAddrs());
}
// Update Pub info
{
//3)将topicRouteData路由 转换为 生产路由信息publishInfo
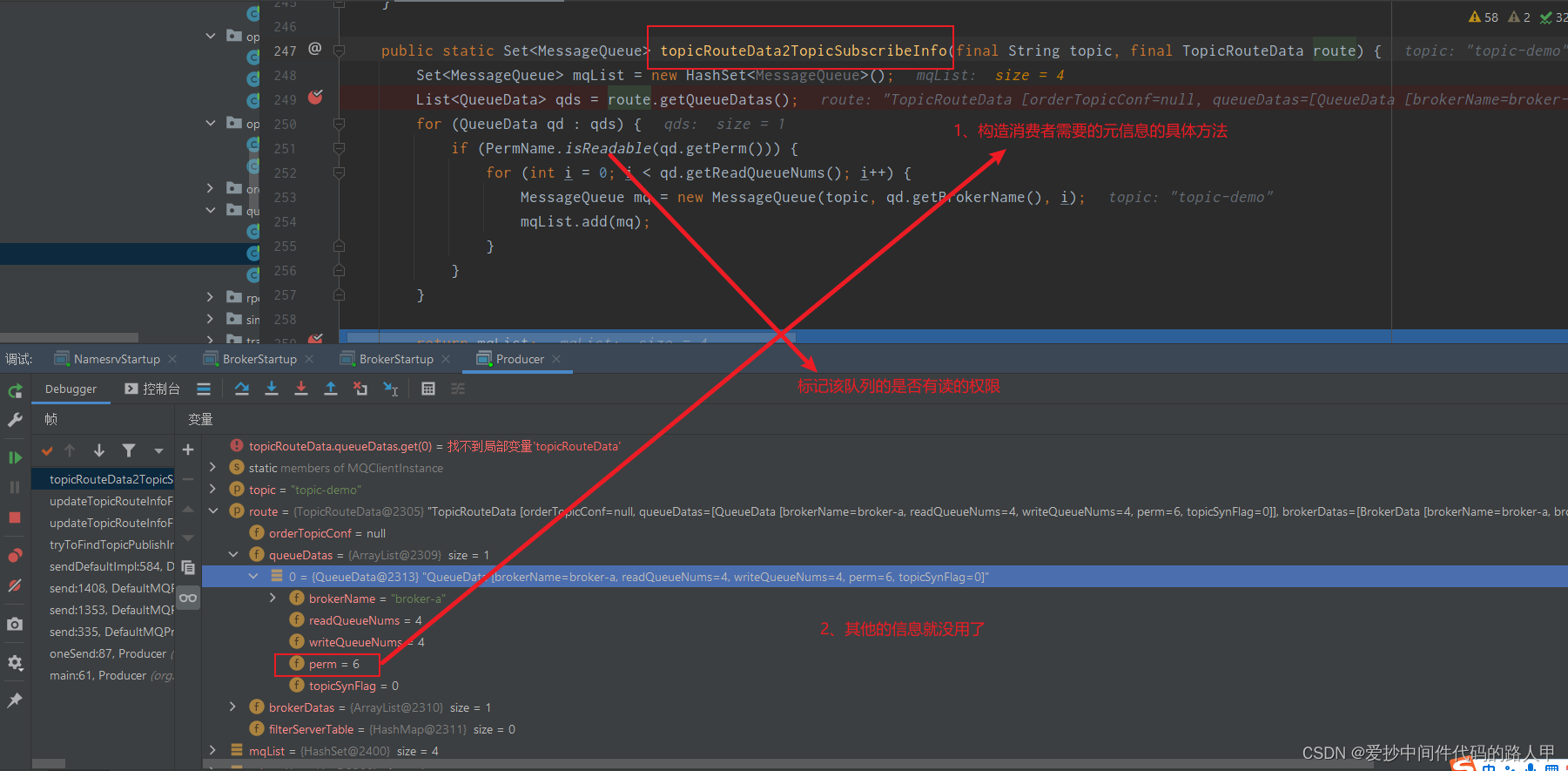
TopicPublishInfo publishInfo = topicRouteData2TopicPublishInfo(topic, topicRouteData);
publishInfo.setHaveTopicRouterInfo(true);
//遍历 生产者
//4)把塞给了每一个生产者的topicPublishInfoTable属性 (可以debug看一下,具体是一些什么信息)
Iterator<Entry<String, MQProducerInner>> it = this.producerTable.entrySet().iterator();
while (it.hasNext()) {
Entry<String, MQProducerInner> entry = it.next();
MQProducerInner impl = entry.getValue();
if (impl != null) {
impl.updateTopicPublishInfo(topic, publishInfo);
}
}
}
// Update sub info
//将topicRouteData路由 转换为 消费路由信息
{
//5) 把topicRouteData 路由信息转换成了MessageQueue
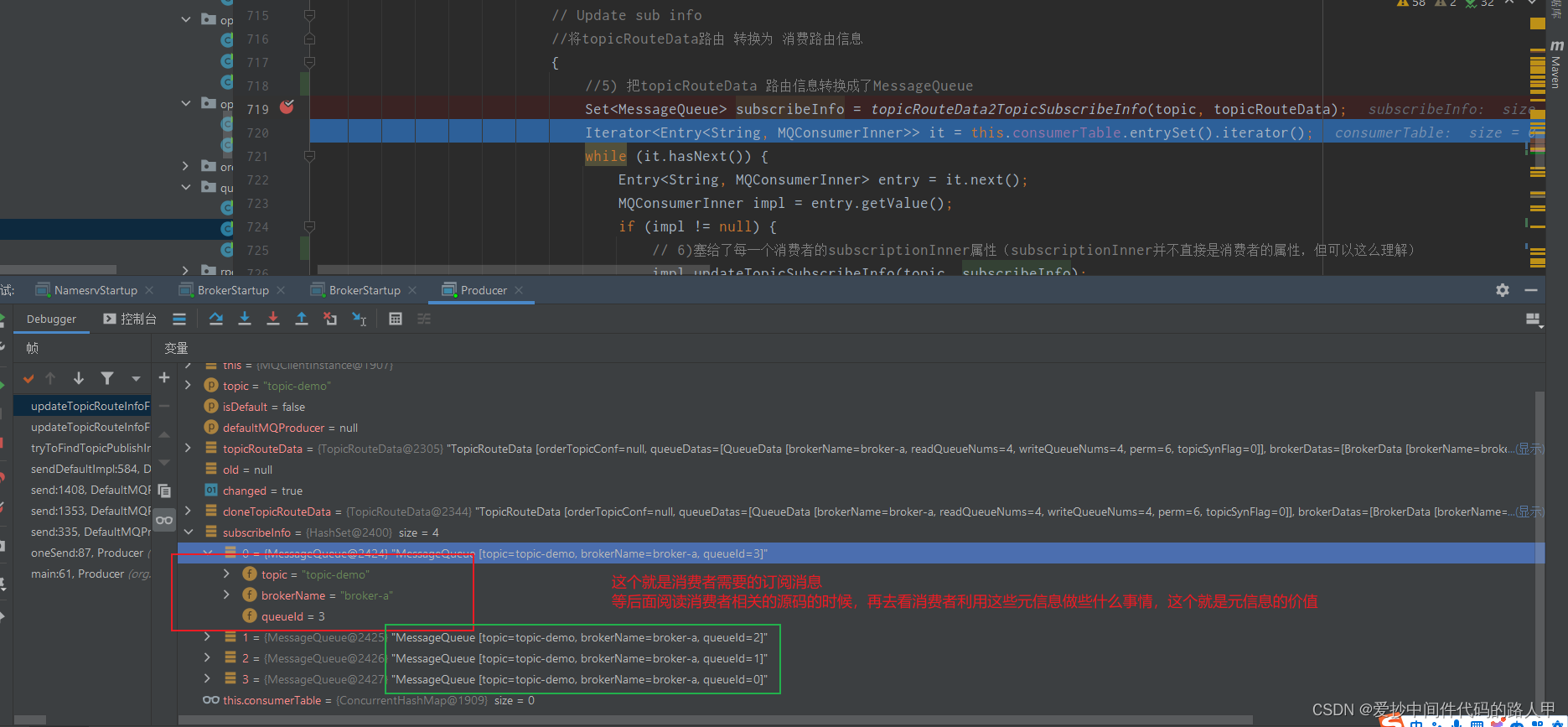
Set<MessageQueue> subscribeInfo = topicRouteData2TopicSubscribeInfo(topic, topicRouteData);
Iterator<Entry<String, MQConsumerInner>> it = this.consumerTable.entrySet().iterator();
while (it.hasNext()) {
Entry<String, MQConsumerInner> entry = it.next();
MQConsumerInner impl = entry.getValue();
if (impl != null) {
// 6)塞给了每一个消费者的subscriptionInner属性(subscriptionInner并不直接是消费者的属性,但可以这么理解)
impl.updateTopicSubscribeInfo(topic, subscribeInfo);
}
}
}
log.info("topicRouteTable.put. Topic = {}, TopicRouteData[{}]", topic, cloneTopicRouteData);
// 7) 更新了 topicRouteTable
this.topicRouteTable.put(topic, cloneTopicRouteData);
return true;
}
} else {
log.warn("updateTopicRouteInfoFromNameServer, getTopicRouteInfoFromNameServer return null, Topic: {}", topic);
}
} catch (MQClientException e) {
if (!topic.startsWith(MixAll.RETRY_GROUP_TOPIC_PREFIX) && !topic.equals(MixAll.AUTO_CREATE_TOPIC_KEY_TOPIC)) {
log.warn("updateTopicRouteInfoFromNameServer Exception", e);
}
} catch (RemotingException e) {
log.error("updateTopicRouteInfoFromNameServer Exception", e);
throw new IllegalStateException(e);
} finally {
this.lockNamesrv.unlock();
}
} else {
log.warn("updateTopicRouteInfoFromNameServer tryLock timeout {}ms", LOCK_TIMEOUT_MILLIS);
}
} catch (InterruptedException e) {
log.warn("updateTopicRouteInfoFromNameServer Exception", e);
}
return false;
}
简单看下来这个核心方法其实主要做了5件事情:
- (1)通过rpc code 为GET_ROUTEINTO_BY_TOPIC 获取指定topic的路由信息
- (2)通过路由信息更新了 broker缓存地址brokerAddrTable
- (3)通过路由信息获取TopicPublishInfo实列,并塞给了每一个生产者
- (4)通过路由信息获取MessageQueue实列集合。并塞给了每一个消费者
- (5)克隆了rpc获取的topic的路由信息,并更新了路由信息缓存table,topicRouteTable
虽然我们把这个方法的核心梳理清楚了,但是其实我们目前并不知道为什么要这么做?
其实要明白为什么这么做,我们就得弄清楚其中几个关键问题?
rpc获取的路由信息到底有些什么信息?
塞给生产者的元信息是什么?
塞给消费者的元信息是什么?
可能其他小伙伴跟笔者有一样的疑问
为什么他们要分开设计?
在分析上面的问题之前,我们先说一下另外一个定时场景的入口:
MQClientInstance#startScheduledTask()
//关键代码
this.scheduledExecutorService.scheduleAtFixedRate(new Runnable() {
//每隔30S尝试更新主题路由信息
@Override
public void run() {
try {
// 前面我们已经分析过的核心方法
MQClientInstance.this.updateTopicRouteInfoFromNameServer();
} catch (Exception e) {
log.error("ScheduledTask updateTopicRouteInfoFromNameServer exception", e);
}
}
}, 10, this.clientConfig.getPollNameServerInterval(), TimeUnit.MILLISECONDS);
说明MQClientInstance实列调用start()方法的时候也会初始化定时任务去定时拉取broker元信息(默认每隔30s,可以设置)
接下来,我们就debug一下,看看消费者、生产者各自维护的元信息都有哪些。
2.7.1 debug 生产者源码 (服务发现相关)
- rpc获取元信息
- 生产者元信息
- 消费者元信息
上面debug的前提如下:
所以经过我们的debug之后,我们大概知道生产者、消费者以及rpc发起请求获取的元信息有哪些内容
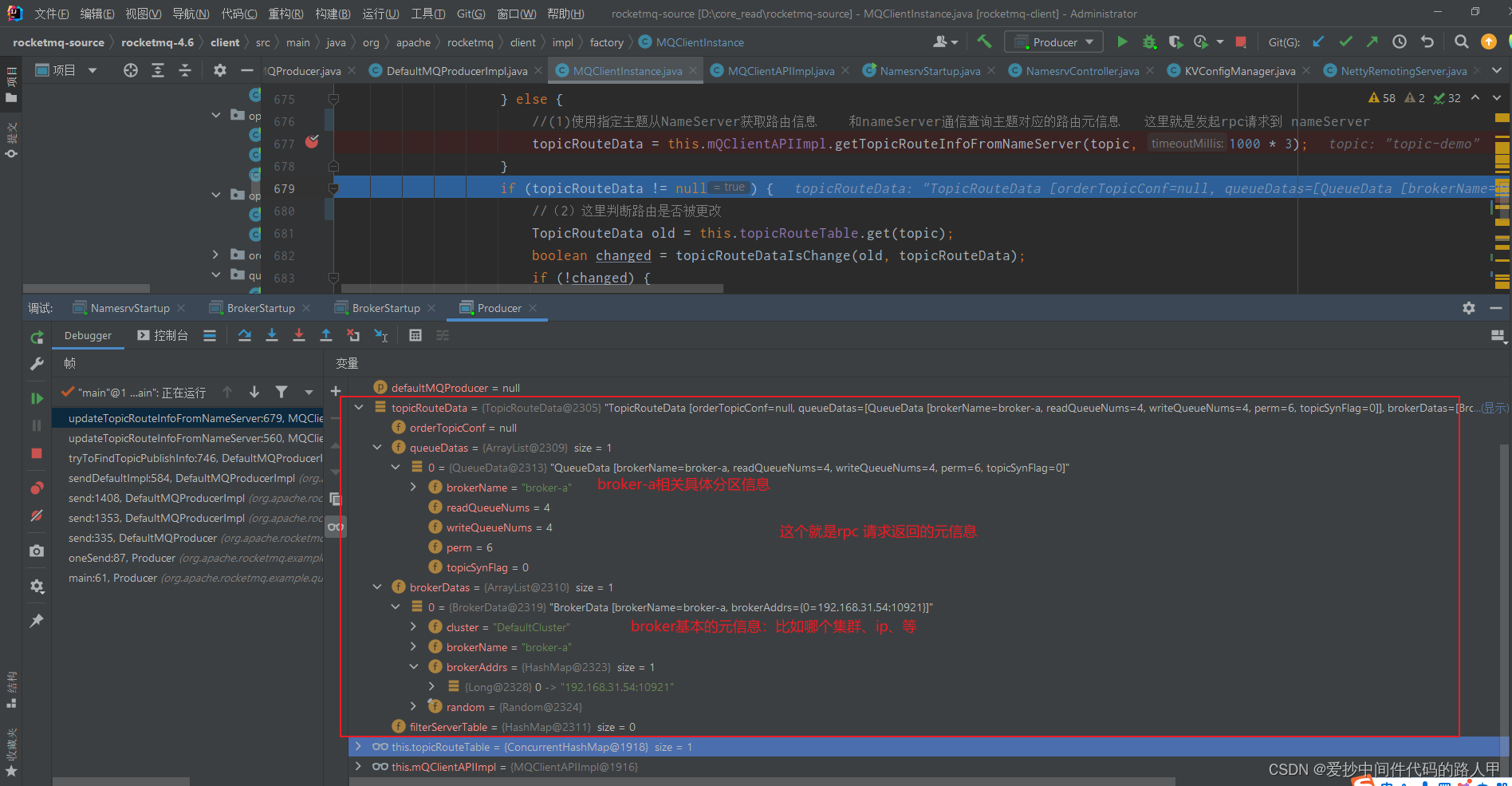
rpc获取的元信息:
TopicRouteData
private String orderTopicConf; // 暂不清楚
//所有的分区信息 元素:topic下某个broker队列相关元数据。
private List<QueueData> queueDatas;
//所有的 broker 集群 元素:代表该topic 某一个集群中的broker元数据;比如id、ip地址等
private List<BrokerData> brokerDatas;
// 暂不清楚
private HashMap<String/* brokerAddr */, List<String>/* Filter Server */> filterServerTable;
QueueData
// broker 组的名称
private String brokerName;
// 读队列数量
private int readQueueNums;
// 写队列数量
private int writeQueueNums;
//队列的读写权限 位运算来判断的
//perm=4 #可读
//perm=2 #可写
private int perm;
//队列的同步标志 同步复制还是异步复制
private int topicSynFlag;
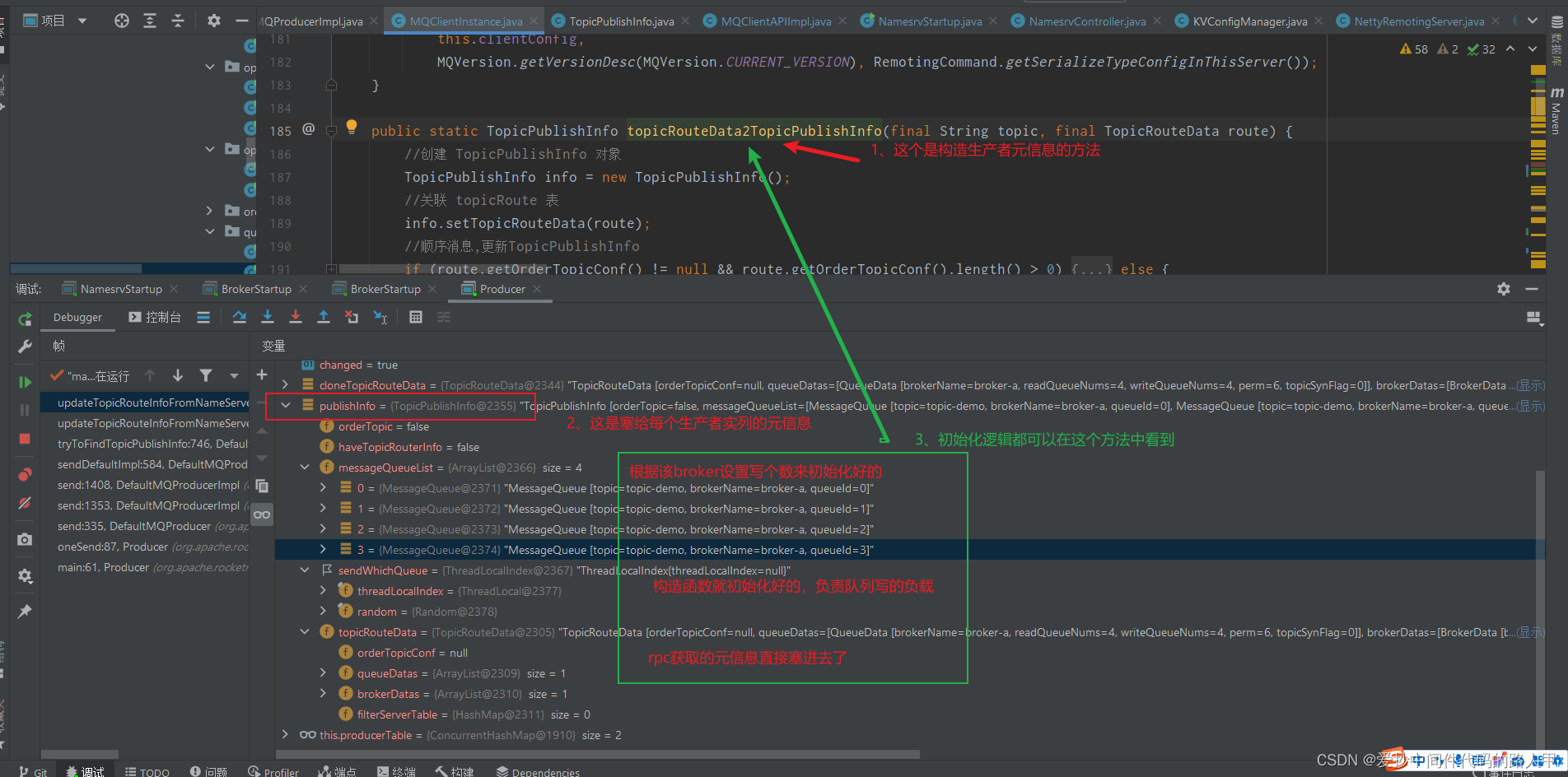
生产者获取的元信息:
TopicPublishInfo
//是否是顺序主题,用于发送顺序消息
private boolean orderTopic = false;
private boolean haveTopicRouterInfo = false;
//一个topic下面的所有的队列 且只要主节点broker的
// 通过rpc元信息当中的QueueData的writeQueueNums属性构造的
private List<MessageQueue> messageQueueList = new ArrayList<MessageQueue>();
//round-robin负载均衡,每选择一次消息队列,该值+1 每选择一次消息队列,该值会自增1,如果超过
//Integer.MAX_VALUE,则重置为0,用于选择消息队列。
private volatile ThreadLocalIndex sendWhichQueue = new ThreadLocalIndex();
//关联Topic路由元信息 前面提到的 rpc获取的元信息
private TopicRouteData topicRouteData;
详细的初始化逻辑可见:MQClientInstance#topicRouteData2TopicPublishInfo
消费者者获取的元信息:
MessageQueue集合:只要可读权限的
//主题
private String topic;
//broker 名称
private String brokerName;
//队列的id,从 0开始的
private int queueId;
看到这里终于没那么糊涂了,总算对消息队列之间的元信息有一些了解了
2.7.2 简单小结一下:
(1)从角色的角度:
服务发现的能力主要为生产者和消费者提供 broker元信息的能力
生产者和消费者对元信息的关注度不同,生产者更关注于broker的写队列设置,而消费者更关注具有可读权限的读队列设置,共同点就是他们都需要topic、queueId、brokerName等基础元信息
(2)从场景来看:
主要有主动和定时2个触发场景
主动场景:生产者调用发送send api的时候
被动场景:生产者和消费者都有通过定时任务来触发,默认30s
(3)从范围来看
主要指定topic下的broker元信息为主
2.8 nameserver选择策略
上面我们已经分析服务发现的核心流程,大概了解到RockeMQ服务发现的机制大致可以分为角色、场景、范围3个维度,接下来我们就跟着源码分析一下,它是如何在nameServer集群中选择了其中一个
代码核心入口:
NettyRemotingClient#invokeSync()
public RemotingCommand invokeSync(String addr, final RemotingCommand request, long timeoutMillis)
throws InterruptedException, RemotingConnectException, RemotingSendRequestException, RemotingTimeoutException {
long beginStartTime = System.currentTimeMillis();
// (1)核心方法获取 nameServer长连接
final Channel channel = this.getAndCreateChannel(addr);//长连接
if (channel != null && channel.isActive()) {
try {
doBeforeRpcHooks(addr, request); // rpc 前置钩子函数
long costTime = System.currentTimeMillis() - beginStartTime;
if (timeoutMillis < costTime) {
throw new RemotingTimeoutException("invokeSync call timeout");
}
//netty发送消息核心
RemotingCommand response = this.invokeSyncImpl(channel, request, timeoutMillis - costTime);
doAfterRpcHooks(RemotingHelper.parseChannelRemoteAddr(channel), request, response);// rpc 后置钩子函数
return response;
} catch (RemotingSendRequestException e) {
log.warn("invokeSync: send request exception, so close the channel[{}]", addr);
this.closeChannel(addr, channel);
throw e;
} catch (RemotingTimeoutException e) {
if (nettyClientConfig.isClientCloseSocketIfTimeout()) {
this.closeChannel(addr, channel);
log.warn("invokeSync: close socket because of timeout, {}ms, {}", timeoutMillis, addr);
}
log.warn("invokeSync: wait response timeout exception, the channel[{}]", addr);
throw e;
}
} else {
this.closeChannel(addr, channel);
throw new RemotingConnectException(addr);
}
}
我们直接进入getAndCreateChannel方法
// 有连接就复用,无就创建(真正创建时会加锁)
private Channel getAndCreateChannel(final String addr) throws RemotingConnectException, InterruptedException {
if (null == addr) {
//核心
return getAndCreateNameserverChannel();
}
// 从长连接池中获取一个长连接(而且还是包装过的长链接)
ChannelWrapper cw = this.channelTables.get(addr);
if (cw != null && cw.isOK()) {
return cw.getChannel();
}
// 根据addr建立一个新的连接
return this.createChannel(addr);
}
继续跟一下
private Channel getAndCreateNameserverChannel() throws RemotingConnectException, InterruptedException {
//优先选择这个NameServer namesrvAddrChoosed是一个原子引用
String addr = this.namesrvAddrChoosed.get();
if (addr != null) {
ChannelWrapper cw = this.channelTables.get(addr);
if (cw != null && cw.isOK()) {
return cw.getChannel();
}
}
// 通过下面的代码,我们知道主要通过随机+轮训的方式获取到address,然后通过netty的Bootstrap的connect()方法建立新的长链接
//核心代码
final List<String> addrList = this.namesrvAddrList.get();
if (this.lockNamesrvChannel.tryLock(LOCK_TIMEOUT_MILLIS, TimeUnit.MILLISECONDS)) {
try {
addr = this.namesrvAddrChoosed.get();
if (addr != null) {
ChannelWrapper cw = this.channelTables.get(addr);
if (cw != null && cw.isOK()) {
return cw.getChannel();
}
}
if (addrList != null && !addrList.isEmpty()) {
for (int i = 0; i < addrList.size(); i++) {
//除非与这个 namesrvAddrChoosed 节点通信出现异常的情况下,才会选择其他节点 // namesrvIndex初始化的时候采用随机
int index = this.namesrvIndex.incrementAndGet();
index = Math.abs(index);
index = index % addrList.size();
String newAddr = addrList.get(index);
this.namesrvAddrChoosed.set(newAddr);
log.info("new name server is chosen. OLD: {} , NEW: {}. namesrvIndex = {}", addr, newAddr, namesrvIndex);
Channel channelNew = this.createChannel(newAddr);
if (channelNew != null) {
return channelNew;
}
}
throw new RemotingConnectException(addrList.toString());
}
} finally {
this.lockNamesrvChannel.unlock();
}
} else {
log.warn("getAndCreateNameserverChannel: try to lock name server, but timeout, {}ms", LOCK_TIMEOUT_MILLIS);
}
return null;
}
通过上面的核心代码,我们知道RockertMQ在做nameServer选择的时候,主要通过随机+轮训的方式获取到address,然后通过netty的Bootstrap的connect()方法建立新的长链接
虽然采用随机+轮训,前提也是之前的长链接不可用或者之前的nameserver挂掉了,不然会继续复用上一次的长链接
2.9 谈谈对阅读nameServer的6大收获
- 基本了解nameServer和broker、生产者、消费者之间的交互流程,知道rpc相关的业务都有唯一的rpc code,且实现逻辑在默认的处理器DefaultProcesser类里可以看到
- 基本了解nameServer的启动流程以及,以及broker元信息维护
- 基本了解nameServer的提供的服务发现功能:2个场景,针对特定topic定时 +主动
- 基本了解nameServer的提供的服务注册功能:2个场景,针对特定topic定时 +主动
- 基本了解nameServer关于并发工具的实践应用:读写锁应用场景、countDownLatch + 异步优化并发rpc请求
- 基本了解nameServer 对于netty的实践应用:比如通过map来实现不同rpc业务处理器和对应线程池的绑定和业务隔离
通过源码学习,笔者终于对nameServer有一个比较全面的了解了,而且发现nameServer之间是互不通信的,并且broker元信息是通过心跳包维护的,所以在某些时刻nameServer集群中的某些节点的broker元数据可能是不同的,但是最终都会一致,所以nameServer并不是数据强一致性的,而是弱一致性,但是nameServer是支持高可用的,同时也在nameServer这块的源码了解到基础并发工具的运用,比如读写锁应用场景、countDownLatch + 异步优化并发rpc请求、jvm钩子函数优化关闭,其中也了解到一些netty相关的应用实践:比如通过map来实现不同rpc业务处理器和对应线程池的绑定














 658
658











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









