






1. 介绍
我们常常说阶梯要慢慢下,但是我们的计算机不这样认为,因为他们是人类智慧的结晶,我们已经知道了最优解,在某些方面,所以我们要找到最速梯度,这样梯度下降就被广泛运用。
梯度下降(gradient descent)在机器学习中应用十分的广泛,不论是在线性回归还是Logistic回归中,它的主要目的是通过迭代找到目标函数的最小值,或者收敛到最小值。本文将从一个下山的场景开始,先提出梯度下降算法的基本思想,进而从数学上解释梯度下降算法的原理,解释为什么要用梯度,最后实现一个简单的梯度下降算法的实例!
2.梯度下降算法
2.1 真实情景
梯度下降法的基本思想可以类比为一个下山的过程。
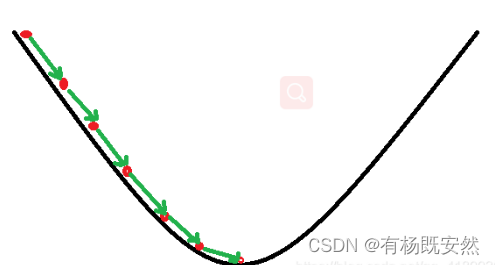
描述的是我们在下山的时候,怎么样才可以以最快的路径到谷底,那么我们可以抽象的把这个山谷看作一个函数,那么找到到谷底的过程,就是我们梯度下降算法的作用,注意这里找的是最优路线,其实我们要计算的就是每两个或多个点之间的斜率,也就是现在人工智能所谓的梯度,这算法在人工智能领域运用非常广泛,当然毋庸置疑这些起源都是数学。
2.2 梯度下降 ---- 数学
梯度下降算法是一种优化算法,用于求解目标函数的最小值。其基本思想是通过迭代更新参数来逐步逼近最优解。
假设我们有一个目标函数f(x),其中x是参数向量,我们需要找到一组参数x使得f(x)最小化。在梯度下降算法中,我们首先需要计算目标函数关于参数向量的梯度,即导数向量。然后根据梯度的方向和大小,更新参数向量,直到满足停止条件为止。
具体来说,梯度下降算法的公式推导过程如下:

初始化参数向量x和学习率α;
计算目标函数关于参数向量的梯度g(x)=(h0(x)-y)*x(i);
根据梯度的方向和大小,更新参数向量x = x - α * g(x);
重复步骤2和3,直到满足停止条件为止。
其中,学习率α控制着参数更新的速度,过大可能导致振荡不收敛,过小可能导致收敛速度过慢。在实际使用中,可以通过调整学习率来平衡收敛速度和稳定性。
2.3 基于python实现梯度下降算法
关于 y = w*x 的 w 的最优解完整代码:
import matplotlib.pyplot as plt
x_data = [1.0, 2.0, 3.0, 4.0, 5.0]
y_data = [2.0, 4.0, 6.0, 8.0, 10.0]
w = 1.0
def forward(x):
return x * w
def loss(x, y):
y_pred = forward(x)
return (y_pred - y) ** 2
def gradient(x, y):
return 2 * x * (x * w - y)
epoch_list = []
loss_list = []
print('predict(before training)', 4, forward(4))
for epoch in range(100):
for x, y in zip(x_data, y_data):
grad = gradient(x, y)
w = w - 0.01 * grad
print('\tgrad:', x, y, grad)
l = loss(x, y)
print('progress:', epoch, 'w=', w, 'loss=', l)
epoch_list.append(epoch)
loss_list.append(l)
print('predict(after training)', 4, forward(4))
plt.plot(epoch_list, loss_list)
plt.ylabel('loss')
plt.xlabel('epoch')
plt.show()
2.3.1 给定x,y值和初始化w:
x_data = [1.0, 2.0, 3.0, 4.0, 5.0]
y_data = [2.0, 4.0, 6.0, 8.0, 10.0]
w = 1.0
2.3.2 定义三个函数forwar(),loss(),gradient():
forwar()
返回的是xw的结果,也就是对整个函数y = xw 求解。
loss()
传入x,y 并返回y_pred-yd的平方,注意y_pred是由我们自定义的数据算出来的,y是给定的y_data的数据,loss就是求他们之间的平方差。
gradient()
它接受两个参数x和y。函数的主要目的是计算梯度值。在数学中,梯度是一个向量,表示一个标量场在某一点处的方向导数沿着该方向取得最大值。在这个例子中,梯度计算公式为:2 * x * (x * w - y)。其中,w是一个未在代码中定义的变量,可能是全局变量或者在其他地方定义的。这个函数可以用于计算某个函数在某个点的梯度值。
def forward(x):
return x * w
def loss(x, y):
y_pred = forward(x)
return (y_pred - y) ** 2
def gradient(x, y):
return 2 * x * (x * w - y)
以下这段代码是一个使用梯度下降法训练神经网络的示例。首先,它创建了两个空列表epoch_list和loss_list,用于存储每个epoch的损失值。然后,它打印出在训练开始之前对输入4进行预测的结果。
接下来,代码进入一个100次迭代的训练循环。在每次迭代中,它会遍历x_data和y_data中的所有数据点,并计算损失函数关于权重的梯度。然后,它更新权重w,使其朝着减小损失的方向移动。在每次迭代中,它还打印出当前的数据点、梯度和损失值。
在每个epoch结束时,代码将当前的epoch数和损失值添加到epoch_list和loss_list中,并打印出进度信息。最后,在训练结束后,它再次打印出对输入4进行预测的结果,并绘制了一个损失值随epoch变化的折线图。
epoch_list = []
loss_list = []
print('predict(before training)', 4, forward(4))
for epoch in range(100):
for x, y in zip(x_data, y_data):
grad = gradient(x, y)
w = w - 0.01 * grad
print('\tgrad:', x, y, grad)
l = loss(x, y)
print('progress:', epoch, 'w=', w, 'loss=', l)
epoch_list.append(epoch)
loss_list.append(l)
print('predict(after training)', 4, forward(4))
plt.plot(epoch_list, loss_list)
plt.ylabel('loss')
plt.xlabel('epoch')
plt.show()
第一次计算结果:

经过100次的求解得到w=2是这个方程的最优解:
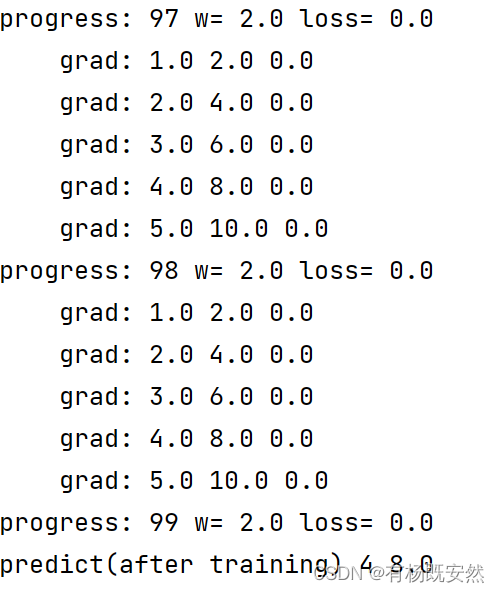
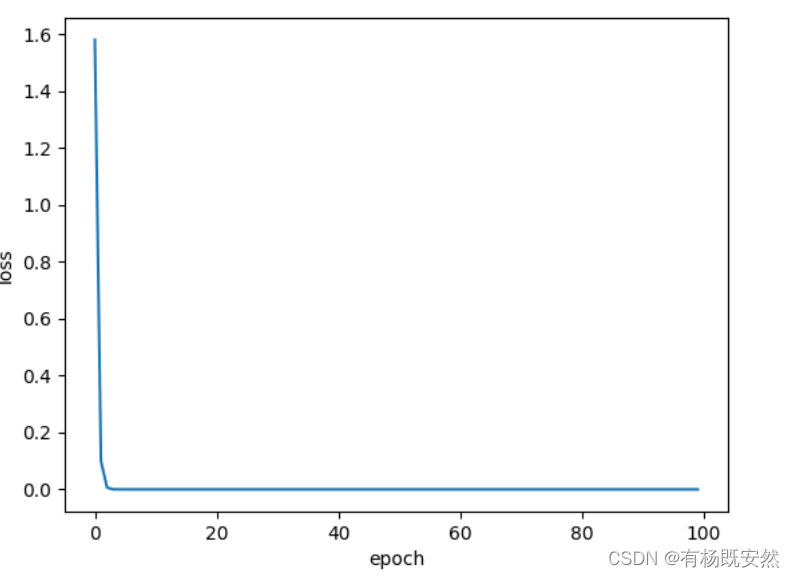
由上图可以知道大概在3-4次的时候loss的值已经是0了,所有后面的计算是浪费资源,当然这是方程简单的情况,有很多复杂的方程需要考虑的东西更多,关于什么时间复杂度等一系列问题。















 572
572











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









