







个人主页:mzwang.top
论文题目
Large-scale visual search with binary distributed graph at Alibaba
相关信息
作者与单位
Kang Zhao, Pan Pan, Yun Zheng, Yanhao Zhang, Changxu Wang, Yingya Zhang, Yinghui Xu, Rong Jin
Machine Intelligence Technology Lab, Alibaba Group
{zhaokang.zk,panpan.pp,zhengyun.zy,yanhao.zyh,changxu.wcx,yingya.zyy,renji.xyh,jinrong.jr}@alibaba-inc.com
出处与时间
CIKM, 2019(CCF B类会议)
作者拟解决的主要问题
近邻图算法由于其在线搜索性能的优势在ANNS上已经得到了广泛的应用。但是,离线近邻图构建的效率和可扩展性却没有被现存研究很好的解决。对几十亿数据在数小时内构建一个亿级近邻图是非常必要的,然而现存方法几乎不能实现这一任务。
Alibaba的拍立淘的核心技术是基于深度学习和大规模ANNS算法的可视化搜索。不幸的是,现存基于近邻图的ANNS方法由于以下两个原因导致其很难应用于拍立淘。
- 图构建所要求的内存一般要比图索引尺寸更大,这给预分配内存带来困难;
- 构建一个大规模,高质量近邻图非常耗时。
论文主要研究内容
- 分布式构建图索引(MapReduce)
- 二进制码对原始向量处理
- 更快地构建索引和执行搜索
论文使用的方法
本文提出Binary Distributed Graph将图结构与二进制编码结合同时加速离线构建和在线搜索过程。本文方法通过召回和重排更多的二进制候选能够达到与真值特征(原始向量)相当的性能。而且,图构建过程通过完全分布式的实施,这显著加速离线构建过程。
- 产生二进制码
将原始向量映射到汉明空间,使用LPH学习压缩d维二进制码。从开始就将查询和数据集向量转变为二进制码(包括索引构建和在线搜索)。
- 一遍分布式分治构图
对二进制码表示的原始数据进行k-means聚类,从而达到对数据集划分的目的。如图1所示,分配某一个点到它所属的划分部分时,主要有三种方案,(a)分配该点至其最近类;(b)分配该点至其最近的t个类(t>1);(c)对数据集进行多重随机划分。本文采用的是第(b)个方案。方案(a)构建的图不保证连通性,方案(c)构建过程比较费时,存在冗余计算。
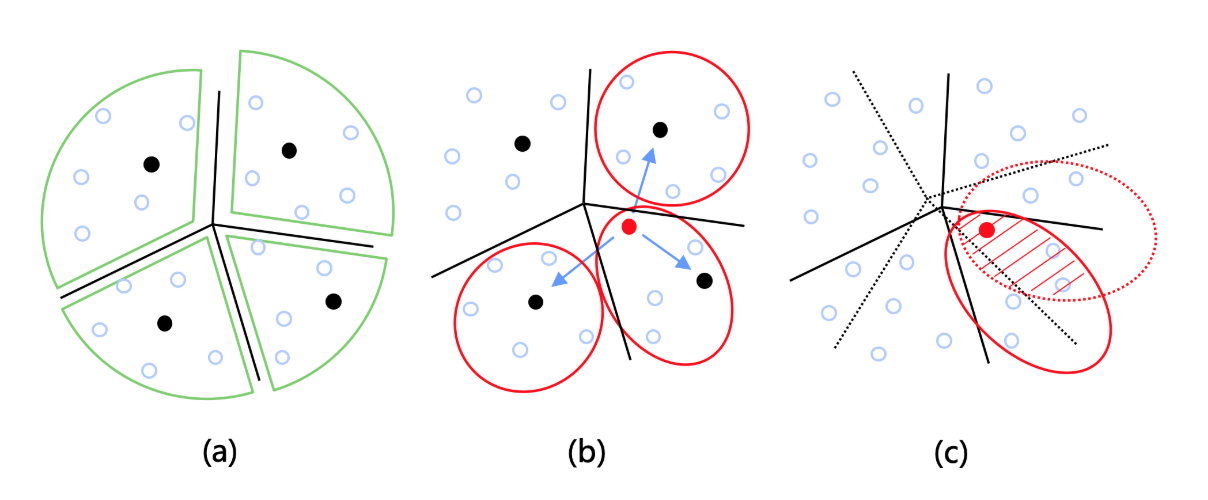
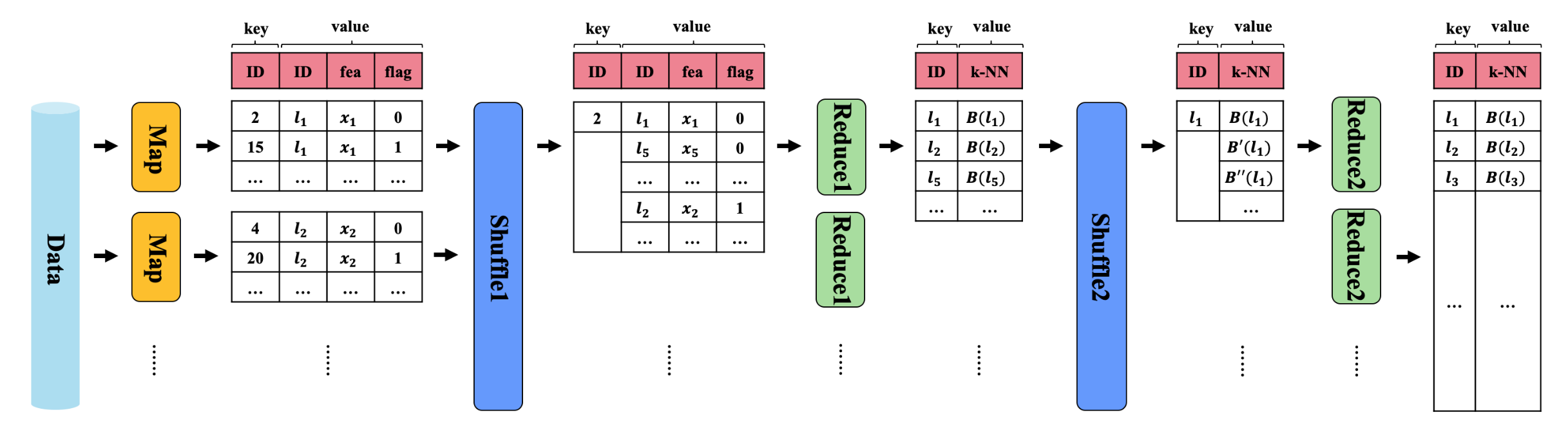
图2展示了分治构图的总过程。编码后的原始数据作为Map的输入,其输出为每一个对象
l
i
l_i
li所属的类,在图2中对应key,value中的flag为0对应的key是该对象所属的最近类,flag为1时为次近的几个类。经过Shuffle1之后,将同一个类包含的对象集中在一起,包括flag为0和flag为1的对象。以上即完成了划分的过程。接下来Reduce1是为每一个类中的每一个对象在该类中选择最近邻居的过程,文中描述仅选择flag=0的邻居。经过Shuffle2归并同一对象的不同邻居组,为什么会生成
l
i
l_i
li的不同邻居组呢?因为同一对象会被划分到不止一个类中,而在每个类中都要选择它的最近邻居组。最后,在Reduce2中排序获取最终近邻结果。
- 分布式邻居扩展
该过程的框架图请看论文原文Figure 7。经过一遍分治已经得到一个初始化的图,邻域扩展的过程是对该初始化图精细化的过程。对图中每个点,通过Map将它的邻居作为key,该点作为value,这很容易分布式执行。然后,经过Shuffle1将每个点的邻居(占一行)以及反向邻居(每个反向邻居对应一行,对于每一行,key为该点id,value为反向邻居)归并到一起。接着,经过Reduce1将上述反向邻居行的value作为key,现value为原key的邻居。Shuffle2将所有key相同的归并到一块,经Reduce2对同一key的所有邻居排序,得到一遍邻居扩展的结果。注意,在Map或Reduce阶段,为了实现分布式并行执行,每一操作仅对某一点及其邻居表执行,不能涉及其它邻居表。另外,我认为论文中的Figure 7是有问题的。
- 搜索过程
随机取一些点作为入口点。执行贪婪搜索,使用汉明距离评估相似性(二进制哈希码)。召回非常多的点,最后用欧式距离对召回的点重排序(原始数据),作为最终返回的结果。
论文的创新点
- 完全分布式的构图过程
- 哈希码与图结构的联合
论文的结论
现存图方法很少考虑近邻图离线构建效率问题,导致现存方法很难实际应用。本文提出的BDG联合哈希二进制码与图结构并在分布式系统中构建图,提升了近邻图的构建效率。在10亿级数据上构图不超过5小时,而且与当前最优的方法HNSW有相当的在线搜索性能。BDG已在淘宝拍立淘上得到实际应用。
我的观点或思考
- NN-Descent的一个显著的特点是,在近邻图构建时他并不依赖全局索引,只需要局部搜索即可。但是,NN-Descent需要多次迭代,而且,每一次迭代他需要在不同节点间交换成对数据,这不利于分布式实施。
- NSW对数据的插入顺序比较敏感,而HNSW通过概率分层缓解了这一现象。
- 索引构建的效率越来越成为一个重要因素。
- 图结构与压缩编码方法联合逐渐成为近邻图算法各种优化部署的标配。
- 分布式索引构建和搜索可能更有效的解决现存的一些问题。















 831
831











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









