






目录
一、概述
memory barrier 产生的原因要深入理解体系结构,这篇文字有点敷于表面,记录一个分析的思路
二、指令乱序
2.1 为什么要乱序
在按照program order执行命令的cpu上,考虑到程序之间有的指令存在指令相关,这种指令的相关性会造成性能的下降,考虑下面的指令:
1. load r1, (r0) // r1 = [r0]
2. add r1, r2 // r2 = r1 + r2
3. store r3, (r4) // [r4] = r3在顺序执行条件下,假如指令1的load指令产生了cache miss,由于指令1,2是相关的,2需要等待1的结果(r1),这会造成流水线stall,尽管3指令和1,2都不相关,但是由于顺序执行的要求,这里也无法得到执行。
考虑这样一种方式,我们通过指令调度,将3在安排在1后执行,这样等到2开始执行时,1中r1的结果已经可用了,这样就可以掩盖流水线的stall,提高指令执行效率。这样的执行行为其实打破了顺序执行的规则,事实上指令进行了乱序执行。
所以,乱序执行可以提高性能。
2.2 如何实现乱序
可以通过两个方法实现指令乱序:
- 利用编译器实现(compile time),称为指令的静态调度
- 利用硬件(runtime),称为动态调度
一般的,编译器乱序是可以观察到的——通过对比不同优化等级的汇编指令可以看出。而硬件的乱序执行我们无法直观的看到,这些可以通过了解一些微架构的实现理解其原理。
2.3 乱序执行带来的副作用
尽管乱序执行可以带来性能上的提升,但在某些情况下,尤其是多核下,会造成一些问题,考虑如下代码:
void foo(void)
{
a = 1;
b = 1;
}
void bar(void)
{
while (b == 0) continue;
assert(a == 1);
}假如foo在cpu0执行,bar在cpu1执行,在cpu0看来a = 1, b = 1指令是无关的,因此foo在执行时有可能先执行b=1,再执行a=1。然而我们看到在bar中,如果前面所说的顺序执行,assert会失败。失败的原因在于a,b没有按照program order执行,编译器和cpu没有看到bar中a,b中逻辑关系的能力,这时候就需要程序员通过显式的指定a,b执行的顺序,即memory barrier。
三、memory barrier
本节主要针对的是内存操作——load/store乱序说明,两个操作数都是寄存器的指令不在考虑范围内。
3.1 memory consistency model
简称memory model,在我们只考虑load,store两种执行的情况下,乱序的情况只有以下四种:
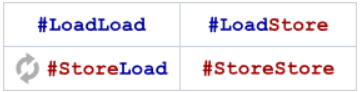
不同体系结构通过允许上述四种乱序中的某几种来构成自己的memory model,如在x86中,只允许store load乱序,不允许其他形式的乱序(实际上x86在一些情况下也存在store-store order Does it make any sense to use the LFENCE instruction on x86/x86_64 processors?,lfence没有作用,sfence代表store-store barrier,mfence代表full barrier,sfence+lfence也可以是full barrier)。
3.2 memory barrier
我们可以通过memory barrier指示编译器或者cpu不对指令进行乱序,如两条不相关的load store指令:
load
load-store-barrier
store
由于每种cpu的memory model不同,它提供的memory barrier原句也不同,可能一条指令可以是避免上述一种或者几种乱序的组合。如读屏障一般是load-load barrier 和load-store barrier组合:
- read barriers load-load barrier
- write barriers store-store barrier
- acquire barriers load-load barrier + load-store barrier
- release barriers load-store barrier + store-store barrier
- full barrier all 4,so acquire + release != full
3.3 锁
我们一般使用锁的方式为:
lock
critical section
unlock
那么我们考虑,在乱序执行的条件下,锁是如何避免critical section的语句没有提前到lock之前,也没有滞后unlock执行的呢?
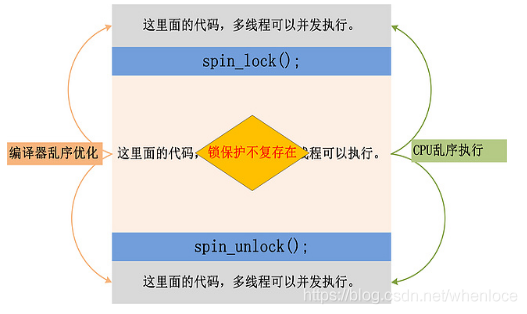
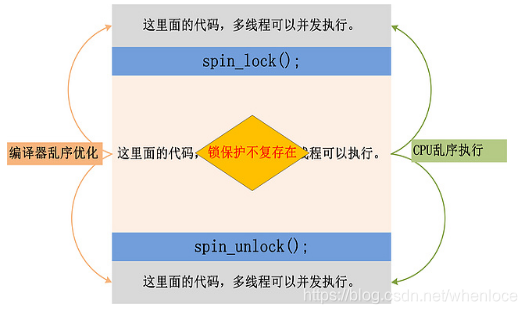
事实上,在memory model种有Acquire和Release语义的概念。
Acquire是说,在Acquire之后的读写指令都不能和Acquire之前的read指令乱序
Release是说,在Release之后的write指令都不能和Release之前的读写指令乱序
这样,如果一个锁的实现保证lock aquire 和unlock release的,那么我们上面提到的乱序执行就不会发生:

那么如何保证呢?使用memory barrier,我们看下图:
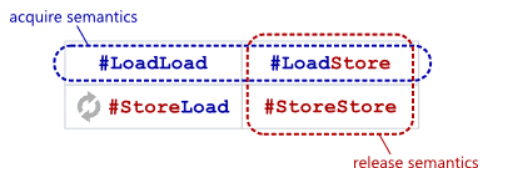
即使用load-load barrier和load-store barrier保证Lock Acquire,使用load-store barrier和store-store barrier 保证Unlock Release。
可以看到没有用到store-load barrier,而x86刚好只有store load乱序,因此cpu天然为我们保证了Lock Acquire和Unlock Release。
参考
【1】Is Parallel Programming Hard, And, If So, What Can You Do About It?
【2】Memory Barriers Are Like Source Control Operations
【3】Acquire and Release Semantics














 1342
1342











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









