








Sparse-Interest Network for Sequential Recommendation
论文地址:https://arxiv.org/pdf/2102.09267.pdf
这里有篇博客梳理的比较清楚:推荐系统论文阅读(五十二)-序列推荐中的稀疏兴趣网络
背景
序列召回中,单个统一的用户向量容易受到用户最近频繁互动的序列影响。从实践中看,用户兴趣概念是多样的,如果在用户历史上兴趣概念相似的item没有出现在用户近期比较频繁的序列中,那很有可能推荐的下一个item不会是这个item。其他多兴趣的方法采用聚类的方式来划分用户兴趣,但是通过聚类获得的用户兴趣一般较少,无法匹配实际中大量的兴趣类别。
解决方案
通过预先构建大量的正交兴趣概念池,基于用户行为从兴趣概念池里面激活K个兴趣,通过预测用户下一个意图来聚合多个用户兴趣向量,聚合期间不使用target item信息,保证离线train和在线infer的一致性。
方案详情
SINE结构如下:
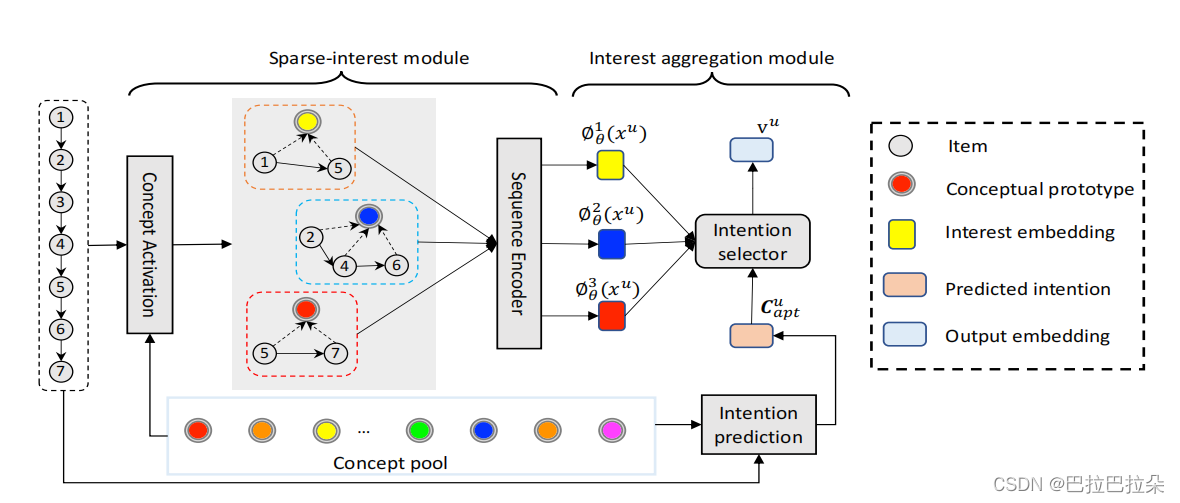
step 1:先通过self-attention的方式计算各个序列的注意力权重
a
\mathbf a
a,计算综合的用户向量
z
u
\mathbf z_u
zu。
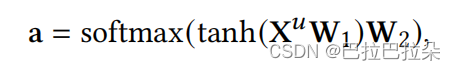
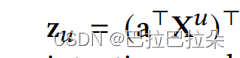
step2:综合的用户向量
z
u
∈
R
D
×
1
\mathbf z_u \in R^{D \times 1}
zu∈RD×1和概率池
C
∈
R
L
×
D
\mathbf C \in R^{L \times D}
C∈RL×D点积相乘,根据用户向量和兴趣概念池的相关性取topK,然后对相关性进行Sigmoid激活后再乘以topK的概念池,得到被激活的K个用户兴趣向量。
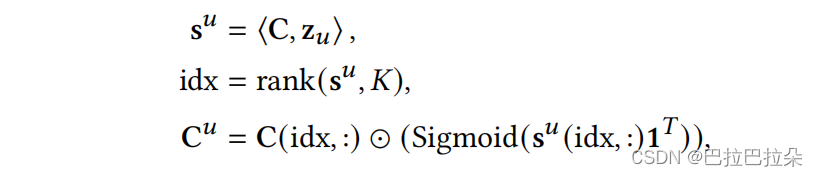
step3:对激活的用户兴趣向量
C
u
\mathbf C^u
Cu进行分配。首先计算序列上第t个位置和第k个激活的兴趣向量之间的相关性
P
k
∣
t
P_{k|t}
Pk∣t,然后计算位置 𝑡 处的item对于预测用户的下一个意图的重要性
P
t
∣
k
P_{t|k}
Pt∣k。
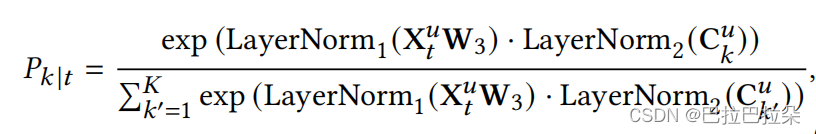
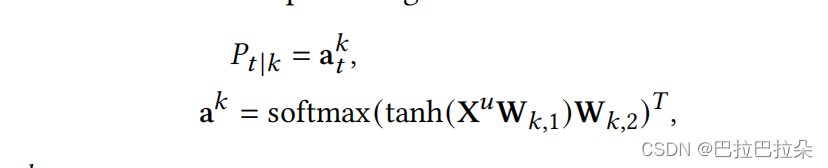
step4:根据step3计算的数据,加权聚合输出用户的K个兴趣向量
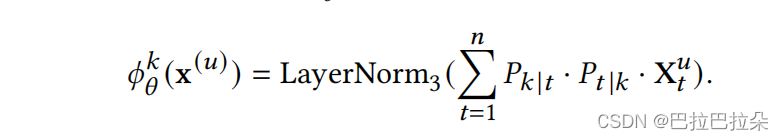
step5:利用产出的多个用户兴趣向量聚合成最终的用户向量
怎么利用这些用户兴趣向量在线上infer,MIND里面使用target item和注意力机制来选择用户兴趣向量。但是这个缺点是线上infer的时候是没有target item信息的,这种线上infer线下train的不一致性会降低模型的性能。
SINE的解法:
提出一种新的兴趣聚合方法,文章认为预测当前的用户意图比找到完美的target item的label要容易,那怎么预估当前的用户意图呢,前面计算的第t个序列在激活的第K个兴趣向量上面的相关性
P
k
∣
t
P_{k|t}
Pk∣t扩展成矩阵
P
∈
R
n
×
K
\mathbf P \in R^{n \times K}
P∈Rn×K,其中n是序列行为数量,K是兴趣数量。那么用户序列Embedding矩阵
X
u
\mathbf { X^u}
Xu可以从用户意图视角重新表述成
X
^
u
∈
R
n
×
D
\mathbf {\hat X^u} \in R^{n \times D}
X^u∈Rn×D,那么根据新的用户序列矩阵,使用注意力机制,用户下一个意向的item向量可以表示
C
a
p
t
u
∈
R
D
\mathbf C^u_{apt} \in R^D
Captu∈RD
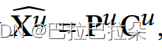
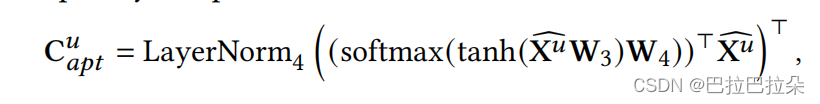
W
3
∈
R
D
×
D
\mathbf W_3 \in R^{D \times D}
W3∈RD×D,
W
4
∈
R
D
×
D
\mathbf W_4 \in R^{D \times D}
W4∈RD×D
然后计算用户下一个意图向量
C
a
p
t
u
\mathbf C^u_{apt}
Captu和多个兴趣向量的相关性,并进行归一化,得到每个兴趣向量的融合权重
e
k
u
e_k^u
eku
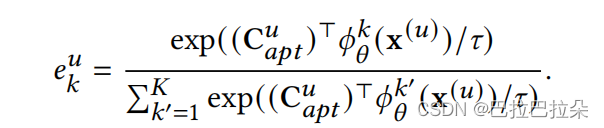
最终的用户兴趣向量就是根据权重参数对多个兴趣向量进行融合
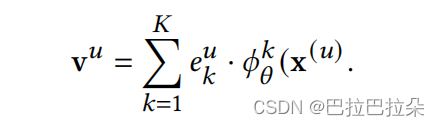
step6:主loss实际中采用了负采样。
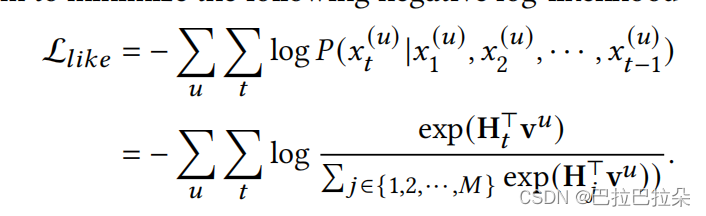
为了保证兴趣之间的正交性,需要对兴趣概念池矩阵进行约束,
C
ˉ
\bar C
Cˉ是矩阵
C
\mathbf C
C的均值矩阵。
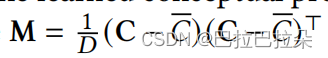
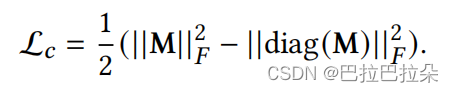
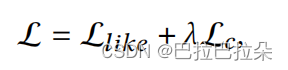
SINE与其他多兴趣召回的区别
- 多兴趣产生方式 MIND是通过Capsule产生多个用户兴趣,ComiRec-SA是通过Self-Attention的多头注意力机制实现多个用户兴趣,SINE产生的机制不太一样,通过构造一个大型的Concept池(用户意图池),然后根据用户行为序列在Concept池上进行聚合得到多个兴趣向量。
- 多兴趣聚合方式 MIND是使用label-aware-attention的方式,根据训练时各个兴趣和label的相关程度进行加权求和,SINE这篇论文认为在infer阶段没有label因而会造成训练和预测不一致,因此SINE是先预估出用户最可能交互的下一个意图,然后计算兴趣向量和这个意图的相关性分数,用这个相关性分数和兴趣向量进行加权求和。总之,SINE认为训练及infer时预估用户下一个意图比找理想的label简单。
SINE的特别之处
SINE通过先构建一个大型的意图池(Concept pool),然后基于用户行为根据attention机制选出最相关的K个意图,选出意图后,再根据每个位置的序列和这K个意图的相关性聚合出K个用户兴趣向量。为了产出最后的用户向量,先预测用户下一个最可能的意图,然后根据预测意图计算各个兴趣向量的相关性,根据相关性分数进行加权求和,得到用户向量,参与到线上topK的召回。















 1579
1579











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









