







1.mysql架构
MySQL物理架构

配置文件
auto.cnf: 包含server_uuidmy.cnf: MySQL配置文件- /etc/my.cnf /etc/mysql/my.cnf /usr/etc/my.cnf ~/.my.cnf #寻找配置文件的位置和加载顺序
形形色色的其他文件
–basedir=dir_name //MySQL安装目录路径
–datadir=dir_name //数据目录的路径,数据目录存储数据,状态,日志等
–pid-file=file_name //MySQL服务器写ProcessID的文件路径
–socket=file_name, -S file_name //在Unix系统上,使用的Unix套接字文件的名字/用于通过管道与本地服务器建立连接
–log-error=file_name //记录错误和启动信息的日志文件名
port = 3306
socket = /tmp/mysql.sock
basedir = /usr/local/mysql
datadir = /data/mysql
pid-file = /data/mysql/mysql.pid
user = mysql
bind-address = 0.0.0.0
max_connections=2000
lower_case_table_names = 0 # 表名区分大小写
server-id = 1
tmp_table_size=16M
transaction_isolation = REPEATABLE-READ
ready_only=1
MySQL逻辑架构
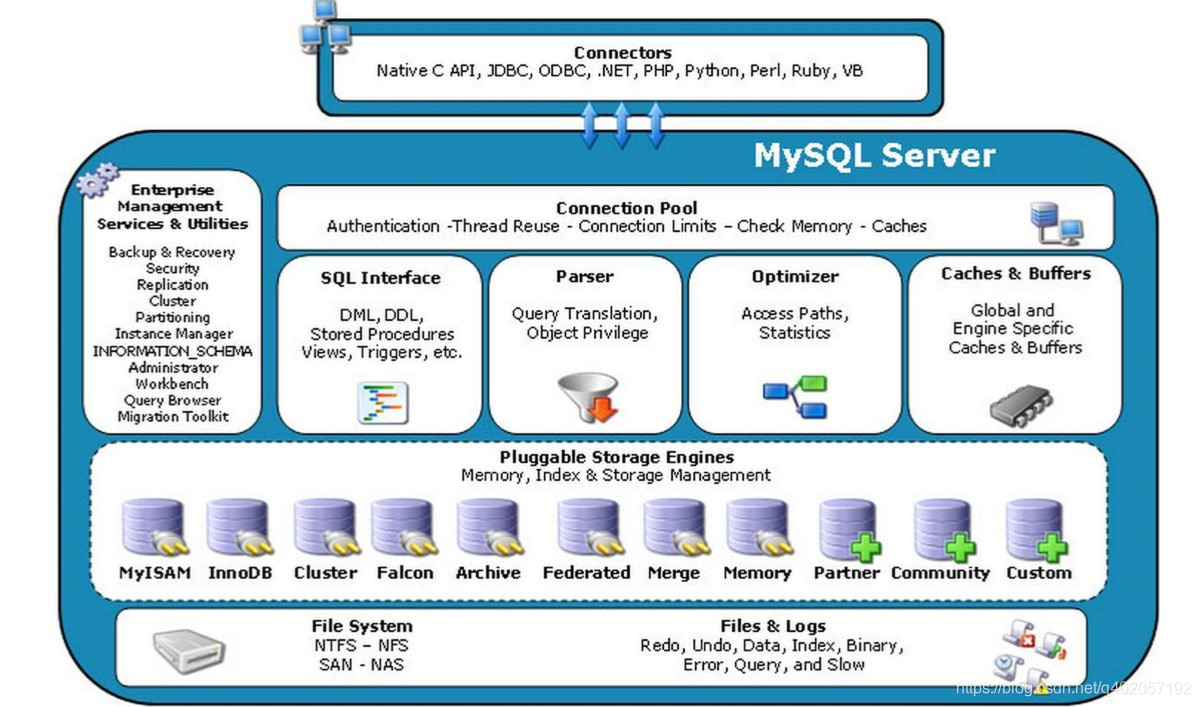
由图,可以看出MySQL最上层是连接组件。下面服务器是由连接池、管理工具和服务、SQL接口、解析器、优化器、缓存、存储引擎、文件系统组成。
连接池:由于每次建立建立需要消耗很多时间,连接池的作用就是将这些连接缓存下来,下次可以直接用已经建立好的连接,提升服务器性能。
管理工具和服务:系统管理和控制工具,例如备份恢复、Mysql复制、集群等
SQL接口:接受用户的SQL命令,并且返回用户需要查询的结果。比如select from就是调用SQL Interface
解析器: SQL命令传递到解析器的时候会被解析器验证和解析。解析器是由Lex和YACC实现的,是一个很长的脚本, 主要功能:
a . 将SQL语句分解成数据结构,并将这个结构传递到后续步骤,以后SQL语句的传递和处理就是基于这个结构的
b. 如果在分解构成中遇到错误,那么就说明这个sql语句是不合理的
优化器:查询优化器,SQL语句在查询之前会使用查询优化器对查询进行优化。他使用的是“选取-投影-联接”策略进行查询。
用一个例子就可以理解: select uid,name from user where gender = 1;
这个select 查询先根据where 语句进行选取,而不是先将表全部查询出来以后再进行gender过滤
这个select查询先根据uid和name进行属性投影,而不是将属性全部取出以后再进行过滤
将这两个查询条件联接起来生成最终查询结果
缓存器: 查询缓存,如果查询缓存有命中的查询结果,查询语句就可以直接去查询缓存中取数据。
通过LRU算法将数据的冷端溢出,未来得及时刷新到磁盘的数据页,叫脏页。
这个缓存机制是由一系列小缓存组成的。比如表缓存,记录缓存,key缓存,权限缓存等
2.MySQL内存结构
MySQL中内存大致分为:全局内存(Global buffer)、线程内存(Thread buffer) 两大部分。
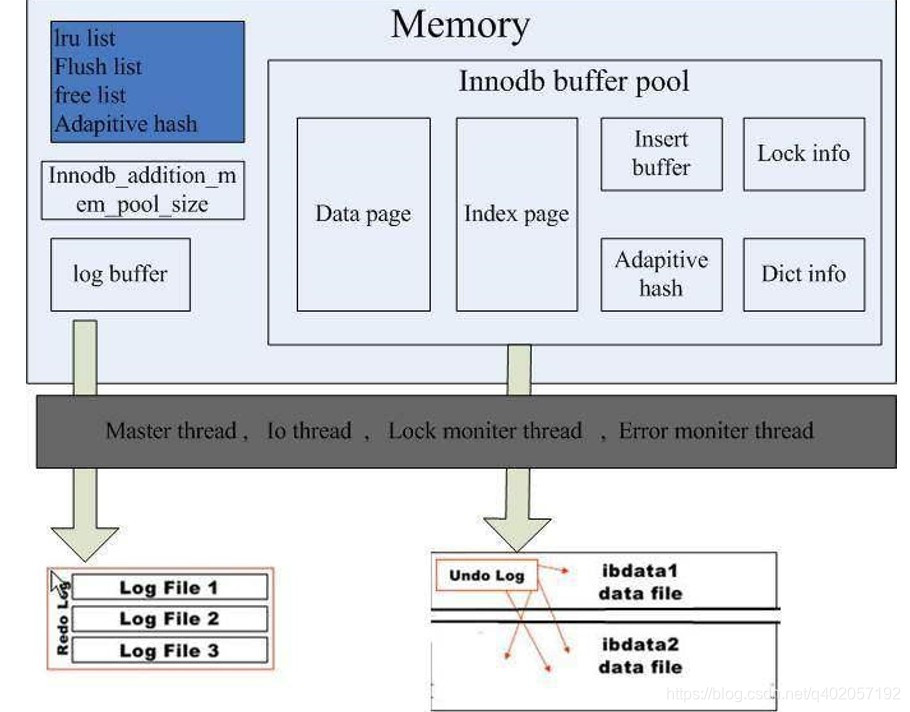
Mysql内存参数配置
- Innodb_buffer_pool_size
innodb buffer/cache 的大小(默认128M) - Innodb_buffer_pool
数据缓存
索引缓存
缓冲数据
内部结构
大的缓冲池可以减小多次磁盘I/O 访问相同的表数据以提高性能
参考计算公式:
Innodb_buffer_pool_size = (总物理内存 - 系统运行所用 - connection 所用)* 90%
Mysql其他参数配置
wait_timeout
服务器关闭非交互连接之前等待活动的秒数
innodb_open_files
限制Innodb能打开的表的个数
**innodb_write_io_threads
innodb_read_io_threads
innodb使用后台线程处理innodb缓冲区数据页上的读写 I/O(输入输出)请求
innodb_lock_wait_timeout
InnoDB事务在被回滚之前可以等待一个锁定的超时秒数
3、MySQL文件结构
(1) 参数文件:启动MySQL实例的时候,指定一些初始化参数,比如:缓冲池大小、数据库文件路径、用户名密码等。
(2) 日志文件:比如:错误日志、二进制日志、慢查询日志、查询日志等等。
通过show variables like "error_log"来查看错误日志存放内容。
通过show variables like "long_query_time"来查看慢查询日志记录的阈值。默认的慢查询日志的阀值是10秒,也就是查询时长超过10秒就会记录到慢查询日志文件;
(3) socket文件:当用UNIX域套接字方式进行连接的时候需要的文件。
(4) pid文件:MySQL实例的进程ID文件。
(5) 表结构文件:用来存放MySQL表结构定义文件。
.frm后缀命名的文件都是表结构文件,和存储引擎类型无关。所有的表都会生成一个.frm文件;
(6) 存储引擎文件:存储引擎正在存储了记录和索引等数据。
(1)共享表空间:共享表空间文件以.ibdata*来命名; 共享表空间下,innodb所有数据保存在一个单独的表空间里面,而这个表空间可以由很多个文件组成,一个表可以跨多个文件存在,所以其大小限制不再是文件大小的限制,而是其自身的限制。从Innodb的官方文档中可以看到,其表空间的最大限制为64TB,也就是说,Innodb的单表限制基本上也在64TB左右了,当然这个大小是包括这个表的所有索引等其他相关数据。
共享表空间主要存放double write、undo log(undo log没有独立的表空间,需要存放在共享表空间)
(2)独立表空间:每个表拥有自己独立的表空间用来存储数据和索引。
(3)查看数据库是否启用独立表空间:
show variables like ‘innodb_file_per_table’;查看,innodb_file_per_table=ON,表示启用了独立表空间;
(4)使用独立表空间的优点:
如果使用软链接将大表分配到不同的分区上,易于管理数据文件
易于监控解决IO资源使用的问题;
易于修复和恢复损坏的数据;
相互独立的,不会影响其他innodb表;
导出导入只针对单个表,而不是整个共享表空间;
解决单个文件大小的限制;
对于大量的delete操作,更易于回收磁盘空间;
碎片较少,易于整理optimize table;
易于安全审计;
易于备份
如果在innodb表已创建后设置innodb_file_per_table,那么数据将不会迁移到单独的表空间上,而是续集使用之前的共享表空间。只有新创建的表才会分离到自己的表空间文件。
(5)共享表空间的数据文件配置:
innodb_data_file_path参数:设置innoDB共享表空间数据文件的名字和大小,例如innodb_data_file_path=ibdata1:12M:autoextend(初始大小12M,不足自增)
innodb_data_home_dir参数:innodb引擎的共享表空间数据文件的存放目录
目前主要是使用独立表空间,但是共享表空间也是需要的,共享表空间主要存放double write、undo log等
4、InnoDB表存储结构
InnoDB存储空间被切分成tablespace,tablespace是一个与多个数据文件相关联的逻辑结构。
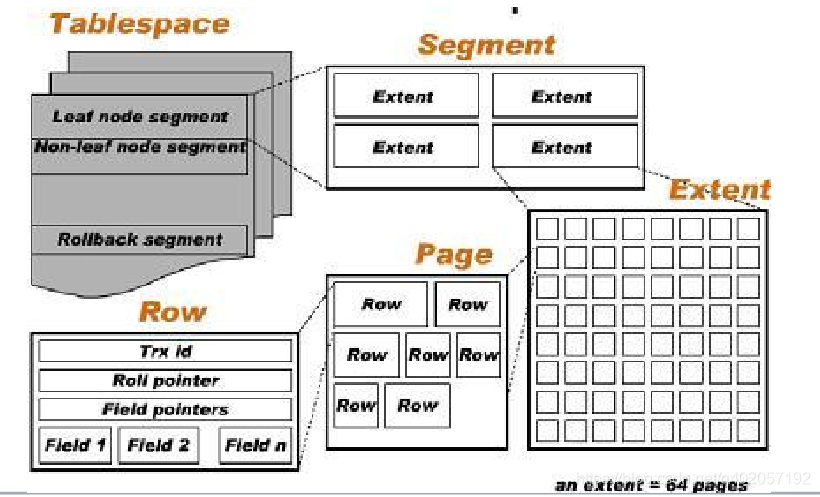

- (1)每页=16Kb(页类型:数据页、undo页、系统页、事务数据页、插入缓冲位图页、插入缓冲空闲列表页、未压缩的二进制大对象页、压缩的二进制大对象页)
- (2)区=64个连续的页=64*16Kb=1MB
-
Pages
InnoDB最小的数据存储单元被也称作块。默认的页框是16KB,一个页包含多行。
可用页大小: 4kb,8kb,16kb,32kb,64kb
配置变量名 :innodb_page_size,在初始化mysqld时配置 -
Extents
一组页组成一个区,InnoDB为了更好的I/O吞吐率,每次读写都是按照区为单位。
一组16KB的页,一个区可以1MB,双写缓冲区(Doublewrite buffer )每次分配/读/写都是以区为单位。 -
Segments
4个区构成一个Segments
SQL执行

MySQL连接

Mysql事务
数据库操作的最小工作单元,是作为单个逻辑工作单元执行的一系列操作;
事务是一组不可再分割的操作集合(工作逻辑单元);
典型事务场景(转账):
update user_account set balance = balance - 1000 where userID = 3;
update user_account set balance = balance +1000 where userID = 1;事务ACID特性
原子性(Atomicity)
最小的工作单元,整个工作单元要么一起提交成功,要么全部失败回滚
一致性(Consistency)
事务中操作的数据及状态改变是一致的,即写入资料的结果必须完全符合预设的规则,
不会因为出现系统意外等原因导致状态的不一致
隔离性(Isolation)
一个事务所操作的数据在提交之前,对其他事务的可见性设定(一般设定为不可见)
持久性(Durability)
事务所做的修改就会永久保存,不会因为系统意外导致数据的丢失
事务并发带来的问题
Read Uncommitted(未提交读)
在该隔离级别,所有事务都可以看到其他未提交事务的执行结果。读取未提交的数据,也被称之为脏读(Dirty Read)。该级别用的很少。

Read Committed(提交读)
这是大多数数据库系统的默认隔离级别(但不是MySQL默认的)。它满足了隔离的简单定义:一个事务只能看见已经提交事务所做的改变,换句话说就是事务提交之前对其余事务不可见。这种隔离级别也支持不可重复读(Nonrepeatable Read),因为同一事务的其他实例在该实例处理其间可能会有新的commit,所以同一select查询可能返回不同结果。

Repeatable Read(可重复读)
这是MySQL的默认事务隔离级别,它确保同一事务的多个实例在并发读取数据时,会看到同样的数据行。不过理论上,这会导致另一个棘手的问题:幻读 (Phantom Read)。简单的说,幻读指当用户读取某一范围的数据行时,另一个事务又在该范围内插入了新行,当用户再读取该范围的数据行时,会发现有新的“幻影” 行。幻读是针对数据插入而不是更新,InnoDB和Falcon存储引擎通过多版本并发控制(MVCC,Multiversion Concurrency Control)机制解决了该问题(mysql彻底解决了幻读问题?请往下看)。

Serializable(可串行化)
这是最高的隔离级别,它强制事务都是串行执行的,使之不可能相互冲突,从而解决幻读问题。换言之,它是在每个读的数据行上加上共享锁。在这个级别,可能导致大量的超时现象和锁竞争。
| 事务隔离级别 | 脏读 | 不可重复读 | 幻读 |
| 读未提交(read-uncommitted) | 是 | 是 | 是 |
| 不可重复读(read-committed) | 否 | 是 | 是 |
| 可重复读(repeatable-read) | 否 | 否 | 是 |
| 串行化(serializable) | 否 | 否 | 否 |
在MySQL的众多存储引擎中,只有InnoDB支持事务,所有这里说的事务隔离级别指的是InnoDB下的事务隔离级别。
mysql怎么实现的可重复读
MVCC多版本并发控制(Multi-Version Concurrency Control)是MySQL中基于乐观锁理论实现隔离级别的方式,用于实现读已提交和可重复读取隔离级别。
在《高性能MySQL》中对MVCC的解释如下

新建一张表test_zq如下
| id | test_id | DB_TRX_ID | DB_ROLL_PT |
MVCC逻辑流程-插入
在插入数据的时候,假设系统的全局事务ID从1开始,以下SQL语句执行分析参考注释信息:
begin;-- 获取到全局事务ID
insert into `test_zq` (`id`, `test_id`) values('5','68');
insert into `test_zq` (`id`, `test_id`) values('6','78');
commit;-- 提交事务
复制代码当执行完以上SQL语句之后,表格中的内容会变成:
| id | test_id | DB_TRX_ID | DB_ROLL_PT |
|---|---|---|---|
| 5 | 68 | 1 | NULL |
| 6 | 78 | 1 | NULL |
可以看到,插入的过程中会把全局事务ID记录到列 DB_TRX_ID 中去
MVCC逻辑流程-删除
对上述表格做删除逻辑,执行以下SQL语句(假设获取到的事务逻辑ID为 3)
begin;--获得全局事务ID = 3
delete test_zq where id = 6;
commit;执行完上述SQL之后数据并没有被真正删除,而是对删除版本号做改变,如下所示:
| id | test_id | DB_TRX_ID | DB_ROLL_PT |
|---|---|---|---|
| 5 | 68 | 1 | NULL |
| 6 | 78 | 1 | 3 |
MVCC逻辑流程-修改
修改逻辑和删除逻辑有点相似,修改数据的时候 会先复制一条当前记录行数据,同事标记这条数据的数据行版本号为当前是事务版本号,最后把原来的数据行的删除版本号标记为当前是事务。
begin;-- 获取全局系统事务ID 假设为 10
update test_zq set test_id = 22 where id = 5;
commit;执行后表格实际数据应该是:
| id | test_id | DB_TRX_ID | DB_ROLL_PT |
|---|---|---|---|
| 5 | 68 | 1 | 10 |
| 6 | 78 | 1 | 3 |
| 5 | 22 | 10 | NULL |
MVCC逻辑流程-查询
此时,数据查询规则如下:
-
查找数据行版本号早于当前事务版本号的数据行记录
也就是说,数据行的版本号要小于或等于当前是事务的系统版本号,这样也就确保了读取到的数据是当前事务开始前已经存在的数据,或者是自身事务改变过的数据
查找删除版本号要么为NULL,要么大于当前事务版本号的记录
这样确保查询出来的数据行记录在事务开启之前没有被删除
根据上述规则,我们继续以上张表格为例,对此做查询操作
begin;-- 假设拿到的系统事务ID为 12
select * from test_zq;
commit;执行结果应该是:
| id | test_id | DB_TRX_ID | DB_ROLL_PT |
|---|---|---|---|
| 6 | 22 | 10 | NULL |
这样,同一个事务中,就实现了可重复读。
幻读
什么是幻读,如下:
快照读和当前读
出现了上面的情况我们需要知道为什么会出现这种情况。在查阅了一些资料后发现在RR级别中,通过MVCC机制,虽然让数据变得可重复读,但我们读到的数据可能是历史数据,不是数据库最新的数据。这种读取历史数据的方式,我们叫它快照读 (snapshot read),而读取数据库最新版本数据的方式,叫当前读 (current read)。
select 快照读
当执行select操作是innodb默认会执行快照读,会记录下这次select后的结果,之后select 的时候就会返回这次快照的数据,即使其他事务提交了不会影响当前select的数据,这就实现了可重复读了。快照的生成当在第一次执行select的时候,也就是说假设当A开启了事务,然后没有执行任何操作,这时候B insert了一条数据然后commit,这时候A执行 select,那么返回的数据中就会有B添加的那条数据。之后无论再有其他事务commit都没有关系,因为快照已经生成了,后面的select都是根据快照来的。
当前读
对于会对数据修改的操作(update、insert、delete)都是采用当前读的模式。在执行这几个操作时会读取最新的版本号记录,写操作后把版本号改为了当前事务的版本号,所以即使是别的事务提交的数据也可以查询到。假设要update一条记录,但是在另一个事务中已经delete掉这条数据并且commit了,如果update就会产生冲突,所以在update的时候需要知道最新的数据。也正是因为这样所以才导致幻读。
如何解决幻读
在快照读情况下,mysql通过mvcc来避免幻读。
在当前读情况下,mysql通过X锁或next-key来避免其他事务修改:















 1371
1371











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









