







直到现在我们一直都在说shard的事情,不是还有replicas吗?现在开始讨论,replicas的作用是提高可用性,也就是做数据备份,防止丢失,如果有个shard挂掉了,它的replica就会顶替他的位置。
在index过程中,replica和shard做了基本一样的事情,新文档进来先index进入shard,然后该shard的replica自动把数据备份到自己的索引中,记住:增加replicas的数量对于es cluster扩容无任何作用!
除了提高可用性,replicas的另外一个重要作用就是可以供读请求访问,这可是非常重要的功能!!!如果你的业务情景是读多写少(大部分都这样的业务情况)那这个东西可以大大的提高读的性能(我自己测试过确实是这样的),但前提要求是你得加node,,,
上面的例子里面我们现在加入1 replica,
PUT /my_index/_settings
{
"number_of_replicas": 1
}
图是这样的
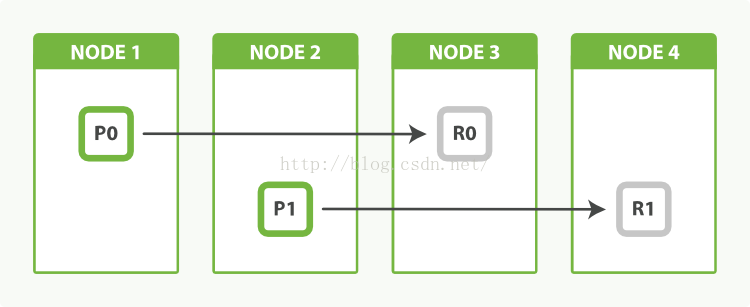
采用replicas进行负载均衡
请求表现永远决定于最慢的node(短板理论),如果我们现在有3个node,必然会发生2个node各1个分片,另外一个node必然2个分片(2*2),这样的设计不好为了平衡可以再加一组replicas也就是2 *3 /2 = 3,每个node3个分片
PUT /my_index/_settings
{
"number_of_replicas": 2
}
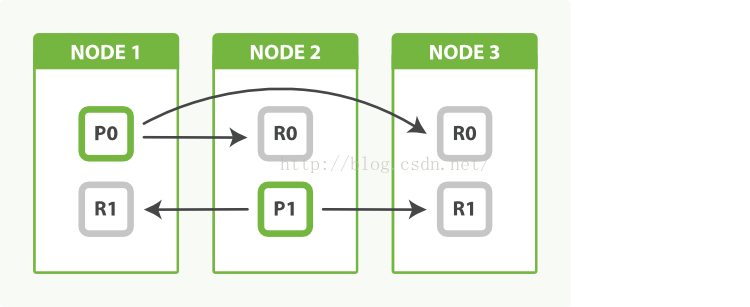
!!!好多人都有这个疑问:
有的node放的shard,有的放的replicas,这样对系统有影响吗?shard和replica消耗还有性能表现相同吗?作者回答了,他们扮演着不同的角色但干着同样的事情,没必要必须把primary 和replicas平衡开来的,所以别担心来。。。
github地址:https://github.com/whybangbang/Elasticsearch---The-Definitive-Guide-















 144
144

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









