







索引
简介
2型控制律加速器(CLA)是一个独立的、完全可编程的32位浮点数学处理器,为C28x系列带来并行控制能力。CLA的低中断延迟允许它 “just-in-time.” (及时)读取ADC采样,显著减少了ADC采样到输出的延迟,从而实现更快的系统响应和更快的MHz控制环路。通过使用CLA为时间关键型控制回路提供服务,主CPU可以自由地执行其他系统任务,如通信和诊断。
以上关于CLA的介绍翻译自[1]的第5章。
[2]是TI官方的学习视频,提供了例程可供下载,是不错的入门材料。
[3]是编译器手册,第10章对CLA的编译器进行了介绍。
[4]对CLA的数学库做了介绍。
[5]讨论了CLA浮点计算时的舍入误差。
C2000Ware_3_01_00_00提供了7类共22个例程,文件位置在C:\ti\c2000\C2000Ware_3_01_00_00\driverlib\f28004x\examples\cla 本文将针对其中一部分进行测试。
转载[6] 我的浮点心 - CLA简介(上)
在TI的产品线中,F2803x Piccolo™系列处理器主打低成本高效控制的路线。在数据计算部分,虽然有IQMath这个伪浮点数计算库,但是在平均最高60MHz的处理速度下,仍然后很多工作无法胜任。为了提高性价比,TI在其中引入了一个新的概念:控制率加速器(Control Law Accelerator, 简称CLA),主要功能是:在原有的CPU构架外,新增一个支持浮点运算的并行处理核心,实现“双核”控制。
什么时候需要用CLA?
- 有大量的浮点数学运算,CPU在计算之余,还需要去响应各种外设的请求。
由于CLA是与原有的CPU并行进行计算,因此在原有的CPU中只需要设置好交换的数据并使能对应的CLA任务,CPU就可以去运行其它的任务,CLA运行完毕后会自动将规定好的数据传回。就好象对自己的助手说:“嘿,张三,帮我把这个表格按照公司的格式生成统计结果”,张三做完后会把数据送回来,而这段时间里你可以继续做其它的事情。 - 采用IQMath库的时候,无法同时满足“精度”和“范围”的需求。
在IQMath库中,CPU将浮点运算转换成定点运算,因此有时无法在精度和范围两方面灵活互补,而CLA采用了浮点数,系统会自动对计算的精度和范围进行调整,达到最优的效果。 - 程序需要对运行速度进行深度优化。
CLA运行的程序只能使用对应的汇编语言进行编程,用户可以在程序执行的流水线等待阶段插入不影响结果的语句,充分利用强大的计算能力,榨干处理器的每一点计算能力。
什么时候不适合使用CLA?
- 有大量的判断、跳转语句(if…else… for… while…)需要运行。
由于CLA采用8级流水线结构,数据的计算能力非常强大,但是在判断和跳转语句中会造成后续的流水线失败,因此,大量的判断和跳转操作最好放在CPU中进行。 - 需要访问复杂的外设。
CLA虽然和CPU共用大多数资源,但是前者只能访问PWM和ADC的有限的寄存器,其它的寄存器访问需要间接的向CPU请求,由此也可以看出来,CLA的存在,主要是为了强化基于PWM控制的运算,而CPU可以更轻松的控制丰富的外设。
CLA的有什么不足?
- 与CPU共用内存资源
CLA没有自己的内存资源,因此必须从CPU中划分出对应的内存区域供CLA的程序和数据使用。 - 没有除法器只有乘法器和加法器
CLA只有乘法器和加法器,没有硬件除法器,因此除法运算需要的周期还是远大于乘法。
翻译[2]
[2]是TI官方提供的一个CLA入门教程,以一个运行在28379DLaunchPad的示例项目初步介绍了CLA的使用方法。
[2]中的一些PPT总结的很好,挑了一些重点进行翻译,该PPT的原文件可以从[2]中下载到。
翻译如有不妥还请各位大佬指正。
CLA受限的C语法编译器
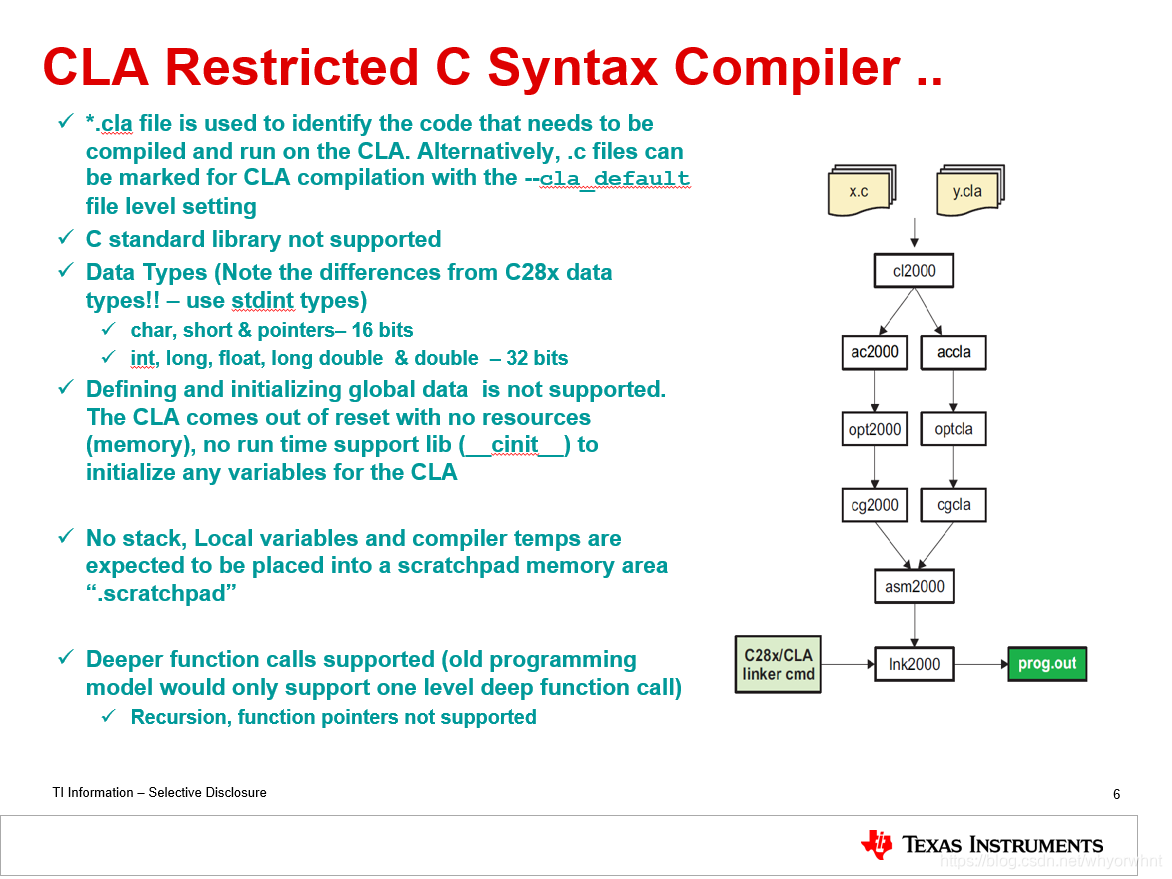
- 后缀为.cla的文件被用做识别那些需要被编译和在CLA上运行的代码。或者,当设置为–cla_default时.c文件也可以被编译。
- 不支持c标准库。
- 数据类型(注意与C28x数据类型的不同! -使用stdint类型)
char, short & pointers - 16 bits
int long float long double & double - 32 bits - 不支持定义和初始化全局变量。CLA从复位中恢复时没有资源和运行库用来初始化变量。
- 没有栈。局部变量和编译临时变量需要被存放在存储区".scratchapad"。
- 支持多级函数调用(过去只支持一级函数调用) 。不支持递归和函数指针。
存储器模型

这页主要讲了不同的数据被放在什么区域。
- 未初始化的全局变量放置在".bss_cla";
- 已经初始化的常量放置在".const_cla";
- 局部变量和编译临时变量放置在".scratchpad",其大小由编译器决定。
- CLA的代码放置在"Cla1Prog"。
- CLA没有C系统堆,因此不支持malloc之类的操作。
注意上述区域都在RAM中,在运行时需要从flash中拷贝到ram中。如果没有为".scratchpad"分配足够的空间则会报错。
从C28x向CLA移植代码

step 1
切换至CLA_CODE编译配置。将CLA变量分配给它们各自的内存空间。根据内存分配的那页PPT,使用#pragma将内存分配给变量。
step 2
在运行时将CLA的代码和常量从FLASH复制到RAM。我们将链接器定义的变量用于“Cla1Prog”和“.const_cla”部分
- 我们需要首先向这些变量添加一个外部存储限定符,以便编译器知道它们存在;
- 然后在initCLA()中的memcpy()中使用这些变量,在代码正上方的注释中提供了memcpy()的语法。

step 3
让CLA控制程序和数据空间。您可以通过MMEMCFG寄存器(TRM 9.4.3.2)执行此操作。必须启用位:
- 给予CLA对程序空间的控制(RAMLS0/1);
- 让CLA控制我们的示例中使用的一个数据RAM(RAMLS2-5)。
step 4
当一个任务被触发时,CLA通过将任务的MVECTx寄存器加载到CLA的程序计数器(MPC)来跳转到该任务。MVECTx在低64Kw内存中包含该任务的地址。使用任务标签(例如Cla1Task1)设置任务1和8 的MVECT寄存器地址。

step 5
通过配置CLA1TASKSRCSELx寄存器来决定触发每个任务的事件。对于每个任务,它都有一个4位字段,其有一个外围触发器列表可供选择(TRM 2.14.7.3),或查看“F2837xD_Cla_defines.h”中提供的宏。在该示例中:
- 任务1必须由ADCINT1触发;
- 任务8没有触发器,将在软件中强制执行一次。
step 5续
您必须设置MIER(使能寄存器)中的相应位来全局启用要激活的任务。有关该寄存器的说明,见TRM的5.7.2.15。

step 6
由于CLA在启动时没有任何内存,因此我们不能让启动代码的__cinit()初始化任何CLA全局变量,因此,我们分配一个任务来执行它
- 在我们的例子中,task8将把延迟系数D[0]清零。我们想运行一次。我们没有给它分配触发源,可以使用软件强制触发。
- 我们通过MCTL寄存器启用软件强制触发(见TRM 5.7.2.9)。然后我们将运行任务8一次。“F2837xD_Cla_defines.h”有一些有用的宏函数来强制执行每个任务。
step 7
我们希望task1触发一个end-of-task中断。
- 我们将PIE 向量表配置为跳转到右边的ISR(见TRM,表1-118);
- 我们为cla-end-of-task-1中断启用PIE组及其子组(见TRM,表1-119)。

step 8
将滤波器代码从adcintIsr1()逐字复制到“freq_proc.cla”文件中的Cla1Task1()
step 9
为任务8编写for循环,将D[]的所有元素初始化为0.

step 10
endof-task1 ISR应该完成adcint1Isr()所做的其余工作,即它应该缓冲CLA中的滤波值,然后当计数达到1024时,它应该向后台循环发出信号,表明应该对数据运行FFT。
- 复制在adcint1Isr()中执行缓冲的代码并将其放入cla1Isr1()
- cla1Isr1()应清除ADC中断标志并确认PIE中的中断

















 3463
3463

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









