










写在前面
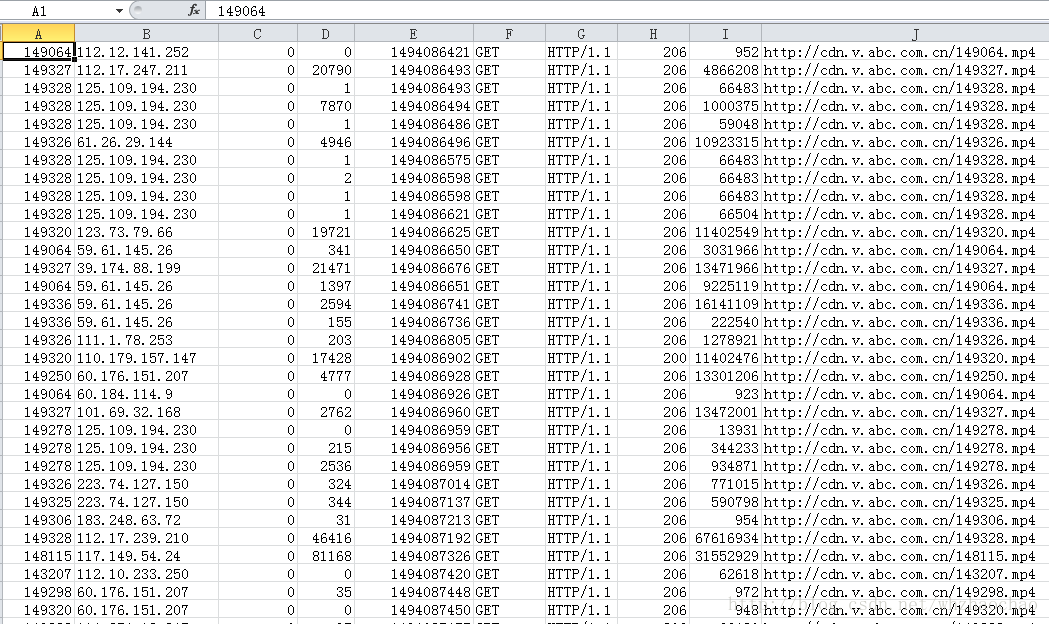
前面文章中,我们使用Spark RDD从非结构化的日志文件中分析出了访问独立IP数,单个视频访问独立IP数和每时CDN流量,这篇文章主要介绍使用Spark SQL从结构化的数据中完成这些数据的分析,如下图所有,先将日志文件结构化成csv文件,此文件可从源码cdn.csv中获取
Pom文件中添加SparkSQL依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.0.0</version>
</dependency>创建SparkSession对象
//创建sparkSession
val sparkSession = SparkSession.builder
.config("spark.sql.warehouse.dir", "D:\\WorkSpace\\spark\\spark-learning\\spark-warehouse")
.master("local")
.appName("spark session example")
.getOrCreate()加载结构化数据
//获取文件路径
val path=sqlWordCount.getClass.getClassLoader.getResource("cdn.csv").getPath
//读取文件
val df = sparkSession.read.csv(path)
//将加载的数据临时命名为log
df.createOrReplaceTempView("log")计算独立IP总数和每个IP访问数
代码
val allIpCountSQL="select count(DISTINCT _c1) from log "
val ipCountSQL="select _c1 as IP,count(_c1) as ipCount from log group by _c1 order by ipCOunt desc limit 10"
//查询独立IP总数
sparkSession.sql(allIpCountSQL).foreach(row=>println("独立IP总数:"+row.get(0)))
//查看IP数前10
sparkSession.sql(ipCountSQL).foreach(row=>println("IP:"+row.get(0)+" 次数:"+row.get(1)))上面这段代码就是简单的数据库SQL统计查询,好像比前面使用RDD计算简单多了
结果
独立ID总数:21012
IP:114.55.227.102 次数:481
IP:114.55.25.11 次数:481
IP:115.236.173.95 次数:378
IP:27.18.175.140 次数:333
IP:115.201.129.102 次数:288
IP:39.190.84.175 次数:277
IP:125.122.240.71 次数:258
IP:115.236.173.94 次数:257
IP:114.55.109.239 次数:231
IP:183.129.67.106 次数:223计算每个视频独立IP总数
代码
//查询每个视频独立IP数
val videoIpCount="select _c0,count(DISTINCT _c1) as count from log group by _c0 order by count desc limit 10 "
sparkSession.sql(videoIpCount).foreach(row=>println("IP:"+row.get(0)+" 次数:"+row.get(1)))看了这个代码,感觉也是很简单的,就是按视频ID分组,再统计每个分组中不同IP的数量
结果
视频ID:149356 次数:3958
视频ID:149064 次数:3885
视频ID:149349 次数:1938
视频ID:149341 次数:1631
视频ID:149344 次数:1334
视频ID:149328 次数:1237
视频ID:89973 次数:945
视频ID:149339 次数:826
视频ID:149345 次数:578
视频ID:149327 次数:545计算每个小时CDN流量
计算思路
这里面主要有一个时间段的问题,不然和上面的都是一样 groupby 一下再 sum 一下就OK了,不过日志中记录的是Unix时间戳,只能按秒去分组统计每秒的流量,我们要按每小时分组去统计,所以核心就是将时间戳转化成小时,总体过程如下
1. 通过SQL查出时间和大小
2. 将结果中的时间转成小时
3. 将时间格式化好后的RDD转成DataFrame,用于SQL查询
4. 通过SQL按小时分组查出结果
代码
def getHour(time:String)={
val date=new Date(Integer.valueOf(time)*1000);
val sf=new SimpleDateFormat("HH");
sf.format(date)
}
//查询每个小时视频流量
val hourCdnSQL="select _c4,_c8 from log "
//取出时间和大小将格式化时间,RDD中格式为 (小时,大小)
val dataRdd= sparkSession.sql(hourCdnSQL).rdd.map(row=>Row(getHour(row.getString(0)),java.lang.Long.parseLong(row.get(1).toString)))
val schema=StructType(
Seq(
StructField("hour",StringType,true)
,StructField("size",LongType,true)
)
)
//将dataRdd转成DataFrame
val peopleDataFrame = sparkSession.createDataFrame(dataRdd,schema)
peopleDataFrame.createOrReplaceTempView("cdn")
//按小时分组统计
val results = sparkSession.sql("SELECT hour , sum(size) as size FROM cdn group by hour order by hour ")
results.foreach(row=>println(row.get(0)+"时 流量:"+row.getLong(1)/(1024*1024*1024)+"G"))
结果
00时 流量:4G
01时 流量:12G
02时 流量:18G
03时 流量:23G
04时 流量:26G
05时 流量:28G
06时 流量:23G
07时 流量:22G
08时 流量:4G
09时 流量:20G
10时 流量:24G
11时 流量:29G
12时 流量:36G
13时 流量:33G
14时 流量:29G
15时 流量:34G
16时 流量:42G
17时 流量:39G
18时 流量:29G
19时 流量:22G
20时 流量:27G
21时 流量:6G
22时 流量:4G
23时 流量:3G完整项目代码及数据
https://git.oschina.net/whzhaochao/spark-learning














 103
103











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









