







目录
一、程序及算法内容介绍:
基本内容:
-
本代码基于Matlab平台编译,将GA(遗传算法)与SVM(支持向量机)结合,进行多输入数据分类预测,数据自动归一化
-
输入训练的数据包含12个特征,1个响应值,即通过12个输入值预测1个输出值(多变量分类预测,个数可自行调整)
-
通过GA算法优化SVM网络的c参数和g参数,记录下最优的值
-
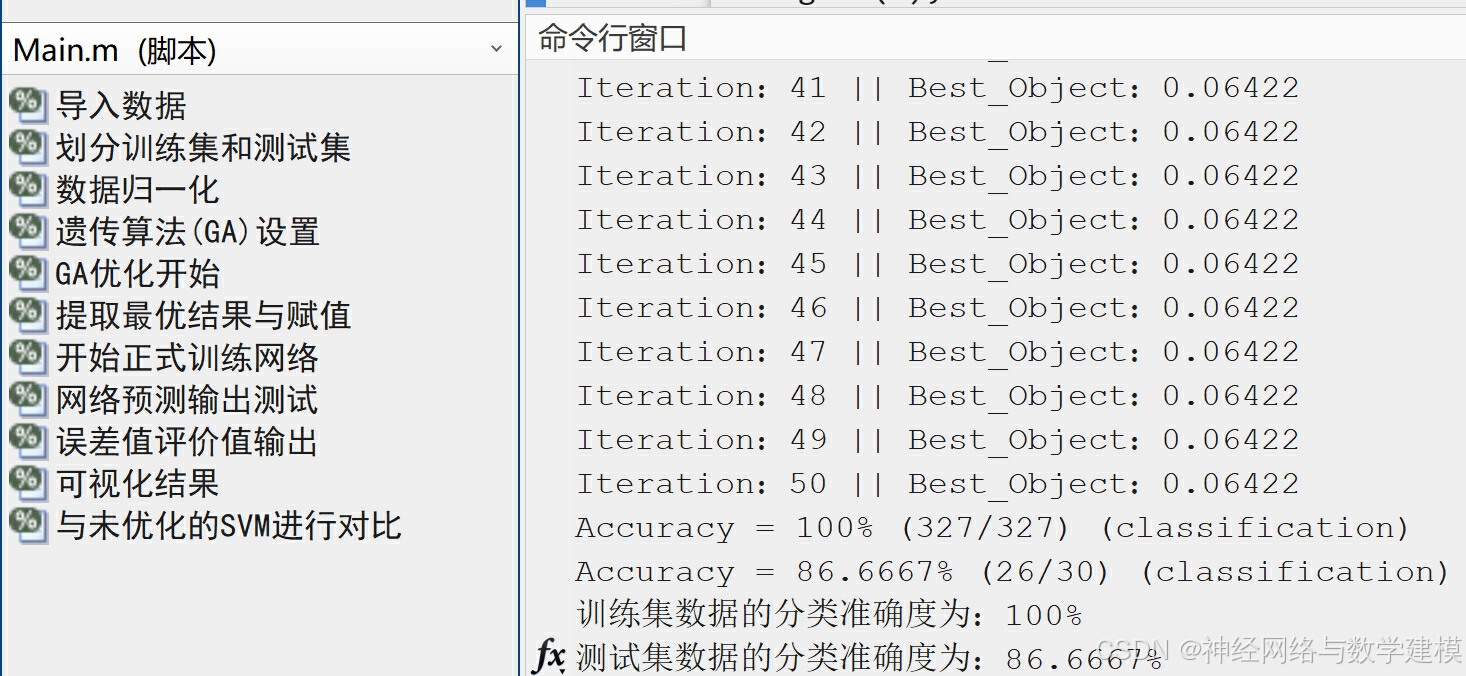
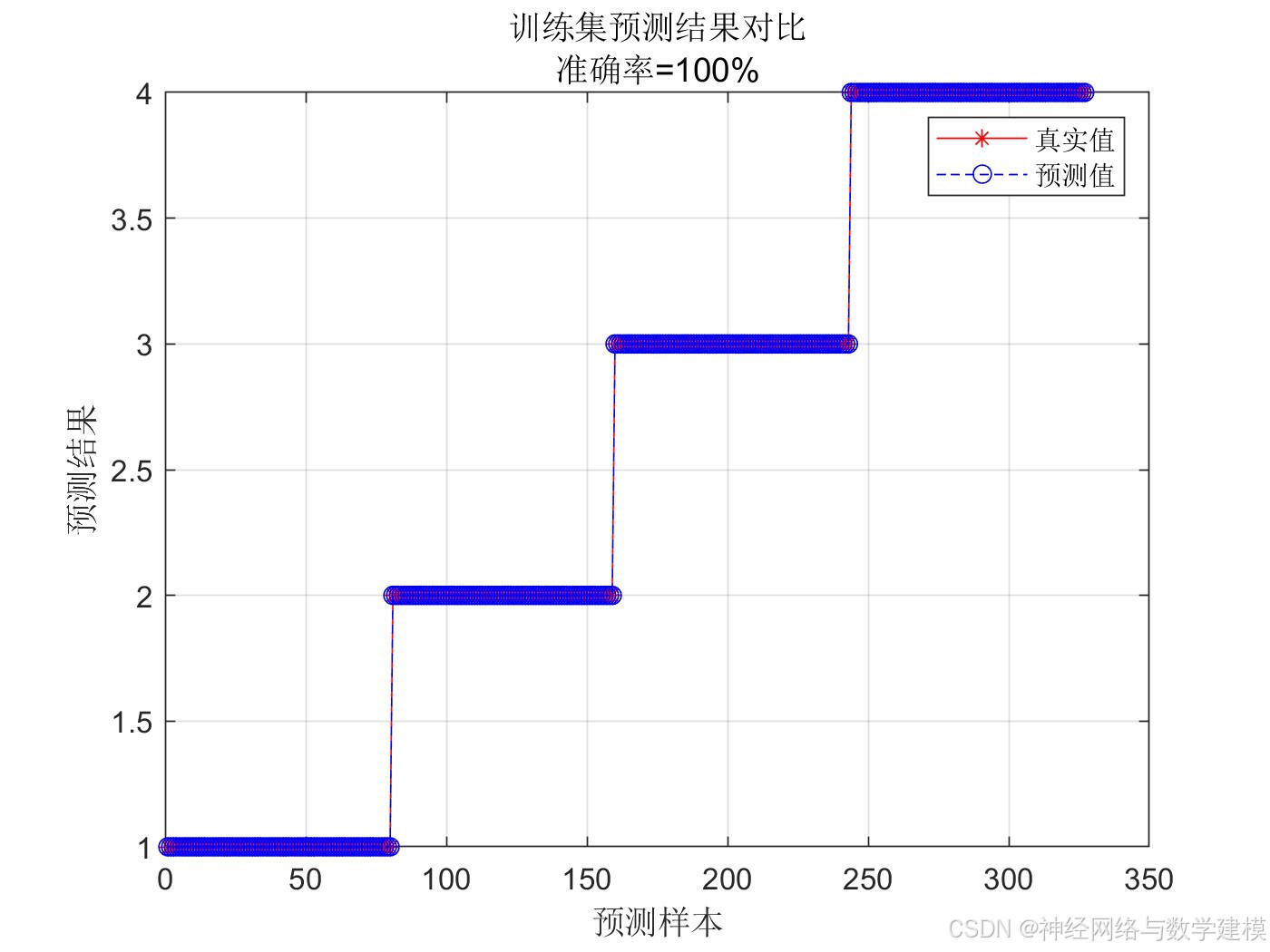
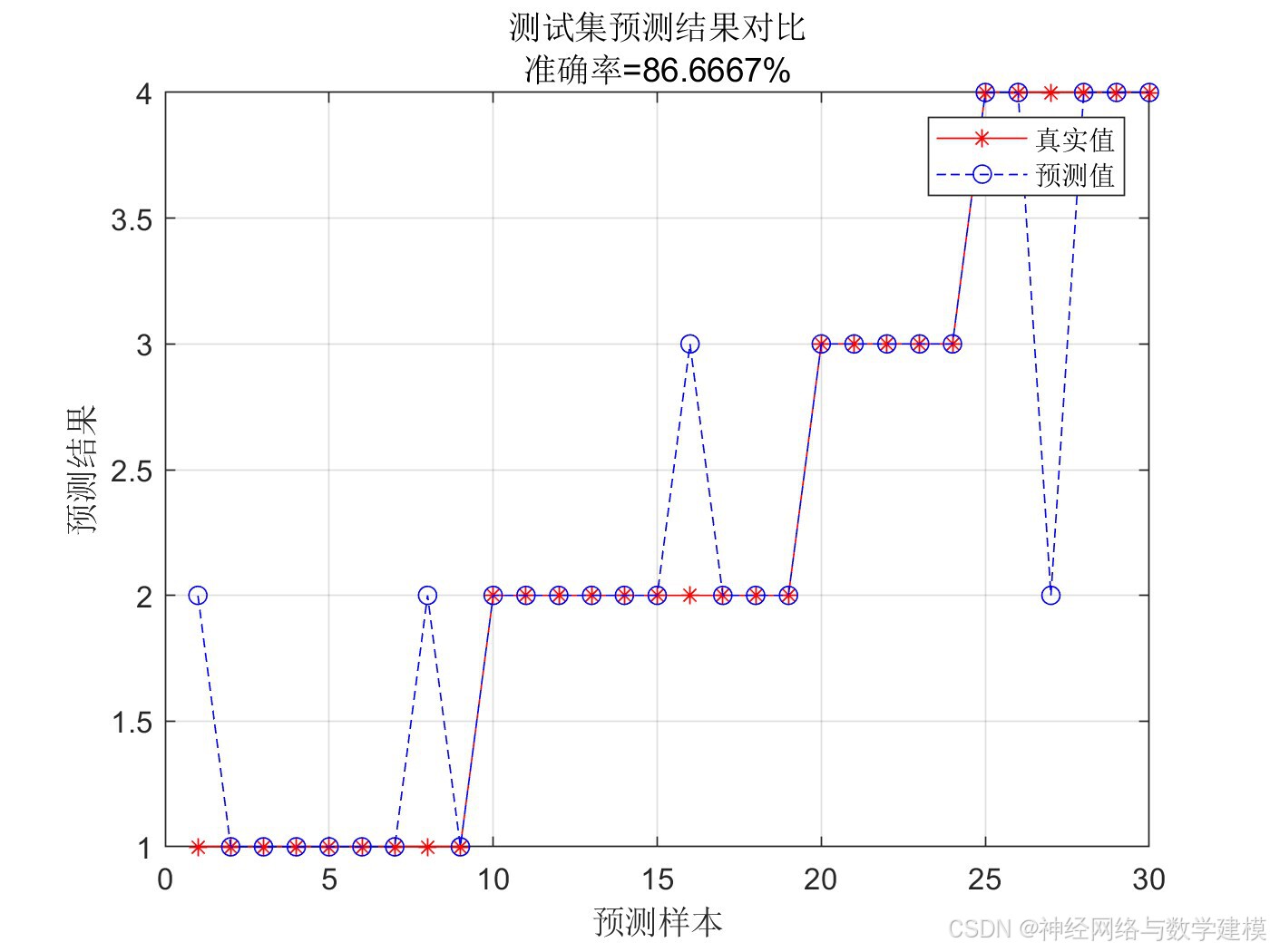
训练GA-SVM网络进行分类预测,并与单一SVM对比体现优势
-
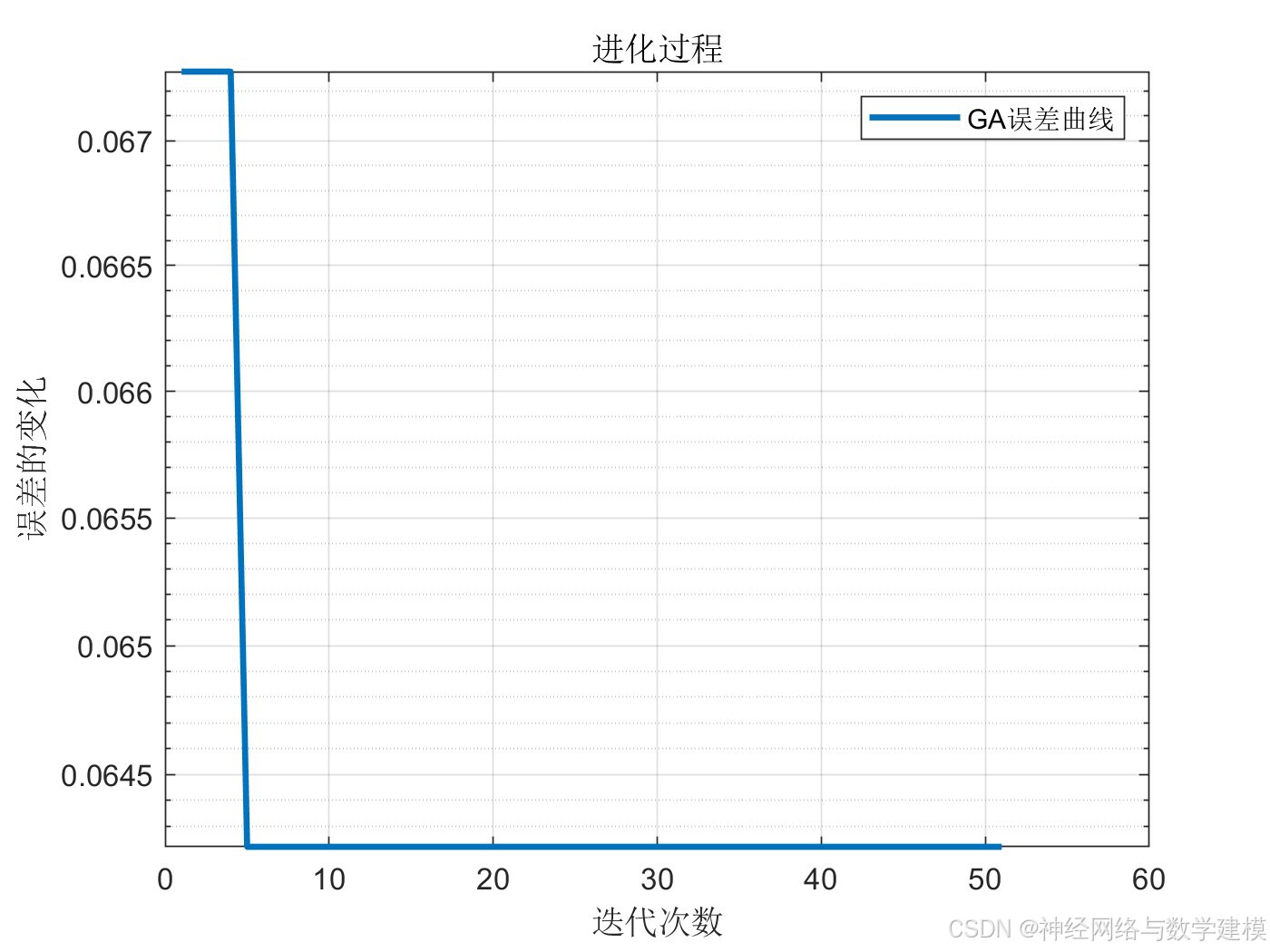
迭代计算过程中,自动显示优化进度条,实时查看程序运行进展情况
-
自动输出多种多样的的误差评价指标,自动输出大量实验效果图片
亮点与优势:
-
注释详细,几乎每一关键行都有注释说明,适合小白起步学习
-
直接运行Main函数即可看到所有结果,使用便捷
-
编程习惯良好,程序主体标准化,逻辑清晰,方便阅读代码
-
所有数据均采用Excel格式输入,替换数据方便,适合懒人选手
-
出图详细、丰富、美观,可直观查看运行效果
-
附带详细的说明文档(下图),其内容包括:算法原理+使用方法说明

二、实际运行效果:
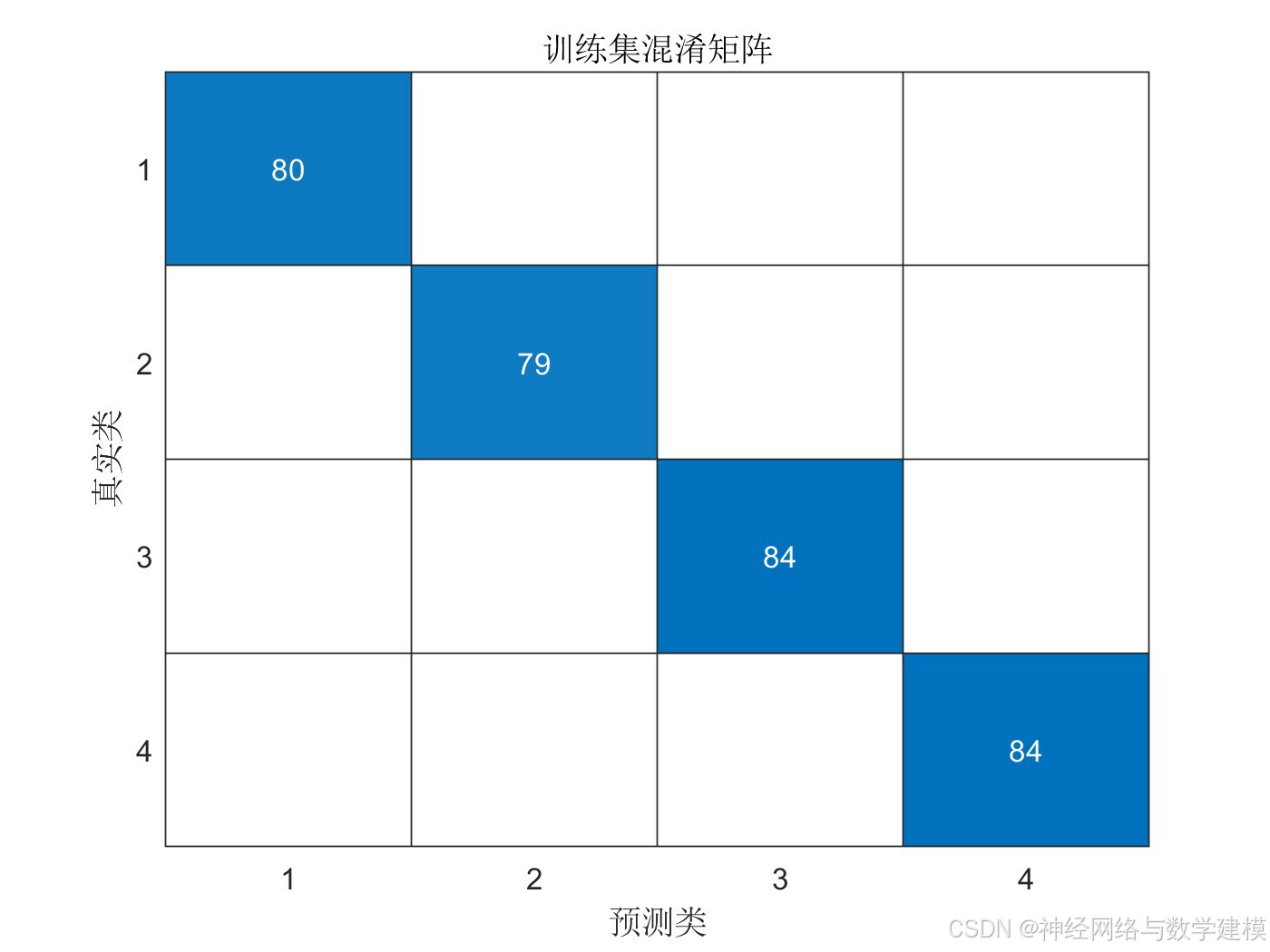
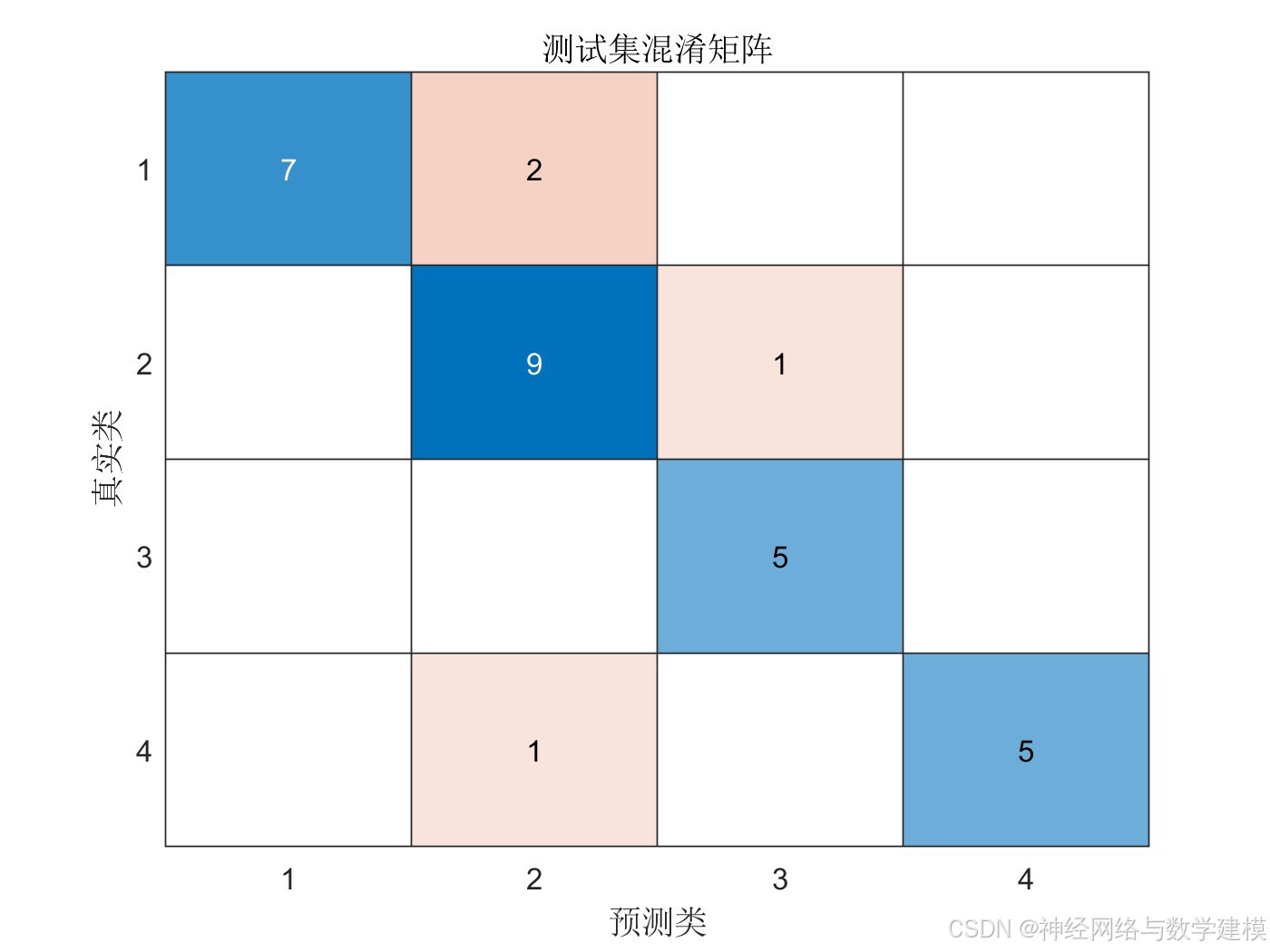
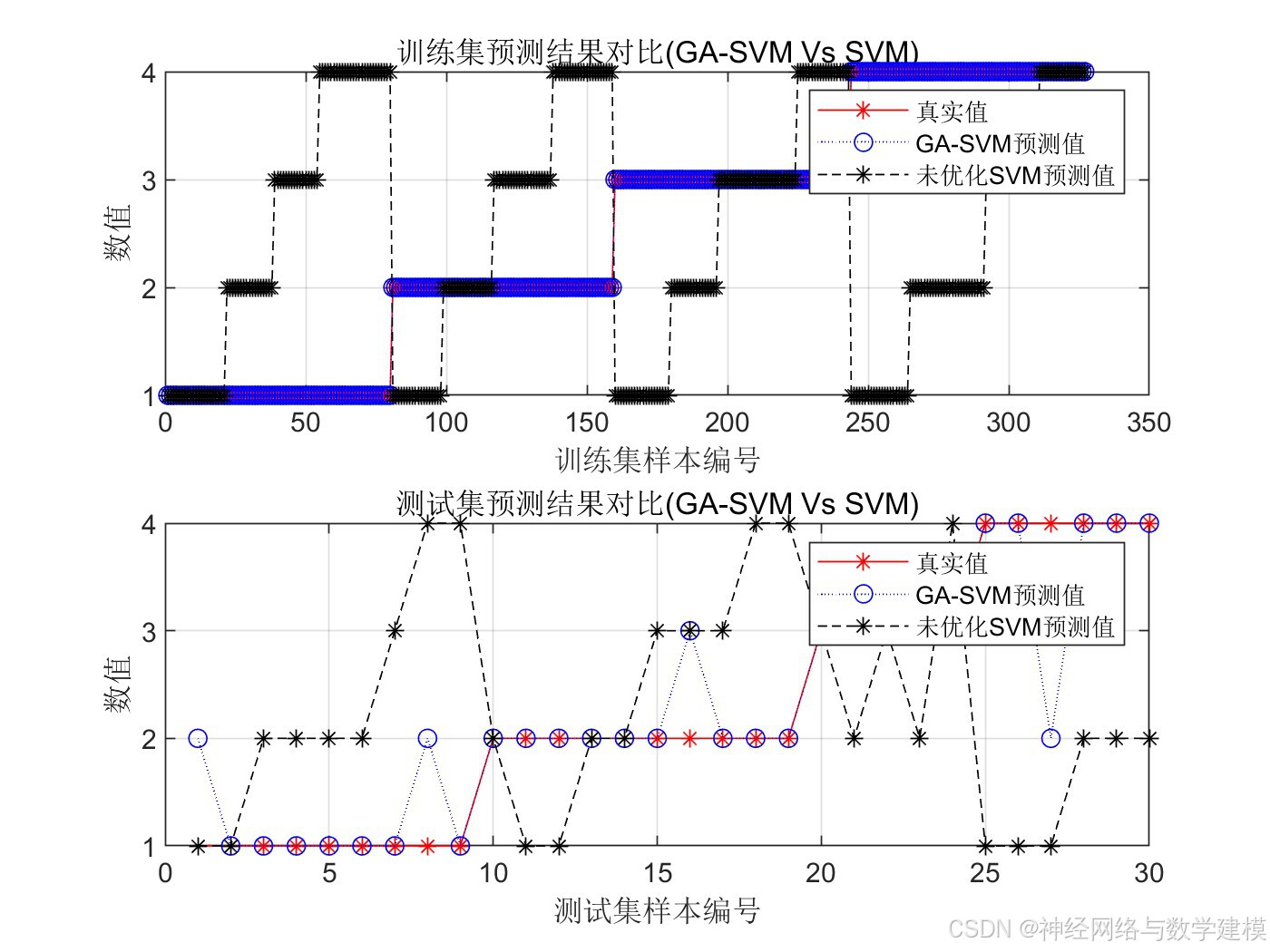
三、算法介绍:
遗传优化算法(Genetic Algorithm, GA)是一种基于自然选择和遗传学原理的优化算法,可以用于优化支持向量机(Support Vector Machine, SVM)的超参数。以下是如何使用遗传优化算法来优化支持向量机的详细步骤:
1. 定义问题
首先,明确需要优化的支持向量机的超参数,包括:“C”-惩罚参数,控制分类器对误分类的容忍度;以及:“γ(gamma)”-在RBF核中使用的参数,控制高维空间中样本的影响范围。
核函数类型:如线性核、多项式核、RBF核等。
2. 编码
在遗传算法中,首先需要对超参数进行编码。可以使用二进制编码、实数编码或其他适合的编码方式。对于C和γ,可以使用实数编码,而核函数类型可以用整数或字符编码。
3. 初始化种群
生成一个初始种群,每个个体代表一组超参数的组合。种群的大小可以根据具体问题进行调整,通常在几十到几百之间。
4. 适应度函数
定义适应度函数来评估每个个体的优劣。对于支持向量机,可以使用交叉验证的准确率作为适应度值。具体步骤为:将当前个体的超参数应用于支持向量机模型;使用交叉验证评估模型的性能,计算准确率;将准确率作为适应度值。
5. 选择、交叉、变异
使用选择操作来选择适应度较高的个体进行繁殖。常用的选择方法包括轮盘赌选择、锦标赛选择等。选择的目的是保留优秀的个体,以便在下一代中传递其基因。对选择出的个体进行交叉操作,以生成新的个体。交叉可以采用单点交叉、多点交叉或均匀交叉等方法。交叉的目的是将优秀个体的特征结合,产生更优的后代。对新生成的个体进行变异操作,以增加种群的多样性。变异可以通过随机改变个体的某些基因值来实现。变异率通常设置为较小的值,以避免过度扰动。
6. 更新种群
将新生成的个体加入到种群中,形成新的种群。可以选择保留部分旧个体,以保持种群的多样性。
四、完整程序下载:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









