






S3C6410处理器介绍
http://blog.csdn.net/nanjianhui/archive/2009/05/09/4163792.aspx
S3C6410做个简单介绍,该芯片大小为13x13mm,424管脚,芯片架构如图: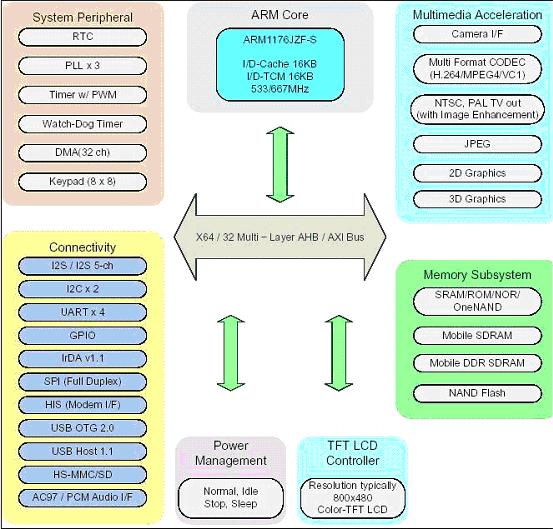
ARM Core:
采用ARM1176JZF-S的核,包含16KB的指令数据Cache和16KB的指令数据TCM,ARM Core电压为1.1V的时候,可以运行到553MHz,在1.2V的情况下,可以运行到667MHz。通过AXI,AHB和APB组成的64/32bit内部总线和外部模块相连。
Power Management:
目前支持Normal,Idle,Stop和Sleep模式。Normal是正常模式,其他模式都处于不同程度的低功耗模式下,说白了就是还有哪些模块在工作,可以被哪些中断唤醒。Sleep模式是最低功耗模式了,可以被有限的中断唤醒。关于在这几种模式下,芯片的功耗到底是多少,目前不得而知,将来一定要测试一下。
TFT LCD Controller:
显示控制器,支持TFT 24Bit LCD屏,分辨率能支持到1024x1024。显示输出接口支持RGB接口,I80接口,BT.601输出(YUV422 8Bit)和输出给TV Encoder的接口。支持最多5个图形窗口并可进行Overlay操作,从window0到window4,分别支持不同的图像输入源和不同的图像格式。实际上,显示控制器可以接收来自Carema,Frame Buffer和其他模块的图像数据,可以对这些不同的图像进行Overlay,并输出到不同的接口,比如LCD,TV Encoder。
System Peripheral:
RTC:系统掉电的时候由备份电池支持,需外接32.768KHz时钟,年/月/日/时/分/秒都是BCD码格式。
PLL:支持三个PLL分别是APLL,MPLL和EPLL。APLL为ARM提供时钟,产生ARMCLK,MPLL为所有和AXI/AHB/APB相连的模块提供时钟,产生HCLK和PCLK,EPLL为特殊的外设提供时钟,产生SCLK。
TIMER/PWM:支持5个32Bit Timer,其中Timer0和Timer1具有PWM功能,而Timer2,3,4没有输出管脚,为内部Timer。
WATCHDOG:看门狗,也可以当作16Bit的内部定时器。
DMA:支持4个DMA控制器,每个控制器包含8个通道,支持8/16/32Bit传输,支持优先级,通道0优先级最高。
KEYPAD:支持8x8键盘,与GPIO复用,按下和抬起都可产生中断。
Connectivity:
I2S:用于和外接的Audio Codec传输音频数据。支持普通的I2S双通道,也支持5.1通道I2S传输,音频数据可以是8/16/32Bit,采样率从8KHz到192KHz。
I2C:支持2个I2C控制器。
UART:支持4个UART口,支持DMA和Interrupt模式,UART0/1/2还支持IrDA1.0功能。UART最高速度达3Mbps。
GPIO:通用GPIO端口,功能复用。
IrDA:独立的IrDA控制器,兼容IrDA1.1,支持MIR和FIR模式。
SPI:支持全功能的SPI。
MODEM:Modem接口控制器,内置8KB SRAM用于S3C6410和外接Modem交换数据,该SRAM还可以为Modem提供Boot功能。
USB OTG:支持USB OTG 2.0,同时支持Slave和Host功能,最高速度480Mbps。
USB HOST:独立的USB Host控制器,支持USB Host 1.1。
MMC/SD:SD/MMC控制器,兼容SD Host 2.0,SD Memory Card 2.0,SDIO Card 1.0和High-Speed MMC。
PCM AUDIO:支持两个PCM Audio接口,传输单声道16Bit音频数据。
AC97:AC97控制器,支持独立的PCM立体声音频输入,单声道MIC输入和PCM立体声音频输出,通过AC-Link接口与Audio Codec相连。
Memory Subsystem:
DRAM Controller:两个片选,支持SDRAM,DDR SDRAM,mobile SDRAM和mobile DDR SDRAM。每个片选最大支持256MB。
NF Controller:NandFlash控制器,支持SLC/MLC NandFlash,支持512/2048Bytes Page的Nandflash,支持8Bit Nandflash,支持1/4/8Bit ECC校验,支持NandFlash Boot功能。
OneNAND Controller:支持2个OneNAND控制器,可外接16Bit OneNand Flash,支持同步异步读取数据,支持OneNAND Boot功能。
SROM Controller:六个片选,支持SRAM,ROM和NOR Flash,支持8/16Bit,每个片选支持128MB。
Multimedia Acceleration:
Camera Interface:外接Camera,支持ITU-R BT.601/656 8bit标准输入。支持Zoom In功能,最大图像达4096x4096,支持Preview,在Preview时支持Rotation和Mirror功能,Preview输出图像格式可以是RGB 16/18/24Bit和YUV420/433格式,支持图像的一些特效。
Multi Format Codec:视频Codec,支持MPEG4 ** Profile,H.264/AVC Baseline Profile,H.263 P3和VC-1 Main Profile编解码功能。支持1/2和1/4像素的运动估计,支持MPEG-4 AC/DC预测,支持H.264/AVC帧内预测,对于MPEG-4还支持可逆VLC和Data Partition功能,支持码流控制(CBR或者VBR),编解码同时进行的时候,可支持VGA 30fps。
TV Encoder:支持将数字视频转换成模拟的复合视频,支持N制和P制,支持Contrast,Brightness,Gamma等控制,支持复合视频和S端子输出。输入视频数据可以来自TV Scaler模块,该模块可以对视频数据进行处理,支持Resize功能,支持RGB与YUV两个不同色彩空间的转换,输入TV Scaler模块的图像最大可以是800x2048,输出图像最大是2048x2048,输出数据给TV Encoder进行编码,然后输出模拟视频。
Rotator:翻转模块支持对YUV420/422和RGB565/888的数据进行硬件翻转。
Post Processor:图像处理模块,类似TV Scaler模块。输入图像最大为4096x4096,输出图像最大为2048x2048,支持RGB与YUV之间的转换。
JPEG Codec:支持JPEG编解码功能,最大尺寸为4096x4096。
2D GRAPHICS:2D加速,支持画点/线,Bitblt功能和Color Expansion。
3D GRAPHICS:3D加速。
==============================================
基本的模块都说了,本人也是大致看了一下S3C6410 datasheet,许多模块还要等以后用的时候,才能了解更多。在我看来,这是一款功能齐全的应用处理器。
内部集成的多媒体解码器(MFC)支持mpeg4/h.263 /h.264的编码与解码,并支持VC1解码。这种H/W编码/解码器支持实时视频会议系统,以及NTSC和所有PAL制式的电视信号输出。
Primitives
Line/Point Drawing
- DDA ( Digital Differential Analyzer) algorithm
- Do-Not-Draw Last Point support
BitBLT
- Stretched BitBLT support ( Nearest sampling )
- Memory to Screen
- Host to Screen
Color Expansion
- Memory to Screen
- Host to Screen
Per-pixel Operation
Maximum 2040*2040 image size
Window Clipping
90°/180°/270°/X-flip/Y-flip Rotation
Totally全部地 256 3-operand【数】运算域 Raster【物】光栅 Operation【数】运算 (ROP)ROP(光栅化单元)
Alpha Blending
Alpha Blending with a user-specified 256-level alpha value
Per-pixel Alpha Blending
8x8x16-bpp pattern drawing
Data Format
16/24/32-bpp color format support
11.11 fixed point format for coordinate data
原语
线/点绘图
-多哈发展议程(数字微分分析器)算法
-请勿绘制最后一点支持
BitBLT
-拉伸BitBLT支持(最近抽样)
-内存屏
-主机屏幕
彩色扩充
-内存屏
-主机屏幕
对每个像素进行操作
最大2040 * 2040年的图片大小
窗口裁剪
90 ° / 180 ° / 270 ° / X-flip/Y-flip旋转
完全256 3 -运算光栅操作(人事登记)
alpha混合
Alpha混合与用户指定的256级Alpha值
对每个像素进行alpha混合
8x8x16 - bpp模式借鉴
数据格式
16/24/32-bpp颜色格式支持
11月11日定点坐标数据格式
42.1.1 FEATURES
• 4M **s/s @133MHz (Transform Only)
• 75.8M pixels/s fill-rates @133MHz (shaded pixels)
• rogrammable Shader Model 3.0 support
• 128-bit (32-bit x 4) Floating-point Vertex Shader
- Geometry-texture cache support
• 128-bit (32-bit x 4) Floating-point two Fragment Shaders
• Max. 4K x 4K frame-buffer (16/32-bpp)
• 32-bit depth buffer (8-bit stencil/24-bit Z)
• Texture format: 1/2/4/8/16/32-bpp RGB, YUV 422, S3TC Compress
• Support max. 8 surfaces (max. 8 user-defined textures)
• API Support: OpenGL ES 1.1 & 2.0, D3D Mobile
• Intelligent Host Interface
- 15 input data-types, Vertex Buffer & Vertex Cache
• H/W Clipping (Near & Far)
• 8-stage five-threaded Shader architecture
• rimitive assembly & hard-wired ** setup engine
• One pixels/cycle hard-wired rasterizer
• One texturing engine (one bilinear-filtered texel/cycle each)
- Nearest/bilinear/trilinear filtering
- 8-layered multi-texturing support
• Fragment processing: Alpha/Stencil/Z/Dither/Mask/ROP
• Memory bandwidth optimization through hierarchical caching
- L1/L2 Texture-caches, Z/Color caches
• System bus interface
- Host interface: 32-bit AHB (AMBA 2.0)
- Memory Interface: two 64-bit AXI (AMBA 3.0) channels
42.1.1特征
• 400三角形/秒@ 133MHz的(变换只有)
• 75.8M像素/ s的填写率@ 133MHz的(阴影像素)
•可编程Shader Model 3.0的支持
• 128位( 32位× 4 )浮点顶点着色
-几何纹理缓存支持
• 128位( 32位× 4 )浮点两个片段着色器
•最大。 4000 x 4000帧缓冲( 16/32-bpp )
• 32位深度缓冲( 8位stencil/24-bit ž )
•纹理格式: 1/2/4/8/16/32-bpp的RGB , YUV 422 , S3TC压缩
•支持最高。 8表面(最大8用户定义的纹理)
• API支持: OpenGL ES的1.1及2.0 , D3D移动
•智能主机接口
- 15输入的数据类型,顶点缓冲区和顶点缓存
• H / W型裁剪(近及远)
• 8级五个线程渲染架构
•原始大会及硬线三角形设置引擎
•一个像素/周期硬线光栅
•一个纹理引擎( 1双线性过滤纹元/周期每个)
-最近/双线性/三线性过滤
- 8层次多纹理支持
•片段处理:阿尔法/模板/ Z用/抖动/面具/光栅化单元
•内存带宽优化通过分层缓存
- L1/L2纹理缓存坐标/颜色缓存
•系统总线接口
-主机接口: 32位的AHB (的AMBA 2.0 )
-内存接口:两个64位的AXI (的AMBA 3.0 )渠道
像素高速缓存、使用该高速缓存的三维图形加速器及方法 http://www.patent-cn.com/G06T/CN1519777.shtml
提供一种用于三维(3D)图形加速器中的像素高速缓存的有效结构。该像素高速缓存包括:z数据存储单元,从帧存储器中读取z数据,并且将所读取的z数据提供给像素光栅化管道;以及色彩数据存储单元,在z数据存储单元从帧存储器中读取z数据的同时,预先从帧存储器中读取并存储色彩数据,并且只有当在像素光栅化管道中判定预定z测试的结果成功时,才将色彩数据提供给像素光栅化管道。因此,该像素高速缓存结构允许在处理色彩数据之前仅预先读取和存储所需色彩数据,从而防止访问延迟、提高色彩高速缓存效率并且降低功耗。
===================================================
PXA300平台2D图形加速器性能测试与分析
http://www.21eic.com/hmi/4093.html
引言
消费类电子产品的快速发展使得人们对嵌入式多媒体系统的性能要求也随之提升。随着消费电子产品性能的不断增强,人们希望有更多的嵌入式多媒体系统能够支持速度快,性能强劲的图形系统,嵌入式图形加速器在嵌入式多媒体系统中的应用开始崭露头角,并在嵌入式多媒体系统中得到更加广泛,更加深入的应用。
硬件加速技术对比软件加速技术有很大的优势:速度快、功能强和CPU占用率低。硬件加速技术和软件加速技术相比的最大优势在处理速度上,如一个简单的浮点运算协处理器,其浮点运算的性能就可以达到通用CPU的30倍。硬件图形加速器能比软件加速提供更多的效果和功能,例如PC图形加速器中的HDR(高动态范围)效果,它使得画面在细微变化时更加自然,但由于消耗太多的运算资源,对于实时渲染场景难以使用软件实现,而借助先进的图形加速硬件就可以完成。CPU占用率低,比如在PC系统中,只有使用中高端双核CPU才能流畅播放1080P H.264视频,而且CPU占有率也高达70%~90%;但是启用图形加速卡的硬件加速功能之后,CPU占用率降低到了10%。
图形硬件加速器在嵌入式多媒体系统中应用越来越广泛。硬件图形加速器能够让嵌入式平台完成一些计算量特别复杂的任务,比如说实时视频音频的编解码和3D游戏[2]。由于嵌入式通用CPU特别注重低功耗和移动性,因此频率一般不是很高,其性能也很难满足高质量实时视频、音频的编解码和3D游戏,如果要完成上述的任务就需要硬件加速器的支持。
1 测试平台简介
1.1 Marvell PXA300集成2D图形加速器
本次测试平台是采用Marvell最新的PXA300应用处理器(Monahans L系列)的嵌入式应用平台。MarvellPXA300处理器内部集成了2D图形加速器,它的加速功能包括绘制直线、填充矩形、矩形区域的缩放、旋转、复制和Alpha混合。这是一款为图形窗口操作量身定制的硬件图形加速器。
本文附图描述了2D图形加速器的结构。它拥有一个图形控制核心和多个缓冲区。图形控制核心从指令缓冲区里面取得图形指令,并从数据缓冲区中取得数据,对数据进行处理后把结果写入目的数据缓冲区。这些指令和数据的读取、写入都是独立于CPU进行的。
2D图形加速器的缓冲区分两种:
一种是指令缓冲区。指令缓冲区是存放图形指令的区域,它在逻辑上是一个队列结构。图形加速器内部则维护了一个头指针,一个尾指针和一个执行指针,以先进先出的方式读取和执行缓冲区里的指令。
另一种是数据缓冲区。数据缓冲区又分源缓冲区和目的缓冲区。源缓冲区是指在进行二元和多元运算时,源数据的存放地址,目的缓冲区则是运算结果存放的地址,一般来说目的缓冲区就是LCD控制器指定的Frame buffer。
1.2 基于Uboot的测试环境搭建
Uboot是一个开源的Bootloader项目,它支持Pow-erPC、ARM、Xscale、X86等体系结构,PXA300就是Xs-cale架构的成员。在Uboot下实现硬件测试功能,基本方法是向Uboot中添加用户自定义的测试命令[3]。
2 2D图形加速器驱动原理
2.1 2D图形加速器体系结构
PXA300集成2D图形加速器基本操作流程如下:
(1)初始化2D图形控制器:初始化源数据缓冲区和目的数据缓冲区,即填写这些缓冲区的首地址、像素位宽、每行占字节数和像素格式。一般初始化这两种缓冲区后就不再改变了。
(2)向指令缓冲区中填充指令:向指令缓冲区中填充图形指令指令。
(3)重置图形控制器:通过写控制寄存器,把所有状态寄存器、中断寄存器和和指令缓冲区相关的寄存器全部重置。
(4)配置指令缓冲区寄存器:即配置指令缓冲区的首地址,长度和尾地址。
Pxa300集成2D图形加速器有个特点,当指令缓冲区相关寄存器配置完成后,就会自动启动图形引擎,依次执行指令缓冲区的图形指令直到缓冲区尾部。当执行完所有指令,要想重新执行图形指令必须重置图形控制器,在执行时更改指令缓冲区寄存器是无效的。为配合这种硬件体系结构,特意设计了两个底层函数,用于填充指令和启动执行引擎。填充指令函数内部维护了当前指令缓冲区的所有信息,将图形指令以整型数组的形式写入缓冲区。启动执行引擎的函数的关键代码如下:
2.2软件接口设计
为了方便应用层使用,并屏蔽硬件的细节,必须设计一个和硬件无关的软件接口,因此提供了一系列绘图函数接口,比如画矩形的函数gc_rect()以及一个特殊的启动图形引擎的函数start_excute(),通过调用这些接口使2D图形加速器工作。硬件绘制矩形的关键代码如下:
3 测试步骤与结果
3.1性能测试指标
2D图形加速性能最基本的指标的每秒完成的图形操作次数。当前PC系统上进行图形性能测试一般有两种性能指标,一种是渲染固定场景所得到的每秒帧数(这种方法适合于3D性能测试),另一种是绘制固定数目的图形的时间,来得到每秒钟绘制图形的数目。这两种性能指标,其本质都是单位时间内完成的图形操作次数,在本文中以后者为性能指标。
3.2性能测试方法
本次测试选择了计算绘制65536条直线和16384个矩形区域的填充、旋转、复制、缩放和Alpha操作的时间来得到绘制的速度。因为绘制直线的速度比较快,所以绘制直线的数量相比其他操作要多一点,以达到比较好的效果。
为模拟正常应用的情况,本文利用随机函数来生成各种图形参数,随机函数采用普遍应用的乘线性同余函数。
本次测试测试了纯软件加速——即依赖CPU计算的软件绘图和硬件加速进行对比(本次测试只实现了一部分图形指令)。由于2D图形加速器是基于成批的图形指令工作的,而生成图形指令本身也需要一定的开销,因此在测试硬件加速时,也分为两种情况:第一种情况是事先把绘图指令填充到指令缓冲区中,然后启动图形引擎并计时;另一种情况是边填充图形指令边绘图,然后计算总时间。故在测试结果中,每种指令都有3组数据。
3.3 测试结果与分析
本次测试共得到了11组数据,限于篇幅无法全部列出。在得到的11组数据中,有10组数据的结果比较接近,只有一组数据(Seed=360)在旋转、复制和Alpha混合方面和其他10组数据相比有明显差距。考虑到随机函数的固有缺陷[4],偶尔出现这样的数据是可能的,可视为特殊情况下的表现,故剔除出有效数据之列。把10组有效数据取得平均值以后,得到如下结果(参见本文附表):
综合各组有效测试数据,除了Alpha混合预先填充情况下,最大偏差达到2.1%以外,各项数值和平均值的最大偏均差不超过1.4%,说明测试数据分布比较均匀且集中,能够有效地反映一般情况下2D图形加速器的绘图速度。
对比软件绘图和硬件绘图的差别,可以发现2D硬件加速器在绘制速度上的优势非常明显,其中绘制直线和绘制矩形比软件加速快10倍左右,而复制区域和Alpha混合则比软件加速快20倍左右。
软件绘制直线的实现选择了DDA算法[5],矩形填充、复制和Alpha混合的实现都是先行后列的顺序读写内存,这样符合ARM体系结构中的缓存机制[6]。2D图形加速器则通过私有的DMA通道来操作内存数据,利用自身向量处理单元进行矩阵运算。从以上测试数据看,该DMA通道的速度和效率都很不错,比软件使用CPU传输要快得多(CPU开启了数据和指令缓存),而且矩阵数据的运算能力也超过CPU。
再对比预先填充和即时填充两种模式,从结果上看两者差距很小,绘制直线比预计填充多用了3.5%的时间,绘制矩形则多用了1.7%的时间,其余差距均在1%以内。这个结果说明越是耗时的绘图操作填充指令的开销占的比例越小,这是因为不同种类的图形指令填充指令所用的时间差不多,但执行时间却相差很多。由此可认为图形硬件的CPU占用率在3.5%以下,因为硬件加速器在绘制图形的时候,只有填充指令这一步是需要CPU来完成的,其余时间CPU都是空闲状态,因此在测试环境下,硬件加速器的CPU占用率是相当低的。
综合以上分析结果,2D图形加速器在计算能力、数据传输速度和CPU占用率上,对比软件加速都存在非常明显的优势。
4 结论
本文实现了基于Bootloader的pxa300处理器集成2D图形加速器的驱动,并在此基础上,通过一系列测试,测定了2D图形加速器的图形性能,并与软件图形加速进行了比较,体现了硬件加速的优势。
高端ARM平台选型
最新推荐文章于 2024-05-10 12:31:19 发布
















 947
947

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









