







Dubbo
(一个能够提供rpc的服务框架)
rpc底层原理
服务间调用可以使用restTemplate(http)、Feign(rpc)或dubbo(rpc)等
RPC就是远程方法调用,可以通过以下协议来传输调用数据进行调用:
- RPC over Http:基于Http协议来传输数据
- PRC over Tcp:基于Tcp协议来传输数据
传输的调用数据基本都会包括: - 调用的是哪个类或接口
- 调用的是哪个方法,方法名和方法参数类型(考虑方法重载)
- 调用方法的入参
rpc http方式的实现方式
a.http方式实现rpc
b.动态代理方式实现rpc(代理内部依然是会通过http协议进行调用)
在使用dubbo时,上面的ip、地址、传输协议(http、dubbo)这些信息实际会由dubbo服务注册到注册中心(dubbo用的是zookeeper),然后消费者会从注册中心去获取到本地。
dubbo服务和dubbo协议是两个不同的概念。一个dubbo服务可以支持多个协议,比如http协议、dubbo协议,后面还会讲到Triple协议。
Triple协议基于Http2协议。gRPC也基于的HTTP2。Dubbo3.0在实现Triple的时候也兼容了gRPC。
dubbo服务如果使用http协议进行调用,那么他使用的是上面的b方式。
dubbo有一个重要概念:Invoker(执行器),每个Invoker表示一个url(dubbo服务节点)。url有ip、port、协议等组成,如果ip一样,协议不一样算不同的url(Invoker)。(即如果是集群,集群中有2个相同dubbo服务,则就会有2个Invoker。如果同一个dubbo服务,既支持http又支持dubbo协议,也会有2个Invoker)。
插播一条关于nacos服务注册/发现的知识点:
nacos 2.x服务注册/发现底层是用grpc来调用的,nacos1.4.1底层是通过http来调用的。
因此,grpc协议主要是用在Nacos 2.x 中的 服务注册与发现方面,而不涉及服务间调用的具体实现,服务间的调用还是用的dubbo服务,然后根据使用的dubbo版,来决定是用dubbo协议还是triple协议。
Dubbo3.0新特性介绍与使用
dubbo性能比http/rest更高
http1x协议慢在哪里?
1.http1.x协议格式
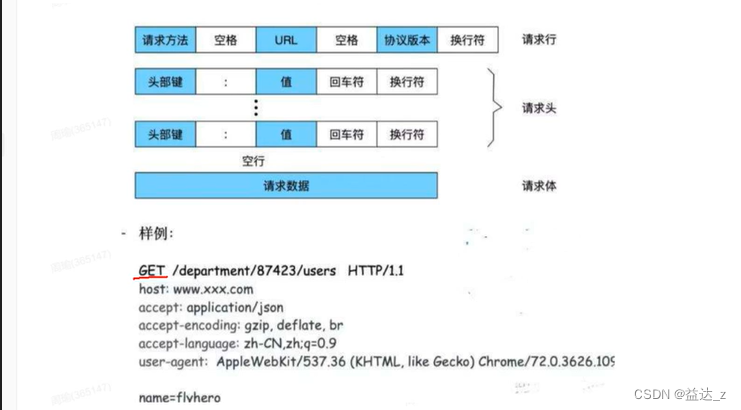
2.http1.x传输的时候,先组装成上面文本格式,再转成字节进行传输,里面会包含回车符,换行符,空行这些。
Dubbo觉得用HTTP1.x协议(特指HTTP1.x,HTTP2后面分析)性能太低了,原因在于:
- HTTP1.x协议中,多余无用的字符太多了,比如回车符、换行符,这每一个字符都会占
用一个字节,这些字节占用了网络带宽,降低了网络IO的效率。另外虽说可以对请求体进行压缩,但是无法对请求头进行压缩。 - HTTP1.x协议中,一条Socket连接,一次只能发送一个HTTP请求。
因为如果连续发送两个HTTP请求,然后收到了一个响应,那怎么知道这个响应对应的是哪个请求呢,这样导致Socket连接的利用低,并发、吞吐量低。
所以有了dubbo协议,它就是为了解决上面两个问题。
dubbo协议(dubbo协议传输数据少,性能更好,且能同时发送多个请求。)
dubbo协议有自己的格式
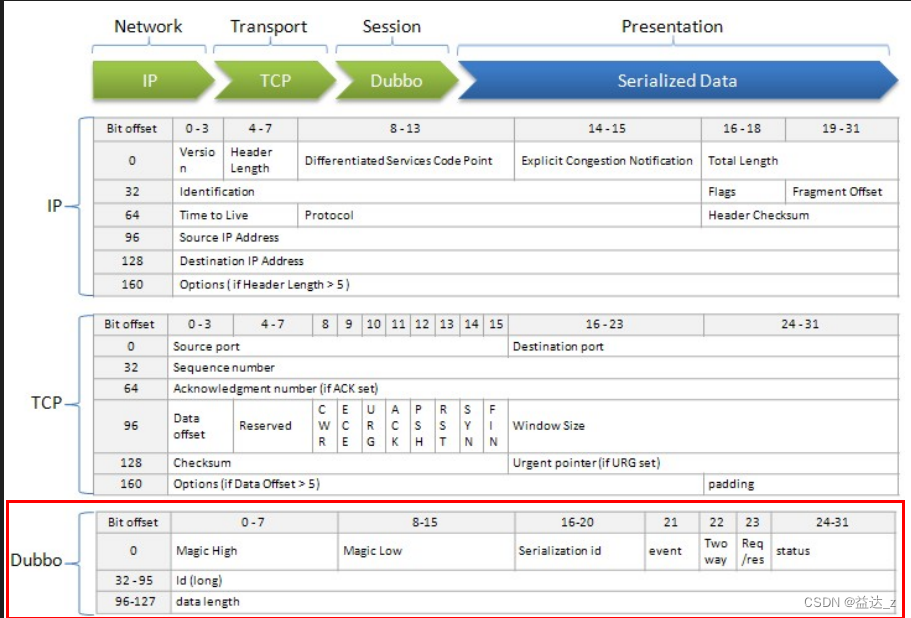 0-15表示dubbo协议标识。
0-15表示dubbo协议标识。
serialization id:表示序列化方式(jdk,json,protobuf等),只需用5位标志位表示,而不像http需要在header声明一长串字符来标识。
event:事件标识,0表示数据包是请求或响应 1表示数据包是心跳包。
Req/res: 0表示响应 1表示请求。
TwoWay:表示调用方式 0表示单向调用 1表示双向调用
id:表示请求id,设计请求id,可以一次发送多个请求,响应的时候通过返回请求id来匹配是哪个请求。而不用像http1.x协议一样只能等一个请求响应后才能发送第二个请求。
dubbo协议在Dubbo框架内使用还是比较舒服的,并且dubbo协议相比于http1.x协议,性能会更好,因为请求中没有多余的无用的字节,都是必要的字节,并且每个Dubbo请求和响应中都有一个请求ID,这样可以基于一个Socket连接同时发送多个Dubbo请求,不用担心请求和响应对不上,所以dubbo协议成为了Dubbo框架中的默认协议。
总结:dubbo协议传输数据少,性能更好,且能同时发送多个请求。
http2协议
a.http1缺点是数据比较冗余、请求头无法压缩且不支持stream(即不支持多次发送/接收),http2优化了这两方面。
HTTP1协议的这种格式,缺点也是很明显的(即数据冗余,请求头无法压缩):
- 额外占用了很多字节,比如众多的回车符、换行符,它们都是字符,都需要一个字节
- 大头儿子,通常一个HTTP1的请求,都会携带各种请求头,我们可以通过请求头来指定请求体的压缩方式,但是我们没有地方可以指定请求头的压缩方式,这样就导致了大头儿子的存在。
b.为了解决这两个严重影响性能的问题,HTTP2(triple协议基于http2,grpc协议也基于http2)出来了,你不就是要发送请求行、请求头、请求体吗,那HTTP2这么来设计,HTTP2设计了帧的概念(包含了Frame Header和Frame Payload)。
c.http2协议格式
 1. 帧长度,用三个字节来存一个数字,这个数字表示当前帧的实际传输的数据的大小,3个字节表示的最大数字是2的24次方(16M),所以一个帧最大为9字节+16M。
1. 帧长度,用三个字节来存一个数字,这个数字表示当前帧的实际传输的数据的大小,3个字节表示的最大数字是2的24次方(16M),所以一个帧最大为9字节+16M。
2. 帧类型,占一个字节,可以分为数据帧和控制帧
a. 数据帧又分为:HEADERS 帧和 DATA 帧,用来传输请求头、请求体的
b. 控制帧又分为:SETTINGS、PING、PRIORITY,用来进行管理的
3. 标志位,占一个字节,可以(说明不只表示是否最后一帧还可以用来表示其它含义)用来表示当前帧是整个请求里的最后一帧,方便服务端解析
4. 流标识符,占4个字节,在Java中也就是一个int,不过最高位保留不用,表示Stream ID(用于标识这个帧属于哪个stream,streamId和帧是一对多的关系,即一个流可以包含多个帧),这也是HTTP2的一个重要设计。
5. 实际传输的数据Payload,如果帧类型是HEADERS,那么这里存的就是请求头,如果帧类型是DATA ,那么这里存的就是请求体(意思是HEADERS 帧和 DATA 帧分开发送)。
既然标志位表示是否是最后一帧,用1bit:0或1表示不就可以了嘛,为啥要用1个字节?
因为这个标志位不只表示当前帧是否为最后一帧,还包含其它。
d.先发请求头,再发请求体。
e.客户端在发送数据帧之前会发送控制帧给服务端,此时服务端/客户端会生成
StreamObserver,每个StreamObserver中包含了唯一的streamid。客户端就会通过这个
StreamObserver来向服务端发送数据帧。42:00
f.http2 是一个二进制协议,一般将传输内容分为一个 HEADERS 帧和多个 DATA 帧。
g.如何保证一个stream中发多个DATA帧的顺序?这个不是由HTTP2来控制的,是由TCP来保证的,TCP中有机制可以保证数据的顺序。
h.onNext表示发送一帧数据(DATA帧),onComplete表示发送结束。
dubbo、triple底层用的是netty。所以triple他不只是一个协议,他也是一个封装了netty的框架,但他又不是和dubbo单独起来的框架,triple属于dubbo的一个子模块(代码在dubbo-rpc-triple)。所以onNext、onComplete的代码是在dubbo的dubbo-rpc-triple中。
i.通过这种设计(header和data单独作为一帧),我们可以发现,我们就可以来压缩请求头了,比如如果帧的类型是HEADERS ,那就进行压缩,当然压缩算法是固定的HPACK算法,不能更换。
j.如果仅仅是新增了能压缩请求头、压缩了请求体,那还不至于说HTTP2性能高,HTTP2最优秀
的地方在于支持Stream(triple基于http2,所以triple支持stream)。
k.上面可以看到每个帧里有一个流标识符,表示Stream ID,这是HTTP2的新特性,表示一个“虚拟流”,达到的效果是,我们可以在一个TCP连接中,同时维护多个Stream,每一个帧都是属于某一个Stream,一个Stream可以包含多个帧。
l.一个stream只有一个streamid。每个streamid只能标识一个请求,包含请求头,请求体,请求响应。
如果现在有一个客户端,想向服务端发送三个请求,如果你只建了一个Stream,那么你仍然只能:
发送请求1–>接收响应1–>发送请求2–>接收响应
2–>发送请求2–>接收响应2。
但是如果你建了三个Stream,那么你就可以开三个线程,同时把这三个请求分别发送到不同的Stream中去,这样服务端那么也会分别从三个Stream中获取到不同的请求进行处理,然后把响应结果也发送到对应的Stream中被客户端接收
到,这样就极大的提高了并发。
即一个stream只有一个streamid。每个streamid只能标识一个请求,包含请求头,请求体,请求响应。
m.HTTP2客户端/服务端作业流程
HTTP2客户端发送一个请求流程
- 新建一个TCP连接(三次握手)
- 新建一个Stream(在客户端新建),生成一个新的StreamID,生成一个控制帧,帧里记录了前面生成出来的StreamID,通过TCP连接发送出去
- (发送请求头)生成一个要发送的请求对应的HEADERS 帧,用来发送请求头,也是key:value的格式,先利用ascii进行编码,然后利用HPACK算法进行压缩,最终把压缩之后的字节存在帧中的Payload区域,记录好StreamID,最后通过TCP连接把这个HEADERS 帧发送出去。
- (发送请求体)最后把要发送的请求体数据按指定的压缩算法(请求中所指定的压缩算法,比如gzip)进行压缩,把压缩之后的字节生成DATA帧,记录好StreamID,通过TCP连接把DATA 帧发送出去。
客户端和服务端建立连接后,会先发送连接前言,表示使用的是http2协议。
HTTP2服务端
- 会不断的从TCP连接接收到某些帧。
- 当接收到一个控制帧时,表示客户端要和服务端新建一个Stream,在服务端记录一下StreamID(这个streamId是客户端传过来的),比如在Dubbo3.0的源码中会生成一个ServerStreamObserver的对象
- 当接收到一个HEADERS 帧,取出StreamID,找到对应的ServerStreamObserver对象,
并解压得到请求头,把请求头信息保存在ServerStreamObserver对象中 - 当接收到一个DATA 帧时,取出StreamID,找到对应的ServerStreamObserver对象,根据请求头的信息看如何解压请求体(为啥请求头不用看如何解压,因为请求头压缩算法是固定的,解压也是固定),解压之后就得到了原生了请求体数据,然后按业务逻辑处理请求体
- 处理完了之后,就把结果也生成HEADERS 帧和DATA 帧时发送客户端,客户端此时就变成了服务端,来处理响应结果。
- 客户端接收到响应结果的HEADERS 帧,是也先解压得到响应头,记录响应体的解压方式
- 然后继续接收到响应结果的DATA 帧,解压响应体,得到原生的响应体,处理响应体
对于Triple协议而言,我们主要理解HTTP2中的Stream、HEADERS 帧、DATA帧就可以了。
–
dubbo协议虽好,但是不够通用,所以这就出现了Triple协议,Triple协议更通用
1.dubbo协议一旦涉及到跨RPC框架,比如一个Dubbo服务要调用gPRC服务,就比较麻烦了,因为发一个dubbo协议的请求给一个gPRC服务,gPRC服务只会按照gRPC的格式来解析字节流,最终肯定会解析不成功的。
2.Triple协议是基于HTTP2,没有性能问题,另外HTTP协议非常通用,全世界都认它,兼容起来也比较简单,而且还有很多额外的功能,比如流式调用。
Triple协议是基于Http2协议的,也就是在使用Triple协议发送数据时,会按HTTP2协议的格式来发送数据,而HTTP2协议相比较于HTTP1协议而言,HTTP2是HTTP1的升级版,完全兼容HTTP1,而且HTTP2协议从设计层面就解
决了HTTP1性能低的问题。
3.总结:dubbo协议不够通用,不好跨RPC框架通信。而Triple协议更通用,因为Triple协议是基于HTTP2。HTTP2比HTTP1.X性能高多了,并且兼容了grpc(因为grpc基于http2),还支持流式调用(可以不断接收/发送多次数据)。
rest协议都是基于http1.x。
triple、grpc基于http2。triple借鉴了grpc。
Google公司开发的gRPC,也基于的HTTP2,目前gRPC是云原生事实上协议标准,包括k8s/etcd等都支持gRPC协议。
triple、dubbo、rest三个协议对比
1.triple协议基于的是HTTP2,rest协议目前基于的是HTTP1,都可以做到跨语言。
2.triple协议兼容了gPRC(Triple服务可以直接调用gRPC服务,反过来也可以),rest协议不行。triple协议支持流式调用,rest协议不行
3.rest协议更方便浏览器、客户端直接调用,triple协议不行(原理上支持,当得对triple协议的底层实现比较熟悉才行,得知道具体的请求头、请求体是怎么生成的)
4.dubbo协议是Dubbo3.0之前的默认协议,triple协议是Dubbo3.0之后的默认协议,优先用
Triple协议
5.dubbo协议不是基于的HTTP,不够通用,triple协议底层基于HTTP所以更通用(比如跨语言、跨异构系统实现起来比较方便)
6.dubbo协议不支持流式调用
Triple协议的流式调用(只有Triple协议才有,dubbo没有,类似rxjava stream)
分UNARY、SERVER_STREAM、BI_STREAM三种模式,下面会讲到。
dubbo、triple底层用的是netty。rest用的是jetty。
grpc协议(会自动生成接口和相关类代码,只需声明protobuf(类似aidl),让我们少写代码,另外不会出现无法sleep的bug)
1.grpc优势:triple协议有个bug,按道理说下面的Consumer是先收到结果1再收到结果2和3的,但是这里是等过了3秒后结果1,2,3才被收到。而grpc就没有这个bug。另外grpc定义了protobuf之后帮我们实现的方法更加方便调用,可以少写代码。另一方面,定义了protobuf后,protobuf编译器会帮我们生成接口和相关类,这样就不可以不用去引用common包,不用去维护common包。
2.grpc需要声明protobuf,声明protobuf文件后对应的java文件会自动生成(类似aidl的使用)。
3.Dubbo3.0跨语言调用
这就需要用到protobuf接口定义语言,protobuf编译器可以将接口编译为特定语言
4.grpc调用分阻塞调用和非阻塞调用,非阻塞调用是利用StreamObserver来处理。
5.protobuf不仅是一种协议,也是一种序列化方式,通过这种序列化方式传输的数据可以节省很多。具体自己看资料。
比如可以不用像jdk序列化一样需要传字段名和值。下面的1,2表示字段的序号。
Triple与gRPC互通(Triple服务可以直接调用gRPC服务)
因为tri兼容了grpc,兼容的意思是,tri协议在发送请求和发送响应时,都是按照grpc的格式来发送的,比如在请求头和响应头中设置grpc能识别的信息。
dubbo3.0服务注册与引入原理
dubbo接口级\应用级注册(即怎么将dubbo服务的数据存到zookeeper)
接口级注册格式:接口名1:tri://192.168.65.221:20880/接口名1?application=应用名
应用级注册格式:应用名:192.168.65.221:20880
但是这种方式怎么知道这个应用有哪些服务?
对于这个问题,在进行服务导出的过程中,会在Zookeeper中存一个映射关系,在服务导出的最后一步,在ServiceConfig的exported()方法中,会保存这个映射关系:
这个映射关系存在Zookeeper的/dubbo/mapping目录下,存了这个信息后,就知道这个应用有哪些服务了。
dubbo接口级注册是指:比如集群中一个应用有三个实例,那么zookeeper的相应服务的providers目录下面就会存在3条记录,这3条记录只是ip不一样,但是服务名是一样的。这就叫接口级注册。
应用级注册(只在zookeeper存ip和端口)就是应用/微服务的注册。随着服务的增加,zookeeper中的数据节点会增加,但是不会给应用增加数据节点。
应用级注册是dubbo3.0才有
3.0之前dubbo服务采用的是接口级注册
Dubbo3.0之后版本,由于需要兼容之前的版本,除了会进行应用级注册,同时也默认也会进行上面的接口级注册。
register-mode
1.all表示既会进行接口级也会进行应用级
2.instance表示只进行应用级注册
3.interface表示只进行接口级注册
应用级注册不是指为微服务在zk生成节点数据,而是为dubbo服务生成节点数据,需要区别开来。
应用级注册实例port不是指server port。而是dubbo服务协议(dubbo,tri,rest)端口,如果支持多个协议就取第一个端口。比如下面的20880。
A.如果只有ip:port信息且只取第一个协议的端口,那怎么去区别多个服务(接口),怎么知道有哪些服务?怎么去区别多个服务(接口)?
(这个是上面的“但是这种方式怎么知道这个应用有哪些服务?”的补充)
1.每个服务都会被包装成MetadataInfo对象,然后在应用及注册的时候会把这些MetadataInfo信息作为key为ip:port的value,然后存到元数据中心(即存到元数据中心,而不是注册中心)。当消费者去查找是否有某个服务,就从value中查找即可。
2.dubbo3.0应用级注册是将服务/接口信息存到元数据中心的,而微服务springcloud是将服
务/接口信息存到注册中心的。
3.在Dubbo2.7中就有了元数据中心,它其实就是用来减轻注册中心的压力的,Dubbo会把服务信息完整的存一份到元数据中心。元数据中心也可以用Zookeeper来实现,在暴露完元数据服务之后,在注册实例信息到注册中心之前,就会把MetadataInfo存入元数据中心。
4.元数据中心保存服务各协议的信息
5.注册中心和元数据中心是不一样的,可以对两者进行地址的配置。
6.但是默认情况下元数据是不存到元数据中心,需要上面的配置才会存到元数据中心,如果不
配置就会存到provider本地,同时本地会暴露一个元数据服务给消费者去调用,并且这个元
数据服务的协议为dubbo协议。
这个元数据服务是接口级注册。
通过metadata-type来配置是将元数据信息存到元数据中心还是本地。
a.remote:存到元数据中心
b.local:存到本地
7.这个端口只是用来生成key的,这个端口会优先使用dubbo协议的端口来生成key,不表示我
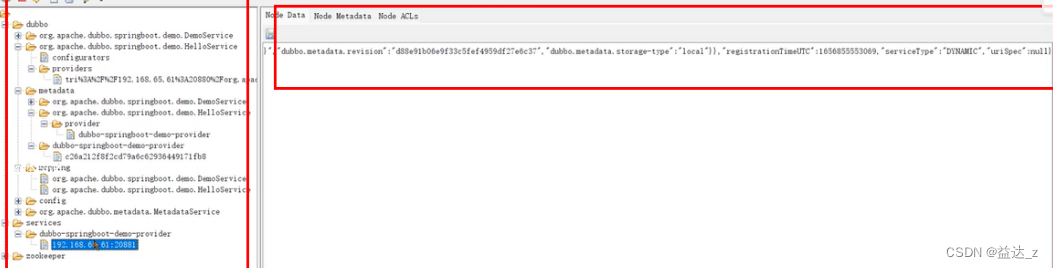
们在以某个协议调用provider就会使用这个实例名称端口,具体要调用哪个端口是要根据右边实例信息的dubbo.endpoints字段。(右边实例信息看笔记)
右边为实例的信息,而不是元数据信息,这里面有个dubbo.metadata.storagetype=local,意思是告诉消费者需要从服务提供者本地去获取元数据,而不是从注册中心
获取。所以消费者获取元数据信息之前需要去获取解析实例信息。
8.元数据中心只有dubbo会用到。
B.如果不使用dubbo协议,而是使用了其它多个协议,比如使用了rest,tri协议,那么会取url为第一个的端口,而不是去properties文件中配置的第一个协议的端口
应用级注册流程总结:
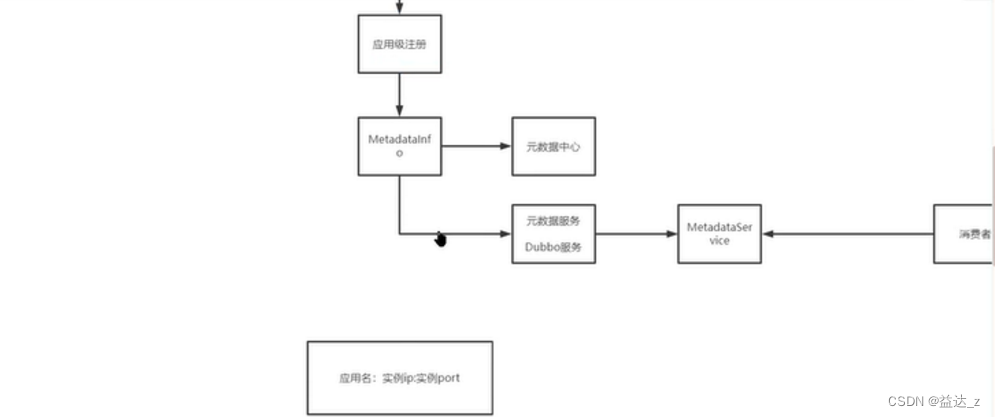 应用级注册的目的是最终将
应用级注册的目的是最终将
应用名:192.168.65.221:20880及对应的实例信息存到注册中心,即下面的位置
 在注册进来前需要将元数据信息MetadataInfo存储到元数据中心/本地(可配置从哪获取,默认是本地,将元数据存到本地)供消费者调用。
在注册进来前需要将元数据信息MetadataInfo存储到元数据中心/本地(可配置从哪获取,默认是本地,将元数据存到本地)供消费者调用。
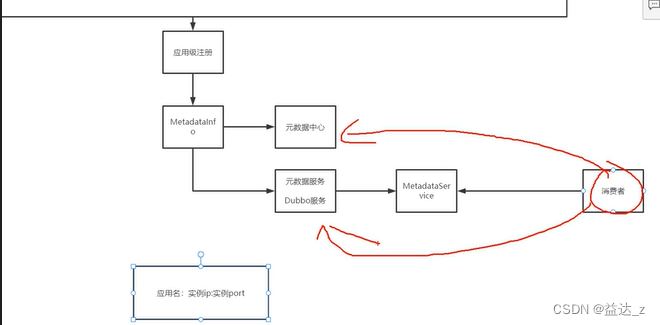 对于消费者而言,是通过mapping接口名找到应用名,再通过应用名从services中找到实例ip+port,然后找到实例信息,然后从实例信息中找到元数据信息进行调用。
对于消费者而言,是通过mapping接口名找到应用名,再通过应用名从services中找到实例ip+port,然后找到实例信息,然后从实例信息中找到元数据信息进行调用。

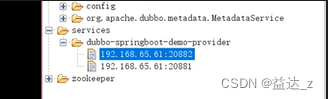
 services中,左边的dubbo-springboot-demo-provider为应用名称,192.168…:20881为服务实例,名称由ip及协议的端口组成,注意这个端口只是用来生成key的,这个端口会优先使用dubbo协议的端口来生成key,不表示我们在以某个协议调用provider就会使用这个实例名称端口,具体要调用哪个端口是要根据右边实例信息的dubbo.endpoints字段。
services中,左边的dubbo-springboot-demo-provider为应用名称,192.168…:20881为服务实例,名称由ip及协议的端口组成,注意这个端口只是用来生成key的,这个端口会优先使用dubbo协议的端口来生成key,不表示我们在以某个协议调用provider就会使用这个实例名称端口,具体要调用哪个端口是要根据右边实例信息的dubbo.endpoints字段。
 元数据中心数据、应用级/接口级注册数据、zk注册中心数据数据的目录结构
元数据中心数据、应用级/接口级注册数据、zk注册中心数据数据的目录结构
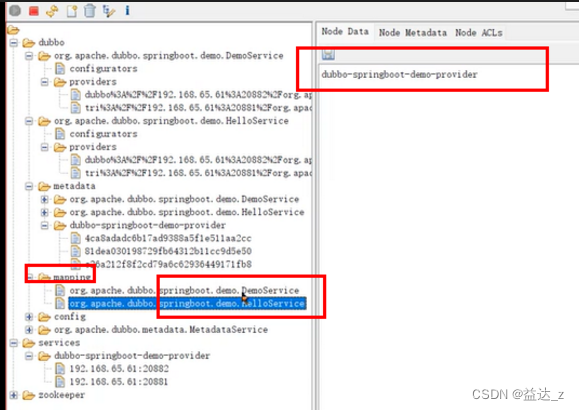
mapping目录下的信息表示服务名(接口名)所对应的应用
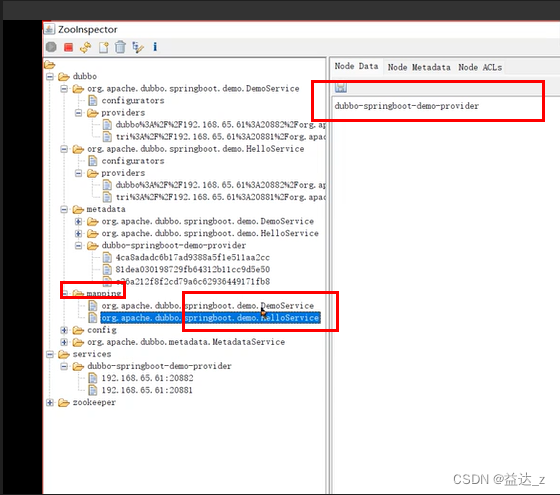 providers目录下的信息为接口级注册的内容
providers目录下的信息为接口级注册的内容
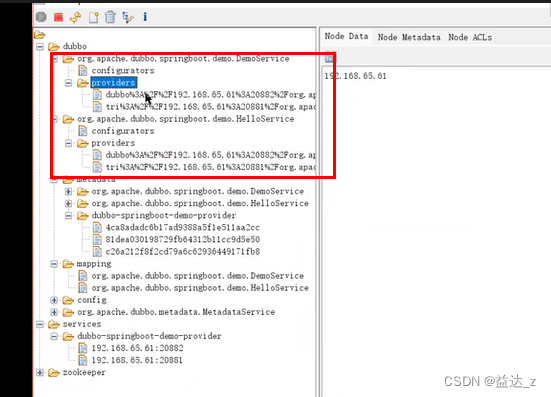 可以看到:
可以看到:
1.元数据中心的信息在dubbo/metadata节点下
2.应用级注册dubbo服务接口对应的应用关系存在/dubbo/mapping目录下。
/services/应用名目录存放的是当前应用的各实例信息。
里面的每个实例会指定元数据信息(ip 端口 支持的协议)需要从哪获取,是需要在本地获取还是直接从元数据中心获取。如果是在该dubbo服务其本地获取,则会调用该dubbo服务的元数据服务进行获取。
3.接口级注册信息存放在:/dubbo/服务接口名/providers/节点下
4.微服务的注册信息在zookeeper节点下
元数据中心数据也是存放在zookeeper的,从下面的配置可以看出。
registry:
address:zookeeper://127.0.0.1:2181
metadata-report:
address:zookeeper://127.0.0.1:2181
所以可以看到zooInspector包含了元数据信息和zookeeper节点信息。
当然也可以把元数据中心的地址和注册中心的地址配置成不一样。这样“元数据dubbo节点”和“zookeeper节点”就存放在不同的zookeeper下。
Dubbo3.0为什么要改成应用级注册?
因为如果按照dubbo3.0之前的版本,采用的是接口级注册,如果集群中一个服务提供者变了或增加了,需要修改的节点是非常多的,需要耗费提供者和消费者一定的性能去更新节点数据。所以就需要改成应用级注册这种方式(只在zookeeper存ip和端口)。
Dubbo3.0之前版本服务注册的流程是怎样的,怎么个接口级注册法(怎么将服务信息数据存
到zookeeper)?
只要协议,ip,端口有一个不一样都会当作是不同的url,然后将每个url进行注册
元数据信息变更后消费者本地缓存如果更新?
通过监听zk实例节点(watch机制,之前讲zookeeper有讲过),来监听元数据信息是否有更
新,因为如果dubbo服务更改的时候会重启,此时zk实例就会进行变动。
**消费者在引入服务的时候,可以设置check属性,默认为true。**表示在启动时候会进行一些
校验判断,比如判断提供者provider服务有启动成功才行等。false表示消费者程序启动时不进行校验,就算provider没有启动,消费者程序也能启动成功等,等消费者程序启动成功后真正调用服务时才去判断provider服务是否可用等。
假设一个应用有两个实例,一个实例提供者用的是dubbo2.7版本,一个实例用的是3.0版本。那么消费者引入服务的时候既要获取2.7版本的服务也需要获取3.0版本的服务。
可以通过在消费者配置migration.step属性来声明需要获取哪个版本的提供者服务:
1.FORCE_INTERFACE:表示只获取(引入)接口级注册的服务信息。
2.APPLICATION_FIRST:表示会先将接口级和应用级信息引入进来,然后对比判断使用哪
个,优先使用应用级注册。
3.FORCE_APPLICATION:表示只获取(引入)应用级注册的服务信息。
相关类是MigrationInvoker
对于APPLICATION_FIRST,会先将接口级和应用级信息引入进来,然后进行对比(调用
calcPreferredInvoker方法),如果判断应用级注册的信息比注册级信息多就会使用应用级
的提供者信息,否则使用接口级提供者信息。
dubbo3.0服务导出和引入总结
1.不管是服务导出还是服务引入,都发生在应用启动过程中。
比如当我们在启动类上加上@EnableDubbo时,该注解上有一个@DubboComponentScan注解,@DubboComponentScan注解Import了一个DubboComponentScanRegistrar,DubboComponentScanRegistrar中会调用DubboSpringInitializer.initialize(),该方法中会注册一个DubboDeployApplicationListener,而DubboDeployApplicationListener会监听Spring容器启动完成事件ContextRefreshedEvent,一旦接收到这个事件后,就会开始Dubbo的启动流程,就会执行DefaultModuleDeployer的start()
进行服务导出与服务引入。
2.导出主要做的是:
为每个需要暴露的dubbo服务封装成一个ServiceConfig对象,每个ServiceConfig对象表
示一个服务,这个对象包含了服务实现类、服务接口名、version…这些。
然后确定应用支持的协议,生成服务URL。比如服务3个,支持协议2种,则生成6个URL。
然后启动服务提供者server,然后如果是dubbo2.7则将url注册到注册中心,如果是
dubbo3.0则将url存入MetaDatanfo对象中(所有的url都是存到这个对象中,而不是每个url
都会new MetaDataInfo)。
当当前接口所有url都存入到MetadataInfo对象后,会将(接口名:应用名)存入元数据中心
mapping目录下,mapping目录下的信息表示服务名所对应的应用(上面讲过)。
以上都是导出所做的事。另外上面是导出某一个服务,如果有多个服务会进行多个服务的导
出操作。
3.导出和注册概念不太一样
服务导出主要是将dubbo服务进行封装(同时也会将接口名/服务名和应用的对应关系也会存到元数据中心),而应用级注册主要做的是,将导出封装的对象根据配置的属性进行处理,然后存到zookeeper中去。
比如会根据metadata-type这些属性进行处理。如果type为local,会导出元数据服务,并将元数据存到本地。如果type为remote会将元数据存到元数据中心。
4.在做完服务导出与服务引入后,还会做几件非常重要的事情,即应用级注册。
(即注册是在导出和导入后执行的)
应用级注册:
a.导出一个应用元数据服务(就是一个MetadataService服务,这个服务也会注册到注册中心,后面会分析它有什么用),或者将应用元数据注册到元数据中心
b.生成当前应用的实例信息对ServiceInstance,比如应用名、实例ip、实例port,并将实例信息注册到注册中心
5.服务引入主要做的是
先将每个@DubboReference包装成一个ReferenceConfig。然后调用get方法,表示想要
得到当前接口的代理对象(所以服务引入就是为了得到代理对象),在代理对象中会生成一
个MigrationInvoker对象,在MigrationInvoker对象中会根据migration-step属性来确定
引入哪些服务信息(上面有讲过这个属性)。
a.FORCE_INTERFACE:表示只获取(引入)接口级注册的服务信息。
b.APPLICATION_FIRST(默认):表示会先将接口级和应用级信息引入进来,然后对比判断使
用哪个,优先使用应用级注册。
c.FORCE_APPLICATION:表示只获取(引入)应用级注册的服务信息。
3.0版中,如果配置了两个dubbo的协议,且为应用级注册,最终消费者只会使用一个端口,算是一个bug。2.7版本(接口级注册)就不会或是版本为3.0但是为接口级注册,会使用负载均衡,循环使用两个端口。
另外还有一个bug,如果配置了2个tri协议,就算是接口级注册,也只会使用一个端口。
Dubbo3.0中的服务调用底层原理
Triple的底层原理分析(数据帧机制)
就是因为HTTP2中的数据帧机制(设计了streamId,支持多次发送接收数据),Triple协议才能支持UNARY、SERVER_STREAM、BI_STREAM三种模式。
UNARY、SERVER_STREAM、BI_STREAM三种模式。
- UNARY:就是最普通的,服务端只有在接收到完整请求包括的所有的HEADERS(一个请求只发一个header帧)帧和DATA帧之后(通过调用onCompleted()发送最后一个DATA帧),才会处理数据,客户端也只有接收完响应包括的所有的HEADERS帧和DATA帧之后,才会处理响应结果。
- SERVER_STREAM:服务端流,特殊的地方在于,服务端在接收完请求包括的所有的DATA帧之后,才会处理数据,不过在处理数据的过程中,可以多次发送响应DATA帧(第一个DATA帧发送之前会发送一个HEADERS帧),客户端每接收到一个响应DATA帧就可以直接处理该响应DATA 帧,这个模式下,客户端只能发一次数据,但能多次处理响应DATA帧。(目前有Bug,gRPC的效果是正确的,Dubbo3.0需要异步进行发送,之前讲过)
- BI_STREAM:双端流,或者客户端流,特殊的地方在于,客户端可以控制发送多个请求DATA帧(第一个DATA帧发送之前会发送一个HEADERS帧),服务端会不断的接收到请求DATA帧并进行处理,并且及时的把处理结果作为响应DATA帧发送给客户端(第一个DATA帧发送之前会发送一个HEADERS帧),而客户端每接收到一个响应结果DATA帧也会直接处理,这种模式下,客户端和服务端都在不断的接收和发送DATA帧并进行处理,注意请求HEADER帧和响应HEADERS帧都只发了一个。
客户端:Triple请求调用和响应处理
(triple基于netty,所以这里相当于分析triple框架netty部分的源码)
A.创建一个Stream的前提是先得有一个Socket连接,所以我们得先知道Socket连接是在哪创建的。
在服务提供者进行服务导出时,会按照协议以及对应的端口启动Server,比如Triple协议就会启动Netty并绑定指定的端口,等待Socket连接。
在服务消费者进行服务引入的过程中,会生成TripleInvoker对象,在构造TripleInvoker对象的构造方法中,会利用ConnectionManager创建一个Connection对象,而Connection对象中包含了一个Bootstrap对象(Netty中用来建立Socket连接的),不过以上都只是创建对象,并不会真正和服务去建立Socket连接,所以在生成TripleInvoker对象过程中不会真正去创建Socket连接,那什么时候创建的呢?
当我们在服务消费端执行以下代码时:
demoService.sayHello(“zzz”)
demoService是一个代理对象,在执行方法的过程中,最终会调用TripleInvoker的doInvoke()方法,在doInvoke()方法中,会利用Connection对象来判断Socket连接是否可用,如果不可用并且没有初始化,那就会创建Socket连接。
一个Connection对象就表示一个Socket连接,在TripleInvoker对象中也只有一个Connection对象,也就是一个TripleInvoker对象只对应一个Socket连接,这个和DubboInvoker不太一样,一个DubboInvoker中可以有多个ExchangeClient,每个ExchangeClient都会与服务端创建一个Socket连接,所以一个DubboInvoker可以对应多个Socket连接,当然多个Socket连接的目的就是提高并发,不过在TripleInvoker对象中就不需要这么来设计了,因为可以Stream机制来提高并发。
以上,我们知道了,当我们利用服务接口的代理对象执行方法时就会创建一个Socket连接,就算这个代理对象再次执行方法时也不会再次创建Socket连接了,值得注意的是,有可能两个服务接口对应的是一个Socket连接,举个例子。
比如服务提供者应用A,提供了DemoService和HelloService两个服务,服务消费者应用B引入了这两个服务,那么在服务消费者这端,这个两个接口对应的代理对象对应的TripleInvoker是不同的两个,但是这两个TripleInvoker会公用一个Socket连接,因为ConnectionManager在创建Connection对象时会根据服务URL的address进行缓存,后续这两个代理对象在执行方法时使用的就是同一个Socket连接,但是是不同的Stream。
总结:
一个TripleInvoker对象只对应一个Socket连接,一个DubboInvoker可以对应多个Socket连接。
ConnectionManager在创建Connection对象时会根据服务URL的address进行缓存。
B.Socket连接创建好之后,就需要发送Invocation对象给服务提供者了,因为是基于的HTTP2,所以要先创建一个Stream,然后再通过Stream来发送数据。
TripleInvoker中用的是Netty,所以最终会利用Netty来创建Stream,对应的对象为Http2StreamChannel,消费端的TripleInvoker最终会利用Http2StreamChannel来发送和接收数据帧,数据帧对应的对象为Http2Frame,它又分为Http2DataFrame、Http2HeadersFrame等具体类型(数据帧分为:HEADERS 帧和 DATA 帧,每个数据帧都有frame header和framepayload看面)。
正常情况下,每生成一个数据帧就会通过Http2StreamChannel发送出去,但是在Triple中有一个小小的优化,会有一个批量发送的思想,当要发送一个数据帧时,会先把数据帧放入一个WriteQueue中,然后会从线程池中拿到一个线程调用WriteQueue的flush方法,该方法的实现看笔记。
C.总体思想是,只要向WriteQueue中添加一个数据帧之后,那就会尝试开启一个线程,要不要开启线程要看CAS是否成功,成功的线程会负责从线程池中获取另外一个线程执行上面的flush方法,从而获取WriteQueue中的数据帧然后发送出去。
有了底层这套设计之后,对于TripleInvoker而言,它只需要把要发送的数据封装为数据帧,然后添加到WriteQueue中就可以了。
D.在TripleInvoker的doInvoke()源码中,在创建完成Socket连接后,就会(开始进行rpc调用,传入rpc需要传的数据):
- 基于Socket连接先构造一个ClientCall对象
- 根据当前调用的方法信息构造一个RequestMetadata对象,这个对象表示,当前调用的是哪个接口的哪个方法,并且记录了所配置的序列化方式,压缩方式,超时时间等
- 紧接着构造一个ClientCall.Listener,这个Listener是用来处理响应结果的,针对不同的流
式调用类型,会构造出不同的ClientCall.Listener:
a. UNARY:会构造出一个UnaryClientCallListener,内部包含了一个DeadlineFuture,DeadlineFuture是用来控制timeout的
b. SERVER_STREAM:会构造出一个ObserverToClientCallListenerAdapter,内部包含了调用方法时传入进来的StreamObserver对象,最终就是由这个StreamObserver对象来处理响应结果的
c. BI_STREAM:和SERVER_STREAM一样,也会构造出来一
ObserverToClientCallListenerAdapter - 紧着着,就会调用ClientCall对象的start方法创建一个Stream(是一个逻辑结构),并且返回一个StreamObserver对象
- 得到了StreamObserver对象后,会根据不同的流式调用类型来使用这个StreamObserver
对象
a. UNARY:直接调用StreamObserver对象的onNext()方法来发送方法参数,然后调用
onCompleted方法,然后返回一个new AsyncRpcResult(future, invocation),
future就是DeadlineFuture,后续会通过DeadlineFuture同步等待响应结果的到来,并最终把获取到的响应结果返回给业务方法。
b. SERVER_STREAM:直接调用StreamObserver对象的onNext()方法来发送方法参数,
然后调用onCompleted方法,然后返回一个new
AsyncRpcResult(CompletableFuture.completedFuture(new AppResponse()), invocation),后续不会同步了,并且返回null给业务方法。
c. BI_STREAM:直接返回new
AsyncRpcResult(CompletableFuture.completedFuture(new
AppResponse(requestObserver)), invocation),也不会同步等待响应结果了,而是直接把requestObserver对象返回给了业务方法。
RequestMetadata提供了构造请求头的方法,toHeader。
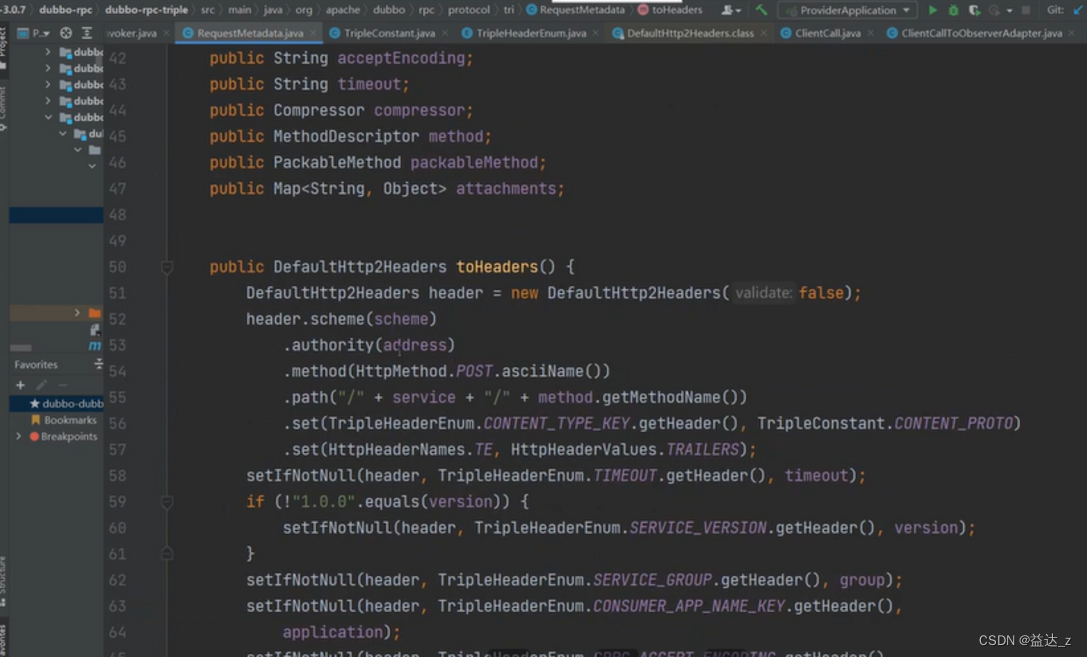 构造请求头的时候会设置一些grpc的相关配置,用于兼容grpc。
构造请求头的时候会设置一些grpc的相关配置,用于兼容grpc。
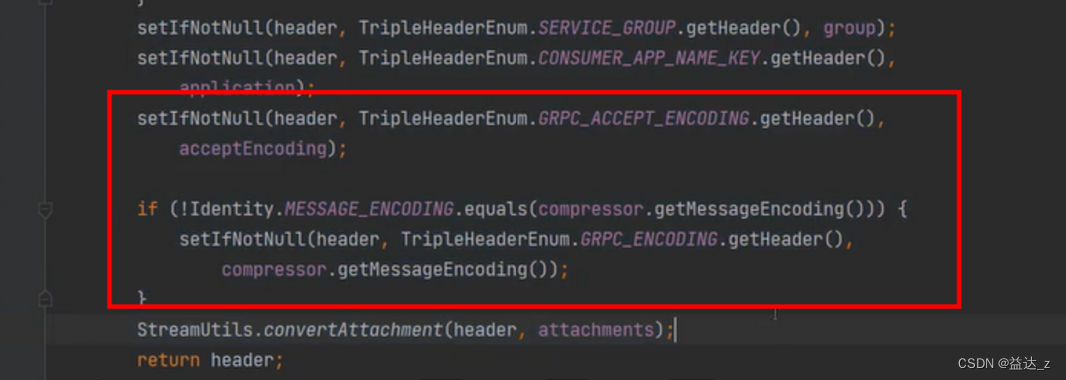 TripleInvoker发送data流程
TripleInvoker发送data流程
所以我们可以发现,不管是哪种流式调用类型,都会先创建一个Stream,得到对应的一个StreamObserver对象,然后调用StreamObserver对象的onNext方法来发送数据,比如发送服务接口方法的入参值,比如一个User对象:
- 在发送User对象之前,会先发送请求头,请求头中包含了当前调用的是哪个接口、哪个方法、版本号、序列化方式、压缩方式等信息,注意请求头中会包含一些gRPC相关的key(怎样的key),主要就是为了兼容gRPC。即请求的方法信息是放在HEADERS 帧,和http1一样。
- 然后就是发送请求体(即发送User对象),发送请求体细分为如下步骤:
2.1. 然后再对User对象进行序列化,得到字节数组
2.2. 然后再压缩字节数组
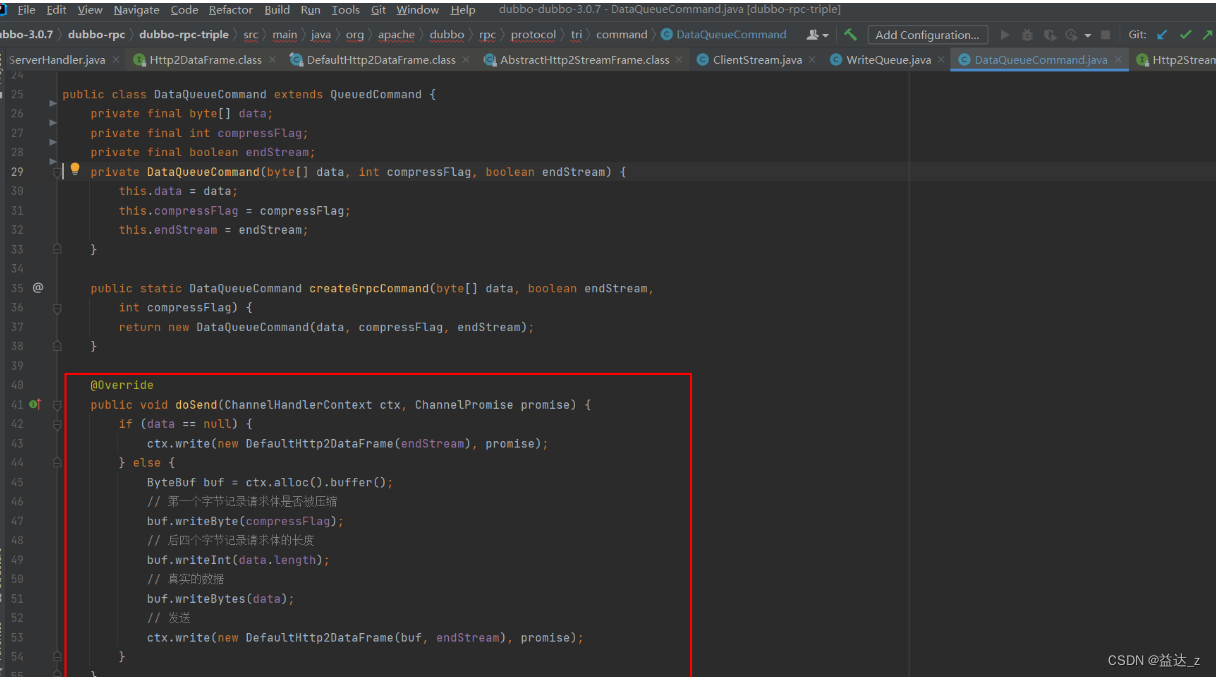
2.3. 然后把压缩之后的字节数组以及是否压缩的标记组装成一个DataQueueCommand对象,并且把这个对象添加到writeQueue中去,然后执行scheduleFlush(),该方法就会开启一个线程从writeQueue中获取数据进行发送,发送时就会触发DataQueueCommand对象的doSend方法进行发送,该方法中会构造一个DefaultHttp2DataFrame对象,该对象中有两个属性endStream,表示是不是Stream中的最后一帧,另外一个属性为content,表示帧携带的核心数据,该数据格式为:
a. 第一个字节记录请求体是否被压缩
b. 紧着的四个字节记录字节数组的长度
c. 后面就真正的字节数据
 从下面可以看出数据帧:HEADERS帧和DATA帧都有endStream属性。
从下面可以看出数据帧:HEADERS帧和DATA帧都有endStream属性。
 DataQueueCommand doSend方法
DataQueueCommand doSend方法
 以上是TripleInvoker发送数据的流程,接下来就是TripleInvoker接收响应数据的流程
以上是TripleInvoker发送数据的流程,接下来就是TripleInvoker接收响应数据的流程
TripleInvoker接收响应data流程
ClientCall.Listener就是用来监听是否接收到的响应数据的,不同的流式调用方式会对应不同的ClientCall.Listener:
a. UNARY:UnaryClientCallListener,内部包含了一个DeadlineFuture,DeadlineFuture是用来控制timeout的
b. SERVER_STREAM:ObserverToClientCallListenerAdapter,内部包含了调用方法时传入进来的
StreamObserver对象,最终就是由这个StreamObserver对象来处理响应结果的
c. BI_STREAM:和SERVER_STREAM一样,也会构造出来一ObserverToClientCallListenerAdapter
如何知道某个Stream中有响应数据,然后触发调用ClientCall.Listener对象的相应的方法?
A.要监听某个Stream中是否有响应数据,这个肯定时Netty来做的(所以这里边的接收响应逻辑肯定就是在handler中进行处理了),实际上,在之前创建Stream时,会向Http2StreamChannel绑定一个TripleHttp2ClientResponseHandler,很明显这个Handler就是用来处理接收到的响应数据的。
B.在TripleHttp2ClientResponseHandler的channelRead0方法中,每接收一个响应数据就会判断是Http2HeadersFrame还是Http2DataFrame,然后调用ClientTransportListener中对应的onHeader方法和onData方法:
- onHeader方法通过处理响应头,会生成一个TriDecoder(每次onHeader方法调用都会生成一个),它是用来解压并处理HEADERS帧响应体的。
- onData方法会利用TriDecoder的deframe()方法来处理DATA帧响应体。
C.另外如果服务提供者那边调用了onCompleted方法,会向客户端响应一个请求头,endStream为true,表示响应结束,也会触发执行客户端
transportListener.onHeader方法,从而会调用TriDecoder的close()方法。
TriDecoder的deframe()方法在处理响应体数据时,会分为两个步骤: - 先解析前5个字节,先解析第1个字节确定该响应体是否压缩了,再解析后续4个字节确定
响应体内容的字节长度。为什么取5个字节,因为上面发送的每个DefaultHttp2DataFrame
或DefaultHttp2HeaderFrame的数据格式为(上面有讲过):
a. 第一个字节记录请求体是否被压缩
b. 紧着的四个字节记录字节数组的长度
c. 后面就真正的字节数据 - 然后再取出该长度的字节作为响应体数据,如果压缩了,那就进行解压,然后把解压之后的字节数组传递给ClientStreamListenerImpl的onMessage()方法,该方法就会按对应的序列化方式进行反序列化,得到最终的对象,然后再调用到最终的UnaryClientCallListener或者ObserverToClientCallListenerAdapter的onMessage()方法。
D.TriDecoder的close()方法最终也会调用到UnaryClientCallListener或者ObserverToClientCallListenerAdapter的close()方法。
UnaryClientCallListener,构造它时传递了一个DeadlineFuture对象: - onMessage()接收到响应结果对象后,会把结果对象赋值给appResponse属性
- onClose()会取出appResponse属性记录的结果对象构造出来一个AppResponse对象,
然后调用DeadlineFuture的received方法,从而将方法调用线程阻塞,并得到响应结果对象。
即onClose()方法不是表示关闭socket。
E.ObserverToClientCallListenerAdapter,构造它时传递了一个StreamObserver对象: - onMessage()接收到响应结果对象后,会调用StreamObserver对象的onNext(),并把结果对象传给onNext()方法,从触发了程序员的onNext()方法逻辑。
- onClose()就会调用StreamObserver对象的onCompleted(),或者调用onError()方法F.responseObserver用于接收对端响应,程序员自己传进去的。
requestObserver用于向对端发送数据的。
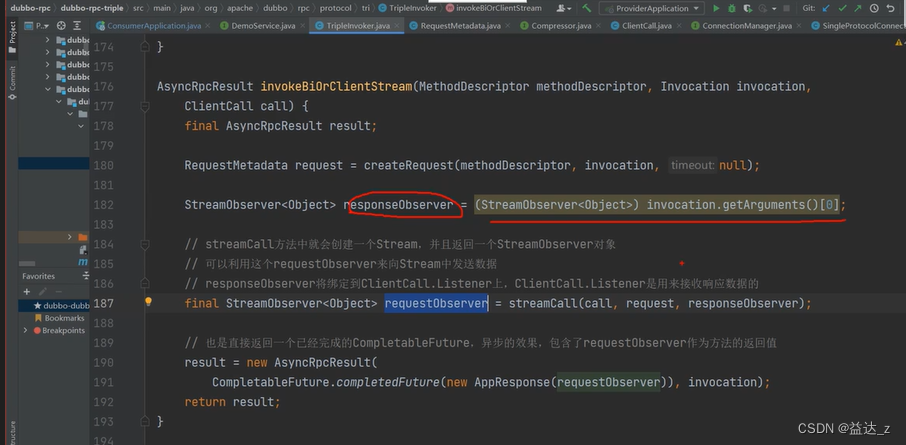
服务端:Triple请求处理和响应结果发送
其实这部分内容和发送请求和处理响应是非常类似的,无非就是把视角从消费端切换到服务端,前面分析的是消费端发送和接收数据,现在要分析的是服务端接收和发送数据。
消费端在创建一个Stream后,会生成一个对应的StreamObserver对象用来发送数据和一个ClientCall.Listener用来接收响应数据,对于服务端其实也一样,在接收到消费端创建Stream的命令后,也需要生成一个对应的StreamObserver对象用来响应数据以及一个ServerCall.Listener用来接收请求数据。
在服务导出时,TripleProtocol的export方法中会开启一个ServerBootstrap,并绑定指定的端口,并且最重要的是,Netty会负责接收创建Stream的信息,一旦就收到这个信号,就会生成一个ChannelPipeline,并给ChannelPipeline绑定一个TripleHttp2FrameServerHandler,而这个TripleHttp2FrameServerHandler就可以用来处理Http2HeadersFrame和Http2DataFrame。
A.比如在接收到请求头后,会构造一个ServerStream对象,该对象有一个
ServerTransportObserver对象,ServerTransportObserver对象就会真正来处
理请求头和请求体:
- onHeader()方法,用来处理请求头
a. 比如从请求头中得到当前请求调用的是哪个服务接口,哪个方法
b. 构造一个TriDecoder对象,TriDecoder对象用来处理请求体
c. 构造一个ReflectionServerCall对象并调用它的doStartCall()方法,从而生成不同的
ServerCall.Listener
i. UNARY:UnaryServerCallListener
ii. SERVER_STREAM:ServerStreamServerCallListener
iii. BI_STREAM:BiStreamServerCallListener
iv. 并且在构造这些ServerCall.Listener时会把ReflectionServerCall对象传入进去,
ReflectionServerCall对象可以用来向客户端发送数据。 - onData()方法,用来处理请求体,调用TriDecoder对象的deframe方法来处理请求体,如
果是endStream,那还会调用TriDecoder对象的close方法
B.TriDecoder: - deframe():这个方法的作用和客户端时一样的,都是先解析请求体的前5个字节,然后
解压请全体,然后反序列化得到请求参数对象,然后调用不同的ServerCall.Listener中的
onMessage() - close():当客户端调用onCompleted方法时,就表示发送数据完毕,此时会发送一个
DefaultHttp2DataFrame并且endStream为true,从而会触发服务端TriDecoder对象的
close()方法,从而调用不同的ServerCall.Listener中的onComplete()
C.UnaryServerCallListener: - 在接收到请求头时,会构造UnaryServerCallListener对象,没什么特殊的
- 然后接收到请求体时,请求体中的数据就是调用接口方法的入参值,比如User对象,那
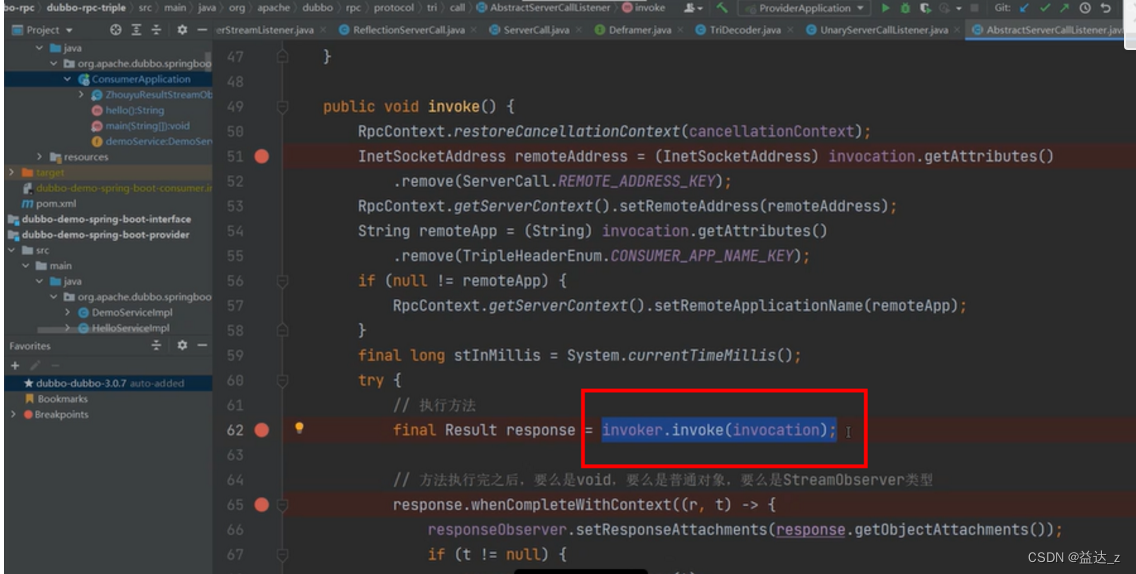
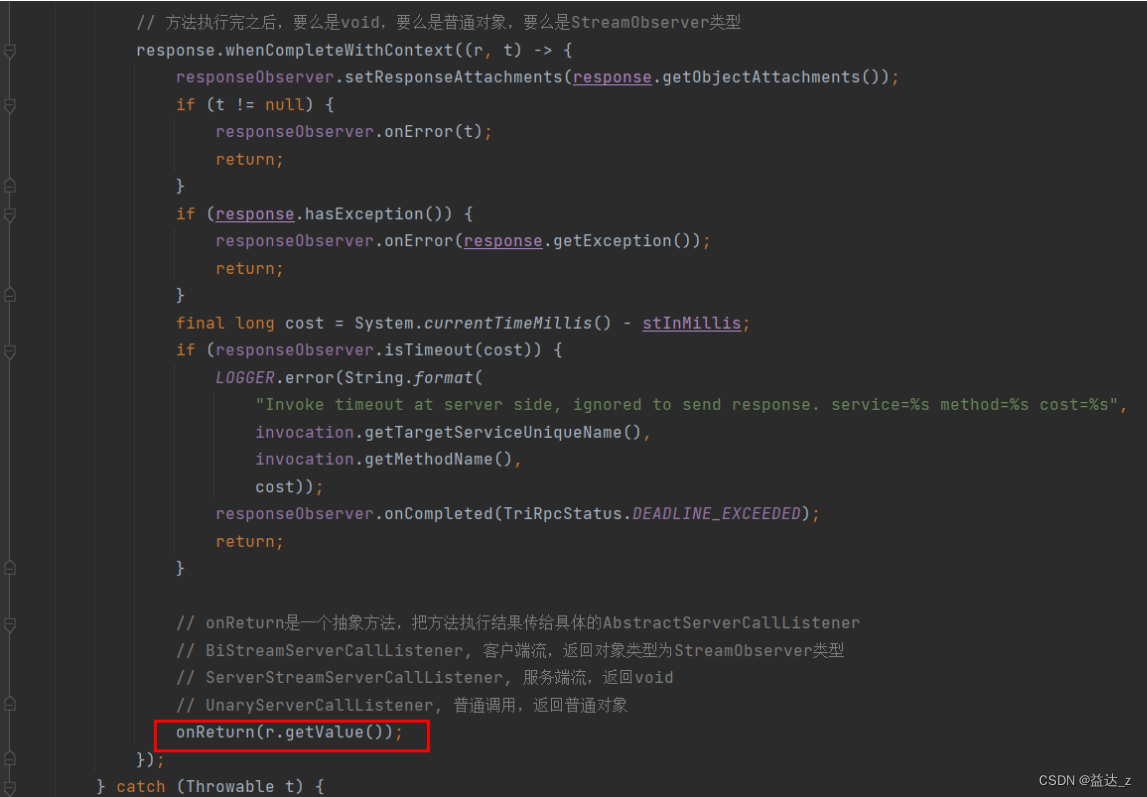
么就会调用UnaryServerCallListener的onMessage()方法,在这个方法中会把User对象设置到invocation对象中 - 当消费端调用onCompleted()方法,表示请求体数据发送完毕,从而触发UnaryServerCallListener的onComplete()方法,在该方法中会调用invoke()方法,从而执行服务方法,并得到结果,得到结果后,会调用UnaryServerCallListener的onReturn()方
法,把结果通过responseObserver发送给消费端,并调用responseObserver的onCompleted()方法,表示响应数据发送完毕,responseObserver是ReflectionServerCall对
象的一个StreamObserver适配对象(ServerCallToObserverAdapter)。
执行invoker方法,从而执行真正服务方法的代码:
 onReturn()方法
onReturn()方法
 D.ServerStreamServerCallListener:
D.ServerStreamServerCallListener: - 在接收到请求头时,会构造ServerStreamServerCallListener对象,没什么特殊的
- 然后接收到请求体时,请求体中的数据就是调用接口方法的入参值,比如User对象,那
么就会调用ServerStreamServerCallListener的onMessage()方法,在这个方法中会把User对象以及responseObserver对象设置到invocation对象中,这是和UnaryServerCallListener不同的
地方,UnaryServerCallListener只会把User对象设置给invocation,而ServerStreamServerCallListener还会把responseObserver对象设置进去,因为服务端流需要这个responseObserver对象,服务方法拿到这个对象后就可以自己来控制如何发送响
应体,并什么时候调用onCompleted()方法来表示响应体发送完毕。 - 当消费端调用onCompleted()方法,表示请求体数据发送完毕,从而触发
ServerStreamServerCallListener的。
E.BiStreamServerCallListener: - 在接收到请求头时,会构造BiStreamServerCallListener对象,这里比较特殊,会把responseObserver设置给invocation并执行invoke()方法,从而执行服务方法,并执行
onReturn()方法,onReturn()方法中会把服务方法的执行结果,也是一个StreamObserver对
象,赋值给BiStreamServerCallListener对象的requestObserver属性。 - 这样,在接收到请求头时,服务方法就会执行了,并且得到了一个requestObserver,它是程序员定义的,是用来处理请求体的,另外的responseObserver是用来发送响应体的。
- 紧接着就会收到请求体,从而触发onMessage()方法,该方法中会调用requestObserver的onNext()方法,这样就可以做到,服务端能实时的接收到消费端每次所发送过来的数据,并且进行处理,处理过程中,如果需要响应就可以利用responseObserver进行响应
- 一旦消费端那边调用了onCompleted()方法,那么就会触发BiStreamServerCallListener
的onComplete方法,该方法中也就是调用requestObserver的onCompleted(),主要就触发程序员自己写的StreamObserver对象中的onCompleted(),并没有针对底层的Stream做什
么事情。
requestObserver是用来处理请求体的,responseObserver是用来发送响应体的。
requestObserver和responseObserver中间接持有了channel,分别可以用来接收和发送
(响应)数据。
triple三种调用方式返回结果比较
SERVER_STREAM、CLIENT_STREAM/BI_STREAM在invoker后马上返回的是CompletedFuture,表示立马返回,不阻塞,以实现异步的效果。
而UNARY返回的是一个DeadlineFuture,其会开启一个延迟任务(延迟的时间就是timeout),到时间后就会检查DeadlineFuture是否完成。
总结
不管是Unary,还是ServerStream,还是BiStream,底层客户端和服务端之间都只有一个Stream,它们三者的区别在于:
- Unary:通过流(tcp方式),将方法入参值作为请求体发送出去,而且只发送一次,服务端这边接收到请求体之后,会执行服务方法,得到结果,把结果返回给客户端,也只响应一次。
- ServerStream:通过流,将方法入参值作为请求体发送出去,而且只发送一次,服务端这边接收到请求体之后,会执行服务方法,并且会把当前流对应的StreamObserver对象也传给服务方法,由服务方法自己控制如何响应,响应几次,响应什么数据,什么时候响应结束,都由服务方法自己控制。
- BiStream,通过流,客户端和服务端,都可以发送和响应多次。
为什么ServerCall.Listener中能向另一端发送数据?
当TripleHttp2FrameServerHandler接收到Http2HeadersFrame的时候,会创建ServerStream对象,此时会把channel传到ServerStream对象中,然后ServerStream对象会创建一个ServerTransportObserver对象,用来处理请求头和请求体。
ServerTransportObserver为ServerStream的内部类。ServerTransportObserver在处理请求头的时候,会创建ReflectionServerCall,创建的时候会将ServerStream传入到ReflectionServerCall的构造参数中,因此ReflectionServerCall就间接持有了channel。创建完ReflectionServerCall对象后,会调用ReflectionServerCall的doStartCall()方法(先调用startCall方法,startCall方法里面再调用doStartCall方法),doStartCall方法会根据rpc方法的调用方式来生成不同的ServerCall.Listener。在构造这些ServerCall.Listener时会把ReflectionServerCall对象传入进去,所以ServerCall.Listener也间接持有了channel,所以也就能向另一端发送数据。同样的道理,ClientCall.Listener也会间接持有channel,从而能向另一端发送数据。
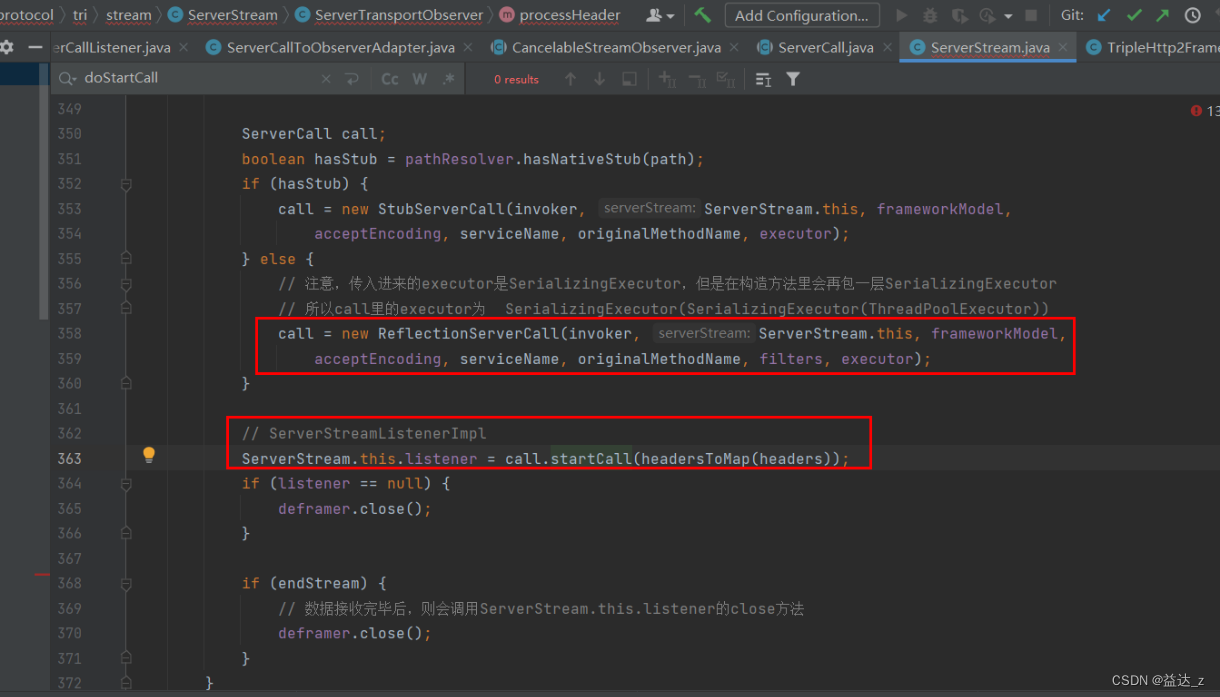
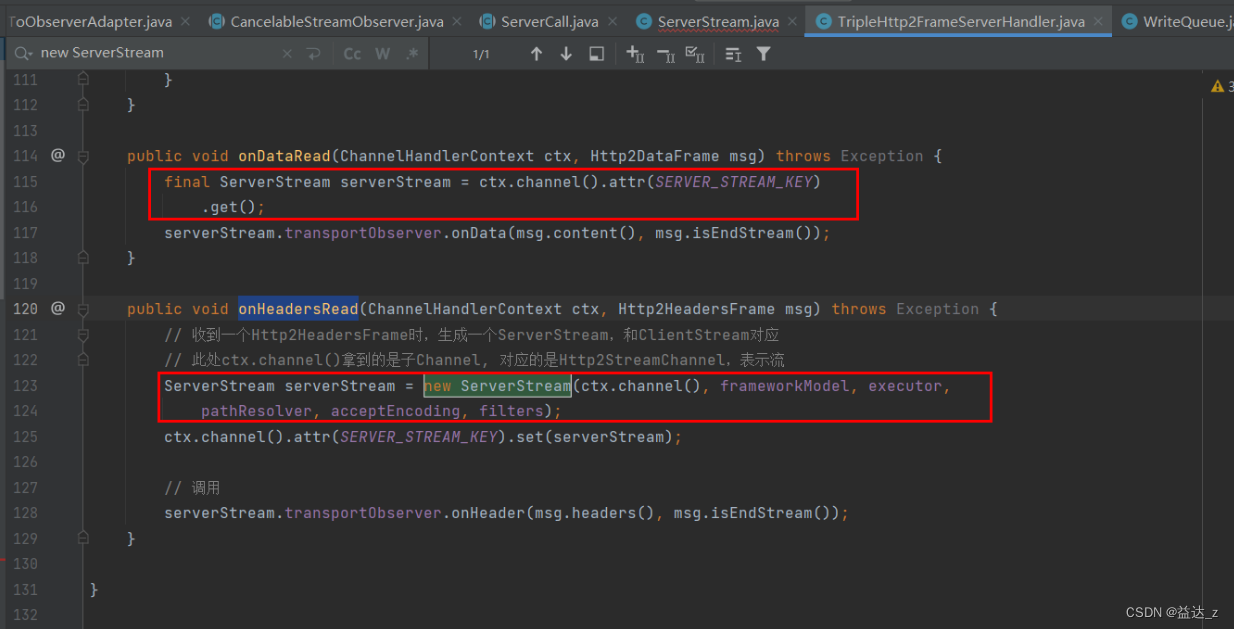
 从TripleHttp2FrameServerHandler中可以知道,只在接收到HEADERS帧时才会创建ServerStream,而在接收到DATA帧时是从channel attr中获取ServerStream的,所以可以知道客户端在发送数据的时候是先发送完HEADERS帧再发送DATA帧的。
从TripleHttp2FrameServerHandler中可以知道,只在接收到HEADERS帧时才会创建ServerStream,而在接收到DATA帧时是从channel attr中获取ServerStream的,所以可以知道客户端在发送数据的时候是先发送完HEADERS帧再发送DATA帧的。
最佳实践
1.如果消费者没有声明如下属性,如果没有声明如下则会订阅所有服务。
指定需要订阅的服务提供方,默认值*,会订阅所有服务,不建议使用
subscribed‐services: spring‐cloud‐dubbo‐provider‐user
即消费者最好指定服务提供方
2.spring cloud alibaba 2.2.8这个版本没有整合dubbo,所以需要指定dubbo的版本


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









