







 本文详细介绍了集成学习中的Stacking方法,包括其原理和应用,并提及了Bagging和Boosting。Stacking利用多个基模型的预测结果作为元分类器的输入,通过mlxtend库可以方便实现。此外,文章还探讨了StackingClassifier的API和参数设置。
本文详细介绍了集成学习中的Stacking方法,包括其原理和应用,并提及了Bagging和Boosting。Stacking利用多个基模型的预测结果作为元分类器的输入,通过mlxtend库可以方便实现。此外,文章还探讨了StackingClassifier的API和参数设置。
集成学习主要分为 bagging, boosting 和 stacking方法。本文主要是介绍stacking方法及其应用。但是在总结之前还是先回顾一下继承学习。
这部分主要转自知乎。
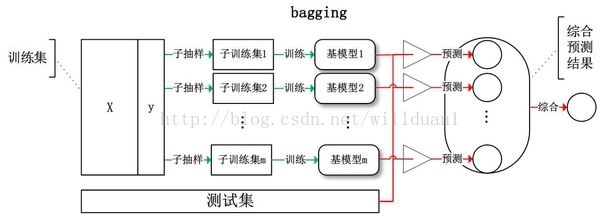
1. Bagging方法:
给定一个大小为n的训练集 D,Bagging算法从中均匀、有放回地选出 m个大小为 n' 的子集Di,作为新的训练集。在这 m个训练集上使用分类、回归等算法,则可得到 m个模型,再通过取平均值、取多数票等方法综合产生预测结果,即可得到Bagging的结果。
2. Boosting 方法
加入的过程中,通常根据它们的上一轮的分类准确率给予不同的权重。加和弱学习者之后,数据通常会被重新加权,来强化对之前分类错误数据点的分类,其中一个经典的提升算法例子是AdaBoost。

3. Stacking 方法:
将训练好的所有基模型对整个训练集进行预测,第j个基模型对第i个训练样本的预测值将作为新的训练集中第i个样本的第j个特征值,最后基于新的训练集进行训练。同理,预测的过程也要先经过所有基模型的预测形成新的测试集,最后再对测试集进行预测:
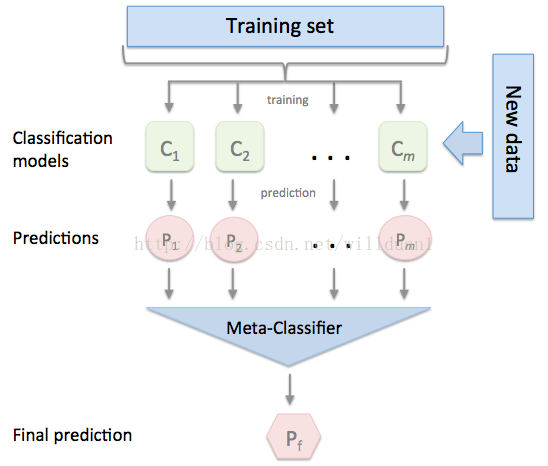
下面我
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 840
840

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









