









1简介
大数据时代中,数据从简单的批处理,扩展到实时处理、流处理。起初的MapReduce处理模式早已独木难支。此外,大数据处理技术也是百花齐放,如 HBase、Hive、Kafka、Spark、Flink 等,对开发者而言,想要将其全部熟练运用几乎是一项不可能完成的任务。此时,Google在2016年2月宣布将大数据流水线产品(Google DataFlow)贡献给 Apache 基金会孵化,2017年1月Apache 对外宣布开源 Apache Beam,2017年5月迎来了它的第一个稳定版本2.0.0。
Apache Beam的主要目标是统一批处理和流处理的编程范式,为乱序无限的大数据集处理提供简单灵活,功能丰富以及表达能力强大的SDK,但Apache Beam不涉及具体执行引擎的实现,Apache Beam希望基于Beam开发的数据处理程序可以执行在任意的分布式计算引擎上。
2Apache Beam架构
2.1基础架构
Apache Beam将数据处理分成三层Beam Model、Pipeline和Beam Runners组成。如下图2-1所示,Model是Beam 的模型或叫数据来源的IO,它是由多种数据源或仓库的IO组成,数据源支持批处理和流处理。Pipeline是Beam的管道,所有的批处理或流处理都要通过这个管道把数据传输到后端的计算平台。这个管道现在是唯一的。数据源可以切换多种,计算平台或处理平台也支持多种。需要注意的是,管道只有一条,它的作用是连接数据和 Runners平台(计算引擎)。Runners是大数据计算或处理平台,目前支持Apache Flink、Apache Spark、Direct Pipeline 和 Google Clound Dataflow 四种。其中 Apache Flink 和 Apache Spark 同时支持本地和云端。Direct Pipeline 仅支持本地,Google Clound Dataflow 仅支持云端。后续还将接入更多大数据计算平台。

图2-1 数据处理架构图
2.2Beam Model
Beam Model便是Beam的编程范式,即Beam SDK的灵魂。首先,了解下Beam Model相关问题域的一些基本概念。
l 数据源
分布式数据处理的数据来源类型通常有两类,有界的数据集和无界的数据流。有界的数据集,比如一个HDFS中的文件,一个Hive表等,数据特点是已持久化、大小固定、不常变动。而无界的数据流,比如Kafka流出来的数据流,其特点是动态、无边界、无法全部持久化。Beam框架设计时便需兼顾这两种数据源数据处理进行考虑,即批处理和流处理。
l 时间
分布式框架的时间处理有两种,一种是全量计算,另一种是部分增量计算。批处理任务通常进行全量的数据计算,较少关注数据的时间属性,但是对于流处理任务来说,由于数据流是无情无尽的,无法进行全量的计算,通常是对某个窗口中得数据进行计算,对于大部分的流处理任务来说,按照时间进行窗口划分,可能是最常见的需求。
l 乱序
对于流处理的数据流来说,数据的到达顺序可能并不严格按照Event-Time的时间顺序。若是按照 Process Time 定义时间窗口,便不存在乱序问题,因为都是关闭当前窗口后才进行下一个窗口操作,需要等待,所以执行都是有序的。而对于Event Time定义的时间窗口,则可能存在时间靠前的消息在时间靠后的消息后到达的情况,这在分布式的数据源中可能非常常见的棘手问题。
Beam Model 处理的目标数据是无界的时间乱序数据流,不考虑时间顺序或有界的数据集可看做是无界乱序数据流的一个特例。Beam Model 从下面四个维度归纳了用户在进行数据处理的时候需要考虑的问题:
- What。如何对数据进行计算?例如,机器学习中训练学习模型可以用 Sum或者Join 等。在Beam SDK中由Pipeline中的操作符指定。
- Where。数据在什么范围中计算?例如,基于Process-Time 的时间窗口、基于Event-Time的时间窗口、滑动窗口等等。在Beam SDK中由Pipeline 的窗口指定。
- When。何时输出计算结果?例如,在1小时的Event-Time时间窗口中,每隔1分钟将当前窗口计算结果输出。在Beam SDK中由Pipeline的Watermark和触发器指定。
- How。迟到数据如何处理?例如,将迟到数据计算增量结果输出,或是将迟到数据计算结果和窗口内数据计算结果合并成全量结果输出。在Beam SDK中由Accumulation指定。
Beam Model将“WWWH”四个维度抽象出来组成了Beam SDK,用户在基于Beam SDK构建数据处理业务逻辑时,每一步只需要根据业务需求按照这四个维度调用具体的API,即可生成分布式数据处理Pipeline,并提交到具体的Runners执行引擎上执行。Apache Beam目前支持的API接口是由Java与Python语言实现的,其他语言版本的API正在开发之中。下表2-1是目前Beam 2.0的SDKs支持数据源IO 。
| 数据源IO | 描述 |
| Amqp | 高级消息队列协议 |
| Cassandra | Cassandra是一个NoSQL列族(column family)实现,使用由Amazon Dynamo引入的架构方面的特性来支持Big Table数据模型。 |
| Elasticesarch | 一个实时的分布式搜索引擎 |
| Google-cloud-platform | 谷歌云 IO |
| Hadoop-file-system | 操作 Hadoop 文件系统的 IO |
| Hadoop-hbase | 操作 Hadoop 上的 Hbase 的接口 IO |
| Hcatalog | Hcatalog 是 Apache 开源的对于表和底层数据管理统一服务平台 |
| Jdbc | 连接各种数据库的数据库连接器 |
| Jms | Java 消息服务(Java Message Service,简称 JMS)是用于访问企业消息系统的开发商中立的 API。企业消息系统可以协助应用软件通过网络进行消息交互。JMS 在其中扮演的角色与 JDBC 很相似,正如 JDBC 提供了一套用于访问各种不同关系数据库的公共 API,JMS 也提供了独立于特定厂商的企业消息系统访问方式 |
| Kafka | 处理流数据的轻量级大数据消息系统,或叫消息总线 |
| Kinesis | 对接亚马逊的服务,可以构建用于处理或分析流数据的自定义应用程序,以满足特定需求 |
| Mongodb | MongoDB 是一个基于分布式文件存储的数据库 |
| Mqtt | IBM 开发的一个即时通讯协议 |
| Solr | 亚实时的分布式搜索引擎技术 |
| xml | 一种数据格式 |
表2-1 Beam 2.0的SDKs支持数据源IO
3简单实战演习
3.1 环境
A. 下载安装JDK 7或更新的版本。
B. 下载maven并配置。
C. 开发环境 Eclipse(个人习惯)。
3.2 Join操作示例
3.2.1Join案例
将用户信息(用户账户+用户名)文本数据,与订单信息(用户账户+订单名+订单详情)文本数据,通过用户账户字段取并集操作。
3.2.2 pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>william-lib</groupId>
<artifactId>wordcount</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>wordcount</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.15</version>
</dependency>
<dependency>
<groupId>org.apache.beam</groupId>
<artifactId>beam-sdks-java-core</artifactId>
<version>2.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.beam</groupId>
<artifactId>beam-runners-direct-java</artifactId>
<version>2.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.beam</groupId>
<artifactId>beam-sdks-java-io-jdbc</artifactId>
<version>2.0.0</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.38</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.7</source>
<target>1.7</target>
<encoding>UTF8</encoding>
<fork>fasle</fork>
<meminitial>1024m</meminitial>
<maxmem>2024m</maxmem>
</configuration>
</plugin>
<!-- The configuration of maven-jar-plugin -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<!-- The configuration of the plugin -->
<configuration>
<!-- Configuration of the archiver -->
<archive>
<!-- 生成的jar中,不要包含pom.xml和pom.properties这两个文件 -->
<addMavenDescriptor>false</addMavenDescriptor>
<!-- Manifest specific configuration -->
<manifest>
<!-- 是否要把第三方jar放到manifest的classpath中 -->
<addClasspath>true</addClasspath>
<!-- 生成的manifest中classpath的前缀,因为要把第三方jar放到lib目录下,所以classpath的前缀是lib/ -->
<classpathPrefix>./</classpathPrefix>
<!-- 应用的main class -->
<mainClass>william_lib.wordcount</mainClass>
</manifest>
</archive>
</configuration>
</plugin>
</plugins>
</build>
</project>
3.2.3TestJoin.java
package william_lib.wordcount;
import org.apache.beam.runners.direct.DirectRunner;
import org.apache.beam.sdk.Pipeline;
import org.apache.beam.sdk.io.TextIO;
import org.apache.beam.sdk.options.PipelineOptions;
import org.apache.beam.sdk.options.PipelineOptionsFactory;
import org.apache.beam.sdk.transforms.DoFn;
import org.apache.beam.sdk.transforms.MapElements;
import org.apache.beam.sdk.transforms.ParDo;
import org.apache.beam.sdk.transforms.SimpleFunction;
import org.apache.beam.sdk.transforms.join.CoGbkResult;
import org.apache.beam.sdk.transforms.join.CoGroupByKey;
import org.apache.beam.sdk.transforms.join.KeyedPCollectionTuple;
import org.apache.beam.sdk.values.KV;
import org.apache.beam.sdk.values.PCollection;
import org.apache.beam.sdk.values.TupleTag;
/**
*
* <pre>
* 2个本地数据集,以指定字段做join操作
* </pre>
*
* @author William_JM
* @date 2017年12月13日
*
*/
public class TestJoin {
@SuppressWarnings("serial")
public static void main(String[] args) {
// 管道工厂创建需求管道
PipelineOptions options = PipelineOptionsFactory.create();
// 显式指定PipelineRunner:DirectRunner(Local模式)
options.setRunner(DirectRunner.class);
// 装置管道
Pipeline pipeline = Pipeline.create(options);
// 读取用户信息数据集
final PCollection<KV<String, String>> userInfoCollection =
pipeline.apply(TextIO.read().from(args[0])).apply("userInfoCollection",
MapElements.via(new SimpleFunction<String, KV<String, String>>() {
@Override
public KV<String, String> apply(String input) {
// line format example:account|username
String[] values = input.split("\\|");
return KV.of(values[0], values[1]);
}
}));
// 业务订单数据集
final PCollection<KV<String, String>> orderCollection =
pipeline.apply(TextIO.read().from(args[1])).apply("orderCollection",
MapElements.via(new SimpleFunction<String, KV<String, String>>() {
@Override
public KV<String, String> apply(String input) {
// line format example: orderId|orderName|description
String[] values = input.split("\\|");
return KV.of(values[0], values[1]);
}
}));
final TupleTag<String> userInfoTag = new TupleTag<String>();
final TupleTag<String> orderTag = new TupleTag<String>();
// 通过 beam提供CoGroupByKey实现对2组关系数据集(key/value)的join操作
// beam SDK为确保数据类型一致,强制数据集压入KeyedPCollectionTuple
final PCollection<KV<String, CoGbkResult>> cogrouppedCollection =
KeyedPCollectionTuple.of(userInfoTag, userInfoCollection).and(orderTag, orderCollection)
.apply(CoGroupByKey.<String>create());
final PCollection<KV<String, String>> finalResultCollection = cogrouppedCollection.apply(
"finalResultCollection", ParDo.of(new DoFn<KV<String, CoGbkResult>, KV<String, String>>() {
@ProcessElement
public void processElement(ProcessContext pc) {
KV<String, CoGbkResult> e = pc.element();
String account = e.getKey();
String username = e.getValue().getOnly(userInfoTag);
for (String order : pc.element().getValue().getAll(orderTag)) {
pc.output(KV.of(account, username + "\t" + order));
}
}
}));
// 结果保存数据集
PCollection<String> formattedResults = finalResultCollection.apply("formattedResults",
ParDo.of(new DoFn<KV<String, String>, String>() {
@ProcessElement
public void processElement(ProcessContext c) {
c.output(c.element().getKey() + " : " + c.element().getValue());
}
}));
formattedResults.apply(TextIO.write().to("joinedResults"));
pipeline.run().waitUntilFinish();
}
}
如上是将用户信息数据集与订单信息数据集做join操作实战单码。
1、 管道工厂生产定制属性管道(Pipeline)——指定数据处理Runner为本地模式。
PipelineOptions options = PipelineOptionsFactory.create();
options.setRunner(DirectRunner.class);
2、 组装数据引流管道
Pipeline pipeline = Pipeline.create(options);
3、 注入用户数据集——这是beam最重要的Model模块,就是指定数据的来源,及数据的结构。本例是有界固定大小的文本文件。
final PCollection<KV<String, String>> userInfoCollection= pipeline.apply
(TextIO.read().from(args[0])).apply("userInfoCollection",MapElements.via(newSimpleFunction<String, KV<String, String>>(){…...}));
final PCollection<KV<String, String>>orderCollection = pipeline.apply
(TextIO.read().from(args[1])).apply("orderCollection",MapElements.via(newSimpleFunction<String, KV<String, String>>() {……}));
4、 join处理——beam是通过Transforms范式,在管道中操作数据,用户需以方法(函数)的形式提供处理逻辑对象(也就是“用户代码”)。本例中使用的是beam SDKs提供的通用方法CoGroupByKey实现对2组关系数据集(key/value)的join操作。
final PCollection<KV<String,CoGbkResult>>cogrouppedCollection = KeyedPCollectionTuple.of(userInfoTag,userInfoCollection).and(orderTag,orderCollection).apply(CoGroupByKey.<String>create());
5、 结果数据保存结构样式——封装数据处理结果为自定义对象
PCollection<String> formattedResults = finalResultCollection.apply("forma
ttedResults",ParDo.of(new DoFn<KV<String,String>, String>(){…}));
6、 指定结果保存路径
formattedResults.apply(TextIO.write().to("joinedResults"));
7、送入管道,分配计算引擎执行
pipeline.run().waitUntilFinish();
3.2.4部署运行
因为Windows上的Beam2.0.0不支持本地路径,故需要打包部署到Linux 上。
1、打jar包
2、准备待合并文本数据userInfo.txt和order.txt。文本内容如下:

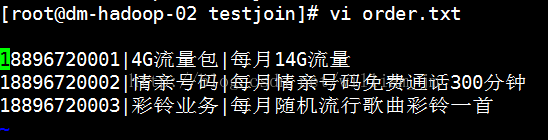
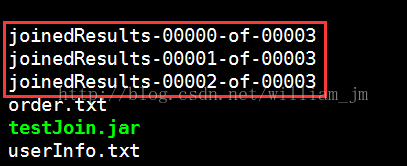
3、执行指令:java -jar testJoin.jaruserInfo.txt order.txt。
执行结果如下图:


4Apache Beam应用场景
Google Cloud、阿里巴巴、百度等巨头公司都在使用Beam,Apache Beam 中文社区正在集成一些工作中的Runners和SDKs IO,包括人工智能、机器学习和时序数据库等一些功能。以下为应用场景的几个例子:
1、 Beam可以用于ETL Job任务
Beam的数据可以通过SDKs的IO接入,通过管道可以用后面的Runners 做清洗。
2、Beam数据仓库快速切换、跨仓库
由于Beam的数据源是多样IO,所以用Beam以快速切换任何数据仓库。
3、Beam计算处理平台切换、跨平台
Runners目前提供了4种可以切换的常用平台,随着Beam的强大应该会有更多的平台提供给大家使用。
5总结
1、Apache Beam的Beam Model将无限乱序数据流的数据处理抽象成“WWWH”四个维度,非常清晰与合理;
2、Beam Model统一了对无限数据流和有限数据集的处理模式,且明确了编程范式,扩大了流处理系统可应用的业务范围,例如,Event-Time/Session窗口的支持,乱序数据的处理支持等。
3、Apache Beam集成了很多数据模型的一个统一化平台,它为大数据开发工程师频繁换数据源或多数据源、多计算框架提供了集成统一框架平台。
4、Apache Beam 主要针对理想并行的数据处理任务,并通过把数据集拆分多个子数据集,让每个子数据集能够被单独处理,从而实现整体数据集的并行化处理。
5、Apache Beam也可以对数据源中数据读取,自定义业务规则,对数据质量进行稽核统计,保存数据质量信息。















 1420
1420

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









