






提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
目录
一、AI (Artificial Intelligence)
3.Deep First Search 深度优先和Depth-limited Search
a. Iterative Deepening DF Search
b. Iterative Deepening DF Search
7. Adversarial Search (α and β cut) 剪枝法
8. Uniform-Cost Search
9. Heuristic Graph search
10. Greedy Best-First Search
11. A和A*算法
前言
随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习的基础内容。
一、AI (Artificial Intelligence)
利用计算机来模拟人的思考过程,对人类行为的模拟(例如学习,推理,规划等),使计算集能实现更高层次的应用
在人工智能中,我们引入了agent概念。智能agent是指一个自治实体,该实体在环境中使用传感器和相应的执行器进行观察,将其活动指向实现目标。聪明的agent也可以学习或使用知识来达到目标,而agent一般通过sensor来感知周围的环境,和actuator来对环境做出相应的行为。
一个agent是由它的结构和程序组成,他们也是实现某一个功能的基础。因此我们可以知道,一个有感知能力的实体是由认知来决定行为的:
二、Search Algorithm 搜索算法
1.Backtracking 回溯法
其实它类似于“穷举法”,利用一些约束条件,来去掉不符合要求的的解,只留下满足要求的解,也有点类似于DFS,一步一步走到叶子结点,满足要求就保存这个解,不满足要求就退回到上一层的结点,直到所有可能的路径都被访问过。
在回溯法中,需要注意的是:一次只需要看一条路径,而且当前点不fail时,则可以继续沿着当前的path继续往前走。在实际写代码中,通常都是用递归来完成。
常见的4-Queens游戏中,我们就可以使用该算法进行模拟
4-queens问题包括在4 x 4的棋盘上放置四个皇后,以便没有两个皇后可以互相俘获。也就是说,不允许将两个皇后放在同一行,同一列或同一对角线上。

根据约束,我们可以得知该空间由4*4的space组成,即 Si = {1, 2, 3, 4} and 1<= I <=4 我们可以通过将其作为边界函数,通过回溯来解决。


private static boolean isSafePlace(int column, int Qi, int[] board) {
//check for all previously placed queens
for (int i = 0; i < Qi; i++) {
if (board[i] == column) { // the ith Queen(previous) is in same column
return false;
}
//the ith Queen is in diagonal
//(r1, c1) - (r2, c1). if |r1-r2| == |c1-c2| then they are in diagonal
if (Math.abs(board[i] - column) == Math.abs(i - Qi)) {
return false;
}
}
return true;
}
# This code is contributed by Yanming Wu2.Bread First Search 广度优先
广度优先搜索也成为了宽度优先搜索,它是连通图的一种遍历策略。正如它的名字一样,它从顶点向下进行辐射状的优先遍历周围较广的区域。

Ref. Breadth-First Search (BFS) Algorithm, 2020
a. 在数据的各个级别中,可以将任何节点标记为开始遍历的起始节点或初始节点。 BFS将访问该节点并将其标记为已访问并将其放置在队列中。
b. 现在,BFS将访问最近的未访问节点并对其进行标记。这些值也被添加到Queue中。Queue适用于FIFO模型(First-in-First-out)。
c. 以类似的方式,分析图上剩余的最近和未访问的节点,并将其标记并添加到Queue中。这些项目将从接收队列中删除,并作为结果打印。
# Python3 Program to print BFS traversal
# from a given source vertex. BFS(int s)
# traverses vertices reachable from s.
from collections import defaultdict
# This class represents a directed graph
# using adjacency list representation
class Graph:
# Constructor
def __init__(self):
# default dictionary to store graph
self.graph = defaultdict(list)
# function to add an edge to graph
def addEdge(self,u,v):
self.graph[u].append(v)
# Function to print a BFS of graph
def BFS(self, s):
# Mark all the vertices as not visited
visited = [False] * (len(self.graph))
# Create a queue for BFS
queue = []
# Mark the source node as
# visited and enqueue it
queue.append(s)
visited[s] = True
while queue:
# Dequeue a vertex from
# queue and print it
s = queue.pop(0)
print (s, end = " ")
# Get all adjacent vertices of the
# dequeued vertex s. If a adjacent
# has not been visited, then mark it
# visited and enqueue it
for i in self.graph[s]:
if visited[i] == False:
queue.append(i)
visited[i] = True
# Driver code
# Create a graph given in
# the above diagram
g = Graph()
g.addEdge(0, 1)
g.addEdge(0, 2)
g.addEdge(1, 2)
g.addEdge(2, 0)
g.addEdge(2, 3)
g.addEdge(3, 3)
print ("Following is Breadth First Traversal"
" (starting from vertex 2)")
g.BFS(2)
# Ref. Neelam Yadav3.Deep First Search 深度优先
DFS是一个递归的过程,它先选择一种可能的情况向前探索,在探索过程中,如果发现原来的选择是错误的,则退回一步重新选择。它与之前所说的BFS不同的是,DFS算法类似于输的先序遍历。这种搜索算法遵循的策略是尽可能深的搜索一个图。
基本思路:首先访问图中某一个起始顶点v,然后由v出发,访问与v相邻且未被访问的任一顶点w1,再访问与w1邻接且未被访问的任一顶点w2,….重复上述过程。当不能再继续向下访问时,依次退回到最近被访问的顶点,若它还有邻接顶点未被访问过,则从该点开始继续上述搜索过程,直到图中所有顶点均被访问过为止。
例如,我们从S点出发,则:

会先走S-A-D-G-E-B,然后才是S-A-D-G-F-C, 并且它遵循的是stak的FILO模型(First-in-last-out)
# Python3 program to print DFS traversal
# from a given given graph
from collections import defaultdict
# This class represents a directed graph using
# adjacency list representation
class Graph:
# Constructor
def __init__(self):
# default dictionary to store graph
self.graph = defaultdict(list)
# function to add an edge to graph
def addEdge(self, u, v):
self.graph[u].append(v)
# A function used by DFS
def DFSUtil(self, v, visited):
# Mark the current node as visited
# and print it
visited.add(v)
print(v, end=' ')
# Recur for all the vertices
# adjacent to this vertex
for neighbour in self.graph[v]:
if neighbour not in visited:
self.DFSUtil(neighbour, visited)
# The function to do DFS traversal. It uses
# recursive DFSUtil()
def DFS(self, v):
# Create a set to store visited vertices
visited = set()
# Call the recursive helper function
# to print DFS traversal
self.DFSUtil(v, visited)
# Driver code
# Create a graph given
# in the above diagram
g = Graph()
g.addEdge(0, 1)
g.addEdge(0, 2)
g.addEdge(1, 2)
g.addEdge(2, 0)
g.addEdge(2, 3)
g.addEdge(3, 3)
print("Following is DFS from (starting from vertex 2)")
g.DFS(2)
#Ref. Neelam Yadav4. Hill Climbing 爬山法
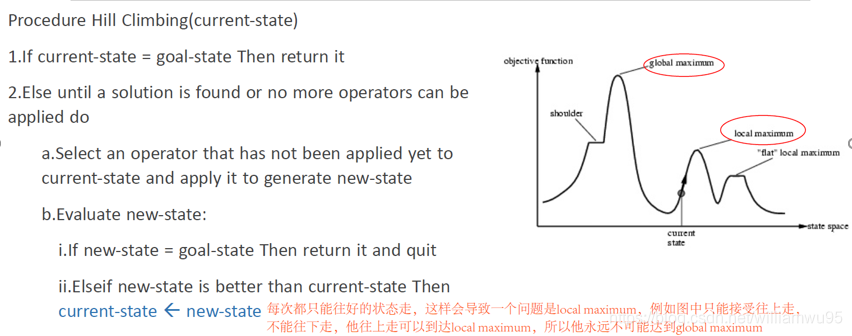
5. Local Beam Search(多个点进行hill climbing)
在局部搜索的上下文中,我们称Local Beam Search为一种特定的算法,该算法开始选择随机生成的状态,然后,对于搜索树的每个级别,它始终会考虑。当前状态的所有可能后继状态中的新状态,直到达到目标为止。
6. Simulated Annealing(optimized version of hill-climbing 爬山法的优化版)

















 881
881











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









