









线上FullGC频繁的排查
原文地址:原文地址
腾讯云服务器 2核4G 8M带宽 3年只要222😂😂,正常价格要4千多,这羊毛不薅白不薅😍😍。 https://curl.qcloud.com/50OxDE4W
本应该写在文末的
这个问题我再github上提交了一个issue,具体issue的讨论见这里
问题
前段时间发现线上的一个dubbo服务Full GC比较频繁,大约每两天就会执行一次Full GC。
Full GC的原因
我们知道Full GC的触发条件大致情况有以下几种情况:
- 程序执行了System.gc() //建议jvm执行fullgc,并不一定会执行
- 执行了jmap -histo:live pid命令 //这个会立即触发fullgc
- 在执行minor gc的时候进行的一系列检查
执行Minor GC的时候,JVM会检查老年代中最大连续可用空间是否大于了当前新生代所有对象的总大小。
如果大于,则直接执行Minor GC(这个时候执行是没有风险的)。
如果小于了,JVM会检查是否开启了空间分配担保机制,如果没有开启则直接改为执行Full GC。
如果开启了,则JVM会检查老年代中最大连续可用空间是否大于了历次晋升到老年代中的平均大小,如果小于则执行改为执行Full GC。
如果大于则会执行Minor GC,如果Minor GC执行失败则会执行Full GC
- 使用了大对象 //大对象会直接进入老年代
- 在程序中长期持有了对象的引用 //对象年龄达到指定阈值也会进入老年代
对于我们的情况,可以初步排除1,2两种情况,最有可能是4和5这两种情况。为了进一步排查原因,我们在线上开启了 -XX:+HeapDumpBeforeFullGC。
注意:
JVM在执行dump操作的时候是会发生stop the word事件的,也就是说此时所有的用户线程都会暂停运行。
为了在此期间也能对外正常提供服务,建议采用分布式部署,并采用合适的负载均衡算法
JVM参数的设置:
线上这个dubbo服务是分布式部署,在其中一台机子上开启了 -XX:HeapDumpBeforeFullGC,总体JVM参数如下:
-Xmx2g
-XX:+HeapDumpBeforeFullGC
-XX:HeapDumpPath=.
-Xloggc:gc.log
-XX:+PrintGC
-XX:+PrintGCDetails
-XX:+PrintGCDateStamps
-XX:+UseGCLogFileRotation
-XX:NumberOfGCLogFiles=10
-XX:GCLogFileSize=100m
-XX:HeapDumpOnOutOfMemoryError
Dump文件分析
dump下来的文件大约1.8g,用jvisualvm查看,发现用char[]类型的数据占用了41%内存,同时另外一个com.alibaba.druid.stat.JdbcSqlStat类型的数据占用了35%的内存,也就是说整个堆中几乎全是这两类数据。如下图:

查看char[]类型数据,发现几乎全是sql语句。

接下来查看char[]的引用情况:
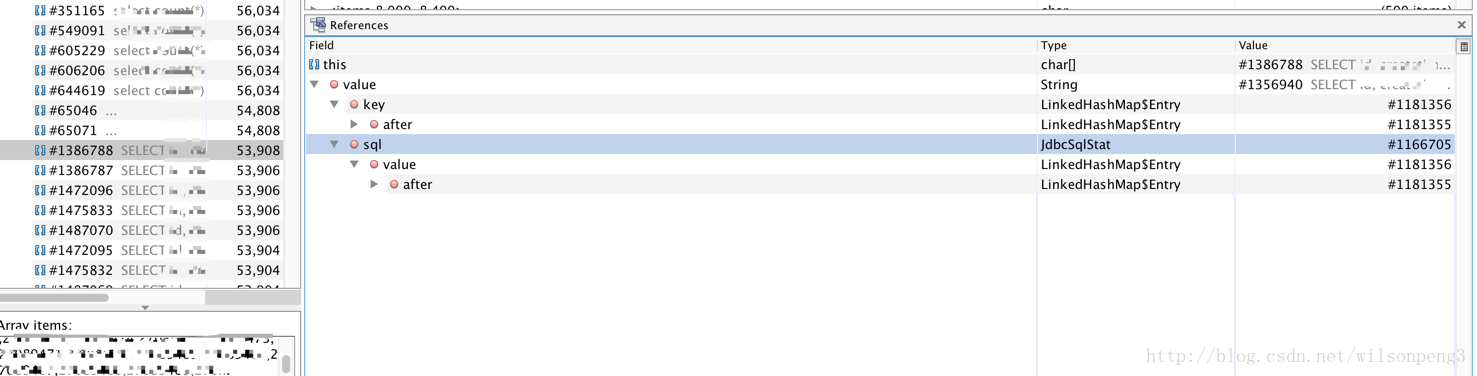
找到了JdbcSqlStat类,在代码中查看这个类的代码,关键代码如下:
//构造函数只有这一个
public JdbcSqlStat(String sql){
this.sql = sql;
this.id = DruidDriver.createSqlStatId();
}
//查看这个函数的调用情况,找到com.alibaba.druid.stat.JdbcDataSourceStat#createSqlStat方法:
public JdbcSqlStat createSqlStat(String sql) {
lock.writeLock().lock();
try {
JdbcSqlStat sqlStat = sqlStatMap.get(sql);
if (sqlStat == null) {
sqlStat = new JdbcSqlStat(sql);
sqlStat.setDbType(this.dbType);
sqlStat.setName(this.name);
sqlStatMap.put(sql, sqlStat);
}
return sqlStat;
} finally {
lock.writeLock().unlock();
}
}
//这里用了一个map来存放所有的sql语句。
其实到这里也就知道什么原因造成了这个问题,因为我们使用的数据源是阿里巴巴的druid,这个druid提供了一个sql语句监控功能,同时我们也开启了这个功能。只需要在配置文件中把这个功能关掉应该就能消除这个问题,事实也的确如此,关掉这个功能后到目前为止线上没再触发FullGC

其他
如果用mat工具查看,建议把 “Keep unreachable objects” 勾上,否则mat会把堆中不可达的对象去除掉,这样我们的分析也许会变得没有意义。如下图:Window–>References 。另外jvisualvm对ool的支持不是很好,如果需要oql建议使用mat。

原文
原文地址:原文地址
扩展
本人自己建了一个jdk8和jdk7的源码阅读仓库,会在阅读源码的过程中添加一些注释。
感兴趣的朋友可以一起来添加对代码的理解。仓库地址:
jdk8:
github: https://github.com/rocky-peng/jdk8-sourcecode-read
gitlab: https://gitlab.com/rocky_peng/jdk8
jdk7:
github: https://github.com/rocky-peng/jdk7-sourcecode-read
gitlab: https://gitlab.com/rocky_peng/jdk7
github和gitlab是完全自动同步的。
jdk8和jdk7的源码来源于jdk8和jdk7的src.zip文件。
如果有不对不足或需要帮助的地方,欢迎添加个人微信:WilsonPeng3


















 5161
5161

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









