







虽然前面实现了识别火车票和发票的信息,但是,输出的是text。使用还需要复制到表格中,可以更简单吗?
当然是可以,这篇文章教你:
识别火车票,直接把信息录入:表格。一步到位。
最终效果:

话不多说,开始实战吧
一、飞书开发者注册
1.1 进入开发者平台,注册登陆:
地址: https://open.feishu.cn/app?lang=zh-CN
1.2 点击创建自建应用:
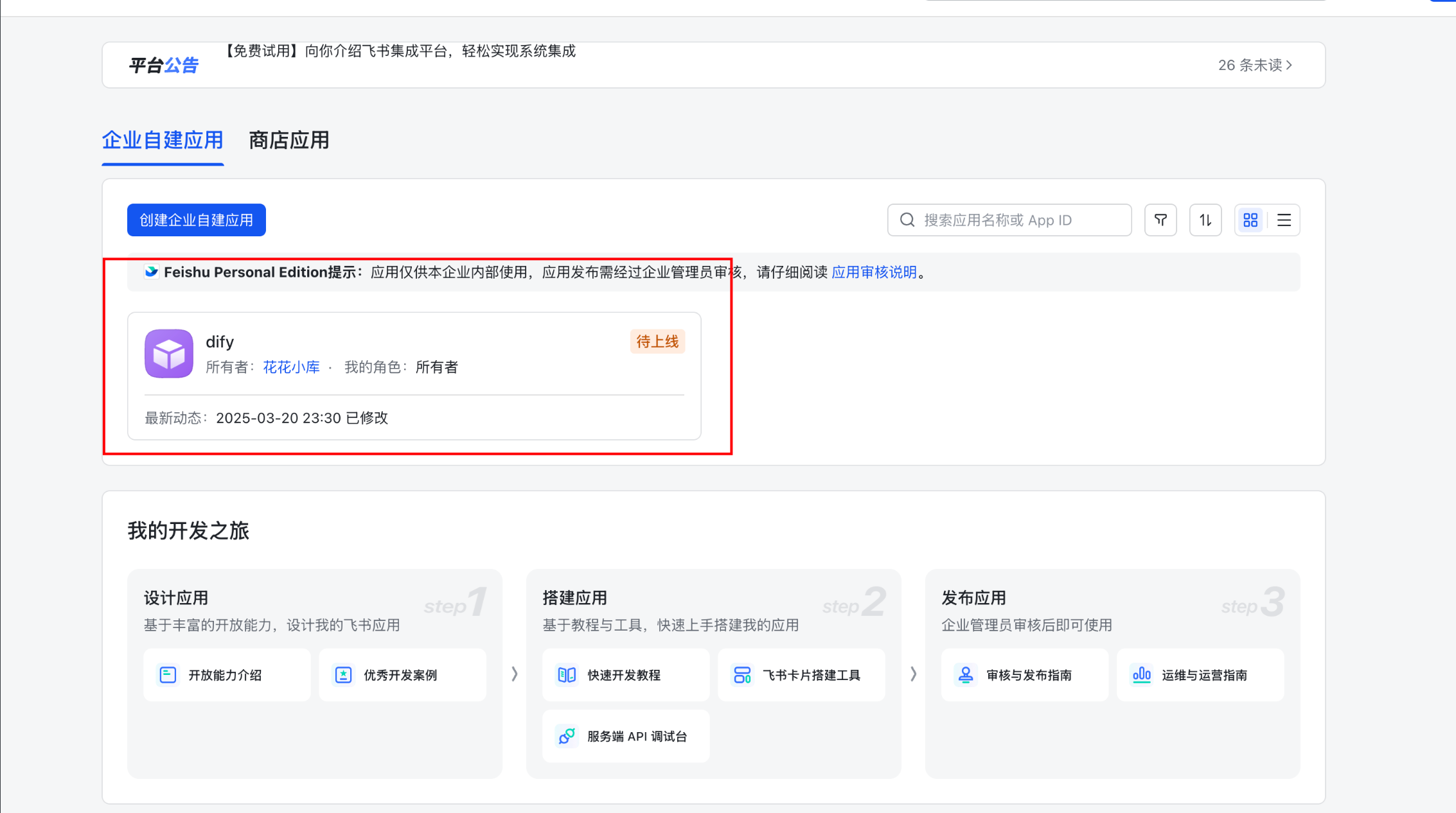
1.3: 创建完成后,展示如下:
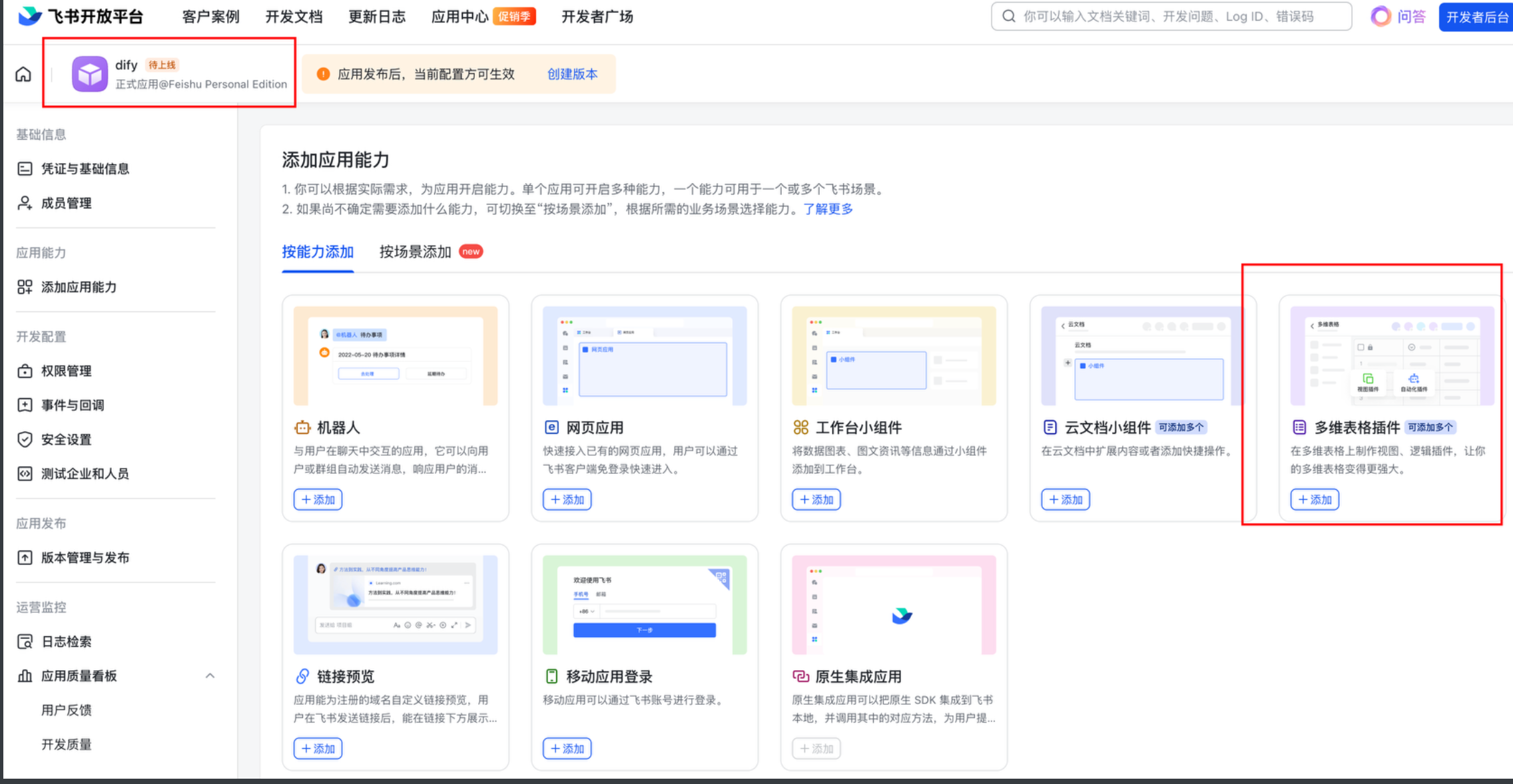
1.4: 进入应用内:
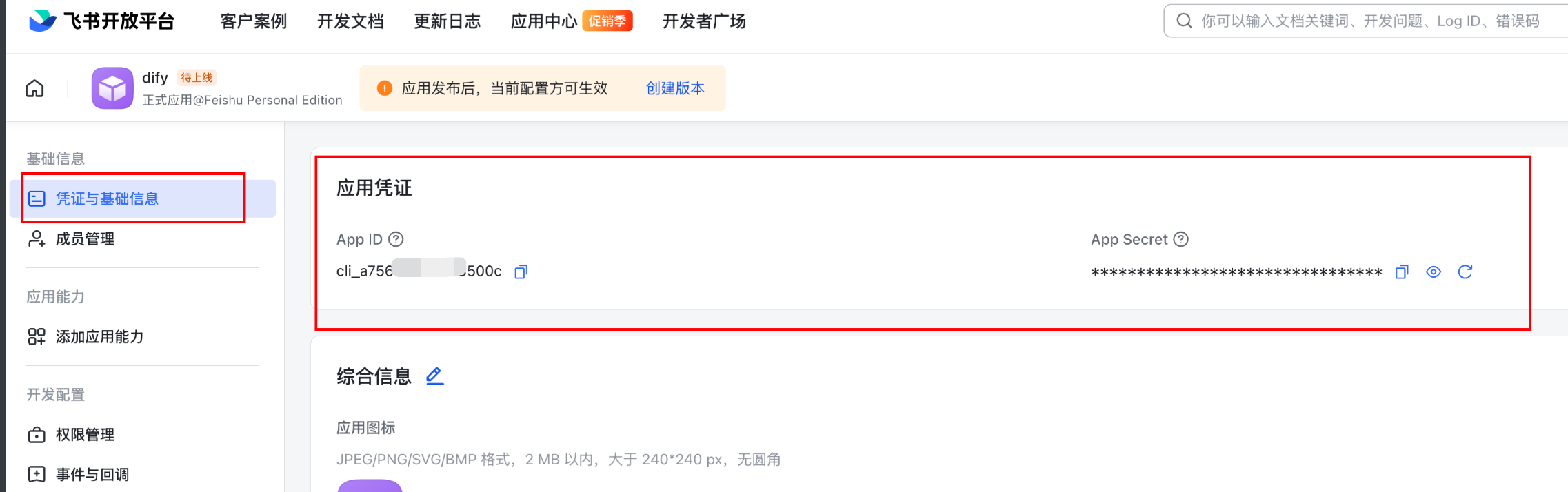
1.5: 获取appid和App Secret:
1.6 开通权限:
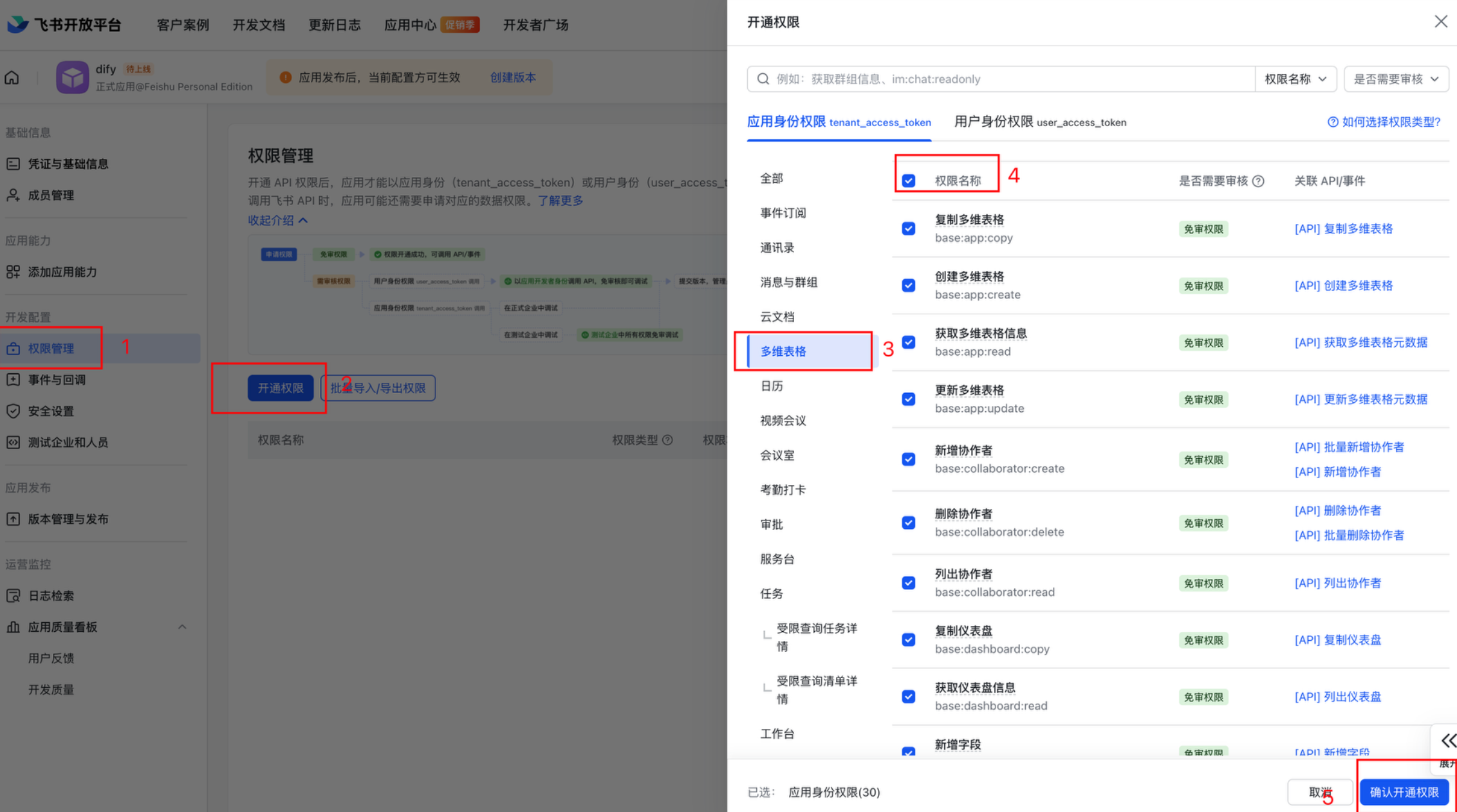
按照图中:1-> 2->3 -> 4->5 .开通权限。
1.7 版本发布
1.7.1 点击创建版本:
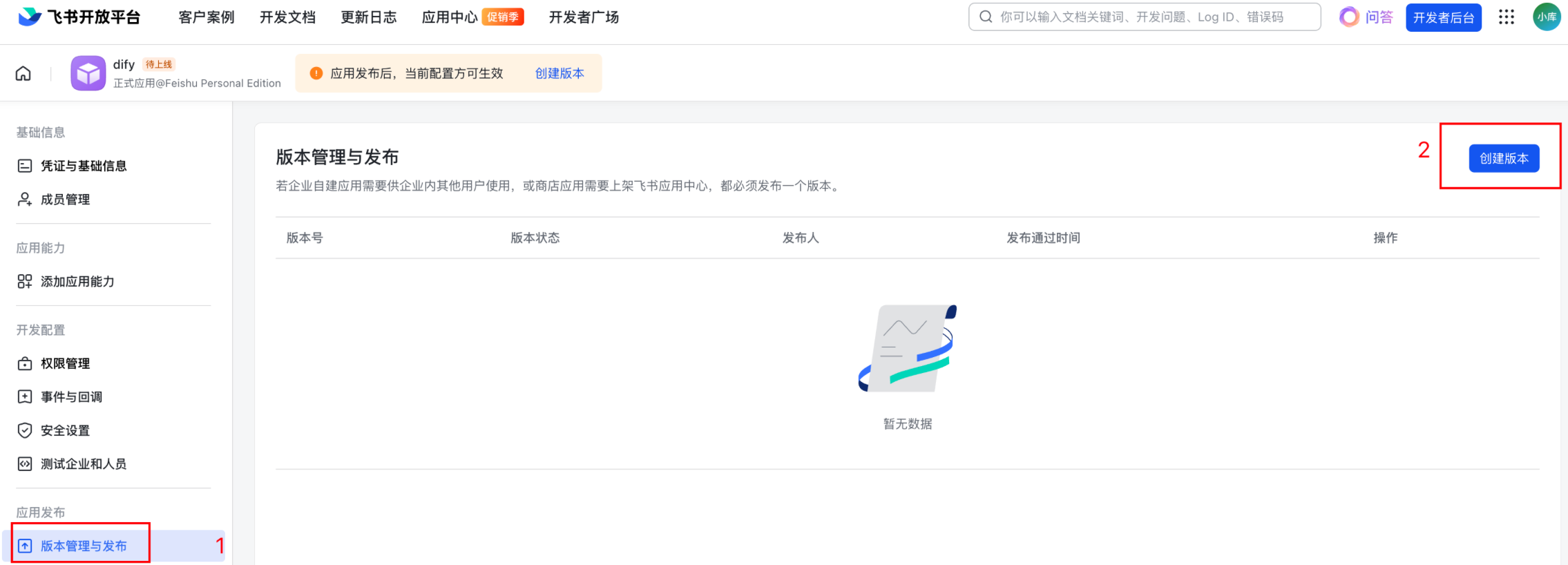
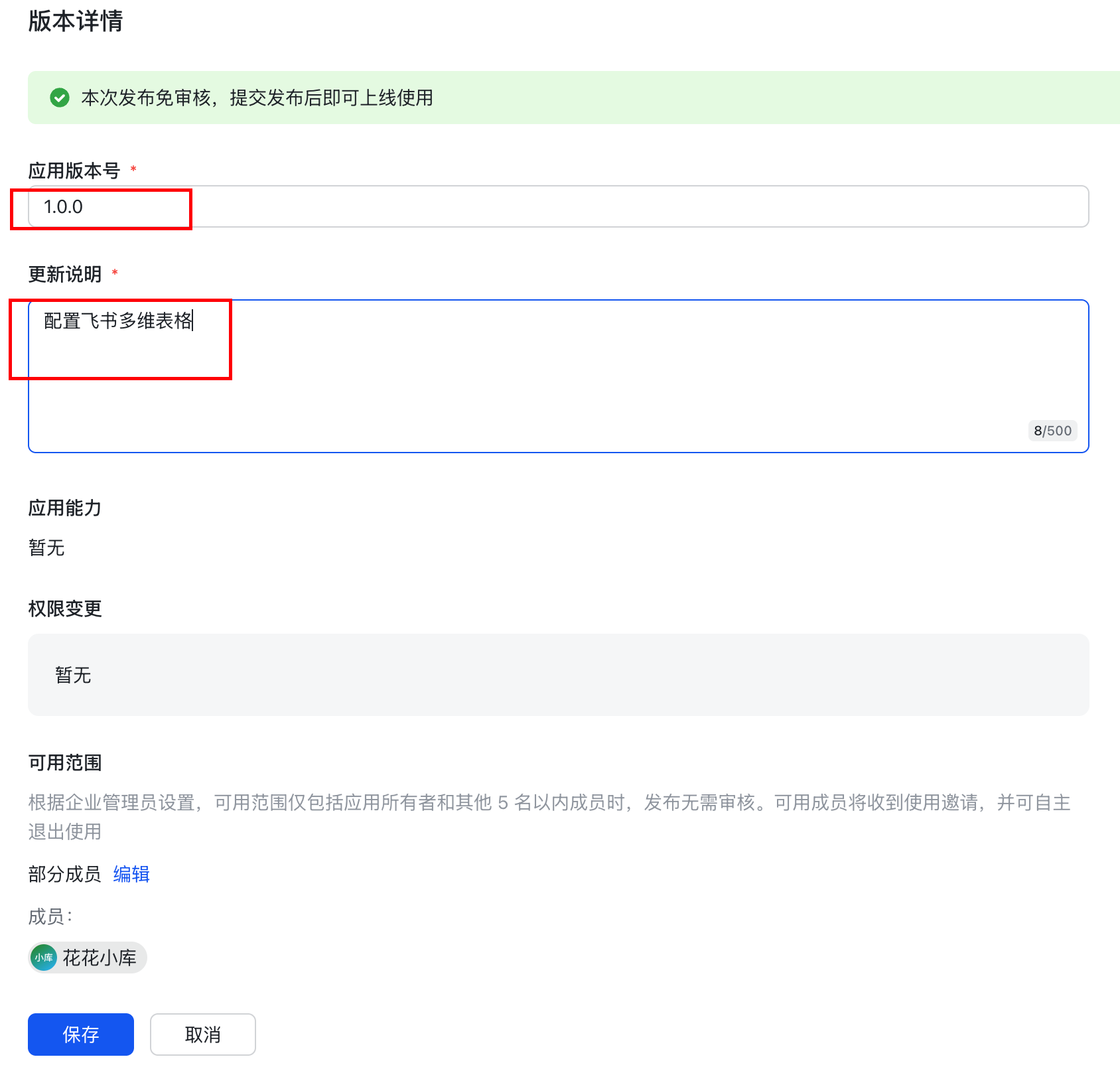
1.7.2 填写版本信息:
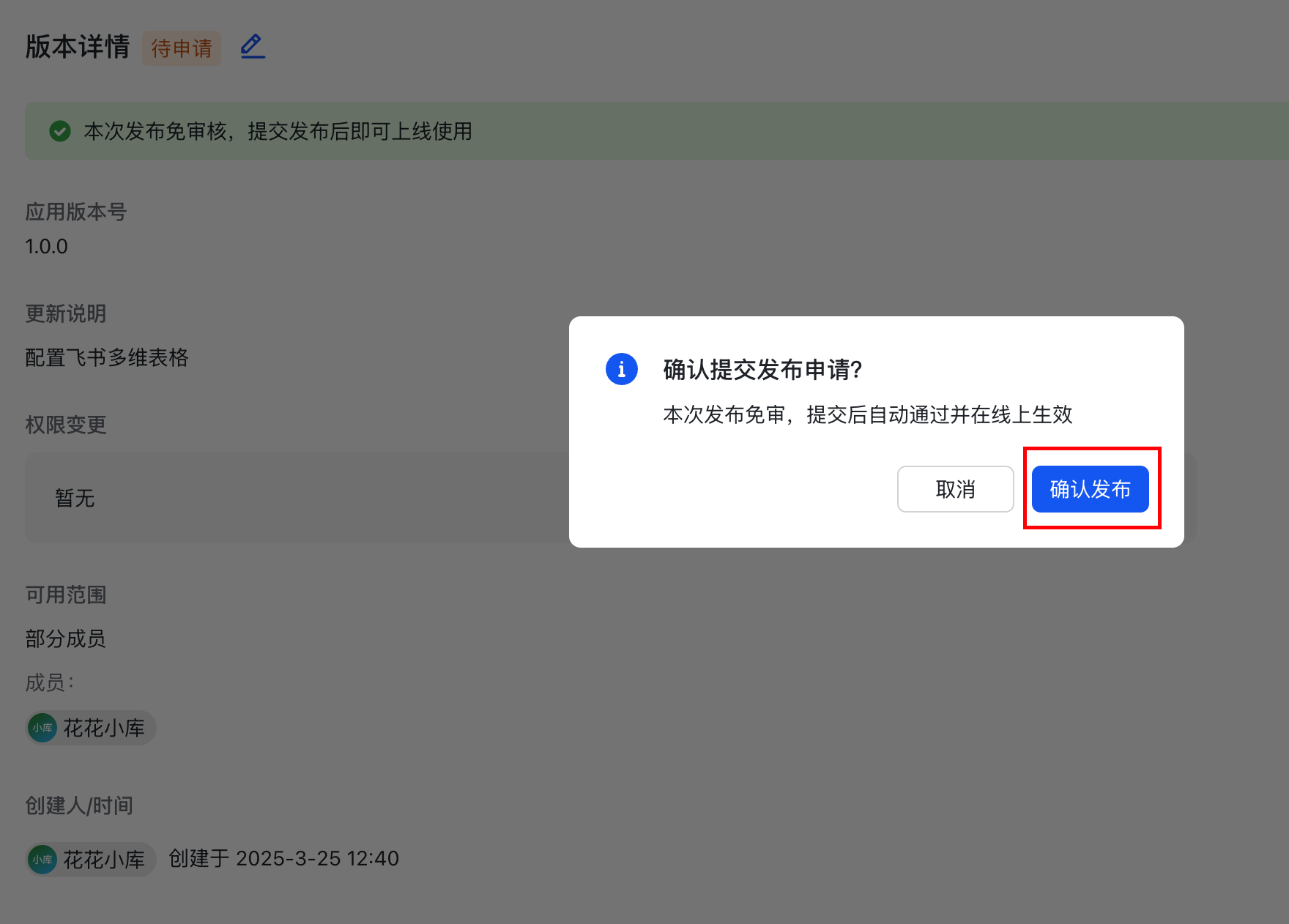
1.7.4 发布:
1.8 进入飞书文档,创建多维表格:
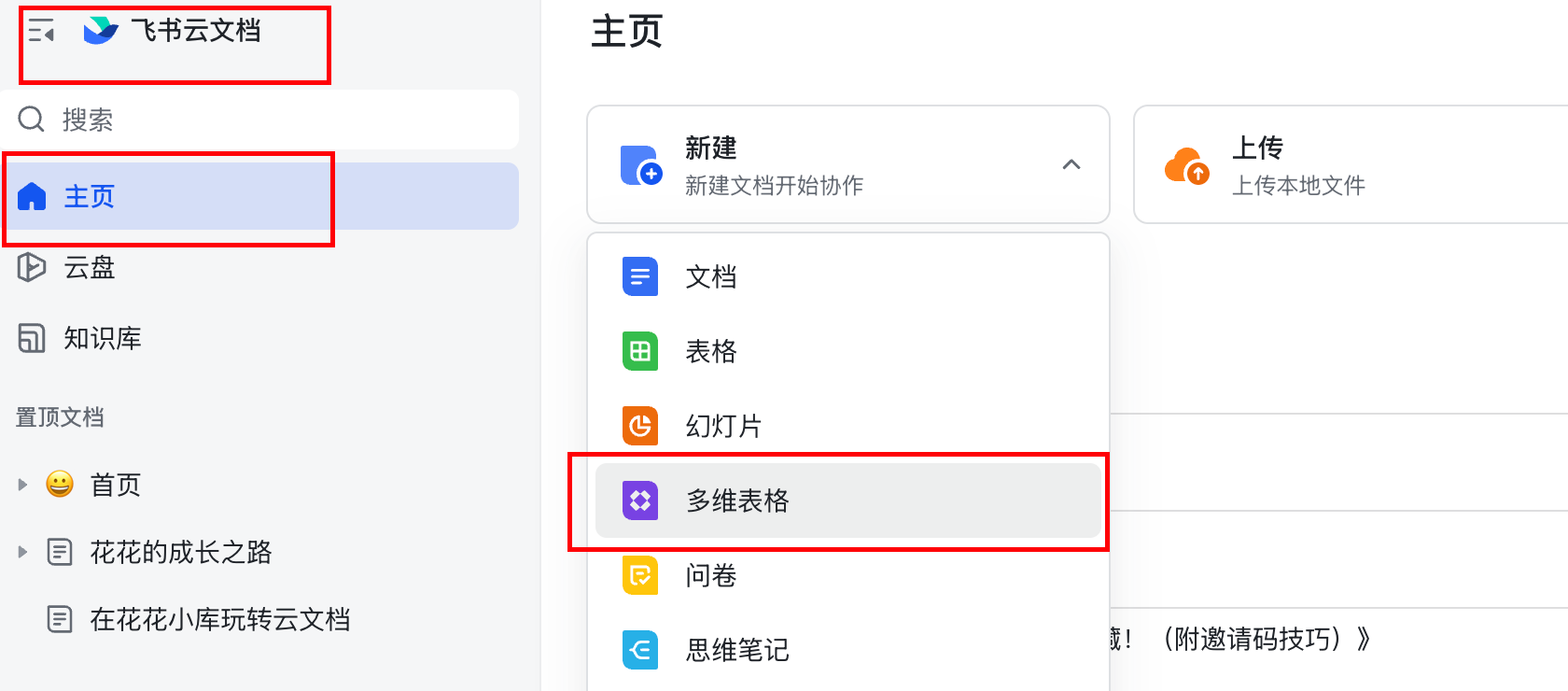
这里很重要。一定要变更 存储位置。
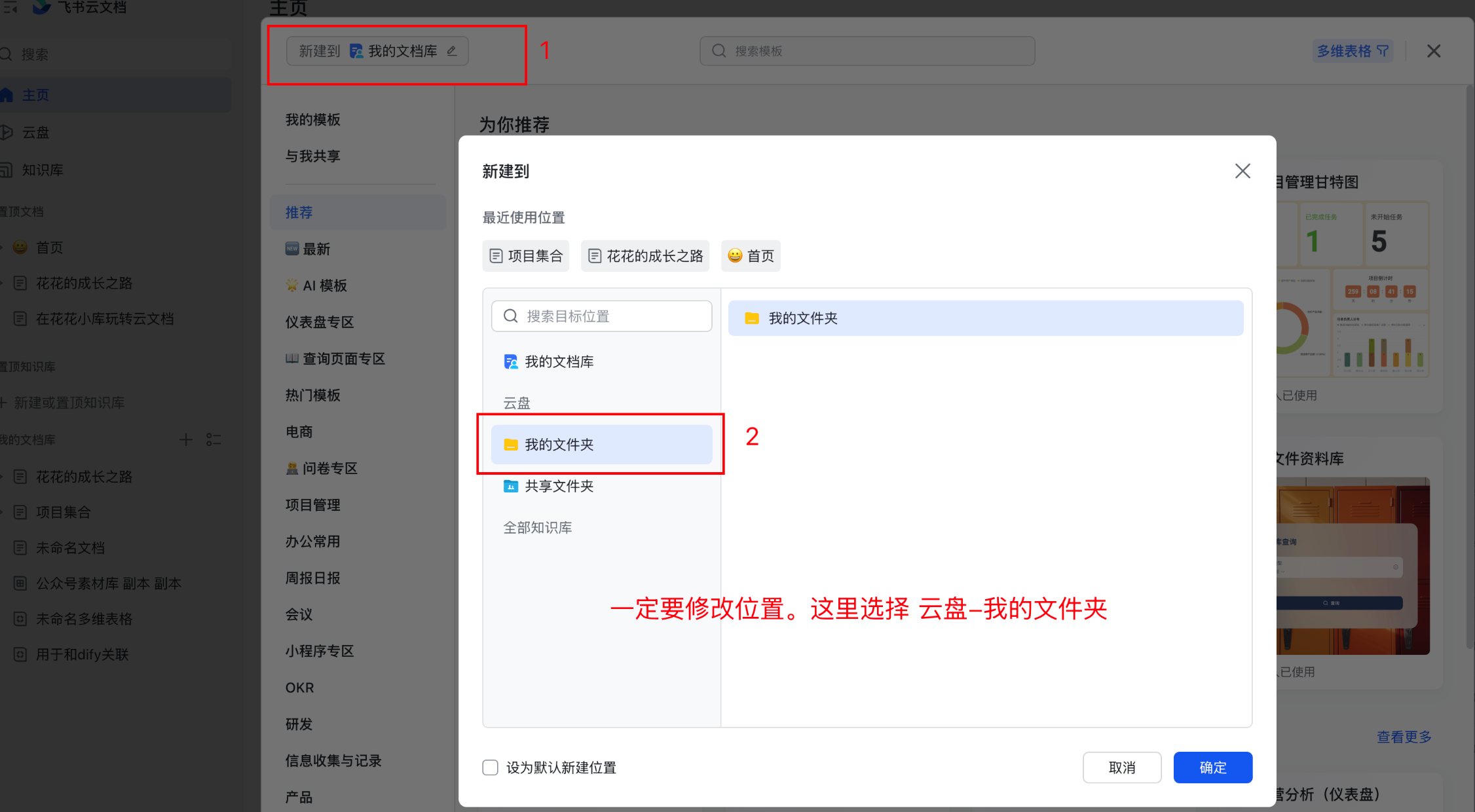
选择创建空白的即可。修改名称,我这里是: 用于和dify关联
1.9 实现自建应用与飞书多维表格的联通。
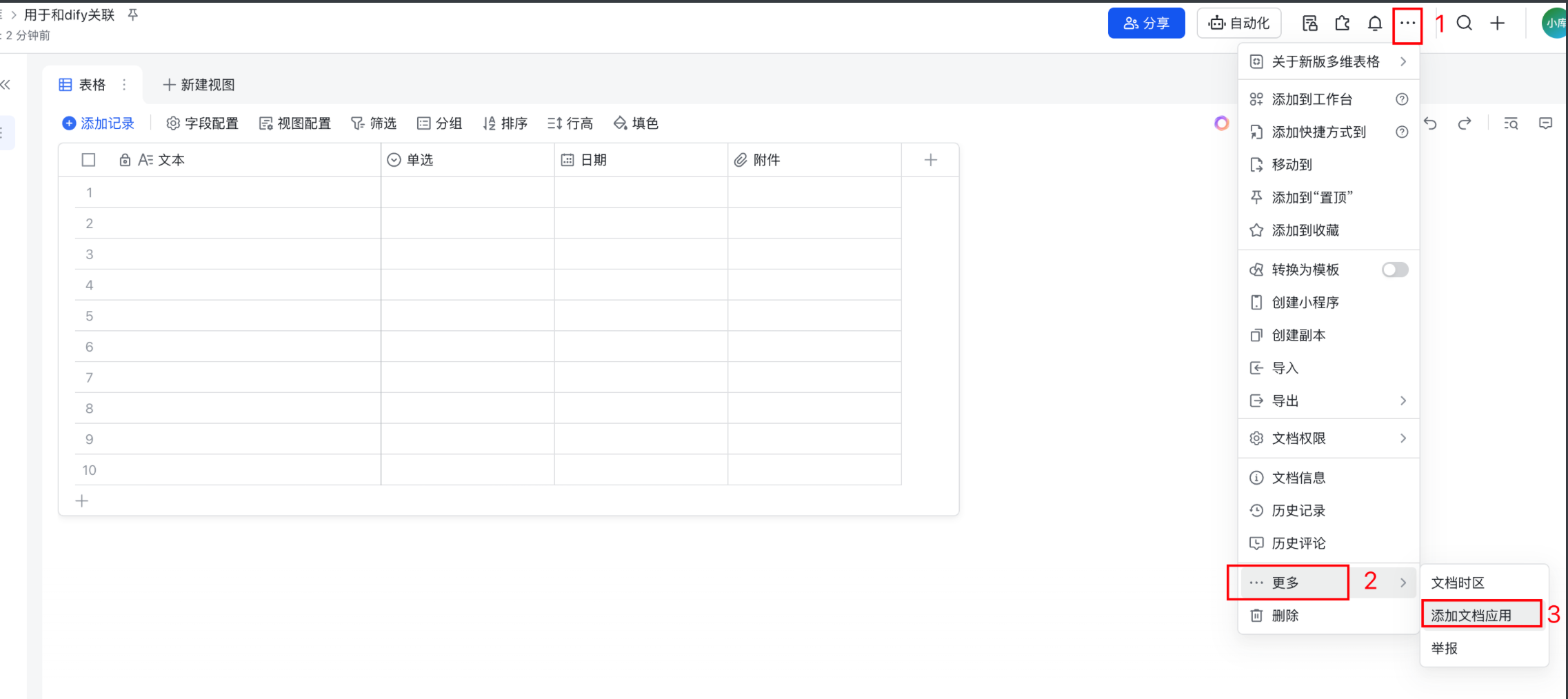
1.9.1 进入创建的多维表格;
点击右上角… 。 选择更多,添加文档应用。按照下图:1,2,3 操作即可。
在搜索框中输入: 1.2 中创建的应用名称。搜索展示出来应用。然后点击应用。

1.9.2 权限配置: 可编辑。然后点击 添加。
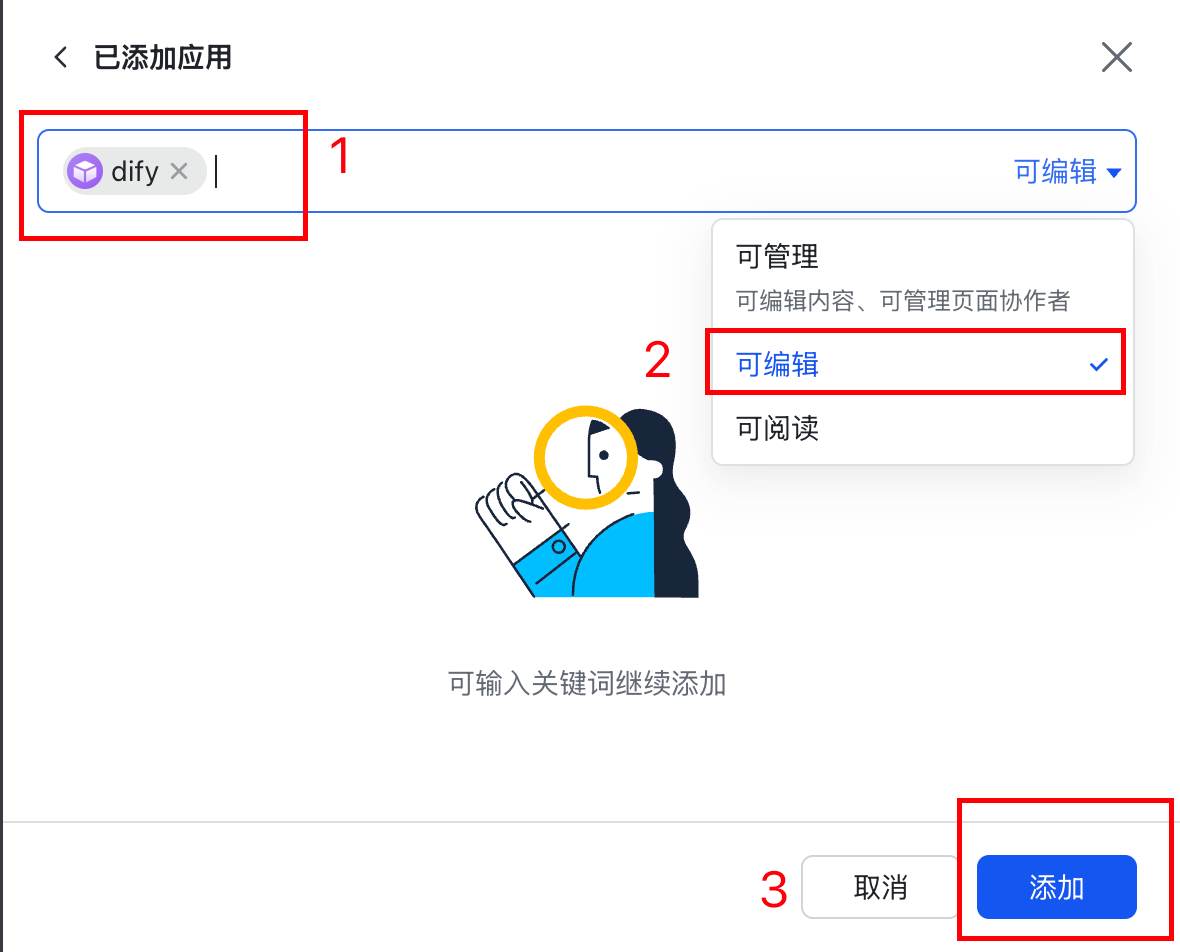
添加完成后,就实现了刚才的应用与飞书多维表格的联通。
二、多维表格结合Dify
使用之前创建的票据识别工作流:
DeepSeek+dify 工作流保姆级教程:票据识别专家智能体
进入工作流的地址:
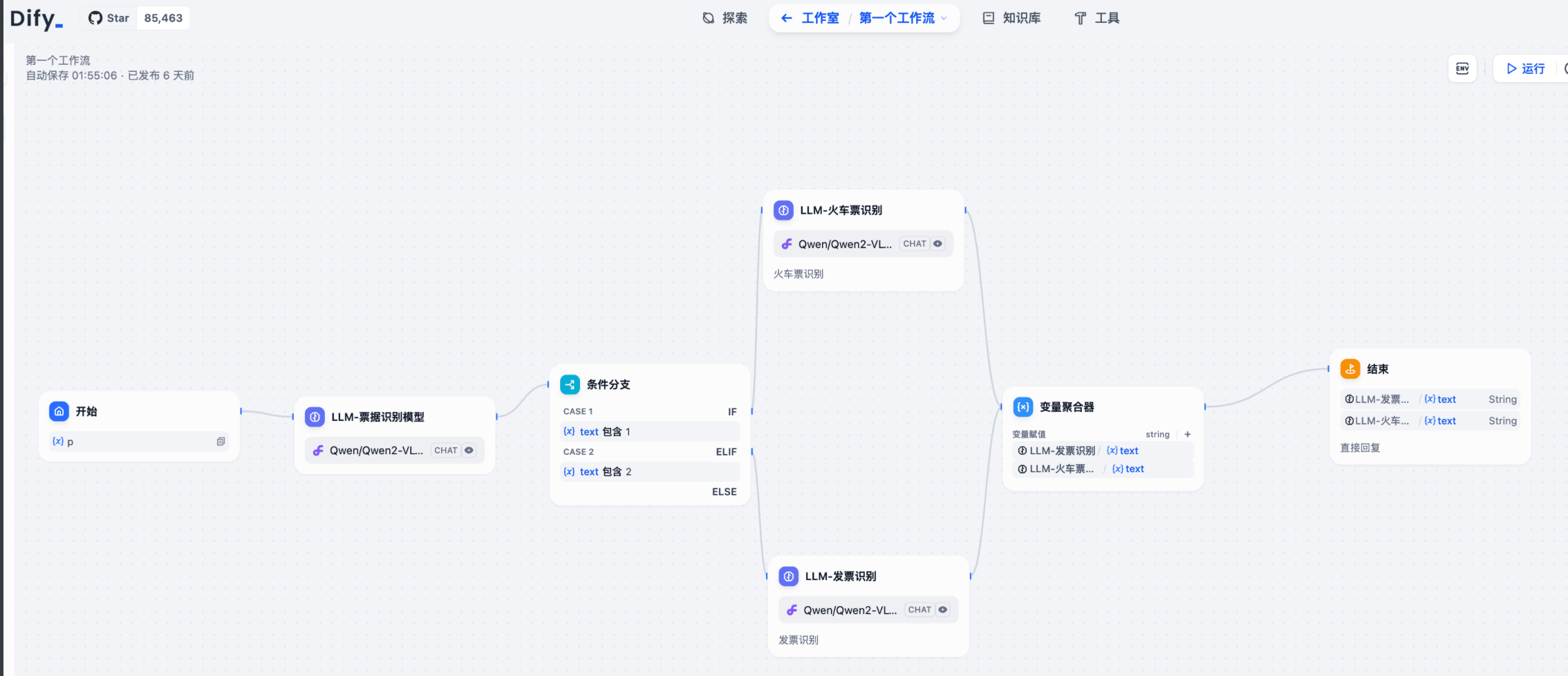
2.1 新增节点 【代码执行】:
在【 变量聚合器】 后面。
为的是把聚合后的数据处理一下,因为多维表格需要的是 json 数组。 我们的工作流输出的是: json 字符串。
配置节点信息:
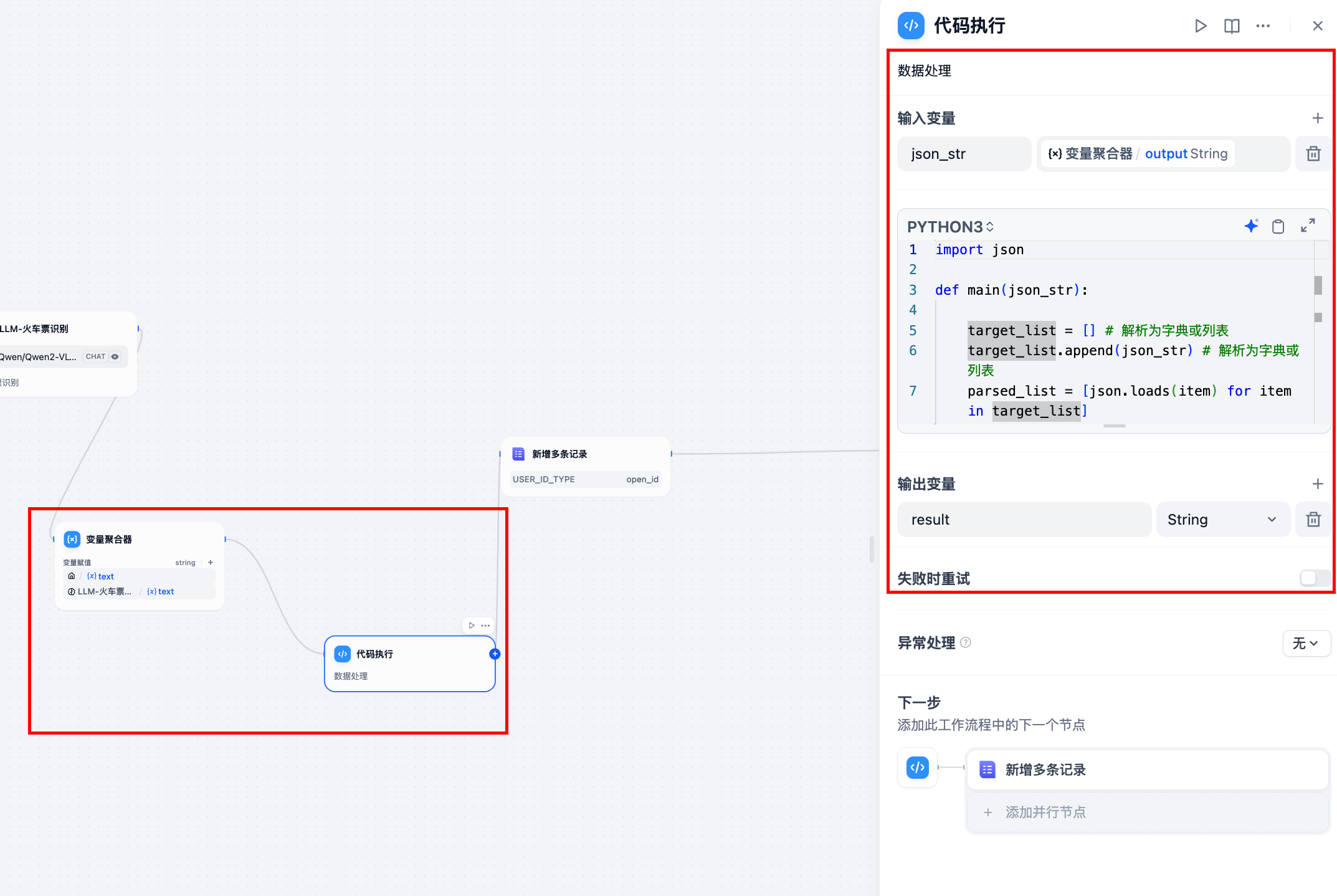
处理数据的代码:
import json def main(json_str):
target_list = [] # 解析为字典或列表
target_list.append(json_str) # 解析为字典或列表 parsed_list = [json.loads(item) for item in target_list]
strt =json.dumps(parsed_list, ensure_ascii=False)
return {'result': strt}
2.2 新增节点【新增多条记录】,在代码执行节点之后:
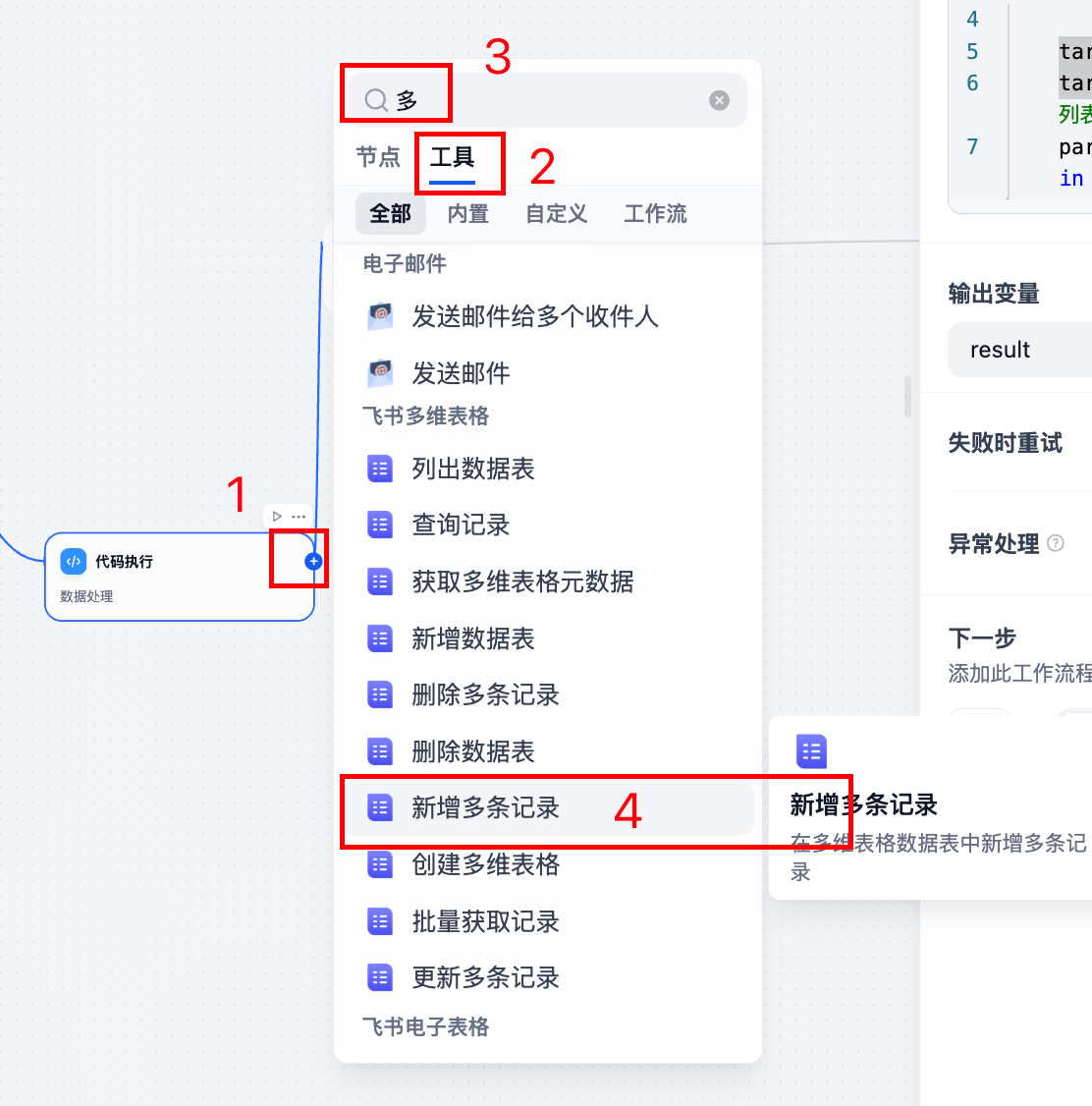
2.3 配置节点多维表格的信息:
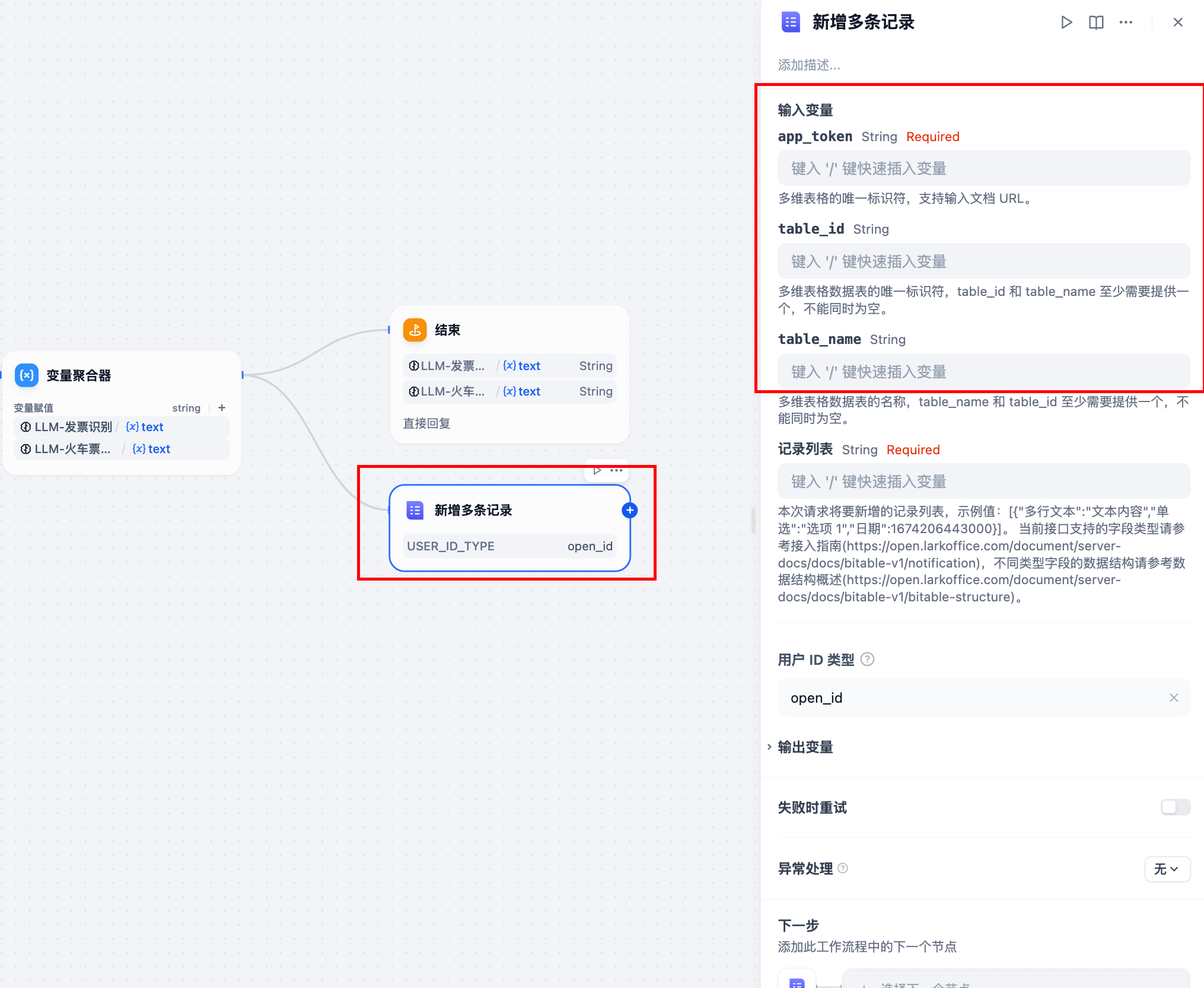
这个插件需要几个关键参数:
app_token:就是多维表格链接 url。table_id或者table_name:想要使用的数据表的 id。记录列表:要记录进表格中的内容,是一个列表结构。
依次去如下位置获得以上参数:
app_token
进入 1 中创建的多维表格。
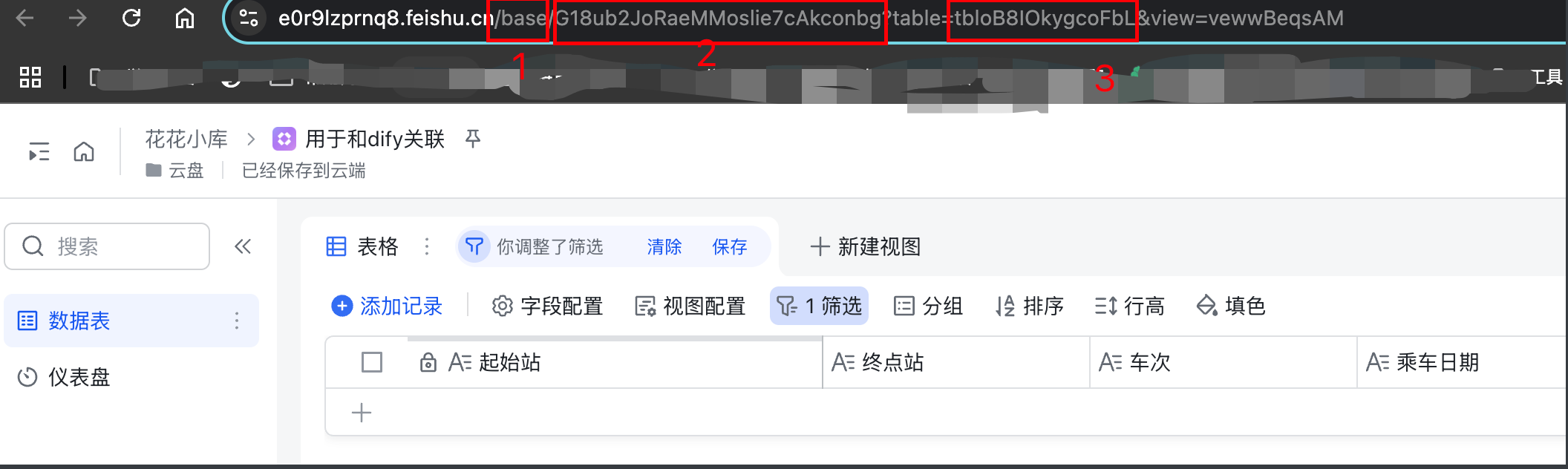
图中:1 必须是base 的。后面2 就是 app_token, 3 就是 table_id
table_id 或者 table_name
上图中的3.
记录列表
通俗的讲,就是输入的内容格式 key-value , key 要和多维表格中的列明一致。
比如:火车票这个识别工作流
[{ \"起始站\": \"兰州西\", \"终点站\": \"北京西\", \"车次\": \"G672\", \"乘车日期\": \"2019年07月22日\", \"出发时间\": \"07:56\", \"票面价格\": \"二等座\", \"身份证号\": \"\", \"姓名\": \"\"}]
多维表格就要设计为:列名要和 json 数组中对象的属性对应。
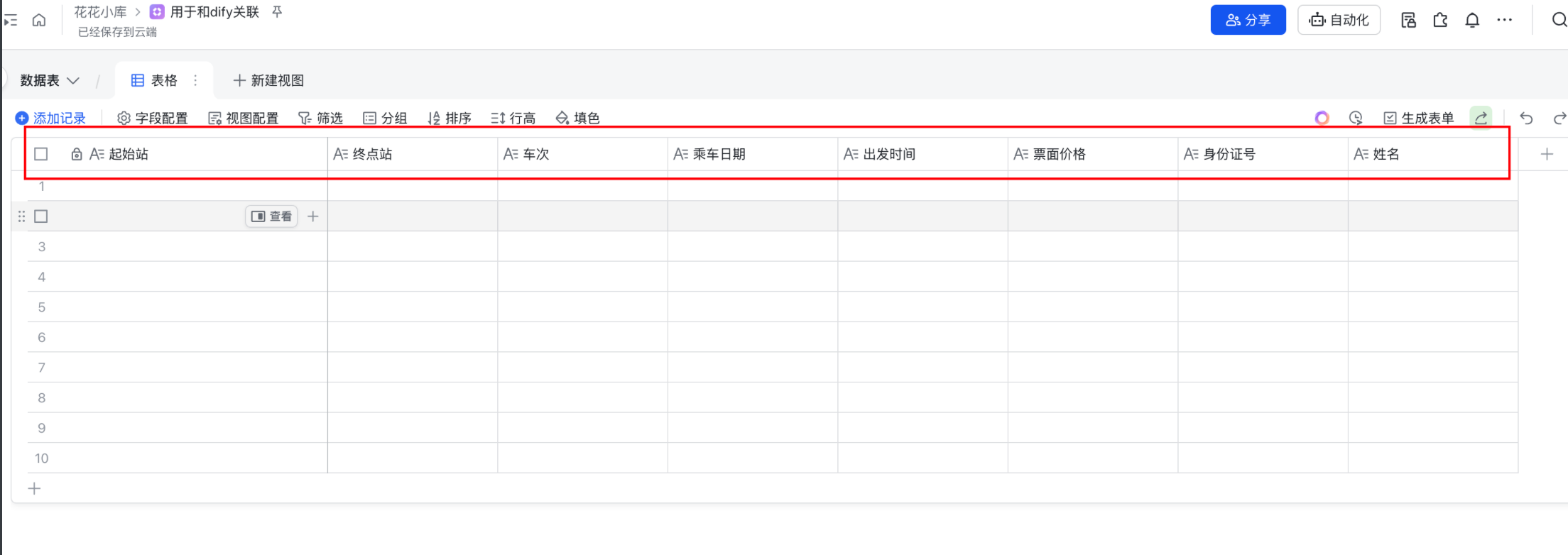
配置好后,如下:
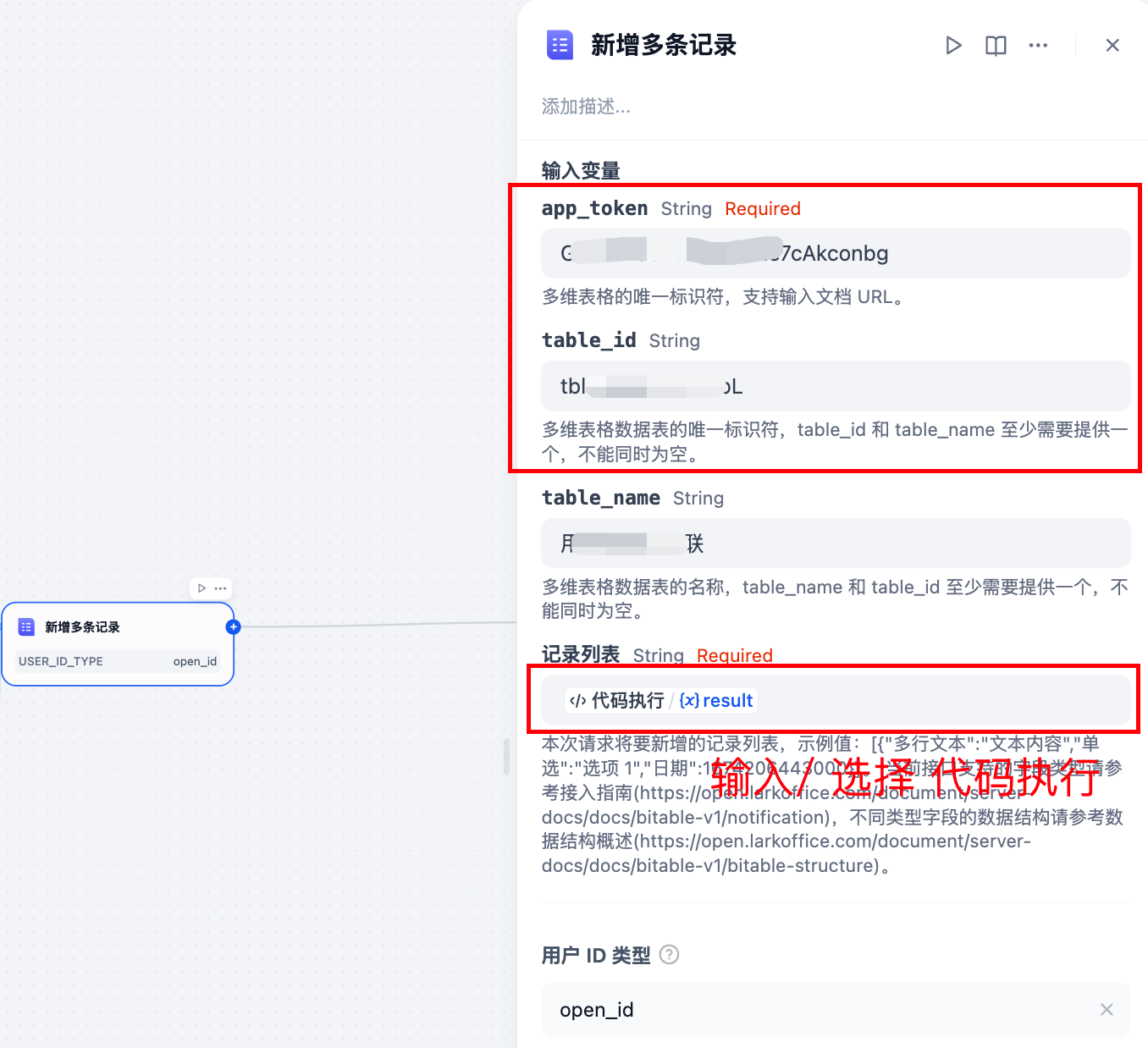
三、执行:
输入的信息如下
执行结果每一步都提示成功;
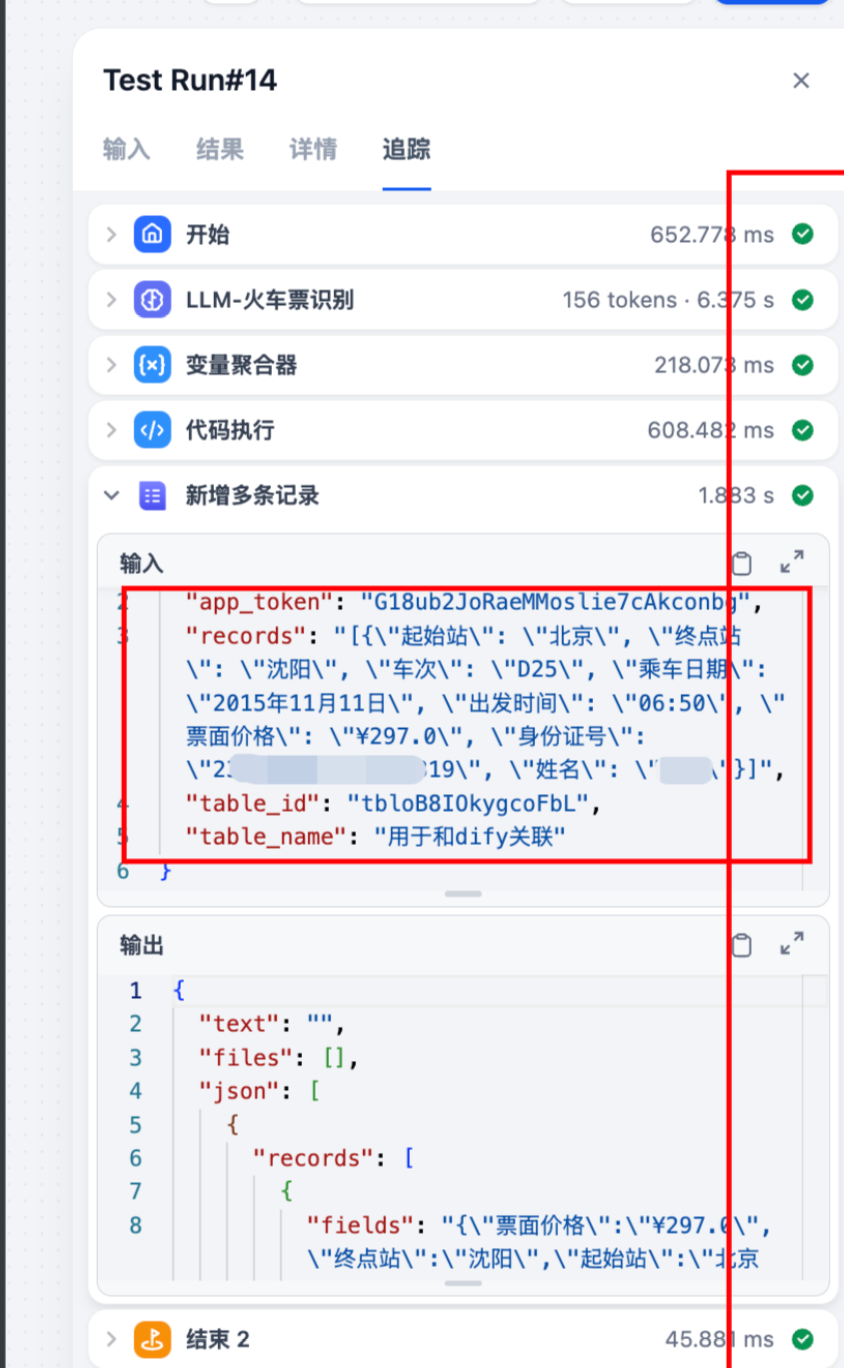
查看多维表格的数据:
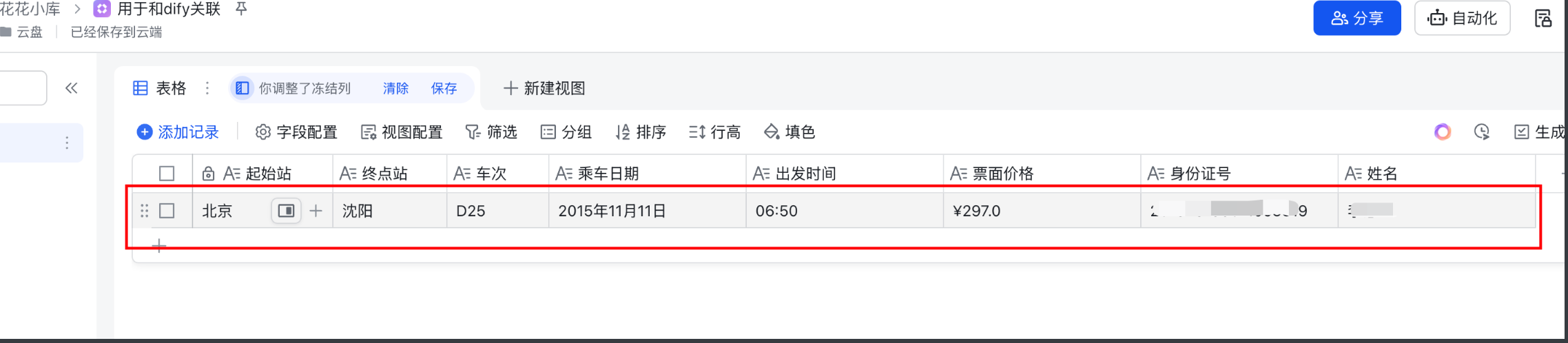
表格中的数据和输入的信息一致。
完美结束。

















 3293
3293

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









