







Java集合
牛客的课,整理笔记


Set

看集合重点看
1.数据结构,这个集合底层是如何实现的,数据是怎么存储的
2.数据的有序性是如何保证的
3.容量,能存多少,扩容机制,缩容机制
HashSet

可以看到Set底层是Map,所以简单看一下,主要逻辑在Map中看
但是这里map加了一个transient,指的是禁止序列化,map就是用来存数据的,为什么禁止序列化呢
因为set只是将数据存在了map的key部分,如果直接序列化,会有很多没有意义value被序列化,浪费空间
这里的PRESENT,是存数据时value部分的值,而不是null。为什么要这么做,因为set集合操作中可能会用到判断是否包含一个数据,或者删除,会用到比较,而如果是null的话,无法进行比较。这里定义为一个object起到了比较的作用

添加的方法
如果以前map中没有这个key,map.put方法会返回null,然后add方法就返回true,表示添加成功了
如果有这个key,会返回之前对应的value,不等于null,add方法返回false
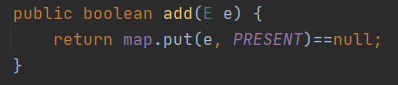
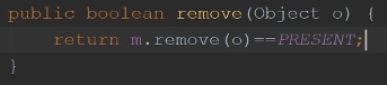
移除数据,如果之前有key,返回map.remove方法返回value,然后remove方法就返回true
否则返回false
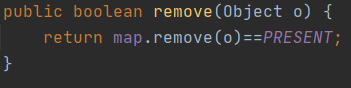
迭代器方法,返回set部分的迭代器
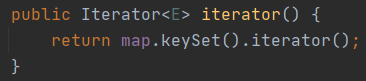
序列化方法,将对象写入流
关键点在于遍历了key部分,只序列化key部分

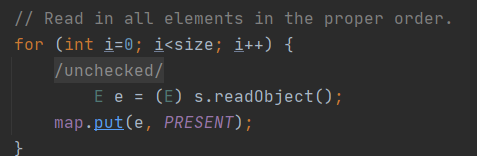
readObject将已经序列化过的流的数据中,转换回对象用的方法
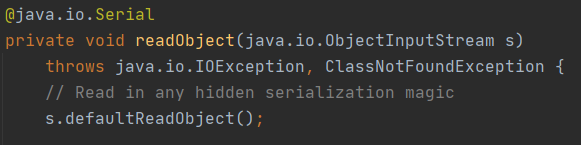
关键也在于for,size是流的字节数,读对象,然后存入提前创建的map中
TreeSet

TreeSet底层也是Map,NavigableMap 可排序的Map,也不能序列化
value存的也是PRESENT常量

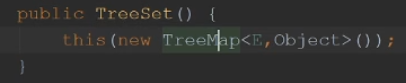
默认的构造器


List
重点
ArrayList

默认长度为10
这里有两个空的数组,一个EMPTY_ELEMENTDATA,一个DEFAULTCAPCITY_EMPTY_ELEMENTDATA
用来区分创建集合的时候,是按照默认长度构建的,还是传入了一个长度。用默认方式和传入长度方式创建扩容方法不一样


具体数组对象和元素的个数size

默认的构造器

传入长度,若传入0,初始化为一个空的数组,小于0报错

添加数据,先扩容,再添加数据

先计算容量,如果是默认构造器构造的数组,那么会考虑默认容量的大小;如果不是无参构造器构造的,那么就直接返回最小容量
计算完以后,传入ensureExplicitCapacity()方法,首先修改次数加一,如果最小容量减去当前数组长度大于0,就扩容;如果小于等于0了,那么说明出现问题了

扩容方法,新的容量,等于旧的容量的1.5倍
但是这个整型变量有可能会溢出
所以这里有个判断,如果新的容量减去旧的容量小于0,说明整数溢出变成负数了,那么就把最小容量赋给新容量
如果没有溢出,但是超过了数组最大的限制,掉hugeCapacity方法
数组扩容,数组不能动态改变。扩容要创建一个新的数组,把旧的数组数据拷贝到新数组中

数组最大限制

如果minCapacity小于0,说明整数溢出了,抛出异常
如果最小容量大于数组最大限制,如果大于,就返回整型最大值,否则,返回数组最大限制
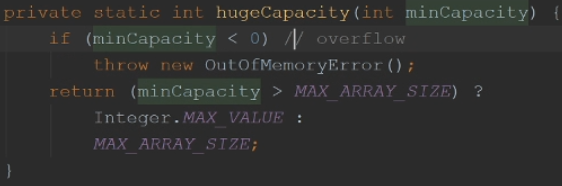
调用默认的迭代器,返回的是实例,是一个内部类Itr
另一个迭代器,增强迭代的能力,可以从后往前,从中间开始迭代,也支持插入,覆盖数据。一般ArrayList的迭代,建议使用这个迭代器
Itr类
cursor 当前迭代的索引下标,游标
lastRet上一次迭代的位置,为了能够更加灵活的迭代(另一个迭代器能从后往前迭代)
期望修改次数,赋值为修改次数。在迭代过程中,会判断是否已经修改,如果修改了,就不能迭代了。用于判断在迭代过程中,是否能对数据进行修改

next()迭代,找到下一个,会先检查修改次数

移除数据

检查修改次数,如果不相等,就抛出异常,意味着在迭代或者删除过程中,有人修改过数据

ListItr()
初始化,可以指定从哪个位置开始迭代

向前迭代

覆盖某一个值,把前一个值覆盖掉

把元素插到当前位置

主动缩容的方法
会把数组初始化为size大小的数组;如果size为0,那么就为空数组

LinkedList

size、首节点,尾节点


Node内部类,前驱和后继节点都有,双向链表

add加到末尾
add,指定位置的添加
如果等于size,就加到最后;如果不等于,就加到index前面


获取值
替换值

删除方法
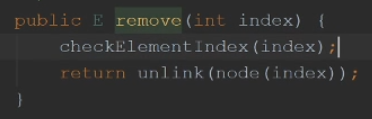
node()方法,获取索引位置处的节点
如果index小于size的一半,从前往后遍历;否则从后向前遍历

Queue和Deque
remove() element() 如果为空,抛出异常;poll() peek()如果为空,返回null




ArrayDeque

ArrayDeque 有一个数组

头指针,尾指针,最大容量为Integer.MAX_VALUE - 8,最小容量为8
tail指向尾部元素后一个元素的位置

构造器,默认初始化容量为16
或者指定元素个数,但是不是指定为几就初始化为几,而是要计算数组的多长合适,因为有最小长度的限制


如何计算
如果比最小容量大,那么要扩展到最接近的2的n次方
ArrayDeque的容量一定是2的n次方
如果溢出了,那么向右移一位

offer
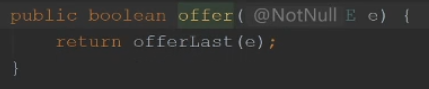
offerLast
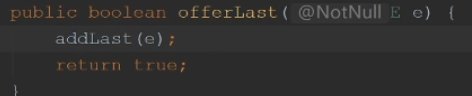
add
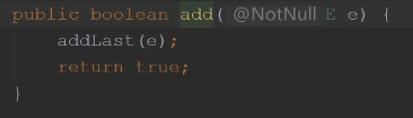
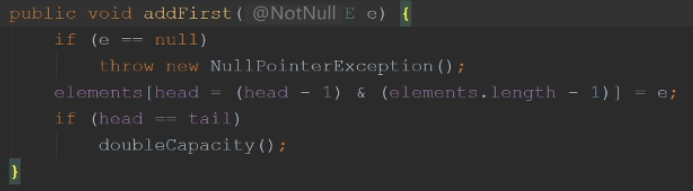
addFirst
(head - 1) & (length - 1)相当于做一个取模运算
如果到尾部了,就双倍扩容
这里创建双倍容量的数组拷贝的时候,先拷贝头指针右侧的元素到新数组0到r位置,然后再拷贝头指针左侧的元素,到新数组r到r + p位置
然后头指针指向0,尾指针指向n

删除头部元素,先把头指针指向的元素删了,然后把头指针右移一位
删除尾部元素,先把尾指针左边一位的位置元素删除了,然后把尾指针指向其左边一位(因为尾指针定义是尾节点的后面一位)

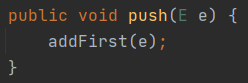
当做栈来用,入栈
出栈
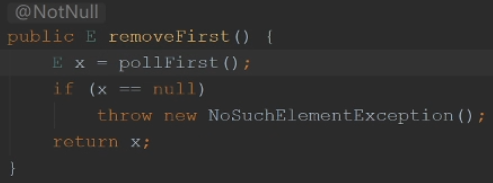
removeFirst又是由pollFirst实现的,如果为空,抛出异常
LinkedList

和之前一样的

入队 offer

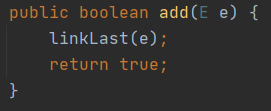
add调用linkLast()

linkFirst,先拿到链表头部节点f,然后头部指针指向新节点,然后将头部节点的前指针指向新节点

linkLast同理

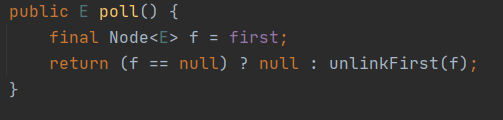
出队,poll


栈的方法
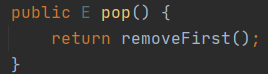

Map



有一个数组table,hashmap内部的数据都是通过这个数组来存储的,数组中的元素是以Node节点封装的
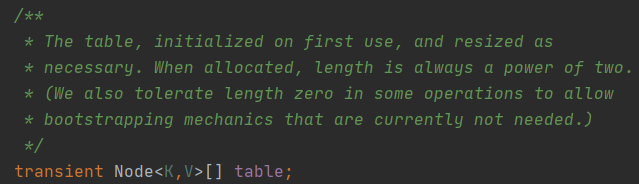
Node是一个内部类,因为hashmap里面是键值对,而每一个键值对都被封装成一个Entry。Node实现了Entry这个接口
有一个指针next指向了下一个节点,因此Node是单链表

Map.Entry 是接口Map中的一个接口

因此这里看出来,HashMap这里是一个数组,数组中的元素是Node,而Node是一个单向链表。是一个数组加单向链表的结构
树的结构:
TreeNode继承于LinkedHashMap中的内部类Entry,而Entry又继承于HashMap中的Node,而Node刚刚看到了,是继承Map.Entry的
因此TreeNode是间接的继承了Node的,因此如果有一个TreeNode,我们可以看成一个树,也可以看成一个链表;当链表转换为树的时候,是按照树的结构重组了链表,但是树中的节点还保留了链表的关系,所以由树还原退化成链表就非常方便


若元素为链表节点,并且长度达到8,不一定就转为树,可能是因为数组太小(小于64),碰撞太多,所以也可能尝试扩容

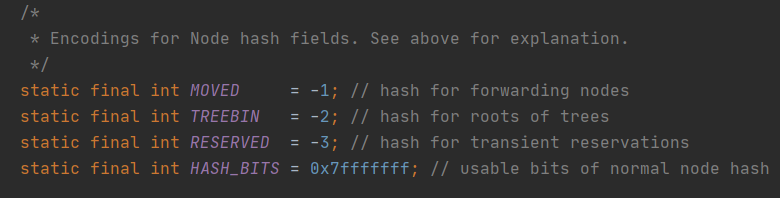
put存放数据要先计算key的哈希值

计算哈希值,有一个高位与低位的异或处理

首先,第一个if,如果数组为空,初次扩容resize()
第二步,第二个if,计算元素位置(hash & n - 1)相当于取模运算,获得数组中该位置的头节点,如果为null,那么就在这个位置新建一个链表节点
第三步,else中,第一个if,如果头节点的key和传入的key是相等的,那么直接覆盖value部分的值
否则,如果p节点是树节点,那么就加到树中,加完以后,返回添加后的节点
否则,一定就是链表了,首先从头开始遍历这个链表,如果p的后继节点为null,直接插到这个这个后继节点处;要注意这里,如果此时,bitCount大于等于8 - 1,则扩容或者转为树;如果发现要插入的节点是已经存在的节点(key相同),那么叫跳出循环。这段逻辑执行完,说明找到了要插入的位置
一般我们看,都会说如果大于等于8,那么链表就转换为树,而这里我们看到是7,问题也显而易见,我们插入一个元素后,bitcCount是7,所以此时链表的节点个数还是8个,也就是一般所说的大于等于8转换


如果此时e不等于null,就说明找到了一个位置插入这个值。先把这个节点的旧值存储下来
如果 !onlyIfAbsent,就是允许更新的话,那么就更新这个值
更新完以后,判断元素的数量是不是大于阈值,如果大于就扩容


扩容机制(重要)
这里扩容是将容量翻倍(一直是2的n次方),但是容量翻倍以后,按照常规理解,可能会将原哈希表中每一个值都重新计算一遍对新的容量大小取余,看放在哪个位置;但是这里如下图所示,在计算新的哈希值时,只需要看看索引多出来的一位是否是1,如果是1,那么就将原哈希表对应位置的元素放在新哈希表的高位(也就是加上当前扩容的容量,如下图的16),否则位置不变,即在低位。这样就使哈希表在扩容的时候,并没有那么复杂,而是只需要一个标志位,看看是否为1就可以了。这种运算非常高效

threshold,人为指定的容量
负载因子,比这个比率更大发生哈希碰撞的几率就高了,就要考虑扩容了,默认是0.75
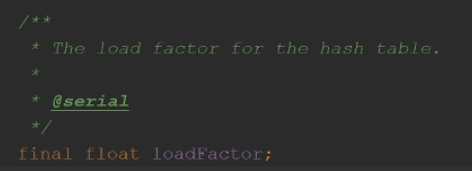
默认构造器里面,初始化了负载因子,0.75。容量是默认值


指定容量的构造器

初始化的容量,这里是有要求的,必须是2的n次方。如果不是2的n次方,会进行处理tableSizeFor

做一个运算,使得容量扩展到2的n次方

resize()扩容方法
threshold是一个参照值
第一个if,如果旧的容量是大于0的,并且已经扩到最大值了,那么就不再扩容了;如果左移一位以后小于最大值,并且旧容量大于默认初始化容量,就扩展到两倍
如果旧的容量不是大于0的,那么说明这个容量没有被初始化过,就参照threshold初始化容量,这里else if 如果旧的threshold大于0,那么就将这个值赋值给新容量,相当于初始化;否则,threshold没有给定,那么就初始化为默认的容量16,并且新的threshold等于默认容量乘以默认的负载因子

如果newThr是0,那么就算出一个临界值,即新的容量乘以负载因子
根据临界值,算出newThr

因为已经计算得到了新的数组的容量大小,所以接下来创建了新的数组,然后就要进行数据的迁移了
如果旧的数组不是空,那么就遍历旧的数组,取出数组当前位置的节点Node,然后清空当前位置。判断当前Node是否是只有一个节点,如果是,那么就直接计算应该放在高位还是低位(上面说过怎么计算),然后直接放到新的数组中
如果当前这个点是一颗树,我们就需要把这个点拆分开来再插入新的数组中

如果是链表,先定义五个变量。低位槽的首尾节点和高位槽的首尾节点,还有一个next
然后进入循环,如果当前e的哈希值和旧容量相与等于0,那么就加到低位槽中。否则加到高位槽中。这个循环里面只是在高低位都形成一个链表
当跳出循环,两个链表已经形成,然后就放入对应的槽中
最后返回形成的新的数组


处理树的split方法,逻辑和处理链表类似,首先对节点位置进行分配,然后再加入到槽中

第一个for循环,处理各个节点应该在高位还是低位
这里的next其实还是和链表的next是一样的,并没有把这个红黑树当成树来看待。这里逻辑和刚刚链表是一样的

但是在插入新数组的时候,如果链表的长度是小于等于6的话,会把这个树转回成链表的形式,否则还是以树的形式存储


get方法

getNode
首先计算hash值应该在的位置,并且将该位置的点赋值给first,也就是头节点
然后进一步判断,传入的key是否是头节点的key,如果是,就返回头节点
否则,判断头节点是否是树,如果是树,再调用树的方法得到Node
如果不是树,那么就是链表,就遍历链表中的每一个节点

得到所有key的集合Set

KeySet是一个内部类,里面有一个iterator()方法,返回一个具体的迭代器

而具体的迭代器里面很简单,只有一个next()方法

继承的父类
这里有一个构造器,里面一个循环,找到数组中不为空的位置,用next指向这个槽的头节点

nextNode中的核心逻辑和构造器中一样, 也是找一个不为空的槽开始从头节点迭代

这个支持树结构的最小容量意思是说,当数组容量很小的时候,发生碰撞会认为是因为数组容量太小导致的,不会将链表转为树。只有当数组容量大小到达64的时候,才会开始将链表转为树


有一个根节点root,类型是Entry,一个比较器

可以看到是一颗红黑树

默认的构造方法,比较器为null,自然排序
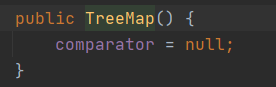
定制排序

TreeMap的key必须要实现Comparator接口,因为要调用compareTo方法

put方法
如果根等于null,要新建一个根,但是在创建之前会自己和自己比较,这里的目的是对key做检查,因为key有可能为null,或者key没有实现Comparator接口

如果比较器不为空,那么比较当前节点和节点 t 的key,如果小于,那么向左子树走,如果大于,右子树;相等直接覆盖
else中,比较器为空,同样的逻辑,
这段代码是为了找到要插入的位置

然后创建这个节点,直接挂在相应位置,返回

Collections

同步集合synchronized…()

这个类内部很多这种方法

传入一个集合实例,转换成线程安全的集合(list,set,queue)
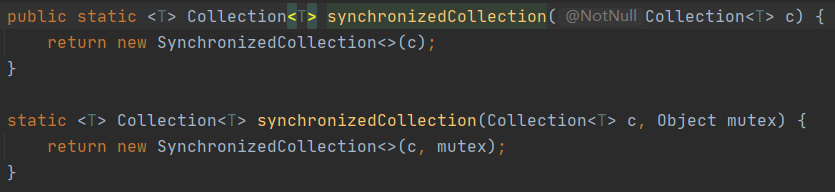
这个类也实现了Collection,有Collection的所有方法,但是在实现过程中,通过锁将传入实例的效果增强了。
mutex锁

这里基本上所有的方法都加了锁,除了迭代器
如果要想加锁,需要用户自己加锁

map的转化


所有的方法都加锁了,迭代也加锁了

不变集合(空集合、一个对象的集合、不可变视图)



空的列表,所有的方法都是基于空列表实现的。比如size返回0,contains返回false,get永远抛出异常


集合中只有一个对象,方法也是基于此实现的


list变量是final的,不可修改
如果要修改,例如set,add,remove都抛出异常

JUC包下的集合

两类,一类CopyOnWrite,一类Concurrent

CopyOnWriteArrayList
写时复制技术,
读读,读写不互斥,不加锁;写写互斥,加锁
读写的冲突是通过复制新数组规避的, 写写互斥是通过加锁规避的
这种技术还有一个缺点,就是实时性不能保证,因为读是从旧数组中读,并不能读到正在更改的数据

重入锁 和 一个数组

无参构造器,长度为0的数组

传入数组的话,复制了一份被当前成员持有

传入一个集合,会将集合中的数据拆开,转换成一个数组

读的方法,get,没有加锁
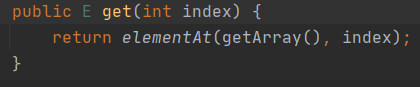

改,add加锁,先获取当前数组,然后将数组拷贝一份,改了以后,再替换原有数组。
但是替换以后,旧的数组不一定被垃圾回收,因为有可能有线程还在读。如果后续有线程读会读新的数组

迭代的方法

这里将数组赋给了一个snapshot,快照。迭代参照快照来读

ConcurrentHashMap




没有继承HashMap

两个table,第二个table是并发扩容用的,数据由table迁到nextTable中
在迁移的过程中,有一部分数组在table中,一部分在nextTable中,如有这时要读取数据,要看一下原来的table中有没有这个数据,如果有直接取,如果没有,table中会存一个重定向、转发的节点,可以理解为一个指针,指向nextTable
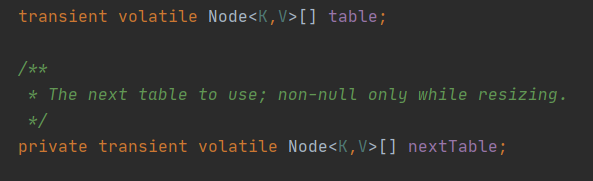
sizeCtl对初始化和扩容机制进行控制

无参构造器

传入map,sizeCtl等于默认容量

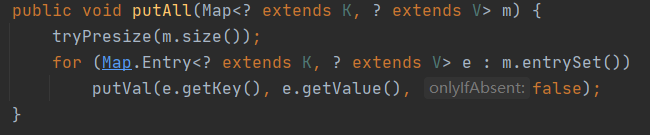
传入容量,先扩展到1.5倍,然后再扩展到2的n次方,这里 sizeCtl等于计算好的容量

concurrentLevel是并发级别,也就是并发线程数。例如如果电脑为8核,并发级别就是8
如果初始化容量,小于并发级别,那么提升到并发级别
然后计算size,cap,最终sizeCtl等于cap

put方法

这个逻辑和HashMap中put逻辑基本一致
首先迭代这个数组,如果数组是空的,就初始化这个数组;
如果不为空,那么判断传入的key的哈希值对应的槽位是否为空,如果为空,那么以cas原子的方式将这个节点放到这个槽中
如果这个槽位非空,如果f,即头节点的哈希值,等于状态值-1。等于-1说明这个槽正在扩容,当前槽里的数据正在往新的数组中迁移,扩容过程中会有意的将头节点的哈希值设置为-1;这个时候,如果要访问这个槽,应该当前线程被阻塞,等待,但是这里为了提高效率,与其阻塞,直接让当前线程也去帮助迁移数据
如果头节点没有锁,并且头节点的key和传入的key相同,那么就找到了要插入的位置,直接覆盖到头节点的val,并直接结束该方法

给头节点加锁(这里就可以看出锁的不是整个map,而是头节点)
如果fh>=0,那么说明是普通Node,是链表,那么就把传入的节点加到链表中去
否则加到树中

加进去以后,判断节点数量,大于阈值,转变为树
至此,put方法结束,那么有哪几个地方会导致扩容
第一个,第二个else if中,如果当前节点上锁,说明正在扩容
第二个,最后转换为树的时候
第三个,addCount,加1,超过阈值,扩容

initTable初始化方法
如果sizeCtl小于0,意味着有别的线程正在初始化,线程让步,转为就绪状态,进入下一轮抢夺
如果不小于0,那么尝试以CAS的方式将sizeCtl改为-1
把数组长度初始化为sc,并且将sc变为原来的3/4。即变成下一次扩容的阈值,即size达到这个阈值的时候,进行扩容

tabAt以cas的方式获取对应位置的节点

看一下扩容方法,这里addCount的逻辑不细看了,直接看一下扩容的机制transfer

stride步长,算一下每个CPU处理多少个节点;如果CPU核数大于1,那么n/8,每个线程处理1/8个节点,然后再除以CPU核数,是它迁移节点的个数;否则,如果只有一个,只能自己迁移全部
如果迁移节点数小于最小范围,那么就强制设置为最小值,默认16
新的数组,是原数组长度的两倍(左移一位)
ForWardingNode 转发节点。如果把一个节点从旧数组迁移到新数组,那么旧数组应该为空,但是并发迁移持续过程中,如果有一个线程来查数据,那么该怎么办?需要在旧数组中存一个转发节点,查到这个节点,就去看新数组对应的槽,在那里读取数据

循环,有一个循环边界bound,记录并发遍历的边界,因为并发迁移是迁移其中某几个节点
advance表示从后向前遍历,位于范围之内
这里的关键是以cas的方式去修改TRANSFERINDEX,这个是迁移的进度。如果抢到了就去迁移它,并通过stride计算范围

如果越界,判断是否转换完成,如果完成,替换旧数组,并重新计算sizeCtl

如果数组中第i个位置为空了,意味着已经迁移完毕了,会将空值变成转发节点
如果头节点正在迁移,那么继续迁移
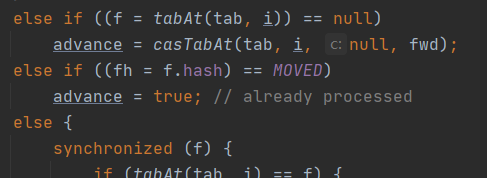
否则,对头节点加锁。
这里就是具体搬运数据,如果fh>=0,代表是链表,如果是链表,逻辑和HashMap中扩容的逻辑相似,分高位和低位

否则,是一个树的结构,但同样也是用链表处理的


get方法,读的时候不用加锁


补充:LinkedHashMap
LinkedHashMap 刚好就比 HashMap 多一个功能,就是其提供有序,并且,LinkedHashMap的有序可以按两种顺序排列,一种是按照插入的顺序,一种是按照读取的顺序(LRU机制),而其内部是靠建立一个双向链表 来维护这个顺序的,在每次插入、删除后,都会调用一个函数来进行双向链表的维护,准确的来说,是有三个函数来做这件事,这三个函数都统称为 回调函数 ,这三个函数分别是:
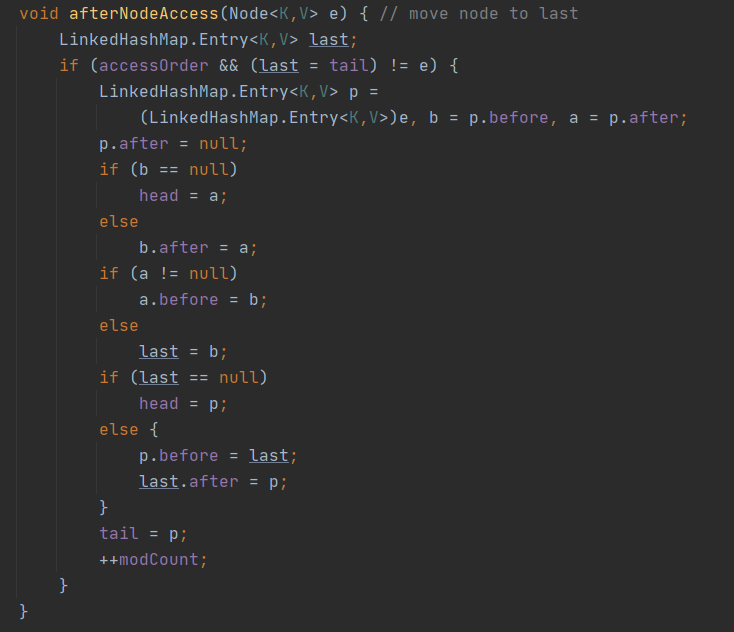
第一个函数:void afterNodeAccess(Node<K,V> p) { }
作用是在访问元素之后,将该元素放到双向链表的尾巴处(所以这个函数只有在按照读取的顺序的时候才会执行)
第二个:void afterNodeRemoval(Node<K,V> p) { }
其作用就是在删除元素之后,将元素从双向链表中删除
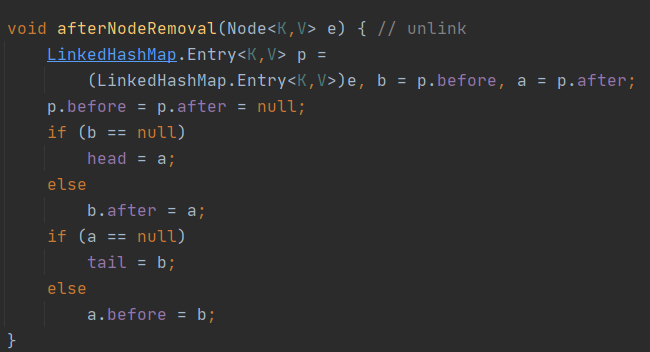
第三个:void afterNodeInsertion(boolean evict) { }
在插入新元素之后,需要回调函数判断是否需要移除一直不用的某些元素。

补充:集合中元素能否为null
















 391
391











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









