






NVME init 初始化
pci_register_driver注册驱动到PCI 总线上
static int __init nvme_init(void)
{
BUILD_BUG_ON(sizeof(struct nvme_create_cq) != 64);
BUILD_BUG_ON(sizeof(struct nvme_create_sq) != 64);
BUILD_BUG_ON(sizeof(struct nvme_delete_queue) != 64);
BUILD_BUG_ON(IRQ_AFFINITY_MAX_SETS < 2);
return pci_register_driver(&nvme_driver);
}
pci_register_driver
注册设备驱动匹配设备类型PCI_CLASS_STORAGE_EXPRESS
static const struct pci_device_id nvme_id_table[] = {
{ PCI_VDEVICE(INTEL, 0x0953),
.driver_data = NVME_QUIRK_STRIPE_SIZE |
NVME_QUIRK_DEALLOCATE_ZEROES, },
{ PCI_VDEVICE(INTEL, 0x0a53),
.driver_data = NVME_QUIRK_STRIPE_SIZE |
NVME_QUIRK_DEALLOCATE_ZEROES, },
{ PCI_VDEVICE(INTEL, 0x0a54),
.driver_data = NVME_QUIRK_STRIPE_SIZE |
NVME_QUIRK_DEALLOCATE_ZEROES, },
{ PCI_VDEVICE(INTEL, 0x0a55),
.driver_data = NVME_QUIRK_STRIPE_SIZE |
NVME_QUIRK_DEALLOCATE_ZEROES, },
{ PCI_VDEVICE(INTEL, 0xf1a5), /* Intel 600P/P3100 */
.driver_data = NVME_QUIRK_NO_DEEPEST_PS |
NVME_QUIRK_MEDIUM_PRIO_SQ |
NVME_QUIRK_DISABLE_WRITE_ZEROES, },
{ PCI_VDEVICE(INTEL, 0xf1a6), /* Intel 760p/Pro 7600p */
.driver_data = NVME_QUIRK_IGNORE_DEV_SUBNQN, },
{ PCI_VDEVICE(INTEL, 0x5845), /* Qemu emulated controller */
.driver_data = NVME_QUIRK_IDENTIFY_CNS |
NVME_QUIRK_DISABLE_WRITE_ZEROES, },
{ PCI_DEVICE(0x126f, 0x2263), /* Silicon Motion unidentified */
.driver_data = NVME_QUIRK_NO_NS_DESC_LIST, },
{ PCI_DEVICE(0x1bb1, 0x0100), /* Seagate Nytro Flash Storage */
.driver_data = NVME_QUIRK_DELAY_BEFORE_CHK_RDY |
NVME_QUIRK_NO_NS_DESC_LIST, },
{ PCI_DEVICE(0x1c58, 0x0003), /* HGST adapter */
.driver_data = NVME_QUIRK_DELAY_BEFORE_CHK_RDY, },
{ PCI_DEVICE(0x1c58, 0x0023), /* WDC SN200 adapter */
.driver_data = NVME_QUIRK_DELAY_BEFORE_CHK_RDY, },
{ PCI_DEVICE(0x1c5f, 0x0540), /* Memblaze Pblaze4 adapter */
.driver_data = NVME_QUIRK_DELAY_BEFORE_CHK_RDY, },
{ PCI_DEVICE(0x144d, 0xa821), /* Samsung PM1725 */
.driver_data = NVME_QUIRK_DELAY_BEFORE_CHK_RDY, },
{ PCI_DEVICE(0x144d, 0xa822), /* Samsung PM1725a */
.driver_data = NVME_QUIRK_DELAY_BEFORE_CHK_RDY |
NVME_QUIRK_DISABLE_WRITE_ZEROES|
NVME_QUIRK_IGNORE_DEV_SUBNQN, },
{ PCI_DEVICE(0x1987, 0x5016), /* Phison E16 */
.driver_data = NVME_QUIRK_IGNORE_DEV_SUBNQN, },
{ PCI_DEVICE(0x1b4b, 0x1092), /* Lexar 256 GB SSD */
.driver_data = NVME_QUIRK_NO_NS_DESC_LIST |
NVME_QUIRK_IGNORE_DEV_SUBNQN, },
{ PCI_DEVICE(0x1d1d, 0x1f1f), /* LighNVM qemu device */
.driver_data = NVME_QUIRK_LIGHTNVM, },
{ PCI_DEVICE(0x1d1d, 0x2807), /* CNEX WL */
.driver_data = NVME_QUIRK_LIGHTNVM, },
{ PCI_DEVICE(0x1d1d, 0x2601), /* CNEX Granby */
.driver_data = NVME_QUIRK_LIGHTNVM, },
{ PCI_DEVICE(0x10ec, 0x5762), /* ADATA SX6000LNP */
.driver_data = NVME_QUIRK_IGNORE_DEV_SUBNQN, },
{ PCI_DEVICE(0x1cc1, 0x8201), /* ADATA SX8200PNP 512GB */
.driver_data = NVME_QUIRK_NO_DEEPEST_PS |
NVME_QUIRK_IGNORE_DEV_SUBNQN, },
{ PCI_DEVICE(0x1c5c, 0x1504), /* SK Hynix PC400 */
.driver_data = NVME_QUIRK_DISABLE_WRITE_ZEROES, },
{ PCI_DEVICE_CLASS(PCI_CLASS_STORAGE_EXPRESS, 0xffffff) },
{ PCI_DEVICE(0x2646, 0x2263), /* KINGSTON A2000 NVMe SSD */
.driver_data = NVME_QUIRK_NO_DEEPEST_PS, },
{ PCI_DEVICE(PCI_VENDOR_ID_APPLE, 0x2001),
.driver_data = NVME_QUIRK_SINGLE_VECTOR },
{ PCI_DEVICE(PCI_VENDOR_ID_APPLE, 0x2003) },
{ PCI_DEVICE(PCI_VENDOR_ID_APPLE, 0x2005),
.driver_data = NVME_QUIRK_SINGLE_VECTOR |
NVME_QUIRK_128_BYTES_SQES |
NVME_QUIRK_SHARED_TAGS },
{ 0, }
};
MODULE_DEVICE_TABLE(pci, nvme_id_table);
NVMe Spec定义NVMe设备的Class code=0x010802h, 如下图。

probe 函数主要为每个cpu core分配queue。
queues为每个core分配一个io queue,所有的core共享一个admin queue。这里的queue的概念,更严格的说,是一组submission queue和completion quque。关于SQ和CQ的概念请参考:
static int nvme_probe(struct pci_dev *pdev, const struct pci_device_id *id)
{
int node, result = -ENOMEM;
struct nvme_dev *dev;
unsigned long quirks = id->driver_data;
size_t alloc_size;
node = dev_to_node(&pdev->dev);
if (node == NUMA_NO_NODE)
set_dev_node(&pdev->dev, first_memory_node);
dev = kzalloc_node(sizeof(*dev), GFP_KERNEL, node);
if (!dev)
return -ENOMEM;
dev->nr_write_queues = write_queues;
dev->nr_poll_queues = poll_queues;
dev->nr_allocated_queues = nvme_max_io_queues(dev) + 1;
// 为每个cpu core分配queue。queues为每个core分配一个io queue,
//所有的core共享一个admin queue。这里的queue的概念,更严格的说,
//是一组submission queue和completion quque。
// 关于SQ和CQ的概念请参考:
dev->queues = kcalloc_node(dev->nr_allocated_queues,
sizeof(struct nvme_queue), GFP_KERNEL, node);
if (!dev->queues)
goto free;
dev->dev = get_device(&pdev->dev);
pci_set_drvdata(pdev, dev);
result = nvme_dev_map(dev);
if (result)
goto put_pci;
INIT_WORK(&dev->ctrl.reset_work, nvme_reset_work);
INIT_WORK(&dev->remove_work, nvme_remove_dead_ctrl_work);
mutex_init(&dev->shutdown_lock);
result = nvme_setup_prp_pools(dev);
if (result)
goto unmap;
quirks |= check_vendor_combination_bug(pdev);
/*
* Double check that our mempool alloc size will cover the biggest
* command we support.
*/
alloc_size = nvme_pci_iod_alloc_size(dev, NVME_MAX_KB_SZ,
NVME_MAX_SEGS, true);
WARN_ON_ONCE(alloc_size > PAGE_SIZE);
dev->iod_mempool = mempool_create_node(1, mempool_kmalloc,
mempool_kfree,
(void *) alloc_size,
GFP_KERNEL, node);
if (!dev->iod_mempool) {
result = -ENOMEM;
goto release_pools;
}
result = nvme_init_ctrl(&dev->ctrl, &pdev->dev, &nvme_pci_ctrl_ops,
quirks);
if (result)
goto release_mempool;
dev_info(dev->ctrl.device, "pci function %s\n", dev_name(&pdev->dev));
nvme_reset_ctrl(&dev->ctrl);
async_schedule(nvme_async_probe, dev);
return 0;
release_mempool:
mempool_destroy(dev->iod_mempool);
release_pools:
nvme_release_prp_pools(dev);
unmap:
nvme_dev_unmap(dev);
put_pci:
put_device(dev->dev);
free:
kfree(dev->queues);
kfree(dev);
return result;
}
nvme_dev_map 进行内存映射
static int nvme_dev_map(struct nvme_dev *dev)
{
//将dev转换成pci_dev
struct pci_dev *pdev = to_pci_dev(dev->dev);
if (pci_request_mem_regions(pdev, "nvme"))
return -ENODEV;
//将一个IO地址空间映射到内核的虚拟地址空间上去
if (nvme_remap_bar(dev, NVME_REG_DBS + 4096))
goto release;
return 0;
release:
pci_release_mem_regions(pdev);
return -ENODEV;
}
pci_request_mem_regions 对6个bar 把对应的这个几个bar保留起来,不让别人使用
调用pci_select_bars,这个函数的返回值是一个mask值,每一位代表一个bar(base address register),哪一位被置位了,就代表哪一个bar为非零。这个涉及到pci的协议,pci协议里规定了pci设备的配置空间里有6个32位的bar寄存器,代表了pci设备上的一段内存空间(memory、io)。
调用pci_request_selected_regions,这个函数的一个参数就是之前调用pci_select_bars返回的mask值,作用就是把对应的这个几个bar保留起来,不让别人使用。
调用ioremap。前面说到bar0对应的物理地址是0xfebd0000,在linux中我们无法直接访问物理地址,需要映射到虚拟地址,ioremap就是这个作用。映射完后,我们访问dev->bar就可以直接操作nvme设备上的寄存器了。但是代码中,并没有根据pci_select_bars的返回值来决定映射哪个bar,而是直接hard code成映射bar0,原因是nvme协议中强制规定了bar0就是内存映射的基址。而bar4是自定义用途,暂时还不确定有什么用。
原文链接:https://blog.csdn.net/weixin_39567943/article/details/111862258
static inline int
pci_request_mem_regions(struct pci_dev *pdev, const char *name)
{
return pci_request_selected_regions(pdev,
pci_select_bars(pdev, IORESOURCE_MEM), name);
}
对bar 0 的pci 总线地址进行ioremap 映射
static int nvme_remap_bar(struct nvme_dev *dev, unsigned long size)
{
struct pci_dev *pdev = to_pci_dev(dev->dev);
if (size <= dev->bar_mapped_size)
return 0;
if (size > pci_resource_len(pdev, 0))
return -ENOMEM;
if (dev->bar)
iounmap(dev->bar);
dev->bar = ioremap(pci_resource_start(pdev, 0), size);
if (!dev->bar) {
dev->bar_mapped_size = 0;
return -ENOMEM;
}
dev->bar_mapped_size = size;
dev->dbs = dev->bar + NVME_REG_DBS;
return 0;
}
当驱动程序需要访问PCI设备的某个BAR(Base Address Register,基地址寄存器)所映射的资源时,它首先使用pci_resource_start函数来获取该资源的起始地址。这个起始地址是PCI设备在物理内存或I/O端口空间中的实际地址。
pci_resource_start(pdev, 0)
其中,dev是指向PCI设备结构体的指针,bar是BAR的编号(通常为0到5)
pci_resource_start返回的地址是PCI设备在物理内存或I/O端口空间中的地址,而不是CPU可以直接访问的虚拟地址。如果驱动程序需要访问这个地址,它还需要使用ioremap函数将这个物理地址转换为一个虚拟地址。
此外,pci_resource_start函数返回的地址是在PCI总线域的地址,而不是在CPU的存储器域的地址。因此,在将这个地址用于访问PCI设备之前,还需要进行地址空间的转换。这通常是通过调用pci_resource_to_user函数来完成的
dev->dbs设置成dev->bar+4096。4096的由来是上面表里doorbell寄存器的起始地址是0x1000
原文链接:https://blog.csdn.net/MHD0815/article/details/136484934
nvme_reset_work
static void nvme_reset_work(struct work_struct *work)
{
struct nvme_dev *dev =
container_of(work, struct nvme_dev, ctrl.reset_work);
bool was_suspend = !!(dev->ctrl.ctrl_config & NVME_CC_SHN_NORMAL);
int result;
if (dev->ctrl.state != NVME_CTRL_RESETTING) {
dev_warn(dev->ctrl.device, "ctrl state %d is not RESETTING\n",
dev->ctrl.state);
result = -ENODEV;
goto out;
}
/*
* If we're called to reset a live controller first shut it down before
* moving on.
*/
if (dev->ctrl.ctrl_config & NVME_CC_ENABLE)
nvme_dev_disable(dev, false);
nvme_sync_queues(&dev->ctrl);
mutex_lock(&dev->shutdown_lock);
result = nvme_pci_enable(dev);
if (result)
goto out_unlock;
result = nvme_pci_configure_admin_queue(dev);
if (result)
goto out_unlock;
result = nvme_alloc_admin_tags(dev);
if (result)
goto out_unlock;
/*
* Limit the max command size to prevent iod->sg allocations going
* over a single page.
*/
dev->ctrl.max_hw_sectors = min_t(u32,
NVME_MAX_KB_SZ << 1, dma_max_mapping_size(dev->dev) >> 9);
dev->ctrl.max_segments = NVME_MAX_SEGS;
/*
* Don't limit the IOMMU merged segment size.
*/
dma_set_max_seg_size(dev->dev, 0xffffffff);
mutex_unlock(&dev->shutdown_lock);
/*
* Introduce CONNECTING state from nvme-fc/rdma transports to mark the
* initializing procedure here.
*/
if (!nvme_change_ctrl_state(&dev->ctrl, NVME_CTRL_CONNECTING)) {
dev_warn(dev->ctrl.device,
"failed to mark controller CONNECTING\n");
result = -EBUSY;
goto out;
}
result = nvme_init_identify(&dev->ctrl);
if (result)
goto out;
if (dev->ctrl.oacs & NVME_CTRL_OACS_SEC_SUPP) {
if (!dev->ctrl.opal_dev)
dev->ctrl.opal_dev =
init_opal_dev(&dev->ctrl, &nvme_sec_submit);
else if (was_suspend)
opal_unlock_from_suspend(dev->ctrl.opal_dev);
} else {
free_opal_dev(dev->ctrl.opal_dev);
dev->ctrl.opal_dev = NULL;
}
if (dev->ctrl.oacs & NVME_CTRL_OACS_DBBUF_SUPP) {
result = nvme_dbbuf_dma_alloc(dev);
if (result)
dev_warn(dev->dev,
"unable to allocate dma for dbbuf\n");
}
if (dev->ctrl.hmpre) {
result = nvme_setup_host_mem(dev);
if (result < 0)
goto out;
}
result = nvme_setup_io_queues(dev);
if (result)
goto out;
/*
* Keep the controller around but remove all namespaces if we don't have
* any working I/O queue.
*/
if (dev->online_queues < 2) {
dev_warn(dev->ctrl.device, "IO queues not created\n");
nvme_kill_queues(&dev->ctrl);
nvme_remove_namespaces(&dev->ctrl);
nvme_free_tagset(dev);
} else {
nvme_start_queues(&dev->ctrl);
nvme_wait_freeze(&dev->ctrl);
nvme_dev_add(dev);
nvme_unfreeze(&dev->ctrl);
}
/*
* If only admin queue live, keep it to do further investigation or
* recovery.
*/
if (!nvme_change_ctrl_state(&dev->ctrl, NVME_CTRL_LIVE)) {
dev_warn(dev->ctrl.device,
"failed to mark controller live state\n");
result = -ENODEV;
goto out;
}
nvme_start_ctrl(&dev->ctrl);
return;
out_unlock:
mutex_unlock(&dev->shutdown_lock);
out:
if (result)
dev_warn(dev->ctrl.device,
"Removing after probe failure status: %d\n", result);
nvme_remove_dead_ctrl(dev);
}
static int nvme_pci_configure_admin_queue(struct nvme_dev *dev)
{
int result;
u32 aqa;
struct nvme_queue *nvmeq;
result = nvme_remap_bar(dev, db_bar_size(dev, 0));
if (result < 0)
return result;
//获取nvme的版本信息
dev->subsystem = readl(dev->bar + NVME_REG_VS) >= NVME_VS(1, 1, 0) ?
NVME_CAP_NSSRC(dev->ctrl.cap) : 0;
if (dev->subsystem &&
(readl(dev->bar + NVME_REG_CSTS) & NVME_CSTS_NSSRO))
writel(NVME_CSTS_NSSRO, dev->bar + NVME_REG_CSTS);
result = nvme_disable_ctrl(&dev->ctrl);
if (result < 0)
return result;
//分配nvmeq结构体,并记录到dev->queues[]数组中,
//并分配submit queue 和complete queue所需要的空间
result = nvme_alloc_queue(dev, 0, NVME_AQ_DEPTH);
if (result)
return result;
nvmeq = &dev->queues[0];
aqa = nvmeq->q_depth - 1;
aqa |= aqa << 16;
writel(aqa, dev->bar + NVME_REG_AQA);
lo_hi_writeq(nvmeq->sq_dma_addr, dev->bar + NVME_REG_ASQ);
lo_hi_writeq(nvmeq->cq_dma_addr, dev->bar + NVME_REG_ACQ);
result = nvme_enable_ctrl(&dev->ctrl);
if (result)
return result;
nvmeq->cq_vector = 0;
nvme_init_queue(nvmeq, 0);
result = queue_request_irq(nvmeq);
if (result) {
dev->online_queues--;
return result;
}
set_bit(NVMEQ_ENABLED, &nvmeq->flags);
return result;
}
static int nvme_alloc_queue(struct nvme_dev *dev, int qid, int depth)
{
struct nvme_queue *nvmeq = &dev->queues[qid];
if (dev->ctrl.queue_count > qid)
return 0;
nvmeq->sqes = qid ? dev->io_sqes : NVME_ADM_SQES;
nvmeq->q_depth = depth;
//获取cp 的 dma addr
nvmeq->cqes = dma_alloc_coherent(dev->dev, CQ_SIZE(nvmeq),
&nvmeq->cq_dma_addr, GFP_KERNEL);
if (!nvmeq->cqes)
goto free_nvmeq;
if (nvme_alloc_sq_cmds(dev, nvmeq, qid))
goto free_cqdma;
nvmeq->dev = dev;
spin_lock_init(&nvmeq->sq_lock);
spin_lock_init(&nvmeq->cq_poll_lock);
nvmeq->cq_head = 0;
nvmeq->cq_phase = 1;
nvmeq->q_db = &dev->dbs[qid * 2 * dev->db_stride];
nvmeq->qid = qid;
dev->ctrl.queue_count++;
return 0;
free_cqdma:
dma_free_coherent(dev->dev, CQ_SIZE(nvmeq), (void *)nvmeq->cqes,
nvmeq->cq_dma_addr);
free_nvmeq:
return -ENOMEM;
}
static int nvme_alloc_sq_cmds(struct nvme_dev *dev, struct nvme_queue *nvmeq,
int qid)
{
struct pci_dev *pdev = to_pci_dev(dev->dev);
if (qid && dev->cmb_use_sqes && (dev->cmbsz & NVME_CMBSZ_SQS)) {
nvmeq->sq_cmds = pci_alloc_p2pmem(pdev, SQ_SIZE(nvmeq));
if (nvmeq->sq_cmds) {
nvmeq->sq_dma_addr = pci_p2pmem_virt_to_bus(pdev,
nvmeq->sq_cmds);
if (nvmeq->sq_dma_addr) {
set_bit(NVMEQ_SQ_CMB, &nvmeq->flags);
return 0;
}
pci_free_p2pmem(pdev, nvmeq->sq_cmds, SQ_SIZE(nvmeq));
}
}
//获取sq的dma_addr
nvmeq->sq_cmds = dma_alloc_coherent(dev->dev, SQ_SIZE(nvmeq),
&nvmeq->sq_dma_addr, GFP_KERNEL);
if (!nvmeq->sq_cmds)
return -ENOMEM;
return 0;
}
首先,调用dma_alloc_coherent为completion queue分配内存以供DMA使用。nvmeq->cqes为申请到的内存的虚拟地址,供内核使用。而nvmeq->cq_dma_addr就是这块内存的物理地址,供DMA控制器使用。
接着,调用nvme_alloc_sq_cmds来处理submission queue,假如nvme版本是1.2或者以上的,并且cmb支持submission queue,那就使用cmb。否则的话,和completion queue一样使用dma_alloc_coherent来分配内存。
之后,nvmeq->irqname表示的是注册中断时的名字,从nvme%dq%d可以看到,就是最后生成的nvme0q0和nvme0q1,一个是给admin queue的,一个是给io queue的。
原文链接:https://blog.csdn.net/zhuzongpeng/article/details/127377347
nvme_alloc_queue分配NVMe queue后,就要将nvme admin queue的属性以及已经分配的admin SQ/CQ内存地址写入寄存器。
NVMe Spec对AQA,ASQ,ACQ定义如下:



Host往SQ中写入命令, SSD往CQ中写入命令完成结果。SQ与CQ的关系,可以是一对一的关系,也可以是多对一的关系,但不管怎样,他们是成对的:有因就有果,有SQ就必然有CQ。
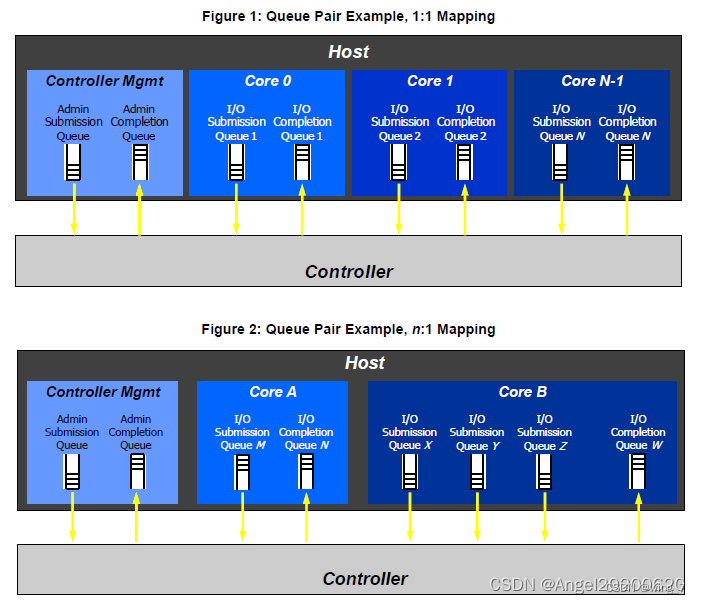
有两种SQ和CQ,一种是Admin,另外一种是I/O,前者放Admin命令,用以Host管理控制SSD,后者放置I/O命令,用以Host与SSD之间传输数据。Admin SQ/CQ 和I/O SQ/CQ各司其职,你不能把Admin命令放到I/O SQ中,同样,你也不能把I/O命令放到Admin SQ里面。
正如上图所示,系统中只有一对Admin SQ/CQ,它们是一一对应的关系;I/O SQ/CQ却可以很多,多达65535(64K减去一个SQ/CQ)。Host端每个Core可以有一个或者多个SQ,但只有一个CQ。给每个Core分配一对SQ/CQ好理解,为什么一个Core中还要多个SQ呢?一是性能需求,一个Core中有多线程,可以做到一个线程独享一个SQ;二是QoS需求,什么是QoS?Quality of Service,服务质量。为了解决卡顿现象,NVMe建议,设置两个SQ,一个赋予高优先级,一个低优先级,按照优先级来分配资源就是QoS。
实际系统中用多少个SQ,取决于系统配置和性能需求,可灵活设置I/O SQ个数。关于系统中I/O SQ的个数,NVMe白皮书给出如下建议: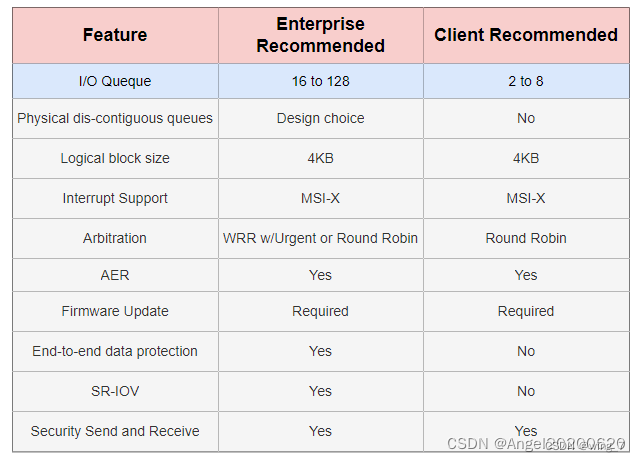
作为队列,每个SQ和CQ都有一定的深度,队列深度也是可以配置的:
对Admin SQ/CQ来说,其深度可以是2-4096(4K);
对I/O SQ/CQ,深度可以是2-65536(64K)。
SQ/CQ的个数可以配置,每个SQ/CQ的深度又可以配置,因此NVMe的性能是可以通过配置队列个数和队列深度来灵活调节的。NVMe命令队列的百般变化,更是AHCI无法做到的。
每个SQ放入的是命令条目,无论是Admin还是I/O命令,每个命令条目大小都是64字节;每个CQ放入的是命令完成状态信息条目,每个条目大小是16字节。
在继续谈(DB)之前,先对SQ和CQ做个小结:
SQ用以Host发命令,CQ用以SSD回命令完成状态
SQ/CQ可以在Host的内存中,也可以在SSD中,但一般在Host 内存中(所有系列文章都是基于SQ/CQ在Host内存中讲的);
两种类型的SQ/CQ:Admin和I/O,前者发送Admin命令,后者发送I/O命令;
系统中只能有一对Admin SQ/CQ,但可以有很多对I/O SQ/CQ;
I/O SQ与CQ可以是一对一的关系,也可以是一对多的关系;
I/O SQ是可以赋予不同优先级的;
I/O SQ/CQ深度可达64K,Admin SQ/CQ深达4K;
I/O SQ/CQ的广度和深度都可以灵活配置;
每条命令大小是64字节,每条命令完成状态是16字节。
SQ/CQ中的”Q”,是Queue,队列的意思,无论SQ还是CQ,都是队列,并且是环形队列。队列有几要素,除了队列深度,队列内容,还有两个重要的,就是队列的头(Head)和尾巴(Tail)。大家都排过队,你加入队伍的时候,都是站到队伍的最后,如果你插队,就会被鄙视。队伍最前头的那个,正在被服务或者等待被服务,一旦完成,就离开队伍。队列的头尾很重要,头决定谁会被马上服务,尾巴决定了新来的人站的位置。==DB,就是用来记录了一个SQ或者CQ的Head和Tail。每个SQ或者CQ,都有两个对应的DB: Head DB和Tail DB。DB是在SSD端的寄存器,记录SQ和CQ的头和尾巴的位置。
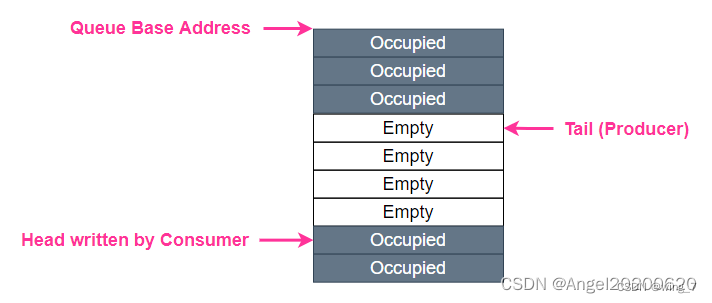
上面是一个队列的生产/消费模型。生产者往队列的Tail写入东西,消费者往队列的Head取出东西。对一个SQ来说,它的生产者是Host,因为它往SQ的Tail位置写入命令,消费者是SSD,因为它往SQ的Head取出指令执行;对一个CQ来说,刚好相反,生产者是SSD,因为它往CQ的Tail写入命令完成信息,消费者则是Host,它从CQ的Head取出命令完成信息。
开始假设SQ1和CQ1是空的,Head = Tail = 0.
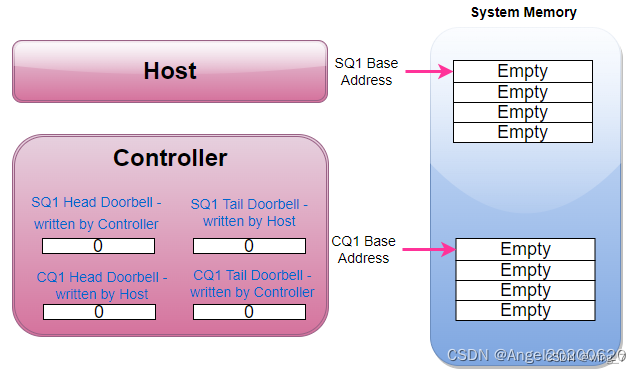
这个时候,Host往SQ1中写入了三个命令,SQ1的Tail则变成3。Host在往SQ1写入三个命令后,同时漂洋过海去更新SSD Controller端的SQ1 Tail DB寄存器,值为3。Host更新这个寄存器的同时,也是在告诉SSD Controller:有新命令了,需要你去取。
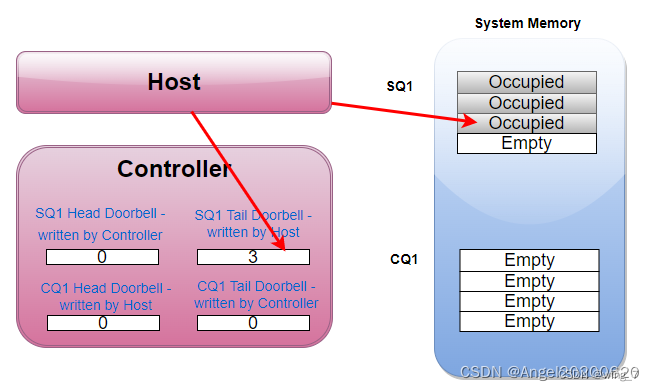
SSD Controller收到通知后,于是派人去SQ1把3个命令都取回来执行。SSD把SQ1的三个命令都消费了,SQ1的Head从而也调整为3,SSD Controller会把这个Head值写入到本地的SQ1 Head DB寄存器。
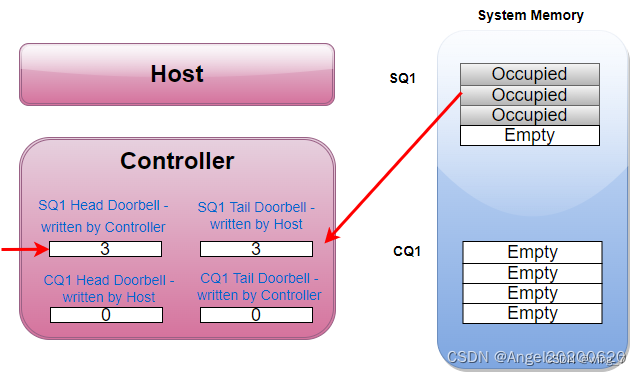
SSD执行完了两个命令,于是往CQ1中写入两个命令完成信息,同时更新CQ1对应的Tail DB 寄存器,值为2。SSD并且发消息给Host:有命令完成,请注意查看。
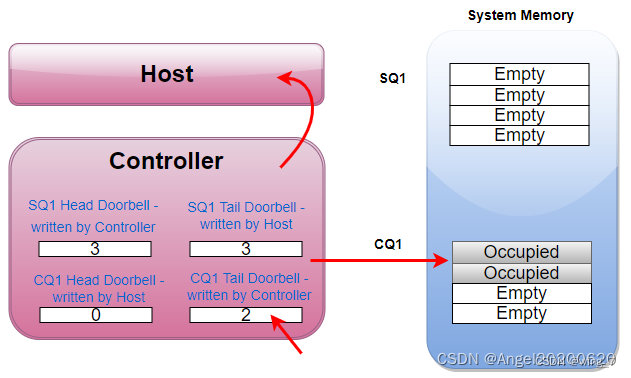
Host收到SSD的短信通知,于是从CQ1中取出那两条完成信息处理。处理完毕,Host又漂洋过海的往CQ1 Head DB寄存器中写入CQ1的head,值为2。
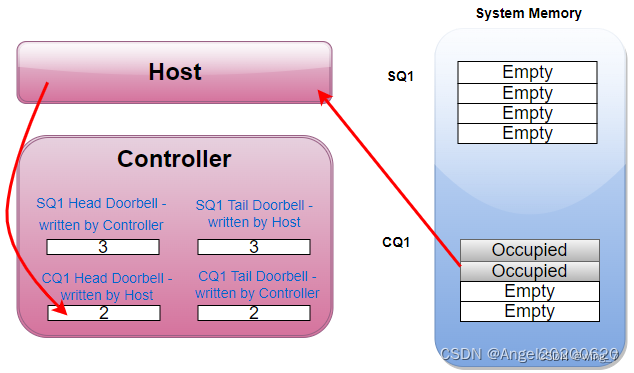
看完这个例子,又重温了一下命令处理流程。之前我们也许只记住了命令处理需要8步,看完上面的例子,我们应该对命令处理流程有个更深入具体的认识。
那么,DB在命令处理流程中起了什么作用呢?
首先,如前所示,它记住了SQ和CQ的头和尾。对SQ来说,SSD是消费者,它直接和队列的头打交道,很清楚SQ的头在哪里,所以SQ head DB由SSD自己维护;但它不知道队伍有多长,尾巴在哪,后面还有多少命令等待执行,相反,Host知道,所以SQ Tail DB由Host来更新。SSD结合SQ的头和尾,就知道还有多少命令在SQ中等待执行了。对CQ来说,SSD是生产者,它很清楚CQ的尾巴在哪里,所以CQ Tail DB由自己更新,但是SSD不知道Host处理了多少条命令完成信息,需要Host告知,因此CQ Head DB由Host更新。SSD根据CQ的头和尾,就知道CQ能不能以及能接受多少命令完成信息。
DB的另外一个作用,就是通知作用:Host更新SQ Tail DB的同时,也是在告知SSD有新的命令需要处理;Host更新CQ Head DB的同时,也是在告知SSD,你返回的命令完成状态信息我已经处理。
这里有一个对Host不公平的地方,Host对DB只能写,还仅限于写SQ Tail DB和CQ Head DB,不能读取DB。在这个限制下,我们看看Host是怎样维护SQ和CQ的。SQ的尾巴没有问题,Host是生产者,对新命令来说,它清楚自己应该站在队伍哪里。但是Head呢?SSD在取指的时候,是偷偷进行的,Host对此毫不知情。Host发了取指通知后,它并不清楚SSD什么时候去取命令,取了多少命令。给个提示: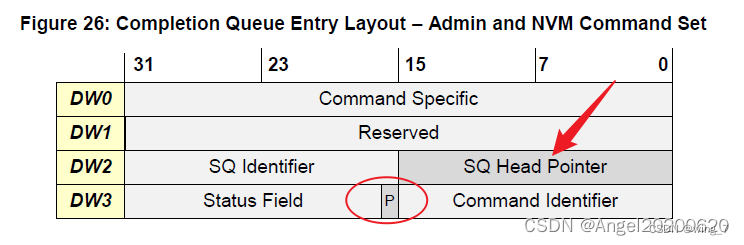
这是什么鬼东西?这是SSD往CQ中写入的命令完成状态信息(16字节)。
是的,SSD往CQ中写入命令状态信息的同时,还把SQ Head DB的信息告知了Host!!这样,Host对SQ中Head和Tail的信息都有了,轻松玩转SQ。
CQ呢?Host知道Head,不知道Tail。那怎么能知道Tail呢?思路很简单,既然你SSD知道,那你告诉我呗!SSD怎么告诉Host呢?还是通过SSD返回命令状态信息中。哈哈,看到上图中的“P”吗?干什么用,做标记用。
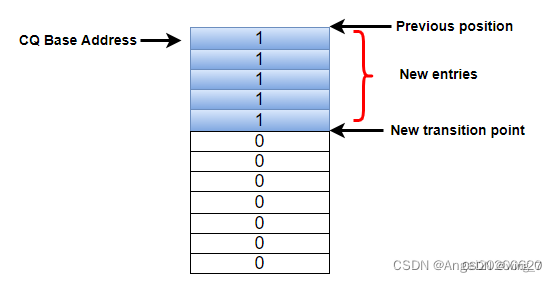
具体是这样的:一开始CQ中每条命令完成条目中的 “P” bit初始化为0,SSD在往CQ中写入命令完成条目时,会把 "P"写成1。记住一点,CQ是在Host端的内存中,Host可以检查CQ中的所有内容,当然包括”P”了。Host记住上次的Tail,然后往下一个一个检查”P”,就能得出新的Tail了。就是这样。
原文链接:https://blog.csdn.net/sinat_43629962/article/details/123985710















 6202
6202











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









