









一、整合流程图
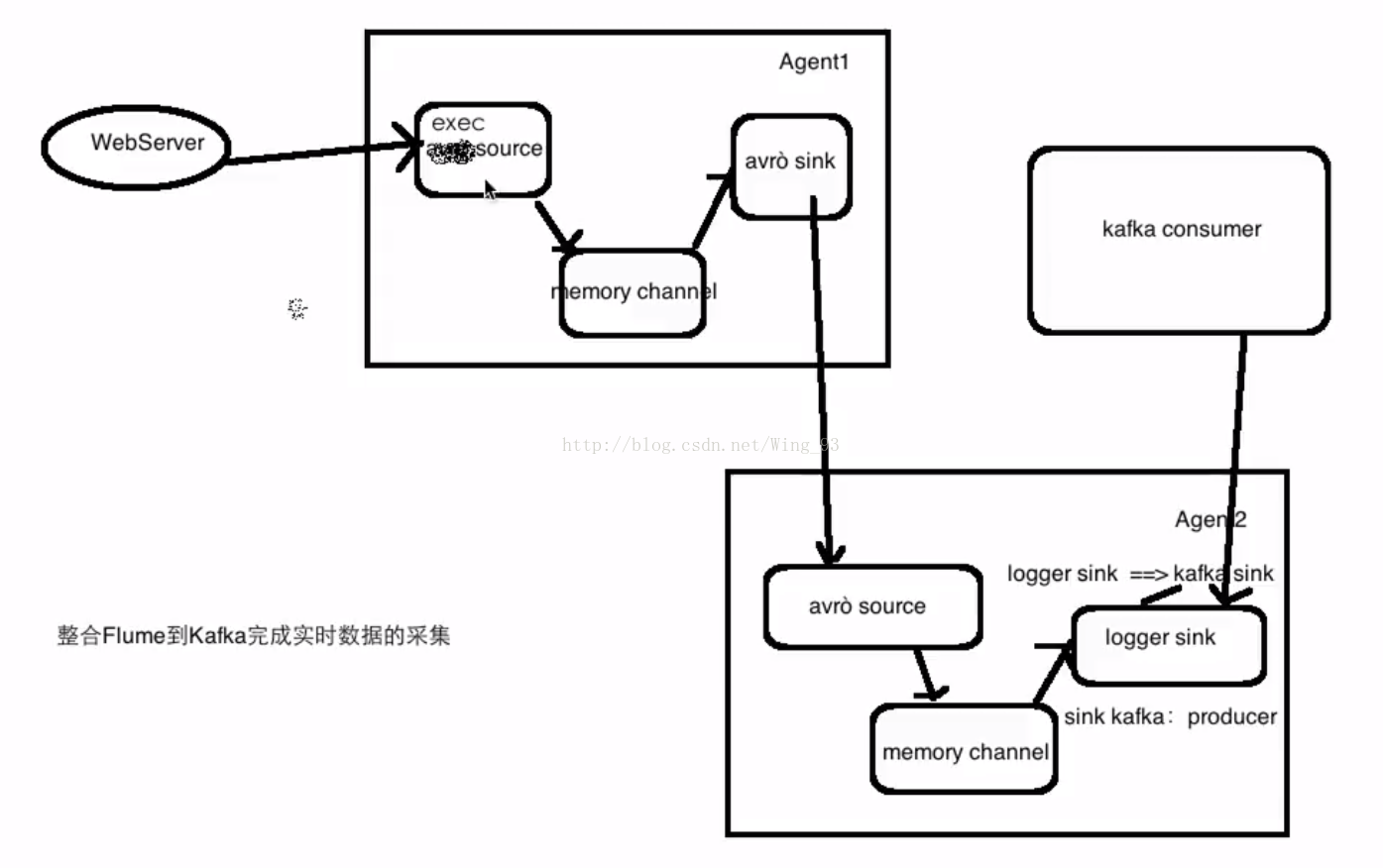
Flume收集WEB服务器的数据信息,然后再对Flume进行串联,即对Flume进行扩展,选中一台flume,把信息sink到Kafka去,此时这台Flume的 sink就相当于是kafka的生产者,再启动一台kafka的消费者,直接对接到kafka的生产者,这样就完成了Flume到Kafka的实时数据采集。
二、Demo分析
此次,我用到的Demo案列,主要就是用一台Flume读取某个日志文件内的内容,然后串联第二台Flume,这台Flume最终把log内容先存储到内存中,再sink到Kafka的消费者里面去,这里Kafka的消费主要是以控制台的方式进行输出。当然你也可以直接通过设置kafka-channel,把内容直接写到kafka里面去。
三、定义配置文件
自定义Fluem的conf目录下的配置文件,此处我定义的配置文件为:avro-memory-kafka.conf,内容如下:
avro-memory-kafka.sources = avro-source
avro-memory-kafka.sinks = kafka-sink
avro-memory-kafka.channels = memory-channel
avro-memory-kafka.sources.avro-source.type = avro
avro-memory-kafka.sources.avro-source.bind = hadoop000
avro-memory-kafka.sources.avro-source.port = 44444
avro-memory-kafka.sinks.kafka-sink.type = org.apache.flume.sink.kafka.KafkaSink
avro-memory-kafka.sinks.kafka-sink.brokerList = hadoop000:9092
avro-memory-kafka.sinks.kafka-sink.topic = hello_topic
avro-memory-kafka.sinks.kafka-sink.batchSize = 5
avro-memory-kafka.sinks.kafka-sink.requiredAcks =1
avro-memory-kafka.channels.memory-channel.type = memory
avro-memory-kafka.sources.avro-source.channels = memory-channel
avro-memory-kafka.sinks.kafka-sink.channel = memory-channel
再定义个配置文件exec-memory-avro.conf:
exec-memory-avro.sources = exec-source
exec-memory-avro.sinks = avro-sink
exec-memory-avro.channels = memory-channel
exec-memory-avro.sources.exec-source.type = exec
exec-memory-avro.sources.exec-source.command = tail -F /home/hadoop/data/data.log
exec-memory-avro.sources.exec-source.shell = /bin/sh -c
exec-memory-avro.sinks.avro-sink.type = avro
exec-memory-avro.sinks.avro-sink.hostname = hadoop000
exec-memory-avro.sinks.avro-sink.port = 44444
exec-memory-avro.channels.memory-channel.type = memory
exec-memory-avro.sources.exec-source.channels = memory-channel
exec-memory-avro.sinks.avro-sink.channel = memory-channel四、启动Flume
这里的启动主要是
flume-ng agent \
--name avro-memory-kafka \
--conf $FLUME_HOME/conf \
--conf-file $FLUME_HOME/conf/avro-memory-kafka.conf \
-Dflume.root.logger=INFO,console
flume-ng agent \
--name exec-memory-avro \
--conf $FLUME_HOME/conf \
--conf-file $FLUME_HOME/conf/exec-memory-avro.conf \
-Dflume.root.logger=INFO,console五、启动Kafka
这里我们需要启动Kafka进行消费,命令如下:
kafka-console-consumer.sh --zookeeper hadoop000:2181 --topic hello_topicr然后我们在日志文件里输入内容,会在kafka消费者里对内容进行输出展示。此处要注意的是,由于是设置了batch,所以当输入内容不够时,控制台会进行延迟后再输出。















 2125
2125

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









