







一:luncen的执行流程
1、流程图
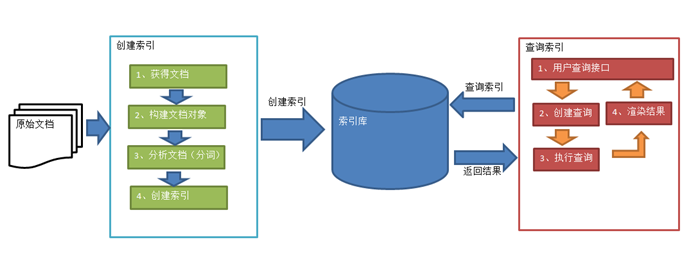
2.、创建索引
原始文档:要在那些内容中进行搜索,这些内容就是原始文档
(1)、获的文档
(2)、创建文档对象
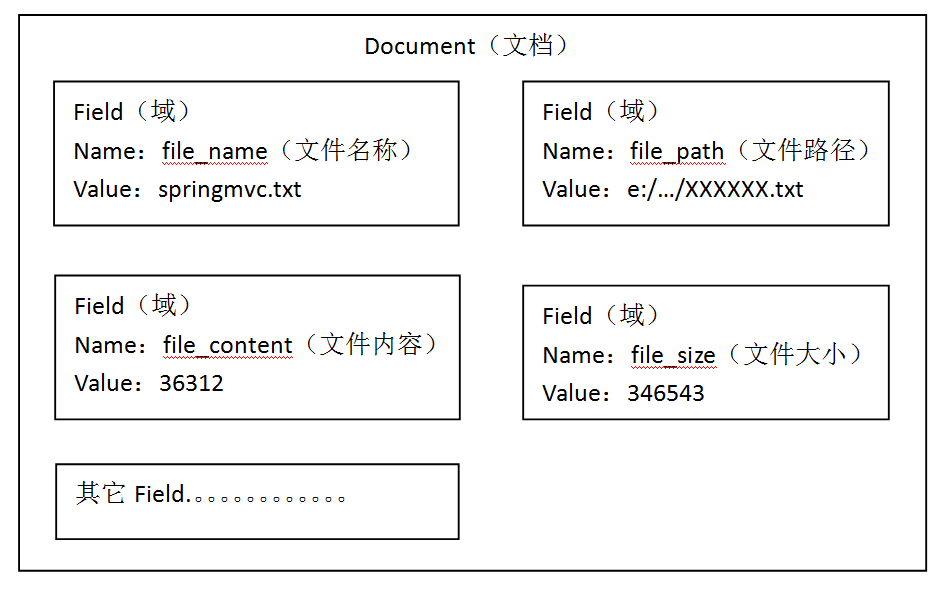
在luncene中对应每个原始文档创建一个document对象。document中有很多field(域),域中保存了原始文档的属性。每个属性保存到一个field中
不同的文档可以有不通的域。每一个文档都有一个唯一的id。
(3)、分析文档:对field中的内容进行分析
a、按照空格对字符串进行切割,得到一个单词列表
b、去除标点符号
c、去除停用词(的、the、等没有意义的词)
d、转换大小写
最终得到一个词汇单元流,单词列表。把每个单词封装成一个 term 对象。
term对象中有:单词所在的域名称,单词本身
不同域中拆分出来相同的单词不是一个term。
(4)、创建索引:
a、基于单词列表创建索引
b、把索引保存到磁盘
c、文档对象保存到磁盘
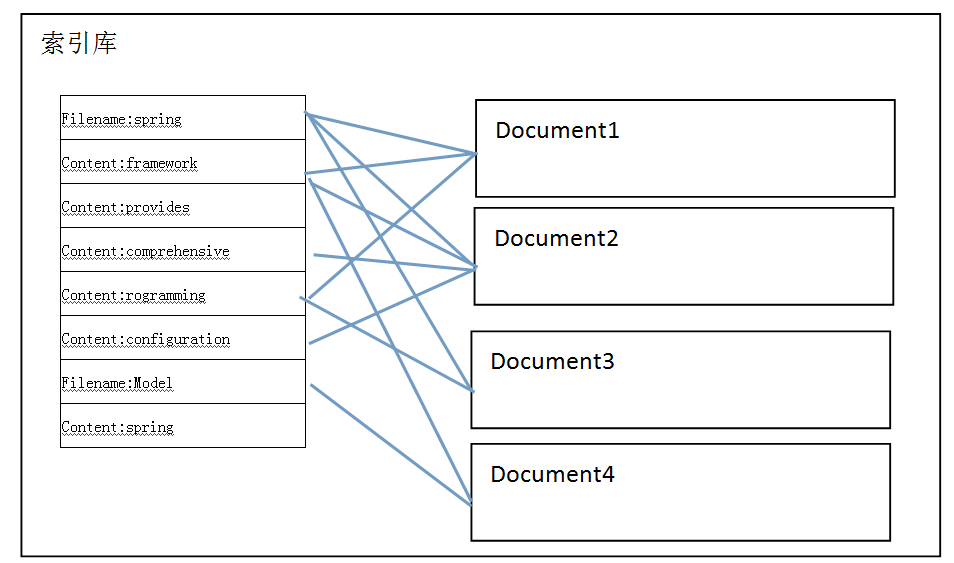
d、需要把关键词(term)和文档的对应关系记录下来。
索引库就是一个倒排索引的结构,是通过单词来查找文档
3、查询索引
(1)、用户查询接口
用户输入查询条件的地方
(2)、把查询内容封装成查询对象
包含两部分内容
a、要搜索的域
b、要搜索的内容
(3)、执行查询
到索引库中查询索引,找到关键词后,根据关键词和文档的对应关系,找到对应文档的id列表
(4)、渲染结果
a、根据文档id找到文档内容
b、从文档域中把内容取出来
c、对内容进行高亮显示
d、对结果进行分页处理

















 559
559

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









