






在当今的数字时代,文档格式转换已成为一项常见需求。特别是将PowerPoint演示文稿转换为PDF格式,这不仅可以确保文档的一致性,还能方便分享和打印。今天,我们将深入探讨一个使用Python开发的强大GUI应用程序,它不仅可以将PPT转换为PDF,还具备文本替换、PDF处理和文件合并等多项功能。
C:\pythoncode\new\unzipconvertpdfmerge.py
应用概述
这个应用程序主要完成以下任务:
- 解压7z压缩文件
- 在PPT文件中替换指定文本
- 将PPT文件转换为PDF
- 处理生成的PDF文件(删除最后一页,更新公司名称)
- 合并所有PDF文件
让我们逐步解析这个应用的核心组件和功能。
全部代码
import os
import wx
import fitz # PyMuPDF
import py7zr
from pptx import Presentation
from pptx.enum.shapes import MSO_SHAPE_TYPE
from PyPDF2 import PdfMerger
import comtypes.client
import pythoncom
class MyFrame(wx.Frame):
def __init__(self):
wx.Frame.__init__(self, None, title="PPT to PDF Converter", size=(500, 300))
panel = wx.Panel(self)
vbox = wx.BoxSizer(wx.VERTICAL)
self.dir_picker = wx.DirPickerCtrl(panel, message="Choose a destination folder")
vbox.Add(self.dir_picker, flag=wx.EXPAND | wx.ALL, border=10)
self.input_box1 = wx.TextCtrl(panel, value="Enter text to replace")
vbox.Add(self.input_box1, flag=wx.EXPAND | wx.ALL, border=10)
self.input_box2 = wx.TextCtrl(panel, value="Enter replacement text")
vbox.Add(self.input_box2, flag=wx.EXPAND | wx.ALL, border=10)
self.unzip_button = wx.Button(panel, label="Unzip and Convert")
vbox.Add(self.unzip_button, flag=wx.EXPAND | wx.ALL, border=10)
self.unzip_button.Bind(wx.EVT_BUTTON, self.on_unzip_convert)
panel.SetSizer(vbox)
def on_unzip_convert(self, event):
destination_dir = self.dir_picker.GetPath()
text_to_replace = self.input_box1.GetValue()
replacement_text = self.input_box2.GetValue()
with wx.FileDialog(self, "Choose a 7z file", wildcard="7z files (*.7z)|*.7z", style=wx.FD_OPEN) as fileDialog:
if fileDialog.ShowModal() == wx.ID_CANCEL:
return
zip_path = fileDialog.GetPath()
# Step 1: Unzip the 7z file
with py7zr.SevenZipFile(zip_path, mode='r') as archive:
archive.extractall(path=destination_dir)
# Step 2: Process all PPT files
pdf_files = []
for root, dirs, files in os.walk(destination_dir):
for file in files:
if file.endswith('.pptx'):
ppt_path = os.path.join(root, file)
pdf_path = os.path.splitext(ppt_path)[0] + ".pdf"
# Replace text in PPT
self.replace_text_in_ppt(ppt_path, text_to_replace, replacement_text)
# Convert PPT to PDF
self.convert_ppt_to_pdf(ppt_path, pdf_path)
# Process the PDF (remove last page, update company name)
self.process_pdf(pdf_path, replacement_text)
pdf_files.append(pdf_path)
# Step 3: Merge all PDFs
self.merge_pdfs(pdf_files, os.path.join(destination_dir, "merge.pdf"))
wx.MessageBox("Process completed!", "Info", wx.OK | wx.ICON_INFORMATION)
def replace_text_in_ppt(self, ppt_path, old_text, new_text):
prs = Presentation(ppt_path)
for slide in prs.slides:
for shape in slide.shapes:
if shape.shape_type == MSO_SHAPE_TYPE.TEXT_BOX:
if shape.text_frame and old_text in shape.text:
shape.text = shape.text.replace(old_text, new_text)
prs.save(ppt_path)
def convert_ppt_to_pdf(self, ppt_path, pdf_path):
# Start PowerPoint application
powerpoint = comtypes.client.CreateObject("PowerPoint.Application")
powerpoint.Visible = 1
# Open the PowerPoint file
presentation = powerpoint.Presentations.Open(ppt_path)
# Save as PDF
presentation.SaveAs(pdf_path, 32) # 32 is the enum value for PDF format
presentation.Close()
# Quit PowerPoint application
powerpoint.Quit()
def process_pdf(self, pdf_path, company_name):
doc = fitz.open(pdf_path)
# Remove the last page
if len(doc) > 1:
doc.delete_page(len(doc) - 1)
# Modify the first page's company name
page = doc[0]
text_instances = page.search_for(company_name)
if text_instances:
for inst in text_instances:
rect = inst.rect
page.insert_text((rect.x0, rect.y0), company_name, fontsize=12, color=(0, 0, 0))
doc.saveIncr() # Save changes to the same file
doc.close()
def merge_pdfs(self, pdf_files, output_path):
merger = PdfMerger()
for pdf in pdf_files:
merger.append(pdf)
merger.write(output_path)
merger.close()
class MyApp(wx.App):
def OnInit(self):
frame = MyFrame()
frame.Show()
return True
app = MyApp()
app.MainLoop()
核心组件
1. 图形用户界面(GUI)
应用使用wxPython库创建了一个简单而功能强大的GUI。主要包含以下元素:
- 目录选择器:用于选择输出目录
- 两个文本输入框:分别用于输入要替换的文本和替换后的文本
- "解压并转换"按钮:启动整个处理流程
class MyFrame(wx.Frame):
def __init__(self):
# ... (GUI 初始化代码)
2. 7z文件解压
使用py7zr库实现7z文件的解压:
with py7zr.SevenZipFile(zip_path, mode='r') as archive:
archive.extractall(path=destination_dir)
3. PPT文本替换
利用python-pptx库在PPT文件中进行文本替换:
def replace_text_in_ppt(self, ppt_path, old_text, new_text):
prs = Presentation(ppt_path)
for slide in prs.slides:
for shape in slide.shapes:
if shape.shape_type == MSO_SHAPE_TYPE.TEXT_BOX:
if shape.text_frame and old_text in shape.text:
shape.text = shape.text.replace(old_text, new_text)
prs.save(ppt_path)
4. PPT到PDF的转换
使用comtypes库调用PowerPoint应用程序进行转换:
def convert_ppt_to_pdf(self, ppt_path, pdf_path):
powerpoint = comtypes.client.CreateObject("PowerPoint.Application")
presentation = powerpoint.Presentations.Open(ppt_path)
presentation.SaveAs(pdf_path, 32) # 32 对应PDF格式
presentation.Close()
powerpoint.Quit()
5. PDF处理
使用PyMuPDF(fitz)库处理PDF文件:
def process_pdf(self, pdf_path, company_name):
doc = fitz.open(pdf_path)
if len(doc) > 1:
doc.delete_page(len(doc) - 1)
page = doc[0]
text_instances = page.search_for(company_name)
if text_instances:
for inst in text_instances:
rect = inst.rect
page.insert_text((rect.x0, rect.y0), company_name, fontsize=12, color=(0, 0, 0))
doc.saveIncr()
doc.close()
6. PDF合并
使用PyPDF2库合并多个PDF文件:
def merge_pdfs(self, pdf_files, output_path):
merger = PdfMerger()
for pdf in pdf_files:
merger.append(pdf)
merger.write(output_path)
merger.close()
工作流程
- 用户选择7z文件和输出目录,输入要替换的文本。
- 点击"解压并转换"按钮后,程序解压7z文件。
- 遍历所有PPT文件,进行以下操作:
- 替换指定文本
- 转换为PDF
- 处理生成的PDF(删除最后一页,更新公司名称)
- 最后,将所有处理过的PDF合并为一个文件。
技术亮点
- 多库协作: 利用多个Python库(wxPython, py7zr, python-pptx, comtypes, PyMuPDF, PyPDF2)协同工作,实现复杂功能。
- 自动化办公: 实现了从PPT文本替换到PDF转换和处理的全自动化流程。
- 用户友好: 提供了直观的GUI,使非技术用户也能轻松操作。
- 可扩展性: 模块化的设计使得添加新功能变得简单。
结果如下
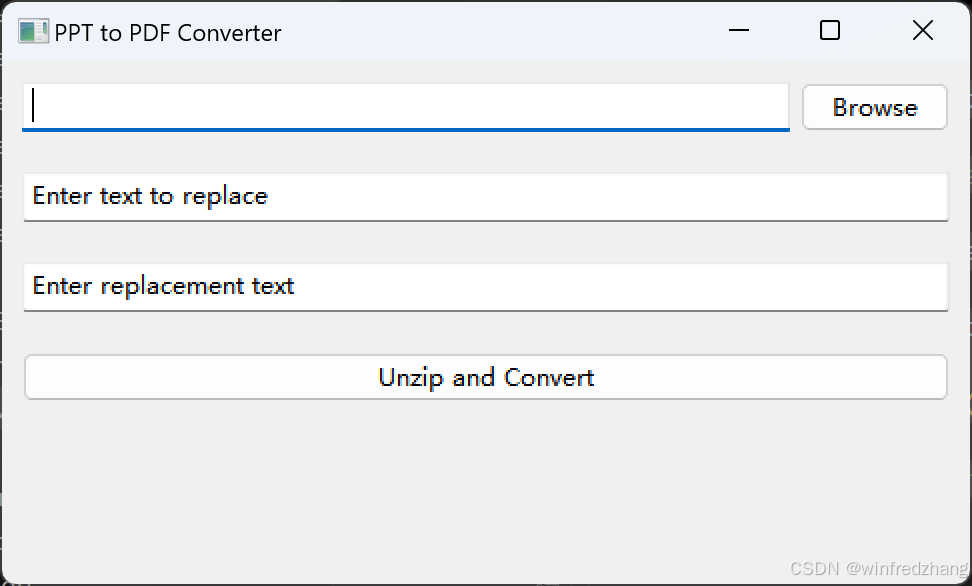
总结
这个Python应用展示了如何将多个复杂的文档处理任务整合到一个用户友好的界面中。它不仅提高了工作效率,还为类似的文档处理任务提供了一个可扩展的框架。无论是对于日常办公还是大规模文档处理,这种自动化工具都能带来显著的效率提升。















 12万+
12万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









