









这一篇我们来谈一下ServerSAN的数据一致性。
一致性的一般概念
就一致性这个概念而言,从工程可理解的角度可以分为三个类型,严格一致性,强一致性,弱一致性。
严格一致性: 对于数据项x的任何读操作将返回最近一次对x进行的写操作的结果。
严格一致性中存在的问题是它依赖于绝对的全局时间。对于所有的进程来说,所有写操作都是瞬间可见的,系统维持着一个绝对的全局时间顺序。举个例子来说,住在新疆的阿凡提用火车托运了箱葡萄干给北京的康熙,立刻又给康熙打了个电话说:‘我给你托运了箱葡萄干,快去接站’。康熙马上到火车站一看真就收到了。这就是严格一致。
事实上我们知道从新疆到北京的火车需要3天时间,托运手续办完并不代表货物已经到了北京。因此严格一致除了极少数场景是不可能达到的。
任何一个因果系统都会有时延等因素存在,对未来的预知是超过科学范畴的。举个例子,
- 节点A在t=0时刻向存储器发出一个写请求。
- 这个请求在t=10时刻才能传输到达存储器。
- 节点B在t=1时刻向存储器发起一个读请求,并在t=2时刻到达存储器。
- 那么按照严格一致性,存储器t=2时刻就应该向B返回A在t=0写入的数据。
- 但是存储器不可能未卜先知,在t=2时刻响应B的读请求时,既不知道A在t=0时向自己进行了写操作,更不知道A在t=0时写入的内容时什么。因此不可能返回t=0时刻写入的内容。
因此,严格一致性在工程上是不可实现的。
强一致: 强一致是对严格一致的适当放松,在工程可实现和满足实际需求间进行折衷。折衷的条件不同也就引出了很多一致性变种,包括:顺序一致性、线性一致性、因果一致性… 准确理解这些折衷方案的差异还真不是个容易的活。对于分布式存储系统,一般以这样的准则判定强一致:如果对于一个写操作,存储系统应答了写成功后,确保任何后续的读操作都能读到刚写入的数据 ,这就是强一致。
仍以上面的例子,如果阿凡提不急于打电话给康熙,而是等到北京火车站收到货后通知阿凡提,然后阿凡提再打电话给康熙。那么康熙再去火车站则一定能收到货。
弱一致性: 是指系统并不保证后续访问都会返回最新的值。系统在数据成功写入之后,不承诺立即可以读到最新写入的值,也不会具体承诺多久后读到。但是会尽可能保证在某个时间级别之后,可以让数据达到一致性状态。
仍以上面的例子来比喻,阿凡提在火车站托运完后,到网上查自己的托运单也许发现不存在,到了晚上才查到。而北京的康熙就更惨,即使阿凡提打了电话说我已经查到运单了,康熙到火车站也不一定能接到货。铁路系统只会向阿凡提承诺开始托运了,但是什么时候到哪里并不承诺,也不向阿凡提通知。
分布式系统的一致性
谈到分布式系统的一致性,大部分读者应该都听说过CAP法则,Paxos协议,raft协议,拜占庭将军问题等。这些名词和上面的一致性又是什么关系?
前面谈到的严格一致、强一致、弱一致,其实都是从外部看到的一个系统的行为,这个系统可以是简单的内存颗粒、一个硬盘,到复杂的一个数据库系统、一个上千节点的PureFlash集群。无论简单复杂都认为系统是一个黑盒,是一个单体,我们只是从外面看他的行为。因此严格一致、强一致、弱一致这些可以称之为行为一致性。行为一致性对于不同的系统,执行起来难度是不一样的:一个硬盘和一个由1000个节点组成的分布式系统为提供相同的行为一致性需要付出的成本代价是天壤之别。
CAP法则,Paxos协议,raft协议,拜占庭将军问题这些都是针对分布式系统才存在的特有问题。这些问题都是系统内部实现时需要解决的分布式系统问题,和前面说的行为一致性是不同的视角。作为基础概念,这些名词间是什么关系呢?
- 应该说拜占庭将军问题是分布式系统基本问题的普遍表述,讲的是在分布式系统里,且具有恶意节点干扰的条件下,系统能够取得一致性的必须条件。李永乐老师有个视频讲的通俗易懂。这个问题有口头消息(OM, Oral Message), 书面消息(SM, Signed Message) 两种解法,OM解法取得一致性结果的必要条件是系统总节点的数量n>= 3m+1(其中m是恶意节点数量)。SM解法可以解决任意恶意节点情况下的共识问题,但是需要对消息进行签名。这两种方法都需要大量的通信。
- CAP 法则在《分布式系统设计的若干问题》一文里已经提到过,CAP是说:在一个分布式系统中,一致性(Consistency)、可用性(Availability)、分区容错性(Partition tolerance),这三个要素最多只能同时实现两点,不可能三者兼得。(当然这里的Consistency其实是指的强一致性。故而才有CP, AP二选一的结论,如果是弱一致性,那么CAP就可以三者兼顾了。)
CAP法则与拜占庭将军问题到底什么关系呢?同样都是分布式系统的行为理论,拜占庭将军问题讲的是获得共识的必须条件。CAP法则给出的是最优局面的上限:CAP最多获得2个。比如说在发生网络分区的情况下,我们只能在CP, AP中选择一个。然而即使我们选择了CP, 也需要满足拜占庭问题的基础条件,我们才能获得共识。 - Paxos 算法的作者也是Lamport, 就是前面说拜占庭将军问题的作者提出的。这个算法描述了一个分布式系统中的各个节点对问题达成一致的步骤与算法过程。这个算法允许n=2m+1个节点的系统中,发生m个节点故障。细心的读者会发现这里和前面拜占庭将军问题里要求n>=3m+1才能达成一致性是矛盾的。事实上是这样的,Paxos算法解决的分布式问题是有条件限制的,只允许有节点故障,网络故障,但不允许有恶意叛徒节点。即,一个节点故障了可以不响应,但不能发出恶意误导数据。相当于拜占庭将军问题里将军都是忠诚的,只是通信出了问题。因此Poxos算法对前提条件的要求比拜占庭将军问题放松了。
但是Paxos算法的难以理解是出了名的,某乎上有个文章我感觉比较容易理解,大家可以看一下。 - Raft算法,因为Paxos算法太难理解和实现,因此诞生了Raft算法。Raft算法之所以能容易理解和实现,是因为Raft进一步加强了限制条件,相对Paxos算法增加了leader概念,并且只允许leader提出Proposal。有点像multi paxos,是特定条件下的特解,但是对于工程领域足够用了。
ServerSAN一致性的定义
前面说了这么多,是在解释一致性问题的来龙去脉以及业界的解决方法。现在让我们回归到分布式存储系统上来。ServerSAN需要实现的是强一致,具体一点即:任何向Client应答了写入成功的数据,在后续的读操作中,确保能被读到。这个要求看上去很简单,但是实现时有很多情况需要考虑,比如:
- 如果系统使用了Cache, 写操作把数据写到了Cache中就向client返回了OK。那么后续再有读操作时,需要将cache中最新的数据返回给client,而不是磁盘上过时的数据。
- 如果系统使用了Append only log, 和使用cache的情况一样,需要从log中返回新数据而非磁盘上的旧数据。
- 如果数据只写入了到了分布式系统的一个节点(Primary),其他节点(Slave)还没有得到最新的数据,系统就向client返回了OK。系统的实现要考虑读操作的实现机制,是否允许从Slave节点读,如果允许那么如何保证Slave也能返回最新的数据。
- 如果发生了节点故障,比如3副本系统里面有一个节点网络不通了,写入2副本后就返回OK了。随后故障节点网络又恢复,此时系统里3个副本数据就不一致,如何保证client不会读到错误的数据.
从上面的这些描述看,存储系统的一致性和上面的CAP, Paxos没有半点关系。实际不然,上面的这些基本规则同样是分布式存储的根基和约束。下面我们来看下PureFlash的设计如何使用并遵守上面的规则。
PureFlash如何保证一致性
1. PureFlash Primary副本的选取
PureFlash使用了多副本保证系统的高可用。多副本一般可以使用三种模型:1) 有主从关系 2) 无主从关系 3) 写操作分主从,读操作无主从。
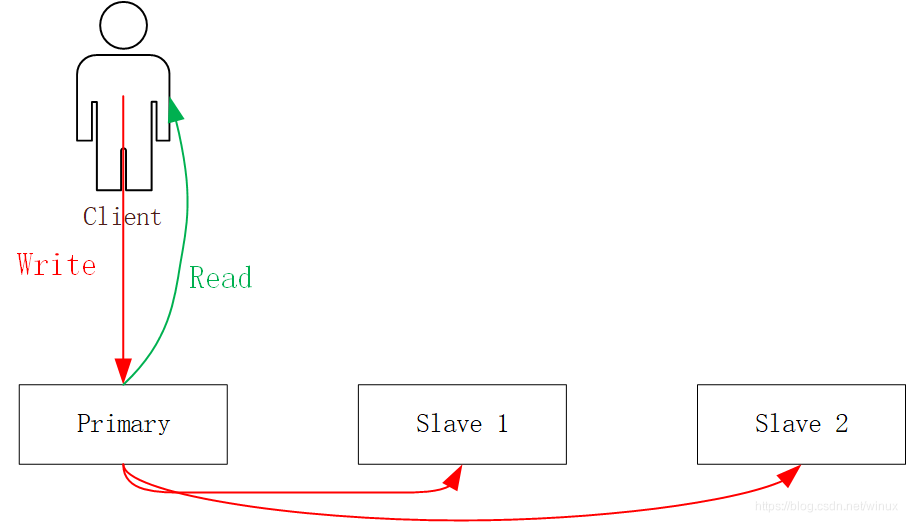
模型1) 有主从关系中,Client的Write和Read操作都只经由Primary节点完成。
模型2) 中,Write和Read都可以经由任意节点完成,不同的Client可以访问不同的节点,同一个Client的不同IO也可以经由不同节点进行,在Client看来就像是同一个节点的多个访问路径。
模型3) 则是Write操作必须经由Primary节点完成,但读操作可以从任意节点进行。
PureFlash采用的是模型1),因此这里也只画出了模型1的图。
在这个模型下,读写都通过同一个节点(Primary)进行,那么Primary副本是如何选取的呢?一个方法是由存储节点自己,比如下图中的(Node 1, Node 2, Node 3)自己进行选举,选举的方法可以运行一个Paxos算法或者Raft算法。但是PureFlash没有这么做,因为1)前面说过实现Paxos或者Raft算法比较复杂且容易出错 2) PureFlash的主业是解决存储问题而不是分布式系统选主。 因此PureFlash使用成熟的分布式选主方案,再加上自己的逻辑,构成了下面的解决方案:
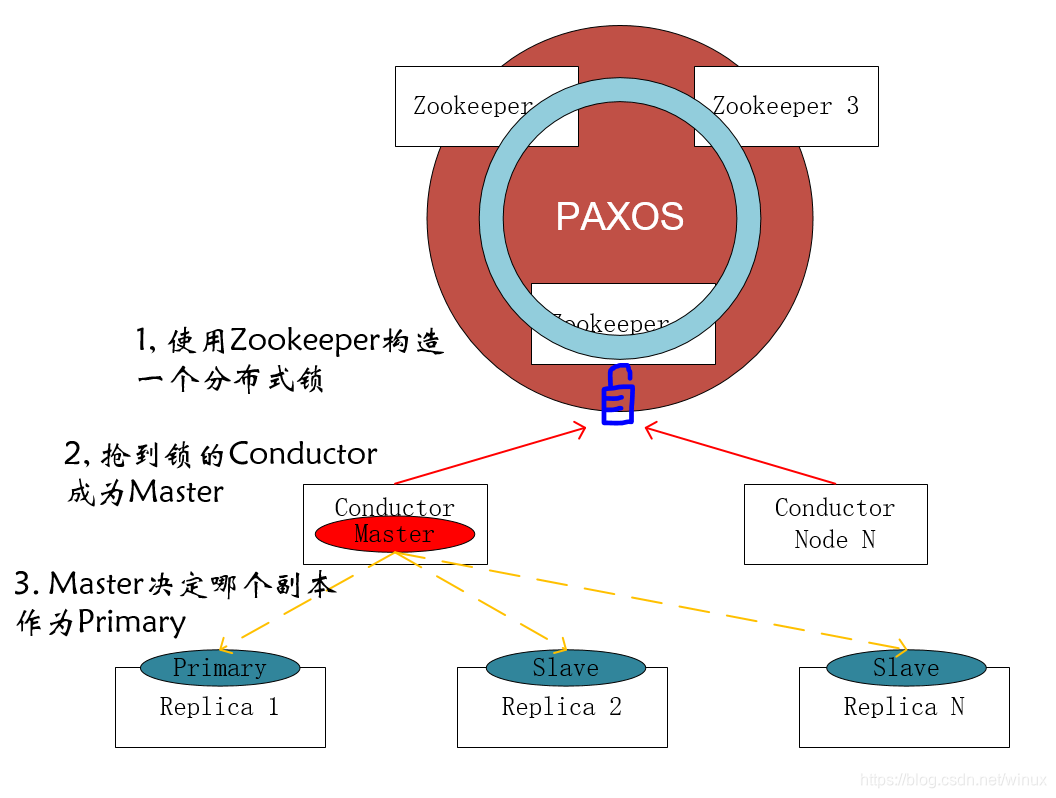
- PureFlash使用一个Zookeeper集群作为系统的分布式根基。我们知道Zookeeper使用的ZAB协议是基于Paxos的改进,因此这也就是Paxos协议作为根基出现在PureFlash系统里的地方。通过ZK我们可以完成Conductor的选主、Store节点的注册与发现。
- Conductor节点是PureFlash系统的控制节点。控制节点可以有多个以保证故障时的高可用。Conductor节点只有一个作为Master处于活动状态,并由Master承担全部的控制任务。其他节点处于热备份状态,当Master节点故障后,热备状态的Conductor会抢到ZK上的锁,并转入活动状态。
- Master Conductor按照一定规则决定每个Shard里哪个Replica作为Primary。决定规则里面考虑了平衡每个节点承载的Primary数量。
2. 读写IO一致性模型
PureFlash系统设计的核心原则是:简化数据路径,以实现低延迟、高吞吐。因此在PureFlash系统里没有Cache,没有WAL等中间环节。在传统的存储系统里,Cache, WAL用于解决写入延迟问题,让Write操作能够快速完成,然后系统再把数据从Cache/WAL重新写入到最终位置。这种模式有两个缺点:
缺点1: 每一笔写入IO要进行二次处理,而这些处理都需要消耗系统CPU、IO资源,因此每笔IO的平均资源消耗是增加的。考虑到计算机系统的CPU、IO总资源能力是固定的,每笔IO的平均成本上升,必然导致系统整体上吞吐能力下降。
当系统的后端介质是HDD时,CPU资源富裕很大,这种模式缺点还不明显。而后端介质换成NVMe SSD后,CPU资源往往成为系统的瓶颈,使用这种模式就非常不合适了。
缺点2: Read IO操作逻辑变复杂。因为中间Cache的存在,IO线程在处理Read IO时都必须要先在Cache中进行查找,如果不命中再去后端存储读取。与此同时,还有一个后端线程负责从Cache中把空闲的数据evict到后端存储。Cache会成为两个线程竞争的临界资源,必须对访问加锁,进一步影响IO性能。

因此PureFlash的设计中没有Cache和WAL,写的时候IO线程直接把数据提交给SSD,读的时候IO线程只从SSD读取,这样模型就简单多。之所以能这么做,得益于当前NVMe SSD的发展,随机写延迟可以低至20us,完全不需要额外的cache机制。
Write过程: 当Volume是多副本时,Write IO会从Client发送给Primary节点,然后Primary节点负责将IO发送给所有的Slave。等所有的Slave都返回OK后,Primary再向Client返回OK。
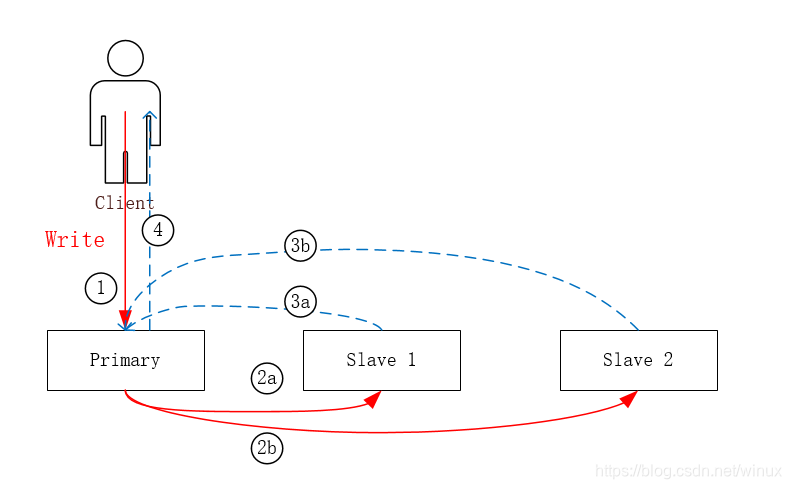
Read过程: Client进行Read时 IO仍然只通过Primary进行。这样就可以保证最新成功的Write数据一定能被读到。
这里有个问题值得思考:既然Read操作也必须经由Primary节点完成,步骤④ 是否可以不等待③的完成?按照正常的流程,只需要Primary节点完成了写入,后续Read IO从Primary上也一定能读到刚刚写入的数据。答案是“步骤④ 必须等待③的完成”,原因是接下来要分析的故障场景。
3. 故障时一致性的保证
继续前面提到的思考问题,“步骤④ 是否可以不等待③的完成”。如果“不等待”,我们假定这样一个场景:
- Primary完成IO后,在③完成前就向Client返回了OK。
- 随后Client发起Read操作,恰在此时Primary发生故障而掉线。而且③没有完成,表明②步骤其实也处于未决状态,最新的数据也许到了Slave1, 也许还没到并再也到不了了。
- Client因为旧的Primary访问不到,而把Read IO发送给Slave 1(Slave 1成为了新的Primary)。
- Slave 1上数据可能是旧的也可能是新的。这就违反了我们的一致性原则:任何向Client应答了写入成功的数据,在后续的读操作中,必须能被读到
因此,必须在向Client返回OK前,保证数据在所有的副本节点上均已落盘,这样才能满足系统承诺给应用的一致性。
如果保证了所有节点都Write完成才返回给Client端,是否可以允许Read操作从任意节点执行?答案仍然是否。一方面这会带来系统设计的复杂性,更重要的这可能会使系统违反单调一致性。
单调一致性:如果进程已经看到过数据对象的某个新值,那么任何后续访问都不会返回该值之前的旧值。
设想下面的场景:
- Client 1向系统发出一个Write IO,
- 由于网络延迟和系统繁忙程度的原因,我们知道IO在每个节点上完成的时间是不确定的。这个IO依次在node 1(primary), node 2, node 3上被完成,尽管primary节点同时把IO 复制给了node2, node3。
- Client 2作为一个独立的Client, 对Client 1的写入不感知。第一次Read 从node1进行,第二次Read从node 2进行。那么从Node1进行的第一次Read已经访问到最新的数据了,从node2进行的第二次Read又退回到了旧的数据。
上面是举了两个反例,这种方法在分布式系统设计里是非常常用的。正常的行为路径往往是单一而且容易设计的,恰恰是各种故障、例外场景很难考虑周全。PureFlash考虑的与一致性相关的故障场景包括:
- Primary节点故障
如果Client发现和Primary节点间的通信不通,Client就会转向其他的Slave节点,然后Slave就会成为新的Primary。鉴于所有的Write操作已经在全部节点上完成,我们可以确保新的Primary拥有最新的数据。旧的Primary副本会被标记成ERROR状态,再执行recovery操作前,任何IO都不会访问到这个副本。 - Slave节点故障
Slave故障对Client完全是透明的,Client只是和Primary通信,Slave的故障由系统自行处理而不需要Client参与。而且对于Client看到的一致性没有任何影响。
还有其他的故障情况比如Client节点故障,网络故障,磁盘故障等,后面我会专门再写一篇故障处理的文章说明。
4. 共享访问时的一致性保证
SAN存储很重要的一个能力是支持共享访问,说实话用到这个能力的场景不多,最具代表性的应该是Oracle RAC了。但是,只要使用Oracle RAC的场景往往正是企业的核心业务,所以这个场景非常重要,价值很高。这也是一个SAN存储是否够得上企业级的标志性feature。
很多人使用SAN存储共享访问功能时往往有个误解,认为只要把一个Volume同时挂载到两个Client主机上,然后格式化成一个标准的本地文件系统(比如ext4),两个主机就能同时访问相同的文件。这是非常错误的。ext4这样的文件系统是为单机设计的,有很多元数据是维护在内存中的,多个主机挂载同一个Volume, 虽然都能从Volume上加载到正确的初始状态,但后面运行起来就会产生混乱。
所以共享访问需要特殊的文件系统,例如Oracle RAC使用的ASM, OCFS2, RedHat的GFS2这样的文件系统。
在这种场景下,作为ServerSAN的实现需要保证什么呢?仍然是:“任何向Client应答了写入成功的数据,在后续的读操作中,必须能被读到”就可以了。需要注意的是,这里的Client应该是复数Clients, 多个Client有的写入,有的读取。Client节点之间是有同步操作的。
结语
一致性这个问题说简单也简单,只要设计时守住 “任何向Client应答了写入成功的数据,在后续的读操作中,确保能被读到” 这个底线就可以了。但是又很复杂,复杂到无法完整描述,之所以复杂就在设计者对各种异常情况的考虑是否周到,而异常的处理跟系统的架构设计又有很大的关系,因而无法完全描述,因系统而异。
最后还要说一下CAP法则,CAP法则并不要求我们去做什么,而是告诉我们哪些是不切实际可以趁早放弃的。一般来说Server SAN需要保证的是CP,舍弃的是A。设计者就要审视当网络故障后,系统里哪部分节点的访问需要放弃,甚至是必须禁止,反过来又要保证哪些部分节点的访问。














 2320
2320











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









