







经过对微博品牌的页面进行分析,数据返回一共分为两种形式,js封装页面代码渲染在预加载页面中,鼠标向下滑动过程中会再次请求服务器,返回json数据,对微博内容进行渲染,json数据一共请求两次
1.首先对微博页面预加载数据进行分析
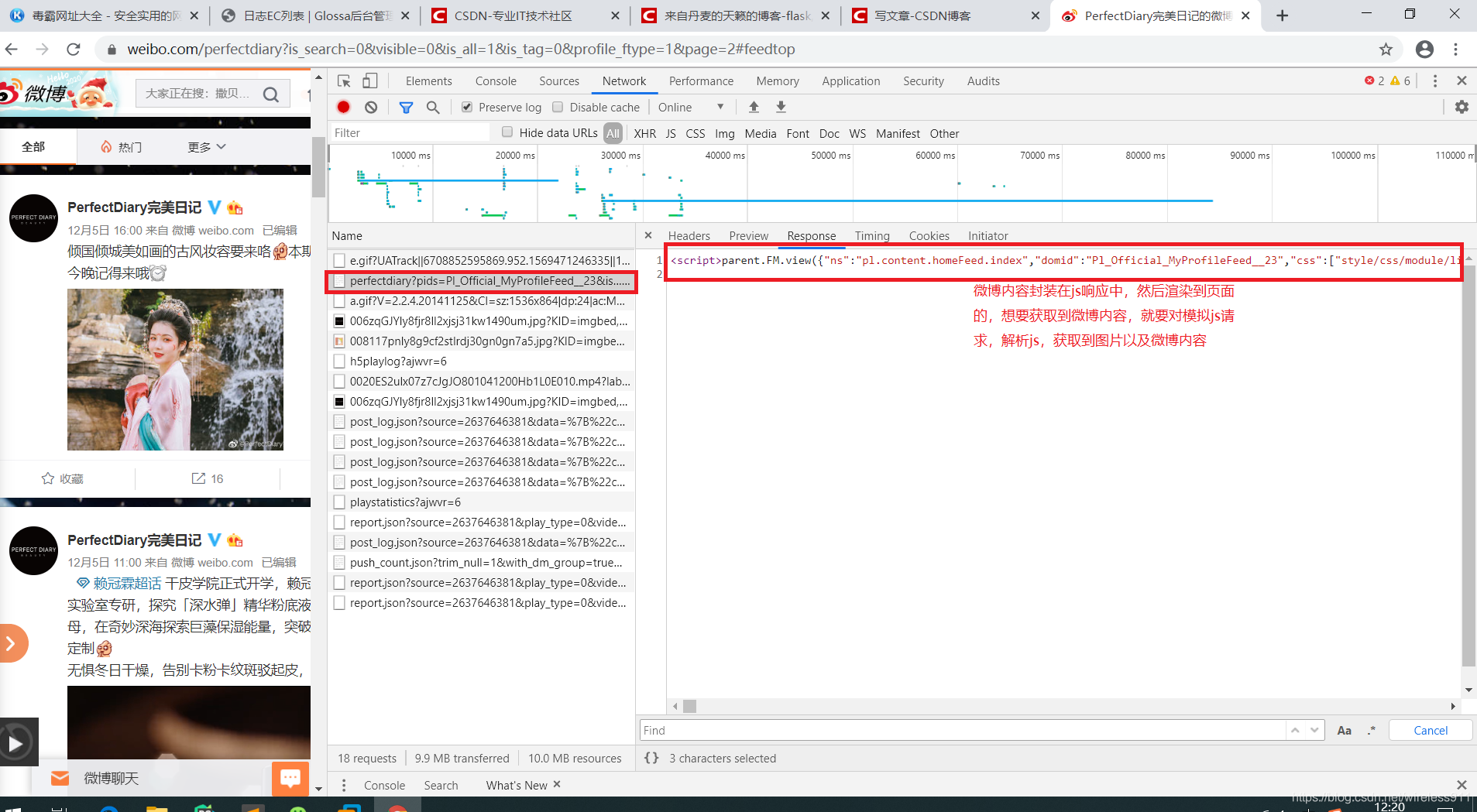
2.然后向下滑动,继续请求json数据,获取请求链接,拼接请求参数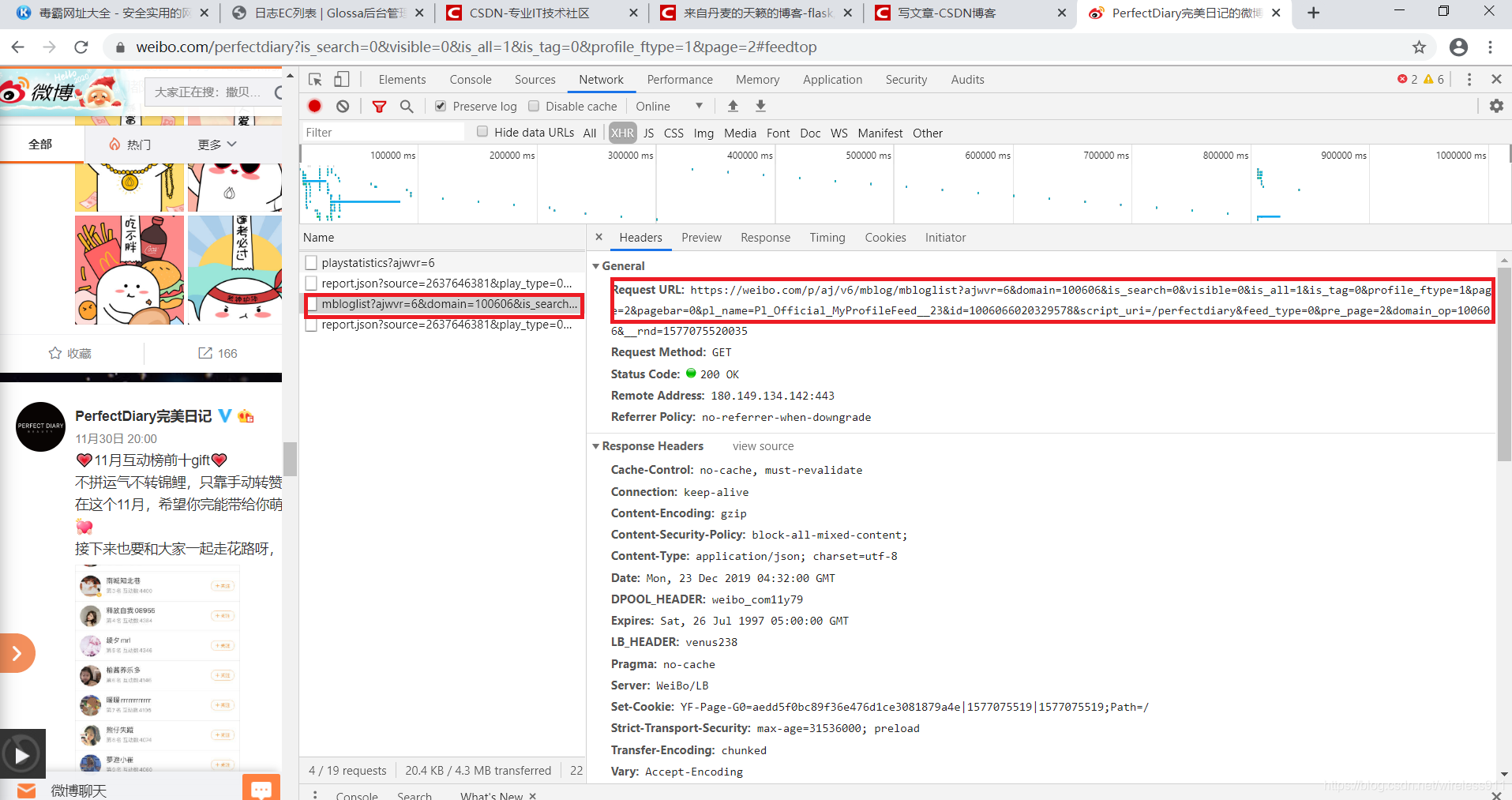
以下是模拟请求获取到的结果示例:
微博内容:

图片内容:
详细代码我上传到了github, 项目地址
https://github.com/17521659186/weibo_spider
部分代码如下:
def get_response(self, page):
"""微博每页的数据分三次请求,初始页面为js渲染html,下拉请求json数据渲染,需要拼接参数"""
requests.packages.urllib3.disable_warnings()
http = urllib3.PoolManager()
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.108 Safari/537.36',
'Cookie': self.cookie,
"X-Requested-With": "XMLHttpRequest"
}
start_url = 'https://weibo.com/{profile}?pids=Pl_Official_MyProfileFeed__23&is_search=0&visible=0&is_hot=1&is_tag=0&profile_ftype=1&page={page}&ajaxpagelet=1&ajaxpagelet_v6=1&__ref=%2Fperfectdiary%3Fis_search%3D0%26visible%3D0%26is_hot%3D1%26is_tag%3D0%26profile_ftype%3D1%26page%3D3%23feedtop&_t=FM_157441560856733'.format(
profile=self.profile, page=page)
r = http.request('GET', start_url, headers=headers)
data = json.loads(r.data.decode().strip()[23:-10]).get("html")
soup = BeautifulSoup(data, 'html.parser', from_encoding='utf-8')
result0 = soup.find_all("div", attrs={"action-type": "feed_list_item"})
for pagebar in [0, 1]:
json_url = "https://weibo.com/p/aj/v6/mblog/mbloglist?ajwvr=6&domain=100606&is_search=0&visible=0&is_all=1&is_tag=0&profile_ftype=1&page={page}&pagebar={pagebar}&pl_name=Pl_Official_MyProfileFeed__23&id=1006066020329578&script_uri={script_uri}&feed_type=0&pre_page={pre_page}&domain_op=100606&__rnd=1575859271326".format(
page=page, pagebar=pagebar, pre_page=page, script_uri=self.script_uri)
res = http.request('GET', json_url, headers=headers)
json_data = json.loads(res.data.decode().strip()).get("data")
json_soup = BeautifulSoup(json_data, 'html.parser', from_encoding='utf-8')
result0 += json_soup.find_all("div", attrs={"action-type": "feed_list_item"})
return result0
Ps:需要注意的一点,微博默认返回的图片是缩略图,清晰图不高,想要获取到高清大图,需要解析到微博大图的地址,我在代码中处理了此类问题,替换了url的地址,以方便获取高清大图
















 7687
7687











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









