






GBase 8a MPP Cluster 数据库接口开发技术
总述
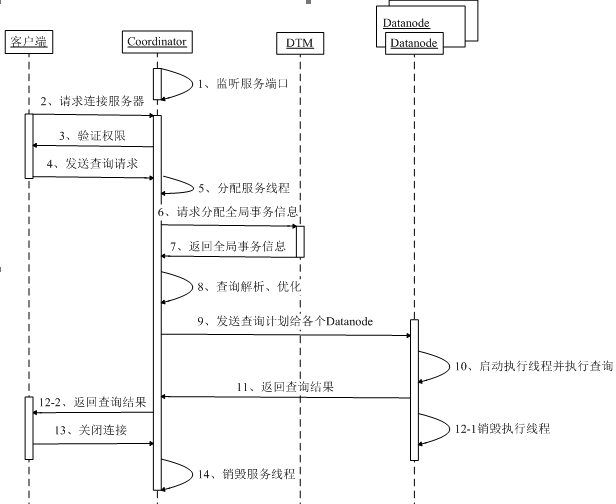
数据库接口是客户端程序与数据库建立连接的技术。下面的时序图展示从客户端发起查询请求到收到数据这段时间,在 GBase 8a 的各个节点间的交互过程,以及在每个节点内部都执行了哪些处理过程。其中 Coodrdonator 是管理节点;Datanode 是数据节点;DTM 是全局事务管理器。
GBase 8a 支持 JDBC、ODBC、C API、ADO.net 和 Python 接口。本文重点讲解项目最常用的 JDBC、ADO.NET、C API、Python 驱动接口。GBase 8a 赋予前三种驱动接口两个高级特性:连接高可用和连接负载均衡。Python 驱动 API 最精简,但是其仅具备连接高可用特性。
一、JDBC 驱动接口
(一)基本概念
JDBC(Java DataBase Connectivity)是一种用于执行SQL语句的Java API,可以为多种关系数据库提供统一访问,它由一组用Java语言编写的类和接口组成。JDBC 接口和数据库引擎最为匹配,所以通过 JDBC 接口操作数据库性能最高。
(二)GBase JDBC 概述
1、 驱动包名称:gbase-connector-java-8.3.81.53-build52.8-bin.jar
2、 要求的 JDK 版本:6 +;
3、 Java 程序调用步骤
(1) 注册 GBase JDBC 驱动
Class.forName("com.gbase.jdbc.Driver");
(2) Connection 接口(com.gbase.jdbc.Connnection)
Connection con=DriverManager.getConnection("jdbc:gbase://127.0.0.1:5258/DatabaseName,"UserName", "Password");
(3) Statement 接口(com.gbase.jdbc.Statement)
Statement st = con.createStatement(); // 生成可向数据库发送 CRUD SQL 操作的语句对象
(4) ResultSet 接口(com.gbase.jdbc.ResultSet)
ResultSet rs = st.executeQuery("select * from customer"); // 通过语句对象执行 SQL,结果集存放在 rs 中
// 如果要取得结果集对象 rs 某列的值,需要知晓 GBase 8a 数据类型与Java类型映射关系
4、GBase 8a 数据类型与Java类型映射关系
| GBase 8a 数据类型 | Java 类型 |
|---|---|
| CHAR, VARCHAR, TEXT | java.lang.String |
| BLOB, LONGBLOB | java.sql.Clob |
| FLOAT, REAL, DOUBLE PRECISION, NUMERIC, DECIMAL, TINYINT, SMALLINT, MEDIUMINT, INTEGER, BIGINT | java.math.BigDecimal |
| DATE, TIME, DATETIME | java.lang.String, java.sql.Date |
| TIMESTAMP | java.sql.Timestamp |
5、字符集设置
GBase JDBC 支持对发送给集群的信息和对获取集群返回的信息指定编码,一般情况下数据流程中的编码是统一的,才能保证没有乱码。在JDBC中指定编码只需要在 URL 中配置参数即可实现。
① utf8编码(可变 3 字节)示例:
jdbc:gbase://192.168.1.56:5258/testDB?useUnicode=true&characterEncoding=utf8&characterSetResults=utf8
② utf8mb4编码(可变 4 字节)示例:
jdbc:gbase://192.168.1.56:5258/testDB?useUnicode=true&characterEncoding=utf8&characterSetResults=utf8mb4
③ gbk编码(汉字编码)示例:
jdbc:gbase://192.168.1.56:5258/testDB?useUnicode=true&characterEncoding=gbk&characterSetResults=gbk
④ gb18030编码(汉字编码)示例:
jdbc:gbase://192.168.1.56:5258/testDB?useUnicode=true&characterEncoding=gb18030&characterSetResults=gb18030
6、IPV6 的支持
GBase JDBC 支持使用 IPV6 与数据库连接,使用方式除了 JDBC 串略有区别外,其他操作完全一样。
假设集群节点 IP 为 2001:da8:e000::1:1:1,JDBC 串示例如下:
jdbc:gbase://(2001:da8:e000::1:1:1):5258/testDB?user=gbase&password=xxxxxx
或者
jdbc:gbase://[2001:da8:e000::1:1:1]:5258/testDB?user=gbase&password=xxxxxx
7、连接 VC(虚拟集群)
GBASE JDBC 与指定 VC 的数据库连接,需要通过在 URL 中配置参数实现,对于配置了VC的集群,且用户没有默认VC的情况,必须在URL 中指定 VC 名称才能与集群连接。
比如虚拟集群名称为vc1,URL 配置示例如下:
jdbc:gbase://192.168.0.1:5258/mydb?vcName=vc1
(二)JDBC 驱动高级特性-连接高可用
1、概念:
GBase JDBC 高可用是接口针对GBase 8a集群所做的在接口层面的连接高可用处理(IP自动路由)。其为数据库接口驱动内部提供的一种高级特性。
2、应用:
适用于扁平结构的GBase集群,在创建JDBC连接时,如果当前IP的集群节点不可用,接口会根据相关参数信息把连接数据库请求自动路由到集群其他可用的节点,消除数据库系统服务不可用的时间。
3、示例:
假设三个管理节点的 GBase 8a 集群:192.168.1.56;192.168.1.57;192.168.1.58;
String dbUrl =
"jdbc:gbase://192.168.1.56:5258/testDB?user=root&password=root&failoverEnable=true&hostList=192.168.1.57,192.168.1.58";
failoverEnable:是否开启高可用。
hostList:IP 列表,以逗号分隔;hostList中不需要包含url中的主IP( 192.168.1.56 )。
连接高可用功能是按照hostList参数配置的IP顺序获取节点,尝试连接,如果某个IP连接成功,则直接返回这个节点的连接,如果所有节点都不能连接,则抛出异常。
连接高可用功能,只保证获取可用连接,并不能保证连接的均匀分布。下文中讲述的“连接负载均衡”特性能解决这个问题。
(三)JDBC 驱动高级特性-连接负载均衡
1、概念:
把数据库连接请求平均分布到各个节点,以分散节点数据库连接压力。
2、应用场景
假设创建9个数据库连接,三个节点都是可用状态,执行结果是每个节点分配到三个连接;如果其中一个节点不可用状态,GBase JDBC 驱动会把9个数据库连接请求再平均分配到另外两个可用节点上。
示例:三个节点的 GBase 8a 集群:192.168.1.56(主);192.168.1.57;192.168.1.58;
String dbUrl ="jdbc:gbase://192.168.1.56:5258/courseware?user=gbase&password=gbase20110531&failoverEnable=true&hostList=192.168.1.57,192.168.1.58&gclusterId=gcl1";
failoverEnable:是否开启高可用。
hostList:集群节点的IP列表,以逗号分隔,hostList中不需要包含url中的主IP。
gclusterId:不同的gclusterId会创建不同的列表,用于区分连接的集群,要求必须以字母开头的可以包含字母和数字最大长度为20的字符串。
(四)JDBC 驱动高级特性-数据批量插入
1、技术背景:
使用驱动对 GBase 8a 集群执行大体量数据插入的时候,如果采用多条 insert 语句插入方式执行,执行性能会比较低。如果要获得更好的执行效率,可以通过数据批量插入的方式来实现。
2、概念:
数据批量插入是驱动内部的一种高级特性,为应用程序提供了相关的API支持。驱动可以根据将用户要插入的多条数据转换为 insert values 元组形式的SQL,一次性发送给数据库服务引擎。此种方式减少了网络传输,同时数据库服务端仅执行一个 insert SQL 语句,尤其是在大量数据的插入操作场景下,性能提升明显。
3、示例:
【需求】testDB 库有一张表 T1 有2个字段 id 和 select_sql,需要将10000条数据插入到表 T1 中。
【代码编写步骤】
① 获取数据库连接。
② 编写SQL语句。
③ 预编译SQL语句。
④ 填充占位符。
⑤ 调用PreparedStatement对象的 addBatch() 做 SQL 语句攒批。
⑥ 调用PreparedStatement对象的 excuteBatch() 执行 SQL 语句。
⑦ 调用PreparedStatement对象的 clearBatch() 清空 Batch
JDBC 串如下:
String URL = "jdbc:gbase://192.168.103.144:5258/testDB?rewriteBatchedStatements=true";
rewriteBatchedStatements:当设置该参数为 true 时,将开启攒批功能,当为 false时,sql将进行逐条发送。
// 示例代码如下:
String sql = "insert into T1 (id,`select_sql`) values (?,?)"; // 如果sql中包含select(不区分大小写),如列名select_sql,需要使用反引号(`)包围。
Connection conn = DriverManager.getConnection(URL, "gbase", "xxxxxx"); // 创建和 GBase 的数据库连接
PreparedStatement stm = conn.prepareStatement(sql); // 使用预处理
for (int i=0; i<10000; i++) {
stm.setString(1, String.valueOf(i));
stm.setString(2, “select ” + String.valueOf(i))
stm.addBatch(); // 向 stm 对象循环添加 insert SQL 语句,即攒批
}
stm.executeBatch(); // 批量执行 insert SQL
虽然每次循环向 stm 对象添加一条 insert SQL 语句,但发送到数据集引擎的 SQL 文实际上是个元组序列:
insert into T1 (id, select_sql) values (‘0’, ‘select 0’),(‘1’, ‘select 1’),(‘2’, ‘select 2’)…(‘9999’, ‘select 9999’)
显然,这一条 insert 语句比 10000 条 insert 语句执行速度快很多。
(五)流式读取
1、技术背景:
在使用 JDBC 驱动从数据库获取数据的时候,一般情况下,进行一次查询,结果集是一次性从数据库获取的,并存放在JDBC所在应用的内存中。这种情况如果查询的结果集比较大,将会导致应用服务器内存增长速度陡增,甚至内存溢出。这种情况下,如果不考虑扩充内存,则就需要开启 GBase JDBC 的流式读取方式。
2、概念:
流式读取方式可以通过数据流的方式,逐条从集群获取数据,将数据获取到JDBC应用所在内存中,从而减小大结果集占用应用服务器的内存。
限制:
开启流式读取在降低应用内存损耗的同时,会增加数据库集群的资源,频繁使用可能对数据库集群性能造成影响。所以,有读取大量数据到客户端的需求时,应首先从业务角度分析,避免一次流式读取过大数据量,比如可以考虑分批读取并存储的方式。
3、示例代码:
// 一、开启流式读取的核心代码:
streamStmt = Conn.createStatement(
java.sql.ResultSet.TYPE_FORWARD_ONLY,
java.sql.ResultSet.CONCUR_READ_ONLY);
streamStmt.setFetchSize(Integer.MIN_VALUE); // 常量
// 二、读取数据的核心代码:
while (rs.next()) {
// 必须遍历(消费)完所有结果集,GBase 8a MPP 才能释放资源
rs.getString(1);
(六)JDBC 驱动综合示例
◆ JDBC 驱动的注册
◆ 创建、关闭数据库连接
◆ 通过 Statement 执行 SQL 显示结果集
◆ 通过 PreparedStatement 批量执行 SQL
◆ 错误陷阱
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.ResultSetMetaData;
import java.sql.SQLException;
import java.sql.Statement;
public class ExecuteSQLByStatement {
private static final String URL = "jdbc:gbase://111.161.65.149:32800/courseware?user=gbase&password=gbase20110531";
public static void main(String[] args) {
prepareTableAndData();
ExecuteSQLByStatement executeSQLByStatement = new ExecuteSQLByStatement();
executeSQLByStatement.executeSQLByStatement();
executeSQLByStatement.executeSQLByPreparedStatement();
}
/**
* 通过Statement 执行SQL 语句, 并把ResultSet 中的结果通过控制台 打印出来。
*/
public void executeSQLByStatement() {
Connection conn = null;
Statement stm = null;
ResultSet rs = null;
ResultSetMetaData rsmd = null;
try {
Class.forName("com.gbase.jdbc.Driver"); // 注册 JDBC 驱动
conn = DriverManager.getConnection(URL); // 连接数据库
stm = conn.createStatement(); // 根据数据库连接对象产生 Statement 对象
rs = stm.executeQuery("select * from student where sid in ('01','02')"); // 执行 SQL
if (rs == null) {
return;
}
rsmd = rs.getMetaData(); // 获取表元数据信息
int rsColoumnCount = rsmd.getColumnCount(); // 得到字段数量
System.out.println("executeSQLByStatement ==>");
while (rs.next()) {
for (int i = 0; i < rsColoumnCount; i++) {
System.out.print(rsmd.getColumnName(i + 1).concat(" = "));
System.out.println(rs.getObject(i + 1));
}
}
System.out.println("<== executeSQLByStatement");
} catch (ClassNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} finally {
try {
rs.close();
} catch (NullPointerException e) {
} catch (Exception e) {
rs = null;
}
try {
stm.close();
} catch (NullPointerException e) {
} catch (Exception e) {
stm = null;
}
try {
conn.close();
} catch (NullPointerException e) {
} catch (Exception e) {
conn = null;
}
}
}
/**
* 通过PreparedStatement 执行SQL 语句, 并把ResultSet 中的结果通过控制台 打印出来。
*/
public void executeSQLByPreparedStatement() {
Connection conn = null;
PreparedStatement stm = null;
ResultSet rs = null;
ResultSetMetaData rsmd = null;
try {
Class.forName("com.gbase.jdbc.Driver"); // 注册驱动
conn = DriverManager.getConnection(URL); // 获取数据库连接对象
stm = conn.prepareStatement("select * from student where sid in (?,?)"); // 通过数据库连接对象产生 PreparedStatement 对象
stm.setString(1, "01");
stm.setString(2, "02");
rs = stm.executeQuery(); // 执行 SQL
if (rs == null) {
return;
}
rsmd = rs.getMetaData(); // 获取表的元数据信息
int rsColoumnCount = rsmd.getColumnCount(); // 得到字段数量
System.out.println("executeSQLByPreparedStatement ==>");
while (rs.next()) {
for (int i = 0; i < rsColoumnCount; i++) {
System.out.print(rsmd.getColumnName(i + 1).concat(" = "));
System.out.println(rs.getObject(i + 1));
}
}
System.out.println("<== executeSQLByPreparedStatement");
} catch (ClassNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} finally {
try {
rs.close();
} catch (NullPointerException e) {
} catch (Exception e) {
rs = null;
}
try {
stm.close();
} catch (NullPointerException e) {
} catch (Exception e) {
stm = null;
}
try {
conn.close();
} catch (NullPointerException e) {
} catch (Exception e) {
conn = null;
}
}
}
(七)SSH 隧道连接
1、技术背景:
需要连接到设置在启用SSH协议服务器上的远程数据库。由于数据库位于启用SSH的服务器上,因此我们无法使用 JDBC API 直接连接之。 为此,我们首先必须创建一个SSH会话,然后使用端口转发将请求转发到服务器并连接到数据库。
2、基本概念:
SSH隧道连接,可以先从JDBC所在服务器与数据库服务器间建立SSH隧道,然后通过该隧道实现从数据库服务器的本地连接并登录集群,实现数据库的操作。
3、常用组件:JSch ( Java Secure Channel )
(1) JSch 是 SSH2 的纯Java实现。
(2) JSch 允许你连接到一个SSH服务器,并且可以使用端口转发,X11转发,文件传输等,当然你也可以集成它的功能到你自己的应用程序。
(3) 使用 JSch,需要从官网下载下载 jsch-0.1.55.jar
4、代码示例:
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import com.jcraft.jsch.JSch; // Java Secure Channel 的缩写。JSch是一个SSH2的纯Java实现
import com.jcraft.jsch.Session;
import java.sql.Connection;
public class GBaseConnOverSSH {
/**
* Java Program to connect to the remote database through SSH using port forwarding
* @author modified by HaoJun
* @throws SQLException
*/
public static void main(String[] args) throws SQLException {
int lport = 6000; // SSH本地端口转发到远程的端口
String rhost = "111.161.65.149";
String host = "111.161.65.149";
int rport = 32800; // 8a 集群数据库服务 5258 端口对应的外部映射端口
String sshUser = "root"; // SSH 协议所在操作系统 root 账户
String ssPassword = "edu@20210715"; // root 的密码
String dbuserName = "gbase"; // 数据库账户
String dbpassword = "gbase20110531"; // 数据库账户密码
String url = "jdbc:gbase://localhost:"+lport+"/courseware";
String driverName="com.gbase.jdbc.Driver";
Connection conn = null;
Session session = null;
try{
java.util.Properties config = new java.util.Properties();
config.put("StrictHostKeyChecking", "no");
JSch jsch = new JSch();
session = jsch.getSession(sshUser, host, 20039); // 20039 是 SSH 协议 22 端口的对外映射端口
session.setPassword(ssPassword);
session.setConfig(config); // 关闭 SSH 严格的公钥检查
session.connect();
System.out.println("Connected");
// 设置SSH本地端口转发,本地转发到远程
int assinged_port = session.setPortForwardingL(lport, rhost, rport);
System.out.println("localhost:"+assinged_port+" -> "+rhost+":"+rport);
System.out.println("Port Forwarded");
// GBase database connectivity
Class.forName(driverName).newInstance();
conn = DriverManager.getConnection (url, dbuserName, dbpassword);
System.out.println ("Database connection established");
System.out.println("DONE");
}catch(Exception e){
e.printStackTrace();
}finally{
if(conn != null && !conn.isClosed()){
System.out.println("Closing Database Connection");
conn.close();
}
if(session !=null && session.isConnected()){
System.out.println("Closing SSH Connection");
session.disconnect();
}
}
}
}
(八)开发框架及中间件
GBase JDBC 符合JDBC 4.0规范,兼容符合此规范的所有开发框架和中间件。
1、持久层
(1) MyBatis
MyBatis是一款优秀的持久层框架,它支持自定义SQL、存储过程以及高级映射。MyBatis可以通过简单的XML或注解来配置和映射原始类型、接口和Java POJO为数据库中的记录。
JDBC驱动在MyBatis中的使用
① 引入MyBatis 和 GBase jdbc 驱动包
② 配置mybatis-config.xml如下:
<dataSource type="POOLED">
<property name="driver" value="com.gbase.jdbc.Driver" / >
<property name="url" value="jdbc:gbase://192.168.5.66:5258/testDB" />
<property name="username" value="gbase" />
<property name="password" value="xxxxxx" />
</dataSource >
(2) Hibernate
Hibernate 是一种 ORM(对象关系映射)框架,其对 JDBC 进行了非常轻量级的封装,屏蔽了不同数据库间的差异,使得开发人员能够以统一的、面向对象的方式操作数据库。
JDBC驱动在 Hibernate 中的使用:
① 根据hibernate版本获取对应的dialect包。
② 引入hibernate,dialect包和 GBase jdbc 驱动包。
③ 配置hibernate.cfg.xml,如下:
<session-factory>
<property name="dialect">org.hibernate.dialect.GBaseDialect</property>
<property name="connection.driver_class">com.gbase.jdbc.Driver</property>
<property name="connection.url">jdbc:gbase://192.168.5.66:5258/bhtjdbctest?profileSql=true</property>
<property name="connection.username">gbase</property>
<property name="connection.password">xxxxxxxx</property>
</session-factory>
2、连接池
主流的连接池 GBase 8a 数据库都可以适配,在使用连接池时,经常遇到的问题是应用从连接池里拿到一个已经失效的连接,这是就会抛出异常,常见的做法是在连接池中开启连接验证机制,保证连接池中的连接是可用的即可。
(1) DBCP连接池
testWhileIdle = “true”:指明连接是否被空闲连接回收器进行检验,如果检验失败,则连接将从连接池中去除。
validationQuery = “SELECT 1”:验证使用的SQL语句。
(2) C3P0连接池
idleConnectionTestPeriod = “60 ” : 每60秒检查所有连接池中的空闲连接。Default:0,表示不进行检测。
preferredTestQuery = “SELECT 1” :验证使用的SQL语句。
(3) Druid连接池
testWhileIdle = “true”:指明连接是否被空闲连接回收器进行检验,如果检验失败,则连接将从连接池中去除。
validationQuery = “SELECT 1”:验证使用的SQL语句。
3、WEB 容器
GBase JDBC 支持 Tomcat、Jboss、IBM WebSphere、Oracle Weblogic、GlassFish 等WEB容器。
二、ADO.NET 驱动接口
(一)GBase ADO.NET 驱动的特性
1、支持集群高可用功能;
2、支持集群负载均衡功能;
3、支持针对集群的带负载均衡的连接池功能;
4、支持GBase 8a数据库全部特性,如:存储过程、视图等;
5、支持大型数据包,可发送和接收高达2GB的BLOB数据;
6、支持协议压缩,允许对客户端和服务器之间交互的数据流进行压缩;
7、支持Windows平台下的TCP/IP套接字连接;
8、支持Linux平台下的TCP/IP套接字或Linux套接字连接;
9、无需安装GBase 8a数据库的客户端,可通过GBase ADO.NET类库实现完整的管理功能。
(二)GBase ADO.NET 开发环境配置
1、安装 Visual Studio 2010 SP1:X16-42552VS2010UltimTrial1.iso
2、安装 GBase ADO.NET:GBaseADO.NET_8.3.81.53_build{xx}_Windows_x86.msi
3、创建 C#.NET 工程:GBaseADONET.sln
4、工程中引用库文件:{GBase ADO.NET Connector}\bin\GBase.Data.dll
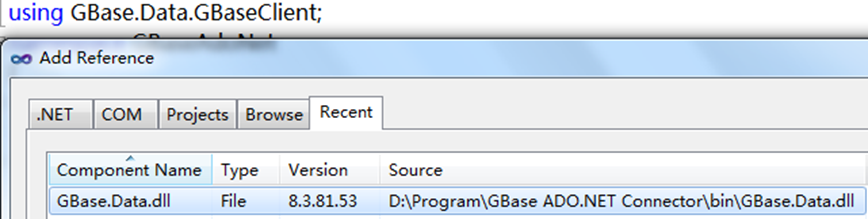
完整代码如下
using System;
using System.Collections.Generic;
using System.Data;
using GBase.Data.GBaseClient;
namespace GBaseAdoNet
{
class Program
{
static void Main(string[] args)
{
String connStr = "server=111.161.65.149;userid=gbase;password=gbase20110531;database=courseware;port=32800;pooling=false";
using (GBaseConnection conn = new GBaseConnection())
{
try
{
conn.ConnectionString = connStr;
conn.Open();
String cmdText = "select * from courseware.student";
GBaseCommand cmd = new GBaseCommand(cmdText, conn);
GBaseDataReader reader = cmd.ExecuteReader(CommandBehavior.SingleResult);
while (reader.Read())
{ // 输出结果集的第二列
Console.WriteLine(reader.GetValue(1));
}
reader.Close();
}
catch (GBaseException ex)
{
switch (ex.Number)
{
case 1042:
Console.WriteLine("Cannot connect to server. Contact administrator");
break;
case 1045:
Console.WriteLine("Invalid username/password, please try again");
break;
default:
Console.WriteLine(ex.StackTrace);
break;
}
}
finally
{
if (conn != null)
conn.Close();
Console.WriteLine("Connect to GBase 8a MPP Cluster successfully.");
}
}
}
}
}
(三)ADO.NET 驱动高级特性-连接高可用
1、概念:按照ipList参数配置的IP顺序获取节点,尝试连接,如果某个IP连接成功,则直接返回这个节点的连接,如果所有节点都不能连接,则抛出异常。连接高可用功能,只保证获取可用连接,并不能保证连接的均匀分布。
2、示例:
三个节点的 GBase 8a 集群 IP:192.168.1.56;192.168.1.57;192.168.1.58;
String connStr = "server=192.168.1.56;user id=gbase;password=gbase20110531;database=courseware;port=5258;pooling=false;failover=true;iplist=192.168.1.57,192.168.1.58";
// failover:是(true)否(false)开启高可用。
// iplist:以逗号分隔的 IP 列表,ipList中不需要包含 server 主IP( 192.168.1.56 )
(四)ADO.NET驱动高级特性-高可用负载均衡
1、概念:
当 ADO.NET 应用程序获取连接的时候,会从 iplist 中顺序获取 IP 创建数据库连接,为每个 IP 创建一个连接,从而实现连接的负载均衡。如果列表中的 IP 不可连接,ADO.NET会顺序获取列表中的下一个IP,尝试连接,所有 IP 都不能创建数据库连接,则抛出异常。即,高可用负载均衡功能既实现了连接负载均衡功能,也实现了高可用功能。
2、示例:
String connStr = "server=192.168.1.56;userid=gbase;password=xxxxxx;
database=testDB;port=5258;pooling=false;
failover=true;iplist=192.168.1.57,192.168.1.58;gclusterid=g1";
/*
failover:是(true)否(false)开启高可用。
iplist:集群管理节点的IP列表,以逗号分隔,ipList中不需要包含 server 主(IP192.168.1.56)。
gclusterid:iplist 所在集群的标识名,要求必须以a-z字符开头的可以包含a-z、0-9所有字符长度为最大为20的字符串。这是开启负载均衡的关键参数
*/
(五)开发框架及中间件
ADO.NET 驱动属于微软 DOT NET 开发框架,中间件也主要是微软提供的。
1、持久层 - EntityFramework
EntityFramework 是微软的一个 ORM(对象关系映射)中间件,用于支持开发人员通过对概念性应用程序模型编程(不是直接操作数据库表)来创建数据访问应用程序,目标是降低面向数据的应用程序所需的代码量并减少维护工作。
ADO.NET驱动在EntityFramework中的使用
(1) 引入EntityFramework 和ADO.NET驱动包
(2) 通过三种方式实现数据库与实体对象的映射,这三种方式都可以通过可视化界面进行配置:
DatabaseFrist:数据库优先,需要先创建数据库。
ModelFrist:实体模型优先,需要先创建实体模型。
CodeFrist:实体类优先,需要在model中写实体类和dbcontext上下文类。
2、连接池
(1) ADO.NET 驱动基于负载均衡的连接池,根据客户端负载均衡策略模式将客户端连接请求分摊到集群节点,根据服务端策略模式可得到负载最小的缓存连接提供给客户端。
(2) 连接池特性:
√ 缓存所有集群节点的连接
√ 提供检查借出连接是否可用
√ 提供检测归还连接是否可用
√ 根据客户端负载策略以轮询方式获取集群各个节点的缓存连接
√ 根据服务端负载策略方式实时或定期获取最小负载节点缓存连接
√ 提供定期动态补充连接、清理无效连接、清理过期连接
(3) 连接池示例:
比如,四个节点的 GBase 8a 集群 IP:192.168.9.173, 192.168.9.174, 192.168.9.175, 192.168.9.176
客户端开启负载均衡连接池,设置连接串参数如下:
String connStr = " server=192.168.9.173;userid=gbase;password=xxxxxx;database=testDB;
pooling=true;min idle size=20;max idle size=40;gclusterid=g1;failover=true; initial pool size=20;iplist=192.168.9.174,192.168.9.175,192.168.9.176; test on borrow=true;
test on return=true;test while idle=true;load balance strategy=polling;max inuse lifetime=0 ";
客户端使用 GBaseConnection 通过上面的连接串进行初始化,并打开连接后,驱动会在集群的每个节点上创建5个连接,并缓存起来,并以 polling (轮询)的方式先从173节点获取缓存连接。
3、WEB 容器一般采用 windows 操作系统的 IIS 服务。
三、GBase C-API
1、样例代码

- 在 VS2010 集成环境中部署 GBaseCAPI Solution 结构如下:
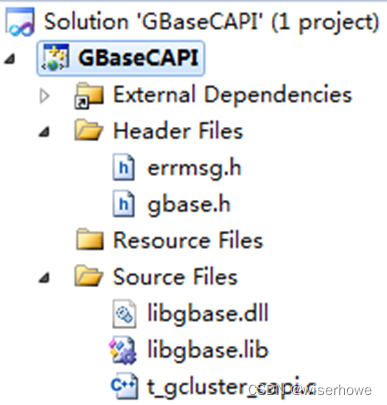
(1) 头文件 gbase.h 存储的是 API 接口、常量和 struct 定义;errmsg.h 存储的是错误代码等。
(2) libgbase.dll 和 libgbase.lib 是库文件;
(3) t_gcluster_capi.c 是测试 API 的 C 语言程序。
2、在 VS2010 集成环境中添加库文件的额外依赖(打开 GBaseCAPI 工程的属性页):
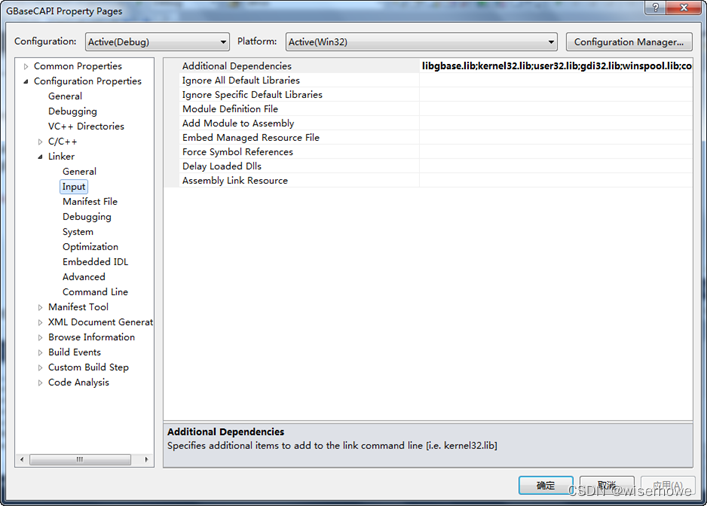
在 Linker => Input => Additional Dependencies 最前面增加 libgbase.lib 字串。这是设置工程要引用 libgbase.lib 第三方库文件。
3、拷贝一份儿库文件到 GBaseCAPI.sln 同级目录下:
libgbase.dll 和 libgbase.lib 既要在 t_gcluster_capi.c 同级目录下要存在,
GBaseCAPI.sln 同级目录下也要有一份儿。
避免无法打开库文件的错误。
4、编码基本步骤:
(1) 声明 GBASE 结构体:
GBASE* gbase=NULL
(2) 初始化 GBASE 结构体:
gbase= gbase_init(0)
(3) 创建数据库连接:
gbase_real_connect(gbase, host, user, passwd, db, port, NULL)
(4) 执行 SQL:
gbase_query(gbase, sqlString)
(5) 释放数据库连接句柄:
gbase_close(gbase);
5、样例代码:
/* 主要测试
(1) 建表
(2) 查询表
(3) 插入数据
(4) 删除数据
(5) 更新数据
(6) 创建存储过程
(7) 执行存储过程
(8) 删除存储过程
*/
#ifdef WIN32
# include <windows.h>
#else
# include <unistd.h>
# include <signal.h>
#endif
#include <stdio.h>
#include <stdlib.h>
#include <ctype.h>
#include <string.h>
#include "gbase.h"
#define PRINT_TABLE 1
#pragma comment(lib, "libgbase.lib")
/*集群信息*/
const char* host = "111.161.65.149";
const char* user = "gbase";
const char* passwd = "gbase20110531";
unsigned int port = 32800;
const char* db = "test";
const char* table_name = "tFact";
/*sql文信息*/
const char* sql_ddl = "create table tFact(a int, b varchar(50))";
const char* sql_insert = "insert into tFact values (1, \'GBase 8a MPP Cluster\')";
const char* sql_select = "select * from tFact";
const char* sql_delete = "delete from tFact where a = 1";
const char* sql_update = "update tFact set b=\'update\' where a =1";
const char* sql_create_proce = "create procedure demo_p(in a varchar(100), out b varchar(100)) \
begin \
set b = CONCAT('InOutParam ',a,' works!'); \
end;";
const char* sql_drop_proce = "drop procedure demo_p";
const char* sql_call_proce = "CALL demo_p('input', @out)";
const char* sql_select_out = "select @out";
GBASE* gbase=NULL; // 定义 GBASE 结构体指针
const char* usage = "%s s[D(DDL), d(delete), u(update), i(insert), p(proce), P(drop proce), c(call proce)]\n";
void print_table(GBASE* gbase, char* table_name);
void demo_ddl();
// tFact 表存在则删除
void dropExistTable()
{
char* sql_dropTab = "drop table if exists tFact";
if(gbase_query(gbase, sql_dropTab))
{
printf("%d\t%s\n", gbase_errno(gbase), gbase_error(gbase));
exit(1);
}
}
void demo_ddl()
{
unsigned int errID;
printf("执行ddl语句:\n\t%s\n", sql_ddl);
dropExistTable();
if(gbase_query(gbase, sql_ddl))
{
errID = gbase_errno(gbase);
printf("%d\t%s\n", errID, gbase_error(gbase));
return;
//exit(1);
}
printf("执行成功\n");
}
void demo_select()
{
GBASE_RES* res = NULL;
GBASE_FIELD* fields = NULL;
GBASE_ROW row;
int i = 0;
unsigned int num_fields = 0;
printf("执行查询sql:\n\t%s\n", sql_select);
if(gbase_query(gbase, sql_select))
{
printf("%d\t%s\n", gbase_errno(gbase), gbase_error(gbase));
return;
}
printf("查询结果:\n");
res = gbase_store_result(gbase);
num_fields = gbase_num_fields(res);
while(fields = gbase_fetch_field(res))
{
printf("|%s\t", fields->name);
}
printf("|\n");
for(i=0;i<num_fields; i++)
{
printf("--------");
}
printf("\n");
while((row = gbase_fetch_row(res)) != NULL)
{
for(i=0; i < num_fields; i++)
{
printf("|%s\t", row[i]);
}
printf("|\n");
}
gbase_free_result(res);
}
void demo_delete()
{
printf("执行删除sql:\n\t%s\n", sql_delete);
if(gbase_query(gbase, sql_delete))
{
printf("%d\t%s\n", gbase_errno(gbase), gbase_error(gbase));
return;
}
print_table(gbase, table_name);
}
void demo_update()
{
printf("执行更新sql:\n\t%s\n", sql_update);
if(gbase_query(gbase, sql_update))
{
printf("%d\t%s\n", gbase_errno(gbase), gbase_error(gbase));
return;
}
print_table(gbase, table_name);
}
void demo_insert()
{
printf("执行插入sql:\n\t%s\n", sql_insert);
if(gbase_query(gbase, sql_insert))
{
printf("%d\t%s\n", gbase_errno(gbase), gbase_error(gbase));
return;
}
print_table(gbase, table_name);
}
void demo_create_proce()
{
printf("创建存储过程:\n\t%s\n", sql_create_proce);
if(gbase_query(gbase, sql_create_proce))
{
printf("%d\t%s\n", gbase_errno(gbase), gbase_error(gbase));
exit(1);
}
printf("创建成功\n");
}
void demo_drop_proce()
{
printf("删除存储过程:\n\t%s\n", sql_drop_proce);
if(gbase_query(gbase, sql_drop_proce))
{
printf("%d\t%s\n", gbase_errno(gbase), gbase_error(gbase));
exit(1);
}
printf("删除成功\n");
}
void demo_call_proce()
{
GBASE_RES* res = NULL;
GBASE_ROW row;
GBASE_FIELD* fields = NULL;
unsigned int num_fields = 0;
int i = 0;
printf("执行存储过程:\n\t%s\n", sql_call_proce);
if(gbase_query(gbase, sql_call_proce))
{
printf("%d\t%s\n", gbase_errno(gbase), gbase_error(gbase));
exit(1);
}
if(gbase_query(gbase, sql_select_out))
{
printf("%d\t%s\n", gbase_errno(gbase), gbase_error(gbase));
exit(1);
}
res = gbase_store_result(gbase);
printf("执行结果\n");
if(res)
{
num_fields = gbase_num_fields(res);
while(fields = gbase_fetch_field(res))
{
printf("\t| %s ", fields->name);
}
printf("\t|\n");
while((row = gbase_fetch_row(res)) != NULL)
{
for(i=0; i < num_fields; i++)
{
printf("\t| %s ", row[i]);
}
printf("\t|\n");
}
}
}
void menu()
{
printf("D - 执行ddl语句创建表\n");
printf("i - 执行插入\n");
printf("s - 执行查询\n");
printf("d - 执行删除\n");
printf("u - 执行更新\n");
printf("p - 创建存储过程\n");
printf("P - 删除存储过程\n");
printf("c - 执行存储过程\n");
printf("Q or q - 退出程序\n");
printf("请输入存在的命令:\n");
}
// 测试程序入口
void main(int argc, char** argv)
{
int key = 0;
int iExit = 0; // 消息循环的退出标识
if(!(gbase = gbase_init(0)))
{
printf("%d\t%s\n", gbase_errno(gbase), gbase_error(gbase));
exit(1);
}
if(!gbase_real_connect(gbase, host, user, passwd, db, port, NULL, 0))
{
printf("%d\t%s\n", gbase_errno(gbase), gbase_error(gbase));
exit(1);
}
menu(); // 显示功能菜单
while(1)
{
key = getchar(); // 获得键盘输入的键值
//printf("键值:%d\n", key);
/*运行demo*/
switch( toascii(key) )
{
case 'D':
demo_ddl(); // 执行ddl语句创建 tFact 表
break;
case 's':
demo_select(); // 执行查询语句
break;
case 'd':
demo_delete(); // 删除语句
break;
case 'u':
demo_update(); // 更新语句
break;
case 'i': // 插入数据
demo_insert();
break;
case 'p': // 创建存储过程
demo_create_proce();
break;
case 'P': // 删除存储过程
demo_drop_proce();
break;
case 'c': // 呼叫存储过程
demo_call_proce();
break;
case 'q': // 退出 Demo
case 'Q': // 退出 Demo
iExit = 1;
break;
default:
menu();
//printf(usage, argv[0]);
}
if(iExit)
{
break;
}
}
gbase_close(gbase);
}
/*打印表中数据*/
void print_table(GBASE* gbase, char* table_name)
{
GBASE_RES* res = NULL;
GBASE_FIELD* fields = NULL;
GBASE_ROW row;
unsigned int num_fields;
char sql_select[500] = "select * from ";
int i=0;
if(0 == PRINT_TABLE)
{
return;
}
printf("打印表中数据\n");
while(table_name[i]){sql_select[14+i] = table_name[i]; i++;}
sql_select[14+i] = '\0';
if(gbase_query(gbase, sql_select))
{
printf("%d\t%s\n", gbase_errno(gbase), gbase_error(gbase));
exit(0);
}
res = gbase_store_result(gbase);
num_fields = gbase_num_fields(res);
while(fields = gbase_fetch_field(res))
{
printf("|%s\t", fields->name);
}
printf("|\n");
for(i=0;i<num_fields; i++)
{
printf("--------");
}
printf("\n");
while((row = gbase_fetch_row(res)) != NULL)
{
for(i=0; i < num_fields; i++)
{
printf("|%s\t", row[i]);
}
printf("|\n");
}
gbase_free_result(res);
}
四、GBase Python Connector
(一)Python 驱动的兼容特性
√ 完全兼容 GBase 8a MPP Cluster
√ 完全支持 SQL 标准语法
√ 支持二进制流插入、更新
√ 支持批量插入优化
√ 支持多SQL 语句执行和获取多结果集
√ 支持TCP/IP 协议
√ 支持Python 的datetime 和GBase 时间类型的映射
(二)Python 驱动架构

◆ GBaseConnection :GBase 数据库的连接。
◆ GBaseCursor :执行GBase 数据库操作的游标类,可以执行SQL 语句、存储过程、获取结果集。
◆ GBaseError :异常处理类,定义接口抛出的异常。
◆ GBaseConstants :常量类,定义客户端标记、字符集等
(三)Python 驱动的安装
1、安装 python3.6 --> python-3.6.8-amd64.exe
2、解压 gbase-connector-python-3.0.1_forpy3.6.tar.gz 文件,在 .\dist\gbase-connector-python-3.0.1\ 目录下的 console 下执行 python setup.py install
3、验证是否装好 :在 DOS 下执行 pip list 可以看到 列表中有
gbase-connnector-python
(四)Python 接口开发示例
1、基本步骤
(1) 库引入
(2) 连接参数
(3) 创建连接对象、传入连接参数
(4) 基于连接对象创建光标对象
(5) 使用光标对象执行 SQL
(6) 使用光标对象获取结果集
(7) 捕获异常
(8) 关闭数据库连接
# 2020.07.01 GBase 8a MPP 数据库连接测试 must be running in python 3.6
''' 测试 GBase 8a MPP Cluster 单条 DQL 执行 '''
from GBaseConnector import connect,GBaseError # 库名称:gbase-connnector-python
config = {'host':'111.161.65.149','port':32800,'database':'courseware',
'user':'gbase','passwd':'gbase20110531'} # 数据库连接参数字典
try:
conn = connect()
conn.connect(**config)
cur = conn.cursor()
cur.execute("select * from student")
rows = cur.fetchall()
for row in rows:
print(row) # 输出行数据
except GBaseError.DatabaseError as e:
print(e)
finally:
conn.close() # 关闭数据库连接
# 2020.07.01 GBase 8a MPP 数据库连接测试 must be running in python 3.6
''' 测试 GBase 8a MPP Cluster 多条 DML 执行 '''
from GBaseConnector import connect,GBaseError
config = {'host':'111.161.65.149','port':32800,'database':'testDB',
'user':'gbase','passwd':'gbase20110531'}
try:
conn = connect()
conn.connect(**config)
cur = conn.cursor()
cur.execute("DROP TABLE IF EXISTS testbyhao")
cur.execute("CREATE TABLE testbyhao (COL1 INT, COL2 VARCHAR(20))")
opfmt = "INSERT INTO testbyhao(COL1, COL2) VALUES(%s, %s)"
rows = []
for i in range(0, 100):
rows.append((i, "row" + str(i)))
cur.executemany(opfmt, rows)
cur.execute("SELECT * FROM testbyhao")
row = cur.fetchmany(3)
while row:
print(row)
row = cur.fetchmany(4)
row = cur.fetchmany(4)
conn.commit()
except GBaseError.DatabaseError as e:
print(e)
conn.rollback()
finally:
conn.close()
2、连接高可用:
三个节点 GBase 8a 集群 IP:
192.168.1.56;192.168.1.57;192.168.1.58;
config = {'host' : ' 192.168.1.56;192.168.1.57;192.168.1.58 ',
'port' : 5258, 'database' : 'testDB', 'user' : 'gbase', 'passwd' : 'xxxxxxxx'}
连接高可用功能是按照 host 参数配置的 IP 顺序获取节点,尝试连接,如果某个IP连接成功,则直接返回这个节点的连接,如果所有节点都不能连接,则抛出异常。连接高可用功能,只保证获取可用连接,并不能保证连接的均匀分布。
五、总结
本文介绍了四种数据库驱动,对应四种专业程序语言,对于开发工程师需要精通一种,对于南大通用的技术支持必须全面掌握代码的实现原理和基本概念,无需读懂代码细节,这样才能做到将客户现场问题精确反馈给研发的效果。
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









